ONNXファイルをテキスト形式に変換して直接編集する
やりたいこと
ONNX形式のファイルが手元にあって、ちょっとだけ直したい。できるだけ手軽に。
目的は、
- Model Zoo等から入手したONNXファイルの、入出力の形式を変更したい(floatじゃなくてbyteにしたいとか)
- ONNXファイルA の出力がそのまま ONNXファイルB の入力になるので、2つをくっつけたい
等です。
方針
- ONNXファイルを、バイナリ形式からテキスト形式に変換する
- 適当なテキストエディタで編集する
- テキスト形式からバイナリ形式に戻す
バイナリ形式⇔テキスト形式の相互変換方法さえわかればできたも同然です。
準備
Protocol Buffer Compilerのダウンロード
バイナリ形式⇔テキスト形式の変換にはProtocol Buffer Compilerを使います。というのも、そもそもONNXファイルはProtocol Bufferを使って定義された形式だからです。
まずは、Protocol BufferのリリースページからProtocol Buffer Compilerのビルド済みファイルをダウンロードしましょう。Windows向けはこれです。
ダウンロードできたら圧縮ファイルを展開します。展開してできた「protoc-X.Y.Z-win64\bin」(XYZはバージョン番号) をパスに追加しておくと便利です。
onnx.protoファイルのダウンロード
ONNXの公式GitHubから、onnx.protoをダウンロードしましょう。
onnx.protoは、ONNX形式の定義が書かれたファイルです。これとProtocol Buffer Compilerがあれば、ONNXファイルを解釈することができるというしろものです。
実行方法
バイナリ形式⇔テキスト形式の相互変換
コマンドプロンプトを開いて、下記を入力します。
-
バイナリ形式 → テキスト形式
protoc --decode onnx.ModelProto onnx.proto < SrcBinaryFile.onnx > DstTextFile.txt -
テキスト形式 → バイナリ形式
protoc --encode onnx.ModelProto onnx.proto < SrcTextFile.txt > DstBinaryFile.onnx
ここで、
- protoc:ダウンロードして展開した「protoc-X.Y.Z-win64\bin\protoc.exe」のパス
- onnx.proto:ダウンロードした「onnx.proto」のパス
- SrcBinaryFile.onnx:変換元のONNXファイルのパス
- DstTextFile.txt:変換後のテキストファイルの書き込み先のパス
- SrcTextFile.txt:変換元のテキストファイルのパス
- DstBinaryFile.onnx:変換後のONNXファイルの書き込み先のパス
です。
うまくいかないときは、ファイルパスがまちがっていないか確認しましょう。めんどうくさければ全部同じフォルダにぶちこみましょう。
テキスト形式での編集
いくつかのONNXファイルについて、「変換後のテキストファイル.txt」をながめつつ、Netron等を使って「変換元のONNXファイル.onnx」と見比べると、何が書いてあるかは大体わかります。
以上
具体例: モデルの入力を NCHW・RGB・float から NHWC・BGR・Byte に変更する
ここからは具体例を紹介します。
OpenCVを使っていると、画像をNHWC・BGR・Byteの配列として扱うことが多いです。
一方、公開されている機械学習モデルではNCHW・RGB・floatの配列が入力として定義されていることがよくあります。
ので、いちいち前処理が必要でめんどうです。特に、複数のモデルを使ったプログラムを書いている場合、前処理に統一性がないとストレスフルかつバグの元になったりします。
そこで、前処理もモデルの中に入れてしまい、入力をNHWC・BGR・Byteの配列にしてしまおうというのがここでの趣旨です。
方針
- 前処理だけを行うONNXモデルを作り、テキスト形式に変換する
- 元のONNXモデルをテキスト形式に変換する
- 二つをテキストエディタ上でくっつけたのち、バイナリ形式に戻す
1. 前処理だけを行うONNXモデルを作り、テキスト形式に変換する
適当なフレームワークでモデルを作成し、ONNX形式でエクスポートします。ここではPyTorchを使います。
import torch
# Model definition
class PreprocessModel(torch.nn.Module):
def forward(self, x):
# BRG to RGB
x = x[:,:,:,[2, 1, 0]]
# NHWC to NCHW, Byte to float, [0, 255] to [0, 1]
x = x.permute(0,3,1,2).float() / 255.
