🤔
Goで「どの画像が似てるか」をグルーピングするツールを作った
この記事について
-
Umeda.go 2022 Spring で話した
「似ている画像を総当りで調べるのに色々工夫した話」の加筆記事になります
ツール
仕様
- 特定フォルダ以下にある画像を全て比較
- jpeg、pngを対象 (zipの中にあるものも含む)
- 似ている画像をグルーピングしてjsonに出力
どうやって「似ている画像」を判定する?
- 画像専用のハッシュを計算して比較します
- md5やsha256など、一般的なハッシュ関数だと
少しの違いでも全く違う値になります - 画像専用のハッシュでは
少しの違いなら「同じ or 似ている値」になります - これなら「解像度違い」「ロゴが入ってるだけの違い」なども判定できます
- この技術自体、解説されてるサイトやブログはいくつかありますが
Perceptual Hashを使って画像の類似度を計算してみる - ユニファ開発者ブログ
がわかりやすいと思うので掲載しておきます
「似ている」という判定
- いずれの画像ハッシュ法でもやることは同じで、以下をやるだけです
- 同じ画像ハッシュ法でImageAとImageBそれぞれのハッシュ値を計算
- 2つのハッシュ値を排他的論理和(XOR)を計算
-
似ている= (立っているbit数<=しきい値)
具体例
- ハッシュ長:
32bitしきい値:2以下なら似ていると判断する場合
| --- | 画像ハッシュ値(2進数) |
|---|---|
| ImageA | 00011100011100000000000000000011 |
| ImageB | 00011100011001010100000000000111 |
| 排他的論理和(XOR)の結果 | 00000000000101010100000000000100 |
上記の場合立っているbit数:5 で しきい値:2 よりも大きいので
「似ていない」と判断できます
「Go言語なら手軽にやれそうと思った」理由
標準パッケージで色々賄える
- 下記に述べてる通り、標準パッケージでサポートしている内容が豊富です
- 少なくとも今回の用途なら十分標準パッケージの実装で賄えます
「png」「jpeg」画像は標準パッケージでサポート
-
image.RegisterFormatに従えば扱う画像の種類も容易に増やせます- やる予定ないですが「tga」「dds」とかも対応フォーマットに入れることができます
「zip」を標準パッケージでサポート
- 解凍せずにzip内にあるデータを開くことができます
- GooglePhotoから一気にダウンロードするとzipになるのでいちいち解凍する必要がないです
「json」を標準パッケージでサポート
- 結果の読み書きが容易です
- 速度やフォーマットにこだわりがなければjson書き込みが楽です
並行(並列)処理が書きやすい
- goroutineとchannelを使用すれば、たくさんの画像データを一気に読むことができます
- 読み込みもストリーミング対応してるので、正しく扱えば消費メモリも増えにくいです
- とは言え定期的にGCが走ってるなと言うのをタスクマネージャーから見ることはできます
すでに画像ハッシュを扱うパッケージも存在する
- 今回使用したのは https://github.com/corona10/goimagehash です
Tips:goimagehashのいいところ
複数の画像ハッシュアルゴリズムに対応している
- 2022/07/20時点で以下に対応してるのでだいたい困ることはないです
- Average hash (aHash)
- Difference hash (dHash)
- Perception hash (pHash)
データのシリアライズ・デシリアライズに対応してる
- 大量の画像を扱った時、どうしても読み込み速度に悩まされます
- 「大量に画像を読み込んで、画像ハッシュ情報を一時ファイルに保存して後で利用したい」
と言った要望に対応できるような作りになっています - 今回作成したツールでもまさにこういう用途がありました
- 比較アルゴリズムの実装に注力したかった
-
一度バイナリデータをbase64に変換し直して、そのbase64の文字列データをjsonに保存する
ことでそれを叶えることができました
実コードは以下になります
今回のサンプルデータ
- 画像ハッシュアルゴリズム:Perceptual Hash(pHash)
- サンプリングは16 x 16
- 理由:時間かかってもいいので正確な結果が欲しかった
- ハッシュ長:64bit * 4
- サンプリングの画像サイズに比例します
- 比較する画像ファイルは637,281ファイル
- 絶妙に切りが悪い数字ですが約63万ファイルと数えます
簡単なツールのアルゴリズム
- 特定のフォルダ以下をfilepath.WalkDirで走査
- 見つけたファイルを「画像ハッシュを計算する関数」に送り続ける
- 画像ハッシュ計算結果受け取りコンテナに溜める
- コンテナに溜まった「画像ハッシュの情報」を総当りで比較しグルーピングする
- 結果をjson書き込み
- 「3」までは比較的容易でした
- Goのお作法に則ってpipeline的に並列処理を書けばできます
- HDDストレージでも約63万ファイルをread速度:75MB/秒で約4時間で処理できました
- 問題は 「4」 です
- ここを考えていく必要があります
「総当たりで比較しグルーピングする」基本アルゴリズム
スライド画像そのままですが貼ります

計算量
- なんの工夫もせず、単純なループ実装を組んでしまうと計算量が 「O(N^2)」 になります
- 要するに以下のようなコードです
for _, a := range container {
for _, b := range container {
// a と bを比較
}
}
計算時間を見積もってみる
まずは簡単なBenchmarkを取ってみます
$ go test -bench .
