KiroのSpecモードで保守可能なツールの作成
はじめに
ちょっとしたツールを作成したけどREADMEを作成しておらず、誰かに連携が必要になったときに意外と時間を要してしまうのって結構あると思います。また、AWSアカウントをまたいでの連携となると何らかのIaCを用いていないと結構手間だったりします。
そんなときにKiroのSpecモードを活用することで保守性の高いツールを作成できるのでは?と考えたので試してみました。
Kiroとは
KiroはAWSが発表しているAI IDEで、仕様駆動開発ができることが特徴となっています。
現在はPREVIEW版として公開されており、ウェイトリストに登録することで利用可能となっています。
※ Kiroについてや、仕様駆動開発については参考になる記事が多数出ておりますのでそちらを参考にしてください。
仕様駆動開発とは
KiroのSpecモードでは実装にあたって以下の3つのファイルを作成します。
(以下 Concepts - Docs - Kiro を参照)
‐ requirements.md : ユーザーストーリーと受け入れ基準を構造化されたEARS(Easy Approach to Requirements Syntax)記法で記述
‐ design.md : 技術アーキテクチャ、シーケンス図、実装上の考慮事項を文書化
‐ tasks.md : 離散的で追跡可能なタスクを含む詳細な実装計画を提供
ファイル構成としては以下のようなイメージになります。

公式ドキュメントより抜粋
実装のフローは以下のようなイメージになります。

公式ドキュメントより抜粋
作成
作成するツール
今回はLambdaを用いたシンプルなETLツールを作成してみます。S3バケットへの格納をトリガーとして、Lambdaでデータを取得してCSVを処理してS3バケットに格納するツールです。
今回求める機能としては以下があります。
- CSVのすべてのデータを
"で囲う(あああ → "あああ" へ変換) - 空文字を0埋めする(あああ,,, → "あああ","0","0","0" へ変換)
- CSVデータ以外に対しては動作しない
イメージとしてはちょっとした数値データをCSV形式で取り込みやすいように変換するツールです。
Requirements Phase
ここから実際に作成を進めていきます。
まず、はじめに作成したいツールの内容をざっくりと記述しKiroに解釈してもらいます。

