LangChainでChatBotを作る備忘録
カスタムChatBotを作ることになった。
フロント側は決めていないが、ChatWorksでBotを作るかReactでWebアプリを作ることになると思う。
とりあえず最初は、LambdaでChatBotを動かしてAPIGateway経由でレスポンス返ってくるようなのを作れないかなと考えている。
構成図(想定)
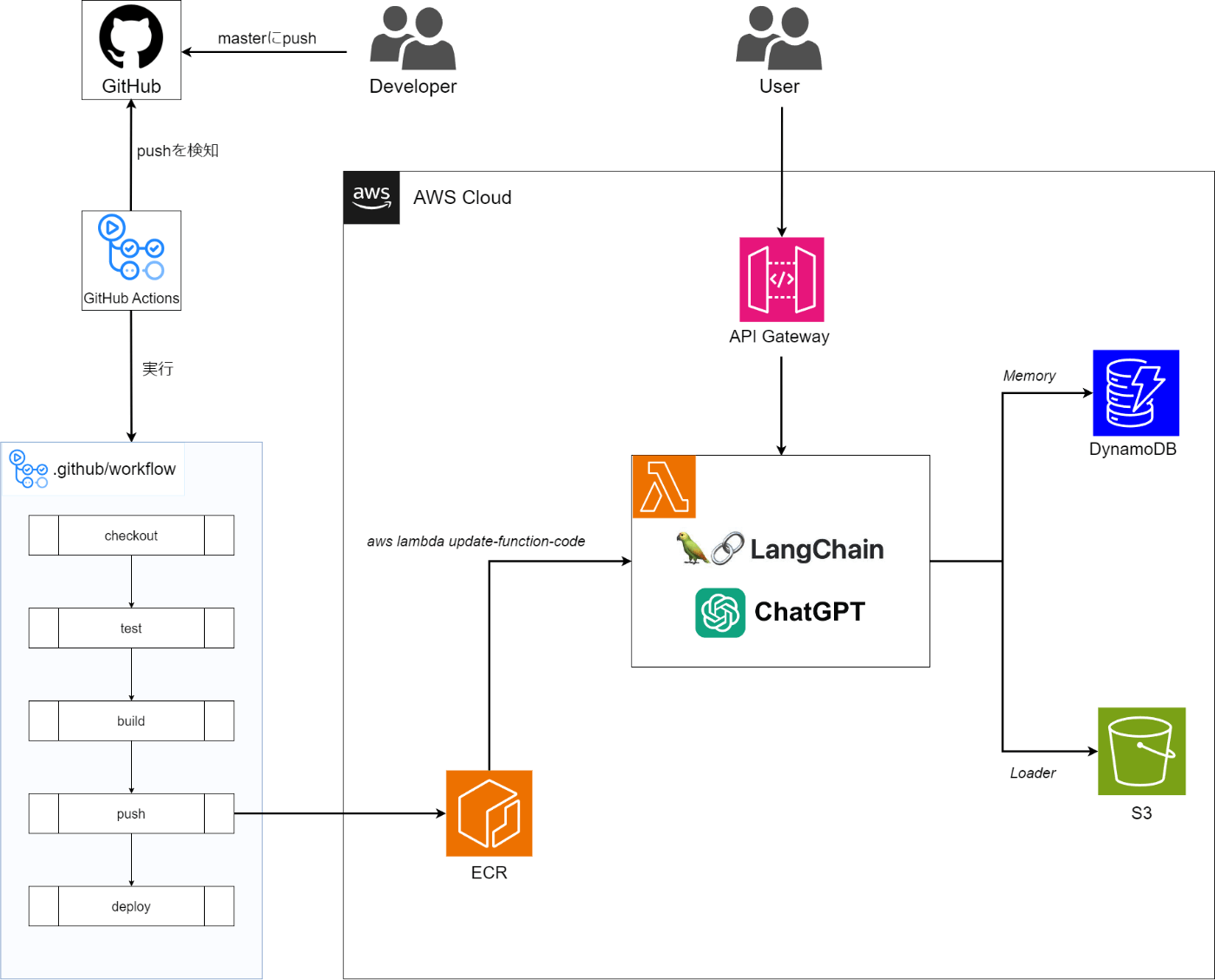
実際はOpenAI APIにリクエスト送ってる。
ついでにCloudFormation使ってみたい。
Lambdaを使うことができなそう。
LangChainで用意されているS3DocumentLoaderだが、内部的にはNLTKが呼ばれている。NLTK内でos.makdir(download_dir)を行っている部分が問題を起こしている。
Lambda内でディレクトリの作成を行う場合は/tmpである必要があるが、download_dirの指定ができなかった。
download_dirを変える方法としては以下が考えられた。
- Lambdaレイヤーのライブラリを直接変える
-
download_dirを設定するような方法を使う
1は、LangChainのサイズが250mb, Lambdaレイヤーは50mbまでしか使えないのでECR上のDockerイメージからLambdaを作る必要があった。DockerFileからDockerイメージを作るときにrequirements.txtからライブラリのインストールをしているのでライブラリを直接触ることができない。
2は見つからなかった。
def default_download_dir(self):
"""
Return the directory to which packages will be downloaded by
default. This value can be overridden using the constructor,
or on a case-by-case basis using the ``download_dir`` argument when
calling ``download()``.
On Windows, the default download directory is
``PYTHONHOME/lib/nltk``, where *PYTHONHOME* is the
directory containing Python, e.g. ``C:\\Python25``.
On all other platforms, the default directory is the first of
the following which exists or which can be created with write
permission: ``/usr/share/nltk_data``, ``/usr/local/share/nltk_data``,
``/usr/lib/nltk_data``, ``/usr/local/lib/nltk_data``, ``~/nltk_data``.
"""
# Check if we are on GAE where we cannot write into filesystem.
if "APPENGINE_RUNTIME" in os.environ:
return
# Check if we have sufficient permissions to install in a
# variety of system-wide locations.
for nltkdir in nltk.data.path:
if os.path.exists(nltkdir) and nltk.internals.is_writable(nltkdir):
return nltkdir
# On Windows, use %APPDATA%
if sys.platform == "win32" and "APPDATA" in os.environ:
homedir = os.environ["APPDATA"]
# Otherwise, install in the user's home directory.
else:
homedir = os.path.expanduser("~/")
if homedir == "~/":
raise ValueError("Could not find a default download directory")
# append "nltk_data" to the home directory
return os.path.join(homedir, "nltk_data")
上のコードはdownload_dirを設定しているらしき場所。
nltk.data.pathに設定したいパスをappendしたいが、インポートしているのはnltkではなくlangchainなのでnltkの設定ができなそう。
import nltk
# NLTKのDownloaderクラスを使用して、カスタムダウンロードディレクトリを指定
custom_download_dir = '/path/to/my/custom/dir'
downloader = nltk.downloader.Downloader(download_dir=custom_download_dir)
# もしくはnltk.data.pathにカスタムディレクトリを追加
if custom_download_dir not in nltk.data.path:
nltk.data.path.append(custom_download_dir)
こんな感じにできたら動かせそう。
nltk.data.path.append(DOWNLOAD_DIR)でディレクトリの設定ができなかったので、NLTKでダウンロードされるファイルを事前に動作させることで動作した。
def initialize_nltk():
nltk.data.path.append(DOWNLOAD_DIR)
nltk.download('punkt', download_dir=DOWNLOAD_DIR)
nltk.download('averaged_perceptron_tagger', download_dir=DOWNLOAD_DIR)
def handler(event, context):
try:
initialize_nltk()
from langchain.document_loaders.s3_directory import S3DirectoryLoader
except ImportError:
raise ImportError(
"Please install langchain with the s3 directory loader extra: pip install langchain[s3-directory]"
)
-
langchainの中のunstructuredでpdfを扱うときはOpenCVを使っているのでDockerImageのサイズが5GBぐらいになってしまう - LambdaでOpenCVを扱えない
Amazon Textractを使用したLoaderがLangChainで用意されていたので使いたかったが、Amazon Textractは日本語対応していなかった。