goos: windows
goarch: amd64
pkg: github.com/akinobufujii/similar_images_grouping
cpu: AMD Ryzen 7 3700X 8-Core Processor
BenchmarkImageHash-16 217176094 5.523 ns/op
PASS
上記の結果が得られたので、画像ハッシュ1回の比較時間は
多く見積もって6ナノ秒ということがわかりました
- 対象ファイル: 約63万ファイル
- 1回の比較計算: 約6ナノ秒
- 何も工夫しない計算オーダー: O(N^2)
実行時間を見積もる
63万 ^ 2 = 396,900,000,000(3,969億)
1ナノ秒=1000億分の1秒
上記2つの値は位が大小のくらいが一致してるのでそのまま秒として計算できます
3,969 * 6 = 23,814秒
= 6.615時間
= 約6時間37分
「最適化しないとめっちゃ時間かかる」 という雰囲気は伝わりましたでしょうか?
なので比較方法を工夫します
高速で総当りに判定するには?
- 「絶対に似ることはないもの」と比較する必要はないので
できるだけ計算をせずにスキップしたいです - 改めてになりますが「似ている」判定は以下です
- 2つのハッシュを排他的論理和を求め
- 「立っているbit数」<=「任意のしきい値」=「似ている」と判断
- 排他的論理和をやる前に
abs(ImageAの立っているbit数 - ImageBの立っているbit数) > しきい値
なら比較する必要はないことが見えてきます - 更に
「立っているビット数」でグルーピングしておけば
一気に計算をスキップできるかもしれません
要するに以下のようなコンテナに要素を突っ込んでいきます
// key: 立っているビット数
// value: 立っているビット数の画像ハッシュ情報配列
type OnesBitKeyImageHashMap map[int]*[]*ImageHashInfo
具体例:ハッシュ長が「32bit」しきい値「2以下」なら「似ている」と判断する場合
| 画像名 | ハッシュ値 |
|---|---|
| ImageA | 00011100011100000000000000000011(8) |
| ImageB | 00011100011001010100000000000111(11) |
8 - 11 の絶対値(abs)は「3」なのですでに 「似てない」 と判断できます
実装結果
-
約2時間20分 かかりました
- 6時間37分の約2.8倍速
- 悪くはないようにみえますがもっと速くしたい
「立っているビット数」がどれくらい種類があるか見てみた
要するに OnesBitKeyImageHashMap のkeyの種類がどれくらいあるかを調べました
下記を見ていただいたら分かる通り、今回の比較する画像は
128ビット立ってるものが非常に多く、かなりの偏りがありました
{
"0": 1825,
"1": 772,
"114": 30,
"120": 1,
"128": 634559,
"15": 12,
"16": 5,
"23": 4,
"3": 26,
"47": 3,
"50": 8,
"55": 6,
"58": 1,
"7": 7,
"8": 9,
"88": 6,
"9": 7
}
ここをもう少し分解できればいい感じに比較をスキップできそうです
64bitごとに「立っているbit数」の種類を出してみる
C言語っぽいですが以下のような感じで64bitごとに「立っているbit数」を数えて
int型変数にシフトしながらエンコード・デコードします
// encodeThresholdBit しきい値のエンコード関数
func encodeThresholdBit(bitlist []uint64) int {
onesCount := 0
for i, data := range bitlist {
onesCount |= bits.OnesCount64(data) << (i * 8)
}
return onesCount
}
// decodeThresholdBit しきい値のデコード関数
func decodeThresholdBit(x int) [4]int8 {
result := [4]int8{}
for i := range result {
result[i] = int8((x >> (i * 8)) & 0x000000ff)
}
return result
}
結果は省略してますが7712種類に分かれました
少なくともさっきよりはいい感じ分かれてるように見えます
{
"0 + 0 + 0 + 0": 1825,
"0 + 0 + 0 + 1": 772,
"0 + 0 + 0 + 16": 1,
"0 + 0 + 0 + 7": 1,
"0 + 0 + 0 + 8": 3,
"0 + 0 + 0 + 9": 7,
"0 + 0 + 1 + 2": 26,
"0 + 23 + 49 + 56": 1,
"10 + 10 + 10 + 17": 3,
"10 + 18 + 10 + 17": 6,
"10 + 45 + 38 + 35": 1,
"14 + 14 + 14 + 8": 8,
"14 + 40 + 39 + 35": 1,
"15 + 35 + 42 + 36": 1,
"15 + 35 + 43 + 35": 1,
"15 + 48 + 32 + 33": 1,
"16 + 16 + 16 + 10": 1,
"16 + 40 + 48 + 24": 1,
"16 + 61 + 19 + 32": 1,
"16 + 63 + 32 + 17": 1,
"17 + 27 + 32 + 52": 1,
"17 + 28 + 35 + 48": 1,
"17 + 30 + 34 + 47": 1,
"17 + 32 + 29 + 50": 1,
"17 + 36 + 47 + 28": 1,
"17 + 37 + 35 + 39": 2,
"17 + 38 + 32 + 41": 1,
これで比較すると・・・?