要件をチャットで入力
AWS Lambdaを用いてCSVデータを処理するツールを作成したいです。
必要な機能は以下のとおりです。
- CSVのすべてのデータを`"`で囲う
- 空文字を0埋めする
実行はS3へのファイル格納をトリガーとして、CSVのみに対して実行したいです。
処理を開始すると、.kiro/specs/csv-data-processor(機能名)/requirements.md が作成されここに要件が記載されます。
最終的なrequirements.md
# 要件定義書
## 概要
AWS LambdaとS3を使用してCSVファイルを自動処理するツールです。S3にCSVファイルがアップロードされると自動的にトリガーされ、データの正規化処理(引用符の追加と空文字の0埋め)を行います。
## 要件
### 要件1
**ユーザーストーリー:** データ管理者として、S3にアップロードされたCSVファイルが自動的に処理されることで、すべてのデータが適切にフォーマットされ標準化されることを望む。
#### 受け入れ基準
1. 指定されたS3バケットにCSVファイルがアップロードされた時、Lambda関数が自動的にトリガーされること
2. Lambda関数がトリガーされた時、.csv拡張子のファイルのみを処理すること
3. CSV以外のファイルがアップロードされた時、Lambda関数はそのファイルを無視し処理しないこと
### 要件2
**ユーザーストーリー:** データアナリストとして、CSVデータのすべてのフィールドがダブルクォートで囲まれることで、処理中のデータ整合性が保たれることを望む。
#### 受け入れ基準
1. CSVファイルを処理する時、システムはすべてのデータフィールドをダブルクォート(")で囲むこと
2. フィールドに既にダブルクォートが含まれている時、システムはクォートを二重化("")して適切にエスケープすること
3. 処理完了時、すべてのフィールドがダブルクォートで一貫してフォーマットされていること
### 要件3
**ユーザーストーリー:** データアナリストとして、CSVファイルの空のフィールドがゼロで埋められることで、データ分析ツールがnull値エラーなしにデータを処理できることを望む。
#### 受け入れ基準
1. システムが空のフィールドに遭遇した時、それを"0"に置き換えること
2. システムが空白文字のみのフィールドに遭遇した時、それを"0"に置き換えること
3. 数値フィールドを処理する時、空の値は"0"に置き換えられること
### 要件4
**ユーザーストーリー:** システム管理者として、処理されたCSVファイルがS3に保存されることで、処理済みデータが下流システムで利用可能になることを望む。
#### 受け入れ基準
1. 処理完了時、システムは処理済みCSVを同じS3バケットに保存すること
2. 処理済みファイルを保存する時、システムは処理済みであることを示す命名規則を使用すること(例:「_processed」サフィックスの追加)
3. 保存に失敗した時、システムはエラーをログに記録し、元のファイルを削除しないこと
### 要件5
**ユーザーストーリー:** システム管理者として、適切なエラーハンドリングとログ機能により、処理パイプラインの監視とトラブルシューティングができることを望む。
#### 受け入れ基準
1. 処理中にエラーが発生した時、システムは詳細なエラー情報をログに記録すること
2. 処理開始時、システムは処理対象ファイルをログに記録すること
3. 処理が正常完了した時、システムは完了ステータスをログに記録すること
4. CSVファイルが不正な形式の時、システムはエラーをログに記録し処理をスキップすること
内容に問題がなければ Move to design phase から次に進みます。
修正点があればチャットから修正を依頼できます。今回は機能内容の調整とドキュメントの日本語化を行いました。
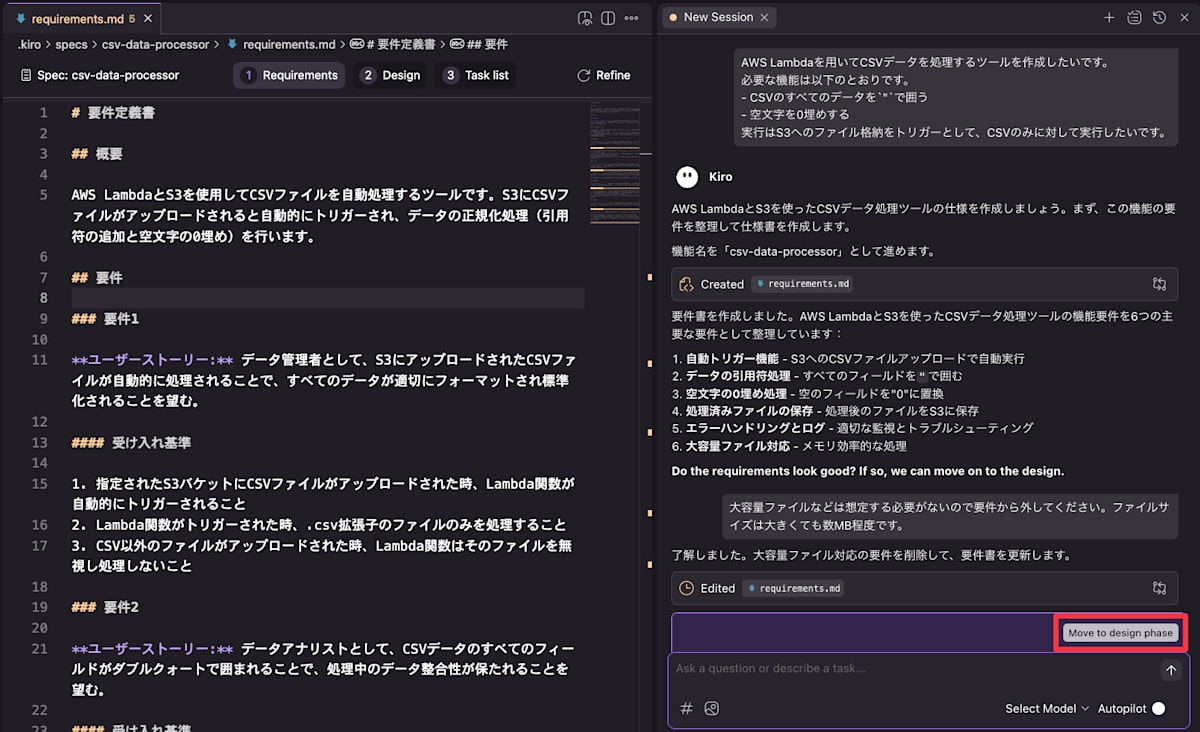
問題がなければ Move to design phase へ
Design Phase
続いて .kiro/specs/csv-data-processor/design.md が作成されより詳細な実装が記載されます。ここでもチャットで修正を加えていくことができるため、Pythonの3.10を利用すること、CloudFormationのテンプレートを作成することを追加で指示しました。
最終的なdesign.mdは以下のようになりました。
最終的なdesign.md
設計書
概要
AWS LambdaとS3を使用したCSVデータ処理システムの設計です。S3イベント通知をトリガーとして、CSVファイルの自動処理を行います。処理内容は全フィールドのダブルクォート囲み、空文字の0埋めです。
