ひとりMongoDB University / M201 MongoDB Performance(7)

この記録は、アドベントカレンダー形式ではじめた、MongoDB Universityの学習コースの記録の続きになります!
ただいまのコース
- M201 MongoDB Performance
このコースでは、開発者 / オペレーション担当者双方向けの中級レベルの内容とのことです。
前回の記事は、ひとりMongoDB University / M201 MongoDB Performance(6) でした。
Chapter 4: CRUD Optimization
Optimizing your CRUD Operations (動画)
- インデックスを効果的に使うためには、絞り込む対象が少なくなるほど良い
- 結果として返るドキュメントの件数は同じでも、インデックスの作成時に指定するキーには、以下の点を注意する
- Equality (まず特定の値で数%に絞り込める場合は、クエリとしてEqualityを重視する)
- Sort (インデックス上でソートした結果がそのまま返るようにする)
- Range (範囲指定の場合は、条件によっては半数以上、あるいはほとんどのドキュメントが対象になる可能性があるので、条件を組み合わせる場合は、先に絞り込めるキーを利用する)
var exp = db.restaurants.explain("executionStats")
# 例えばコレクションにドキュメントが10万件あった場合
# zipcode がこの条件だと 5万以上のものが単純に5万件(過半数)あると、インデックスを利用しても
# 範囲に一致する件数が多すぎるので効率的ではない
exp.find({ "address.zipcode": { $gt: '50000' }, cuisine: 'Sushi' }).sort({ stars: -1 })
# たとえば、以下のように限りなく絞り込める条件が他にあれば、それをインデックスのキーとして先に持っていくのが良い
db.restaurants.createIndex({ "cuisine": 1, "stars": 1, "address.zipcode": 1 })
exp.find({ "address.zipcode": { $gt: '50000' }, cuisine: 'Sushi' }).sort({ stars: -1 })
Check: Optimizing your CRUD Operations
- インデックスで考慮すべき点は?
- equality, sort, range
- この順番でインデックスを考慮すること
Covered Queries (動画)
カバードクエリについて。
- カバードクエリってなに?
- カバードクエリがどのように作用するか
- Important caveats (重要な注意点について)
カバードクエリについて
- インデックスのキーや並びにマッチしたクエリを利用することで高いパフォーマンスが得られる
- インデックスのみのスキャンで完結するので、必要でないドキュメントを読みこまずにすむ
- ドキュメントそのものよりは、インデックスのほうがサイズが小さい
カバードクエリの動き
- ドキュメントの検索のクエリがインデックスの全てのキーを見たし、プロジェクション(抽出するフィールド)もインデックスに指定したものだけを対象にする場合は、抽出もインデックスだけで完結する
# サンプルの restaurants コレクションで実験
# 検証用のインデックスを作成します
var exp = db.restaurants.explain("executionStats")
db.restaurants.createIndex({name: 1, cuisine: 1, stars: 1})
'name_1_cuisine_1_stars_1'
# インデックスをカバーするクエリを発行
# find() の2番目の引数に、抽出対象のフィールドを明示します
# 抽出対象の条件を指定
# 作成した複合インデックスのフィールドのみを明示
# _id は明示的に非表示
db.restaurants.find({name: { $gt: 'L' }, cuisine: 'Sushi', stars: { $gte: 4.0 } }, { _id: 0, name: 1, cuisine: 1, stars: 1 })
{ name: 'LAuberge Chez Francois', cuisine: 'Sushi', stars: 4.1 }
{ name: 'LAuberge Chez Francois', cuisine: 'Sushi', stars: 4.3 }
... 略 ...
