Directly edit ONNX file in text format
Goal
Modify an .onnx file a little as easy as possible.
The reasons are:
- I want to change the input / output format of the ONNX file obtained from Model Zoo.
- The output of ONNX file A is the input of ONNX file B, so I want to combine them.
and so on.
Overview
- Convert ONNX files from binary format to text format
- Edit with a text editor
- Convert it from text format to binary format
The point is how to convert between binary and text format.
Preparation
Download "Protocol Buffer Compiler"
We use Protocol Buffer Compiler for the conversion between binary and text format because ONNX is a format defined using Protocol Buffers.
First, download the pre-built file of Protocol Buffer Compiler from the Protocol Buffer's Release Page. This is for Windows.
Then, unzip it. I recommend to add the "protoc-X.Y.Z-win64\bin" (XYZ is the version number) to the path.
Download onnx.proto
From ONNX Official GitHub, download onnx.proto.
onnx.proto defines the ONNX format. With this and the Protocol Buffer Compiler, you can interpret ONNX files.
How to execute
Conversion between binary and text format
Open Command Prompt and enter the followings:
-
Binary to text
protoc --decode onnx.ModelProto onnx.proto < SrcBinaryFile.onnx > DstTextFile.txt -
Text to binary
protoc --encode onnx.ModelProto onnx.proto < SrcTextFile.txt > DstBinaryFile.onnx
Where
- protoc: The path to "protoc-X.Y.Z-win64\bin\protoc.exe" you downloaded and unzipped
- onnx.proto: The path to "onnx.proto" you downloaded
- SrcBinaryFile.onnx: The path to the original ONNX file
- DstTextFile.txt: The path to write the converted text file
- SrcTextFile.txt: The path to the source text file
- DstBinaryFile.onnx: The path to write the converted binary file
If it doesn't work, make sure the file paths are correct. If you are lazy, just put them in the same folder.
Edit in text format
Take a look at "DstTextFile.txt" and compare it with the "SrcBinaryFile.onnx" using Netron.
You can find the definition of the operators here.
Example: Change model input from NCHW-RGB-float to NHWC-BGR-Byte
When using OpenCV, images are often treated as an array of NHWC-BGR-Byte.
On the other hand, the inputs of machine learning models are often NCHW-RGB-float. Therefore, preprocess is required, which is sometimes troublesome, especially when using multiple models with different preprocessing.
So, the purpose here is to add some nodes for preprocessing to the model and change the input format to NHWC-BGR-Byte.
Overview
- Create an ONNX model that only preprocesses and convert it to text format
- Convert the original ONNX model to text format
- Put the two together in a text editor and then convert it to binary format
1. Create an ONNX model that only preprocesses and convert it to text format
Create a model with any framework and export it in ONNX format. Here, we use PyTorch.
import torch
# Model definition
class PreprocessModel(torch.nn.Module):
def forward(self, x):
# BRG to RGB
x = x[:,:,:,[2, 1, 0]]
# NHWC to NCHW, Byte to float, [0, 255] to [0, 1]
x = x.permute(0,3,1,2).float() / 255.
# Output [1,256,256,3] RGB float
return x
# Input shape definition
batch_size = 1
height = 256
width = 256
channel = 3
# I/O names definition
input_names = ["inputByteArray"]
output_names = ['outputFloatArray']
# ONNX file name definition
onnx_file_name = "Preprocess{}x{}x{}xBGRxByte.onnx".format(batch_size, height, width)
# Export ONNX model
cpu = torch.device("cpu")
model = PreprocessModel().to(cpu)
x = torch.randn((batch_size, height, width, channel)).byte().to(cpu)
torch.onnx.export(model,
x,
onnx_file_name,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=input_names,
output_names=output_names
)
print('Onnx model exporting done')
This generates Preprocess1x256x256xBGRxByte.onnx, which is the model that only preprocesses.
Let's check it on Netron.

"Gather" corresponds to the conversion from BGR to RGB. (x = x[:,:,:,[2, 1, 0]])
"Transpose" corresponds to the conversion from NHWC to NCHW. (x = x.permute(0,3,1,2))
"Cast" corresponds to the cast from Byte to Float. Div is division.
Now let's convert this model to text format.
protoc --decode onnx.ModelProto onnx.proto < Preprocess1x256x256xBGRxByte.onnx > Preprocess1x256x256xBGRxByte.txt
Executing the above will generatePreprocess1x256x256xBGRxByte.txt. It's a little long, but I'll post the full text.