アーキテクチャ
システム構成
主要コンポーネント
- S3 Bucket: CSVファイルの格納とイベント通知の発生源
- Lambda Function: メイン処理ロジックを実行
- CSV Processor: CSVデータの変換処理を担当
- CloudWatch Logs: ログとモニタリング
コンポーネントとインターフェース
Lambda Function Handler
責任: S3イベントの受信とメイン処理フローの制御
インターフェース:
- 入力: S3イベント通知(JSON)
- 出力: 処理結果ステータス
主要メソッド:
-
lambda_handler(event, context): メインエントリーポイント -
validate_event(event): イベントの妥当性検証 -
extract_s3_info(event): S3バケット名とオブジェクトキーの抽出
CSV Processor
責任: CSVデータの読み込み、変換、書き込み
インターフェース:
- 入力: S3オブジェクト情報(バケット名、キー)
- 出力: 処理済みCSVファイル
主要メソッド:
-
read_csv_from_s3(bucket, key): S3からCSVデータを読み込み -
process_csv_data(csv_content): CSVデータの変換処理 -
write_csv_to_s3(bucket, key, processed_data): 処理済みデータをS3に書き込み
Data Transformer
責任: CSVフィールドの具体的な変換処理
主要メソッド:
-
quote_fields(row): 各フィールドをダブルクォートで囲む -
fill_empty_fields(row): 空フィールドを"0"で埋める -
escape_quotes(field): 既存のクォートをエスケープ
データモデル
S3イベント構造
{
"Records": [
{
"s3": {
"bucket": {
"name": "bucket-name"
},
"object": {
"key": "file.csv"
}
}
}
]
}
CSVデータ変換例
変換前:
name,age,city
John,25,Tokyo
Jane,,Osaka
Bob,30,
変換後:
"name","age","city"
"John","25","Tokyo"
"Jane","0","Osaka"
"Bob","30","0"
エラーハンドリング
エラー分類と対応
-
ファイル形式エラー
- 非CSVファイル: 処理をスキップ、ログ出力
- 不正なCSV形式: エラーログ出力、処理中断
-
S3アクセスエラー
- 読み込み失敗: リトライ機構、エラーログ
- 書き込み失敗: エラーログ、元ファイル保持
-
Lambda実行エラー
- メモリ不足: エラーログ、処理中断
- タイムアウト: エラーログ、部分処理状況の記録
ログ出力仕様
- INFO: 処理開始、完了、ファイル情報
- WARNING: 非CSVファイルのスキップ
- ERROR: 処理失敗、S3アクセスエラー
テスト戦略
単体テスト
-
CSV変換ロジック
- 正常なCSVデータの変換
- 空フィールドの0埋め
- クォートエスケープ処理
-
S3操作
- ファイル読み込み
- ファイル書き込み
- エラーハンドリング
統合テスト
-
エンドツーエンドテスト
- S3アップロード → Lambda実行 → 処理済みファイル確認
- 各種エラーケースの動作確認
-
パフォーマンステスト
- 数MBサイズのCSVファイル処理
- 同時実行時の動作確認
実装技術選択
プログラミング言語
- Python 3.10: AWS Lambdaでの標準的な選択、CSV処理ライブラリが豊富
主要ライブラリ
- boto3: AWS SDK、S3操作
- csv: Python標準ライブラリ、CSV処理
- logging: ログ出力
AWS設定
- Lambda Runtime: Python 3.10
- Memory: 256MB(数MBのCSVファイル処理に十分)
- Timeout: 30秒
- S3 Event Notification: ObjectCreated イベント、.csv拡張子フィルター
インフラストラクチャ
CloudFormation構成
テンプレート構造:
- S3バケット(入力・出力用)
- Lambda関数とIAMロール
- S3イベント通知設定
- CloudWatch Logsグループ
パラメータ化:
- バケット名プレフィックス
- Lambda関数名
- メモリサイズ・タイムアウト設定
出力:
- S3バケット名
- Lambda関数ARN