Type "it" for more
# 対象件数を確認: 847 件です
db.restaurants.find({name: { $gt: 'L' }, cuisine: 'Sushi', stars: { $gte: 4.0 } }, { _id: 0, name: 1, cuisine: 1, stars: 1 })
.count()
847
# 同じクエリを使って、実行計画&計測結果を見てみます
exp.find({name: { $gt: 'L' }, cuisine: 'Sushi', stars: { $gte: 4.0 } }, { _id: 0, name: 1, cuisine: 1, stars: 1 })
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.restaurants',
indexFilterSet: false,
parsedQuery:
{ '$and':
[ { cuisine: { '$eq': 'Sushi' } },
{ name: { '$gt': 'L' } },
{ stars: { '$gte': 4 } } ] },
winningPlan:
{ stage: 'PROJECTION_COVERED',
transformBy: { _id: 0, name: 1, cuisine: 1, stars: 1 },
inputStage:
{ stage: 'IXSCAN',
keyPattern: { name: 1, cuisine: 1, stars: 1 },
indexName: 'name_1_cuisine_1_stars_1',
isMultiKey: false,
multiKeyPaths: { name: [], cuisine: [], stars: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ name: [ '("L", {})' ],
cuisine: [ '["Sushi", "Sushi"]' ],
stars: [ '[4, inf.0]' ] } } },
rejectedPlans: [] },
executionStats:
{ executionSuccess: true,
nReturned: 847,
executionTimeMillis: 1,
totalKeysExamined: 965,
totalDocsExamined: 0,
executionStages:
{ stage: 'PROJECTION_COVERED',
nReturned: 847,
executionTimeMillisEstimate: 0,
works: 966,
advanced: 847,
needTime: 118,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 0, name: 1, cuisine: 1, stars: 1 },
inputStage:
{ stage: 'IXSCAN',
nReturned: 847,
executionTimeMillisEstimate: 0,
works: 966,
advanced: 847,
needTime: 118,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { name: 1, cuisine: 1, stars: 1 },
indexName: 'name_1_cuisine_1_stars_1',
isMultiKey: false,
multiKeyPaths: { name: [], cuisine: [], stars: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ name: [ '("L", {})' ],
cuisine: [ '["Sushi", "Sushi"]' ],
stars: [ '[4, inf.0]' ] },
keysExamined: 965,
seeks: 119,
dupsTested: 0,
dupsDropped: 0 } } },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1636185936, i: 20 }),
signature:
{ hash: Binary(Buffer.from("29fde499ad2f656d02aeebf6e9e85e0802172116", "hex"), 0),
keyId: 6993039015175782000 } },
operationTime: Timestamp({ t: 1636185936, i: 20 }) }
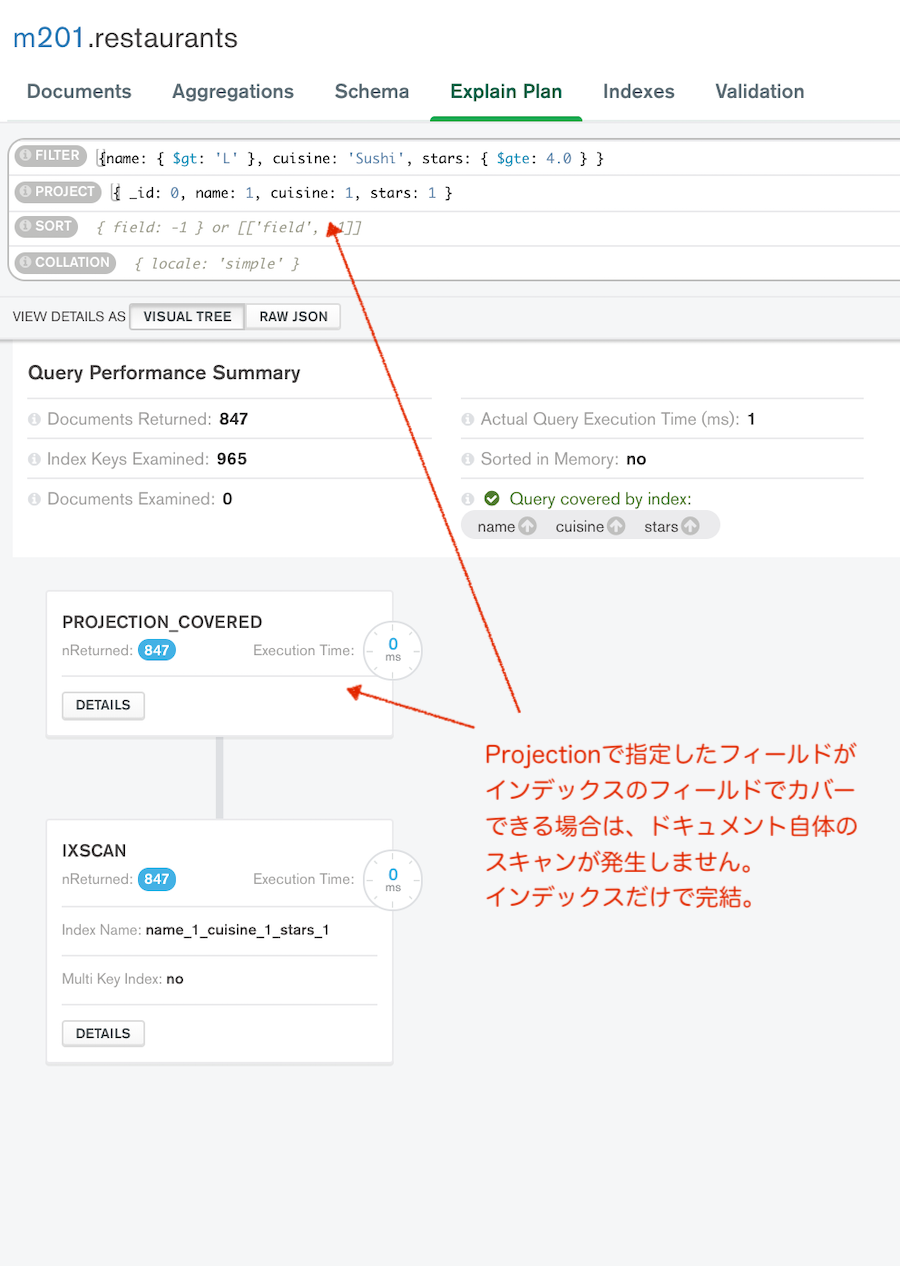