ir_version: 6
producer_name: "pytorch"
producer_version: "1.7"
graph {
node {
output: "1"
name: "Constant_0"
op_type: "Constant"
attribute {
name: "value"
t {
dims: 3
data_type: 7
raw_data: "\002\000\000\000\000\000\000\000\001\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"
}
type: TENSOR
}
}
node {
input: "inputByteArray"
input: "1"
output: "2"
name: "Gather_1"
op_type: "Gather"
attribute {
name: "axis"
i: 3
type: INT
}
}
node {
input: "2"
output: "3"
name: "Transpose_2"
op_type: "Transpose"
attribute {
name: "perm"
ints: 0
ints: 3
ints: 1
ints: 2
type: INTS
}
}
node {
input: "3"
output: "4"
name: "Cast_3"
op_type: "Cast"
attribute {
name: "to"
i: 1
type: INT
}
}
node {
output: "5"
name: "Constant_4"
op_type: "Constant"
attribute {
name: "value"
t {
data_type: 1
raw_data: "\000\000\177C"
}
type: TENSOR
}
}
node {
input: "4"
input: "5"
output: "outputFloatArray"
name: "Div_5"
op_type: "Div"
}
name: "torch-jit-export"
input {
name: "inputByteArray"
type {
tensor_type {
elem_type: 2
shape {
dim {
dim_value: 1
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
dim {
dim_value: 3
}
}
}
}
}
output {
name: "outputFloatArray"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_value: 1
}
dim {
dim_value: 3
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
}
}
}
}
}
opset_import {
version: 11
}
Now let's take a closer look.
You can see that the main part is defined in graph {}, which contains the elements node {}, input {}, and output {}. Be careful not to confuse the input and output in node {}.
First, looking at graph {input {}} and graph {output {}}, you can easily guess that these are the I/O definitions for this model. Also, since these elem_type are different, you can guess that they are the definitions of byte type and float type.
Next, let's take a look at the second node {}.
node {
input: "inputByteArray"
input: "1"
output: "2"
name: "Gather_1"
op_type: "Gather"
attribute {
name: "axis"
i: 3
type: INT
}
}
There are two input, "inputByteArray" and "1". You can see that the former specifies the previous graph {input {}}. So what about the latter?
Now let's take a look at the first node {}.
node {
output: "1"
name: "Constant_0"
op_type: "Constant"
attribute {
name: "value"
t {
dims: 3
data_type: 7
raw_data: "\002\000\000\000\000\000\000\000\001\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"
}
type: TENSOR
}
}
It says output: "1". Apparently, this node outputs the result with the name "1". The second node {} receives this as input: "1".
Finally, let's take a look at the sixth node {}.
node {
input: "4"
input: "5"
output: "outputFloatArray"
name: "Div_5"
op_type: "Div"
}
You can see that this node takes inputs named "4" and "5" and outputs the result with the name "outputFloatArray". You can see that this output name matches the name of graph {output {}} and this is the output of this model itself.
Now you have a rough idea of how ONNX is represented in text format.
2. Convert the original ONNX model to text format
Let's say you have something called SupreCoolNet.onnx.
Just following the conversion method above:
protoc --decode onnx.ModelProto onnx.proto < SupreCoolNet.onnx > SupreCoolNet.txt
3. Put the two together in a text editor and then convert it to binary format
Overwrite input
Let's assumed that the input of SupreCoolNet.txt is as follows.
input {
name: "input_1"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_param: 1
}
dim {
dim_value: 3
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
}
}
}
}
Make a note of the name of this original input, input_1".
After making a note, we no longer need the definition of this input. Let's overwrite it with the input definition of the ONNX model that only preprocesses.
input {
name: "inputByteArray"
type {
tensor_type {
elem_type: 2
shape {
dim {
dim_value: 1
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
dim {
dim_value: 3
}
}
}
}
}
Add nodes required for preprocessing
Copy all the node {} of the ONNX model that only preprocesses and add them inside the graph {} of SupreCoolNet.txt.
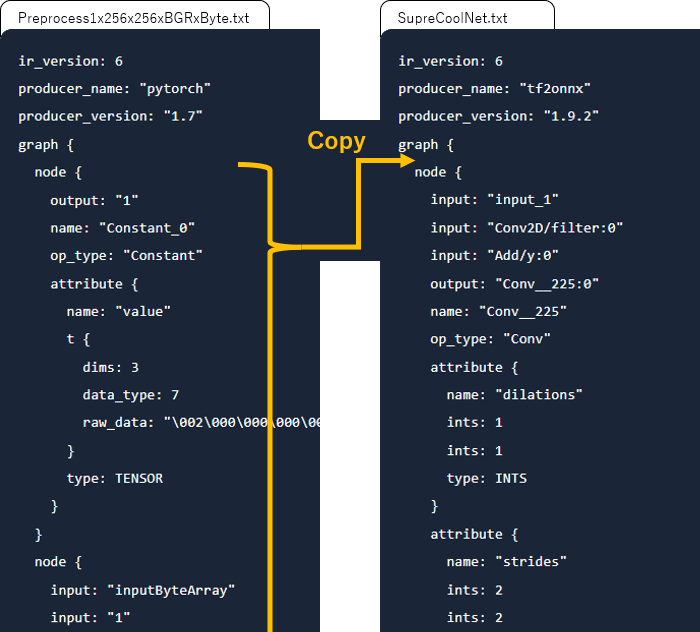
Correct the output name of the last node of preprocessing
Change the name of output of the last node {} of preprocessing to the name of the original input of the model. In this example, it is input_1".
node {
input: "4"
input: "5"
output: "input_1"
name: "Div_5"
op_type: "Div"
}
Finally, save this and convert it back to binary format.
protoc --encode onnx.ModelProto onnx.proto < SupreCoolNet.txt > SupreCoolNet_1x256x256x3xBGRxByte.onnx
Remarks
If you want to use ONNX on Unreal Engine, see our plugin.
Discussion