# Output [1,256,256,3] RGB float
return x
# Input shape definition
batch_size = 1
height = 256
width = 256
channel = 3
# I/O names definition
input_names = ["inputByteArray"]
output_names = ['outputFloatArray']
# ONNX file name definition
onnx_file_name = "Preprocess{}x{}x{}xBGRxByte.onnx".format(batch_size, height, width)
# Export ONNX model
cpu = torch.device("cpu")
model = PreprocessModel().to(cpu)
x = torch.randn((batch_size, height, width, channel)).byte().to(cpu)
torch.onnx.export(model,
x,
onnx_file_name,
export_params=True,
opset_version=11,
do_constant_folding=True,
input_names=input_names,
output_names=output_names
)
print('Onnx model exporting done')
これを実行するとPreprocess1x256x256xBGRxByte.onnxというファイルが生成されます。これが前処理だけを行うONNXモデルです。
試しにNetronで見てみましょう。

最初のGatherは、BGRからRGBの変換(x = x[:,:,:,[2, 1, 0]])に相当します。
Transposeは行列の転置ですね。NHWCからNCHWの変換(x = x.permute(0,3,1,2))に相当します。
CastはByteからFloatへのキャスト、Divは割り算ですね。ちゃんとできていそうです。
なお、詳細な演算の定義はこちらに記載されています。
では、このモデルをテキスト形式に変換してみましょう。
protoc --decode onnx.ModelProto onnx.proto < Preprocess1x256x256xBGRxByte.onnx > Preprocess1x256x256xBGRxByte.txt
上記を実行するとPreprocess1x256x256xBGRxByte.txtが生成されます。少し長いですが全文を載せておきます。
ir_version: 6
producer_name: "pytorch"
producer_version: "1.7"
graph {
node {
output: "1"
name: "Constant_0"
op_type: "Constant"
attribute {
name: "value"
t {
dims: 3
data_type: 7
raw_data: "\002\000\000\000\000\000\000\000\001\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"
}
type: TENSOR
}
}
node {
input: "inputByteArray"
input: "1"
output: "2"
name: "Gather_1"
op_type: "Gather"
attribute {
name: "axis"
i: 3
type: INT
}
}
node {
input: "2"
output: "3"
name: "Transpose_2"
op_type: "Transpose"
attribute {
name: "perm"
ints: 0
ints: 3
ints: 1
ints: 2
type: INTS
}
}
node {
input: "3"
output: "4"
name: "Cast_3"
op_type: "Cast"
attribute {
name: "to"
i: 1
type: INT
}
}
node {
output: "5"
name: "Constant_4"
op_type: "Constant"
attribute {
name: "value"
t {
data_type: 1
raw_data: "\000\000\177C"
}
type: TENSOR
}
}
node {
input: "4"
input: "5"
output: "outputFloatArray"
name: "Div_5"
op_type: "Div"
}
name: "torch-jit-export"
input {
name: "inputByteArray"
type {
tensor_type {
elem_type: 2
shape {
dim {
dim_value: 1
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
dim {
dim_value: 3
}
}
}
}
}
output {
name: "outputFloatArray"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_value: 1
}
dim {
dim_value: 3
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
}
}
}
}
}
opset_import {
version: 11
}
ここで、中身を少し詳しく見ておきましょう。
主要部分はgraph {}の中で定義されていて、その中にはnode {}、input {}、output {} という要素があることがわかります。node {}の中にもinput、outputという要素があるので混同しないように注意してください。
まず、graph { input {} } とgraph { output {} } を見てみると、これらがこのモデルの入出力の定義であることが容易に推測できます。また、これらの elem_type が異なることから、これらがByte型とFloat型の定義であることも推測できます。
次に、二つ目の node {} を見てみましょう。
node {
input: "inputByteArray"
input: "1"
output: "2"
name: "Gather_1"
op_type: "Gather"
attribute {
name: "axis"
i: 3
type: INT
}
}
inputが二つあって、"inputByteArray"および"1"となっています。前者は、先の graph { input {} } を指定しているものとわかります。では後者は?