上記のクエリで、結果の一部に下記の通りに出力されている。totalDocsExamined: 0 なので、結果を返す際にドキュメント側は参照せず、インデックスのデータのみで完結している。
executionStats:
{ executionSuccess: true,
nReturned: 847,
executionTimeMillis: 1,
totalKeysExamined: 965,
totalDocsExamined: 0
}
最終的には同じ検索結果だけれど、プロジェクションの条件で、明示的に「インデックスの対象に含まれないもの」だけを指定した場合は、インデックスだけでは他に抽出すべきフィールドがあるのかどうか判断できないので、インデックスでのドキュメントの絞り込みの後で、ドキュメントを参照してのデータ抽出になる。
# プロジェクションのところで、「抽出対象の明示」でなく「抽出対象じゃないフィールドの明示」とすると、結果が変わります
exp.find({name: { $gt: 'L' }, cuisine: 'Sushi', stars: { $gte: 4.0 } }, { _id: 0, address: 0 })
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.restaurants',
indexFilterSet: false,
parsedQuery:
{ '$and':
[ { cuisine: { '$eq': 'Sushi' } },
{ name: { '$gt': 'L' } },
{ stars: { '$gte': 4 } } ] },
winningPlan:
{ stage: 'PROJECTION_DEFAULT',
transformBy: { _id: 0, address: 0 },
inputStage:
{ stage: 'FETCH',
inputStage:
{ stage: 'IXSCAN',
keyPattern: { name: 1, cuisine: 1, stars: 1 },
indexName: 'name_1_cuisine_1_stars_1',
isMultiKey: false,
multiKeyPaths: { name: [], cuisine: [], stars: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ name: [ '("L", {})' ],
cuisine: [ '["Sushi", "Sushi"]' ],
stars: [ '[4, inf.0]' ] } } } },
rejectedPlans: [] },
executionStats:
{ executionSuccess: true,
nReturned: 847,
executionTimeMillis: 3,
totalKeysExamined: 965,
totalDocsExamined: 847,
executionStages:
{ stage: 'PROJECTION_DEFAULT',
nReturned: 847,
executionTimeMillisEstimate: 0,
works: 966,
advanced: 847,
needTime: 118,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
transformBy: { _id: 0, address: 0 },
inputStage:
{ stage: 'FETCH',
nReturned: 847,
executionTimeMillisEstimate: 0,
works: 966,
advanced: 847,
needTime: 118,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 847,
alreadyHasObj: 0,
inputStage:
{ stage: 'IXSCAN',
nReturned: 847,
executionTimeMillisEstimate: 0,
works: 966,
advanced: 847,
needTime: 118,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { name: 1, cuisine: 1, stars: 1 },
indexName: 'name_1_cuisine_1_stars_1',
isMultiKey: false,
multiKeyPaths: { name: [], cuisine: [], stars: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ name: [ '("L", {})' ],