- CloudWatch Logsグループ名
デプロイメント戦略
-
CloudFormationスタック作成
- インフラリソースの一括作成
- パラメータによる環境別設定
-
Lambda関数デプロイ
- ZIPパッケージでのコード配布
- CloudFormationでの関数更新
-
権限設定
- S3バケットへの読み書き権限
- CloudWatch Logsへの書き込み権限
- Lambda実行ロール
内容に問題がなかったので Move to implementation plan から次に進みます。
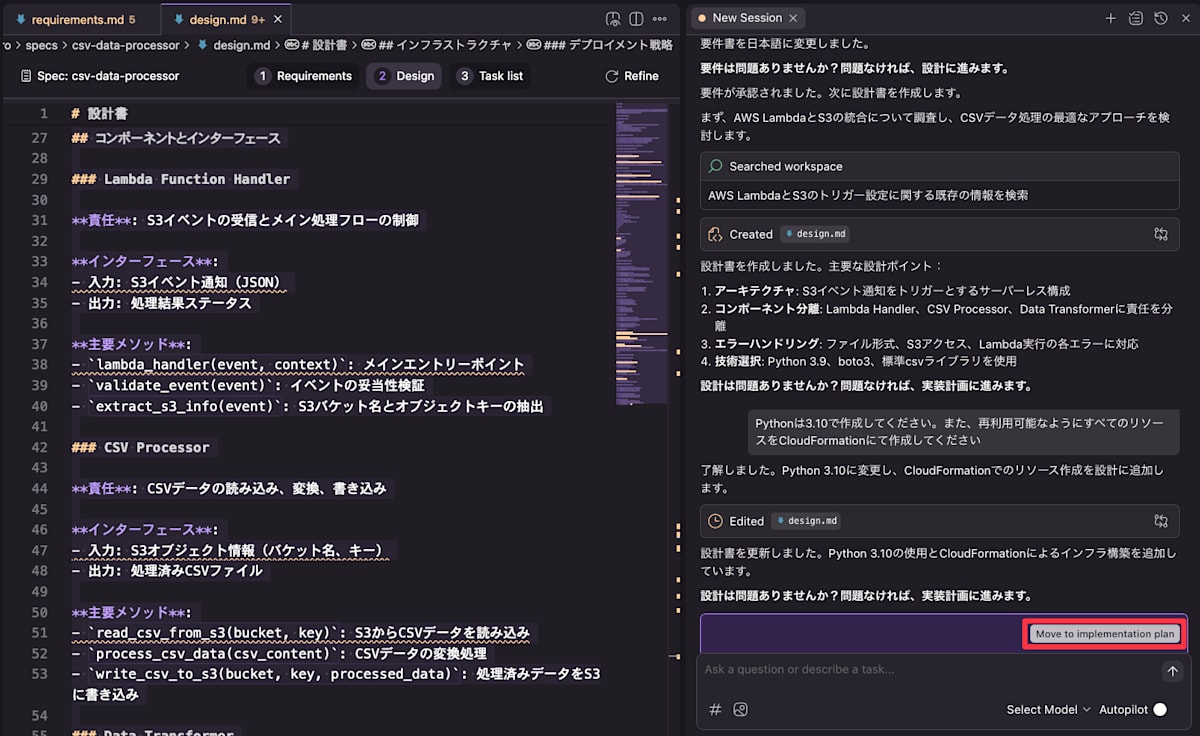
問題がなければ Move to implementation plan へ
Implementation Planning
続いて .kiro/specs/csv-data-processor/tasks.md が作成され実装計画が記載されます。
ここでも内容を修正したければ修正することができます。今回は特に修正を行わず Finalize task list しました。
最終的なtasks.md
# 実装計画
- [ ] 1. プロジェクト構造とコア機能の設定
- ディレクトリ構造の作成(lambda、cloudformation、testsフォルダ)
- requirements.txtファイルの作成(boto3、その他必要なライブラリ)
- _要件: 1.1, 1.2_
- [ ] 2. CSVデータ変換機能の実装
- [ ] 2.1 データ変換クラスの作成
- DataTransformerクラスの実装(フィールドのクォート囲み、空文字の0埋め機能)
- クォートエスケープ処理の実装
- _要件: 2.1, 2.2, 3.1, 3.2_
- [ ] 2.2 データ変換機能の単体テスト作成
- 正常なCSVデータの変換テスト
- 空フィールドの0埋めテスト
- 既存クォートのエスケープテスト
- _要件: 2.3, 3.3_
- [ ] 3. CSV処理機能の実装
- [ ] 3.1 CSVプロセッサクラスの作成
- CSVProcessorクラスの実装(S3からの読み込み、データ変換、S3への書き込み)
- 処理済みファイル名の生成機能(_processedサフィックス)
- _要件: 4.1, 4.2_
- [ ] 3.2 CSV処理機能の単体テスト作成
- S3からのCSV読み込みテスト(モック使用)
- データ変換処理のテスト
- S3への書き込みテスト(モック使用)
- _要件: 4.1, 4.2, 4.3_
- [ ] 4. Lambda関数ハンドラーの実装
- [ ] 4.1 メインハンドラー関数の作成
- lambda_handler関数の実装(S3イベント受信、処理フロー制御)
- S3イベントの妥当性検証機能
- バケット名とオブジェクトキーの抽出機能
- _要件: 1.1, 1.3_
- [ ] 4.2 エラーハンドリングとログ機能の実装
- 詳細なエラーログ出力機能
- 処理開始・完了ログの実装
- 非CSVファイルのスキップ処理
- _要件: 5.1, 5.2, 5.3, 5.4_
- [ ] 4.3 Lambda関数の単体テスト作成
- S3イベント処理のテスト
- エラーハンドリングのテスト
- ログ出力のテスト
- _要件: 1.2, 1.3, 5.1, 5.4_
- [ ] 5. CloudFormationテンプレートの作成
- [ ] 5.1 インフラリソースの定義
- S3バケットリソースの定義
- Lambda関数とIAMロールの定義
- CloudWatch Logsグループの定義
- _要件: 1.1, 4.1, 5.2_
- [ ] 5.2 S3イベント通知の設定
- S3バケットのイベント通知設定(ObjectCreated、.csvフィルター)
- Lambda関数への権限付与
- _要件: 1.1, 1.2_
- [ ] 5.3 パラメータと出力の定義
- CloudFormationパラメータの定義(バケット名プレフィックス等)
- 出力値の定義(バケット名、Lambda ARN等)
- _要件: 4.1_
- [ ] 6. 統合テストとデプロイメント準備
- [ ] 6.1 デプロイメントスクリプトの作成
- Lambda関数のZIPパッケージ作成スクリプト
- CloudFormationスタックのデプロイスクリプト
- _要件: 4.1_
- [ ] 6.2 エンドツーエンドテストの作成
- 実際のS3アップロードから処理完了までのテスト
- 各種エラーケースの統合テスト
- _要件: 1.1, 2.1, 3.1, 4.1, 5.1_
Execution Phase
tasks.mdの実装計画を1つ1つ進めて行くことで実装されます。