- 結果は 約2時間33分 かかったので
さっきは 約2時間20分 だったので遅くなってしまいました - おそらく、64bitごとのエンコード・デコードが
比較のスキップ量よりも時間がかかってしまったことが原因だと思います
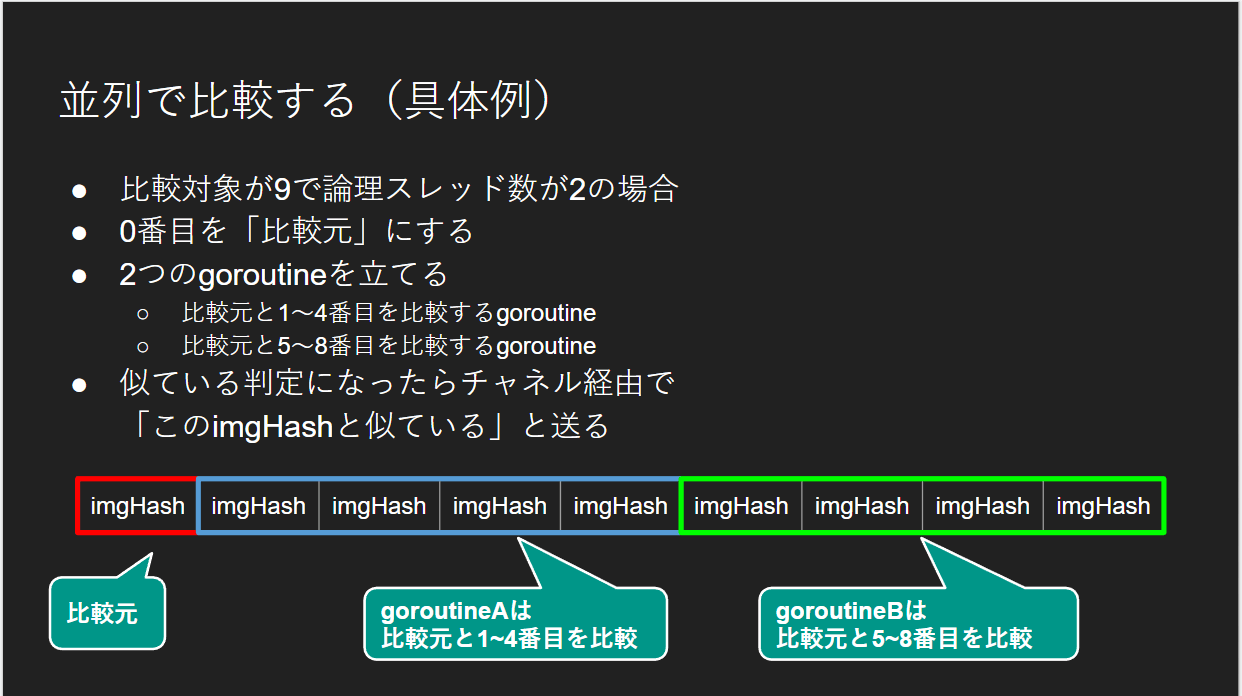
比較を並列化する
もっと単純に考えます
比較処理をどうにかして並列化できないか を考えます
- 画像イメージ情報すべてを「単一のスライス」に突っ込んでしまう
- そのスライスを「論理スレッド数」で見る場所を決めて比較する
- その情報をグルーピングする
- それを繰り返す
スライド画像そのままですが以下のイメージです
実コードは以下です
並列比較の実行結果
- 約37分 になりました
- 約63万ファイルの総当り比較がこの時間なら個人的に満足です
- 見積もり上の話ですがもともとは 6時間30分以上かかってた 比較時間が
37分になったので高速化成功と言っていいんじゃないでしょうか?
- 見積もり上の話ですがもともとは 6時間30分以上かかってた 比較時間が
- もちろんどのアルゴリズムもそうですが
人の目から見て「似ている」という内容でした
まとめ
| アルゴリズム | 実行時間 |
|---|---|
| 立っているビット数をkeyにして計算をスキップする | 約2時間20分 |
| 立っているビット数を64bitごとに合成してkeyにし、計算をスキップする | 約2時間37分 |
| 並列で総当り比較する | 約37分 |
- 「似ている画像を判断する」のは比較的容易に情報が出てきました
- ただこの技術を実用するときは
「この中にある何と何の画像が似ているのか」という時ではないか?
と思いました- 少なくとも今回自分が達成したかったのはそれでした
- 意外とそういう事例は調べても簡単には出て来ませんでした
- 今回はそれを自前で解決することを目的にして
様々なアルゴリズムを考えて最適化してみました
- ただ、最後にわかったのは
「小手先の最適化よりも並列に処理するのが一番確実で速い」という事実でした- 並列処理できるときは最優先で考えたほうが良さそうです(小並感)
- Goは並行(並列)処理を書きやすいのでオススメです
最後に一言
力こそパワー
Discussion