cuisine: [ '["Sushi", "Sushi"]' ],
stars: [ '[4, inf.0]' ] },
keysExamined: 965,
seeks: 119,
dupsTested: 0,
dupsDropped: 0 } } } },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1636186652, i: 9 }),
signature:
{ hash: Binary(Buffer.from("7aa1eebc9a63239b872ac7af9857307015bec3a4", "hex"), 0),
keyId: 6993039015175782000 } },
operationTime: Timestamp({ t: 1636186652, i: 9 }) }
速度も変わります。
totalDocsExamined: 847 で、絞り込んだドキュメントに対して除外フィールド以外のものを取り出す流れになります。
executionStats:
{ executionSuccess: true,
nReturned: 847,
executionTimeMillis: 3,
totalKeysExamined: 965,
totalDocsExamined: 847
}
Compass で確認
プロジェクションでインデックスをカバーするフィールドを指定した場合
プロジェクションでインデックスをカバーするフィールドを明示していない場合

注意点
- インデックスの対象になるフィールドが以下の場合は、カバードクエリが聞きません
効きません- フィールドが配列型の場合 (マルチキーインデックス)
- フィールドがネストしたドキュメントの場合
- mongos に対してクエリを投げる場合(つまりクラスタ化されている場合)は、クエリにシャードキーの対象となるキーが含まれていないとダメ
今回の内容は、ドキュメントではここに当たります。
- Covered Query
- https://docs.mongodb.com/manual/core/query-optimization/#covered-query
- Limitation をよく見ること
- Geospatial indexes cannot cover a query とあるので、地理情報のデータも注意
- In previous versions, an index cannot cover a query on a sharded collection when run against a mongos. (mongos に対してシャーディングされたコレクションに対してのカバードクエリは発行できない) - mongos はあちこちから条件にあったデータを集めてから、さらにまとめる必要があるので
- sharded key ではないけれど _id フィールドも併用してのカバードクエリは利用できそう?
- Geospatial indexes cannot cover a query とあるので、地理情報のデータも注意
Check: Covered Queries
以下の3タイプのインデックスを設定。このインデックスをカバーするような問い合わせはどれ?
{ _id: 1 }
{ name: 1, dob: 1 }
{ hair: 1, name: 1 }
こちら。(ただし例)
db.example.find( { name : "Alice" }, {_id : 0, dob : 1, name : 1} )
db.example.find( { hair: "short" }, {_id : 0, hair : 1 } )
Regex Performance (動画)
- 正規表現での検索を行う場合のインデックスの活用について
- テキストインデックスを設定しても、クエリのパターン指定によってパフォーマンスが出ない場合がある
- 通常のインデックスを設定しても同様で、完全一致でないと効果的に利用できない
-
find( name: /kirby/ )のようなクエリだと、部分一致なのでインデックスキーの全てをスキャンすることになる- インデックスはB-Treeで構成されているので、できるだけ早い段階で絞り込めるようにクエリを構成すること
- たとえば、
kirbyで「始まる」という条件が明確なら、キャレット(^)を指定する find( { name: /^kirby/ } )
Regex Performance
以下の条件でインデックス、クエリを指定する場合。
db.products.createIndex({ productName: 1 })
db.products.find({ productName: /^Craftsman/ })
このとき、インデックスはどう使われる?
- The query will do an index scan.