実装計画を1つ1つ進めて行く
実装が完了するとディレクトリ構造が作成されたほか、requirements.txtが作成されます。
どちらも想定されていたタスク通りの実行です。

計画通りにファイル構造とrequirements.txtが作成される
以降同様に繰り返します。
無事に最後まで構築できました!

デプロイ
作成されたデプロイ手順にしたがってデプロイを実行してみます。
今回はローカルから以下のコマンドでデプロイしました。
./scripts/deploy_all.sh -r ap-northeast-1 -f kiro-csv-processor
残念ながら循環参照があり1度でのデプロイはできませんでしたが、エラー内容を連携することで直ぐに修正を実行してくれました。

循環参照があるためデプロイに失敗しました

エラー内容を連携することで直ぐに修正を実行してくれる
デプロイが完了したのでテストしてみます。

無事にデプロイが完了しました
以下のようなCSVファイルを作成してS3にアップロードしてみます。
name,age,city
John,25,Tokyo
Jane,,Osaka
Bob,30,

CSVのアップロード
無事に変換されてS3にアップロードされました。

変換前後のCSVファイル
まとめ
KiroのSpecモードを活用することで、短時間で簡単なツールを作成することができました。
今回は案件での利用ではないものの、しっかりとしたドキュメントを残しつつ進めることができたので作業自体に安心感もありました。
生成AI系のツールでお任せで作ってしまうとできてしまってから思ったのと違うということが多々ありますが、仕様を固めてからの実装となるので仕様駆動開発が行えるKiroのSpecモードは非常に有用だと感じました。
一方で、実装方法などまだまだ人間が確認するべきポイントは存在するので依存しすぎずに利用することが重要であると感じました。
実際に案件で利用する場合にメンバーとどう協力するかなど検討事項はありますが、特別なプロンプトなどを用いなくても順に進めるだけでもドキュメンテーション化されていくのでこれからAIを活用した開発案件を始めようとしている人とも相性がいいのかなと感じることもできました。
Discussion