ここで、一つ目の node {} を見てみましょう。
node {
output: "1"
name: "Constant_0"
op_type: "Constant"
attribute {
name: "value"
t {
dims: 3
data_type: 7
raw_data: "\002\000\000\000\000\000\000\000\001\000\000\000\000\000\000\000\000\000\000\000\000\000\000\000"
}
type: TENSOR
}
}
output: "1"となっています。どうやら、このノードは"1"という名前で結果を出力しているようです。これを二つ目の node {} がinput: "1"で受け取っているというわけですね。
最後に、6番目の node {} を見てみましょう。
node {
input: "4"
input: "5"
output: "outputFloatArray"
name: "Div_5"
op_type: "Div"
}
このノードは"4"と"5"という名前の入力を受け取り、結果を"outputFloatArray"という名前で出力していることがわかります。この出力名はgraph { output {} } の名前と一致しており、このモデル自体の出力につながっているとわかります。
これで、ONNXがテキスト形式でどう表されるか大体おわかりいただけたかと思います。
2. 元のONNXモデルをテキスト形式に変換する
ここでは仮に SupreCoolNet.onnx というものがあるとします。先の変換方法の通りに変換しましょう。
protoc --decode onnx.ModelProto onnx.proto < SupreCoolNet.onnx > SupreCoolNet.txt
3. 二つをテキストエディタ上でくっつけたのち、バイナリ形式に戻す
入力定義の上書き
SupreCoolNet.txtの入力は以下にようになっているものとします。
input {
name: "input_1"
type {
tensor_type {
elem_type: 1
shape {
dim {
dim_param: 1
}
dim {
dim_value: 3
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
}
}
}
}
この元の入力の名前"input_1"はメモしておきましょう。
メモしたらこの入力の定義は用済みです。前処理だけを行うONNXモデルの入力の定義で上書きしてしまいましょう。
input {
name: "inputByteArray"
type {
tensor_type {
elem_type: 2
shape {
dim {
dim_value: 1
}
dim {
dim_value: 256
}
dim {
dim_value: 256
}
dim {
dim_value: 3
}
}
}
}
}
前処理に必要なnodeの追加
前処理だけを行うONNXモデルの node {} を全部コピーして、SupreCoolNet.txtのgraph {}の中に追加します。
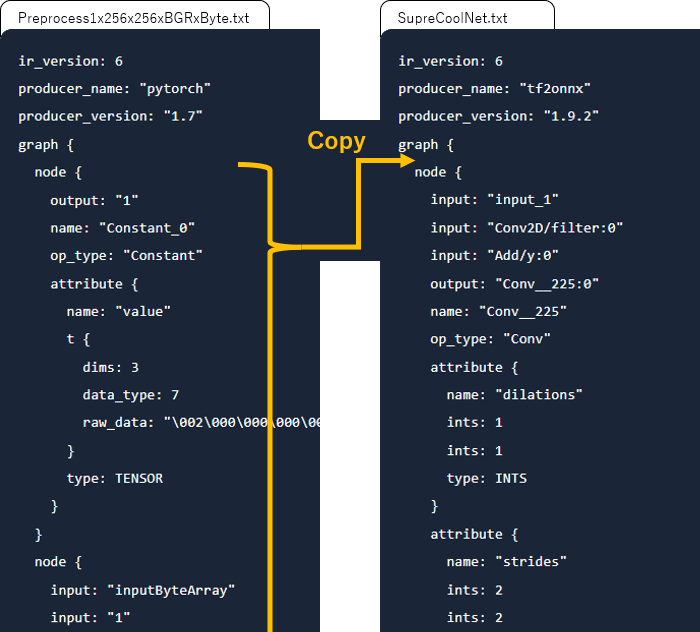
前処理の最後の node の 出力名の修正
前処理の最後の node {} のoutputの名前をモデル本来の入力の名前に直してやります。今回なら"input_1"です。
node {
input: "4"
input: "5"
output: "input_1"
name: "Div_5"
op_type: "Div"
}
あとはこれを保存して、バイナリ形式に戻してやれば完成です。
protoc --encode onnx.ModelProto onnx.proto < SupreCoolNet.txt > SupreCoolNet_1x256x256x3xBGRxByte.onnx
最後に
Unreal EngineでONNXを使うためのプラグインを公開しています。
Discussion