- インデックスは利用されるが、全てのインデックスについてのスキャンは発生しない
- B-Treeでの構成なので、前方一致で "Craftsman" を満たすツリーから先を対象にするので、それ以外のスキャンが不要になる
Aggregation Performance (動画)
アグリゲーションを利用する場合のパフォーマンスについて。
抽出したドキュメントをさらにパイプラインで加工、処理するような場合です。
-
リアルタイム性を要求される場合
- 「アプリケーション」へのデータ提供の場合が該当
- パフォーマンスが大事
- 「アプリケーション」へのデータ提供の場合が該当
-
バッチ処理で良い場合
- 分析目的(分析自体は別のタイミングで実施、そのためのデータ生成)
- 正確に集計されることが第一
- バックグラウンドでの処理、時間がかかっても問題ない場合
-
アグリゲーションの場合、実行前にオプティマイザが各ステージについてインデックスの利用について判定
- 処理の後半のステージでの指定でも、インデックスを利用することが効率的ならそれに応じたプランを算出する
- ただし、データ変換があったりする場合は、それ以後はインデックスが使われない
- できるだけステージの早い段階で $match などで、インデックスを使い絞り込むようにすること
-
注意点
- アグリゲーションで返される最大のサイズは 16MB
- アグリゲーションの各ステージで利用可能なRAMは100MB
- 足りないと例外が発生する
- ディスク利用を可能にすると、その分パフォーマンスにインパクトが生じる (allowDiskUsageの有効化の場合)
- 足りないと例外が発生する
-
できるだけインデックスで絞り込むようにすること
- ステージで処理する件数を少なくするように工夫すること
- プロジェクションで抽出するフィールドもできるだけ少なくすること
Check: Aggregation Performance
アグリゲーション時のパフォーマンスで考慮すべきことは?
- When $limit and $sort are close together a very performant top-k sort can be performed
- データの件数の絞り込みとソートの指定が必要な場合は、双方をセット(前後)で利用すること(インデックス利用のため)
- Transforming data in a pipeline stage prevents us from using indexes in the stages that follow
- データ変換ステージを挟むと、それ以後のステージではインデックスが効かないため、順番に注意
Lab 4.1: Equality, Sort, Range
以下のクエリを、equality, sort, range のルールに従って効率的なインデックス利用となるようにしたい。
どのインデックスが適切? (ちょっと問題を変えています)
db.accounts.find( { accountBalance : { $lte : NumberDecimal(55000.00) }, city: "New York" } )
.sort( { firstName: 1, lastName: 1 } )
-
{ city: 1, firstName: 1, lastName: 1, accountBalance: 1 }- accountBalance を先に持ってくると、このクエリの場合はレンジ指定での検索なので、件数が多くなる可能性が高い
- まずは明確に City で絞り込むと良い
- あとは、ソートの条件がカバードクエリに合致していることが大事なので、インデックスのキーに含まれること
Lab 4.2: Aggregation Performance
ここは演習。
前提条件として、検証環境にサンプルデータ(restaurants)をロードしていること。
以下のアグリゲーションを発行したら、エラーが発生しました。
db.restaurants.aggregate([
{ $match: { stars: { $gt: 2 } } },
{ $sort: { stars: 1 } },
{ $group: { _id: "$cuisine", count: { $sum: 1 } } }
])
{
"ok": 0,
"errmsg": "Sort exceeded memory limit of 104857600 bytes, but did not opt in to external sorting. Aborting operation. Pass allowDiskUse:true to opt in.",
"code": 16819,
"codeName": "Location16819"
}
# ソートの際のメモリ利用制限(100MB) でエラーが発生です....
このエラーを解消するために、適切なインデックスを作成してください。
インデックスに指定したフィールドを回答欄に登録してください。
実際に Atlas & Compass で試してみる
db.restaurants.aggregate([
{ $match: { stars: { $gt: 2 } } },
{ $sort: { stars: 1 } },
{ $group: { _id: "$cuisine", count: { $sum: 1 } } }
])
MongoServerError: Error in $cursor stage :: caused by :: Sort exceeded memory limit of 33554432 bytes, but did not opt in to external sorting.
エラーが返りました。
粛々とインデックスを設定してみます。
db.restaurants.dropIndexes()
# パーシャルインデックスを使うといいのかな?
# あと、レストランのインデックスがあるといいのかな?
db.restaurants.createIndex(
{ starts: 1 }, { partialFilterExpression: { 'stars': { $gt: 2 } } }
)
# パーシャルインデックスありではダメでした....。なしでの作成が正解。でもなぜかな??
困った時は、フォーラムも参考にしましょう!
(回答についてのディスカッションもあります)
Discussion