AWSでデータレイクを学ぶ その3 (AthenaでCTAS、ビュー、データパーティショニング)




こんにちは、アキです!
前回はGlue Crawlerを使ってデータカタログを作成しました。今回は、前回作成したデータカタログに対してAthenaを使ってクエリを実行します。また、Glue Jobを使ってETL処理を行いましたので、それについてもまとめます。
今回も引き続きこちらの本(AWSではじめるデータレイク)で学習をしたものをアウトプットします。
Athenaとは
サーバレス、フルマネージドなクエリサービスです。
S3に保存したデータに対してクエリを実行することができます。利用するには、対象のデータをGlueデータカタログを登録しておく必要があります。
料金はクエリ実行時にスキャンされるデータの量に応じた従量課金制となっています。
前回作成したデータカタログに対して実行してみます。
SELECT * FROM "practice_crawler_zenn"."zenn_input";
FROM句以降は、"データベース名"."テーブル名"で記載します。結果は以下のようになりました。
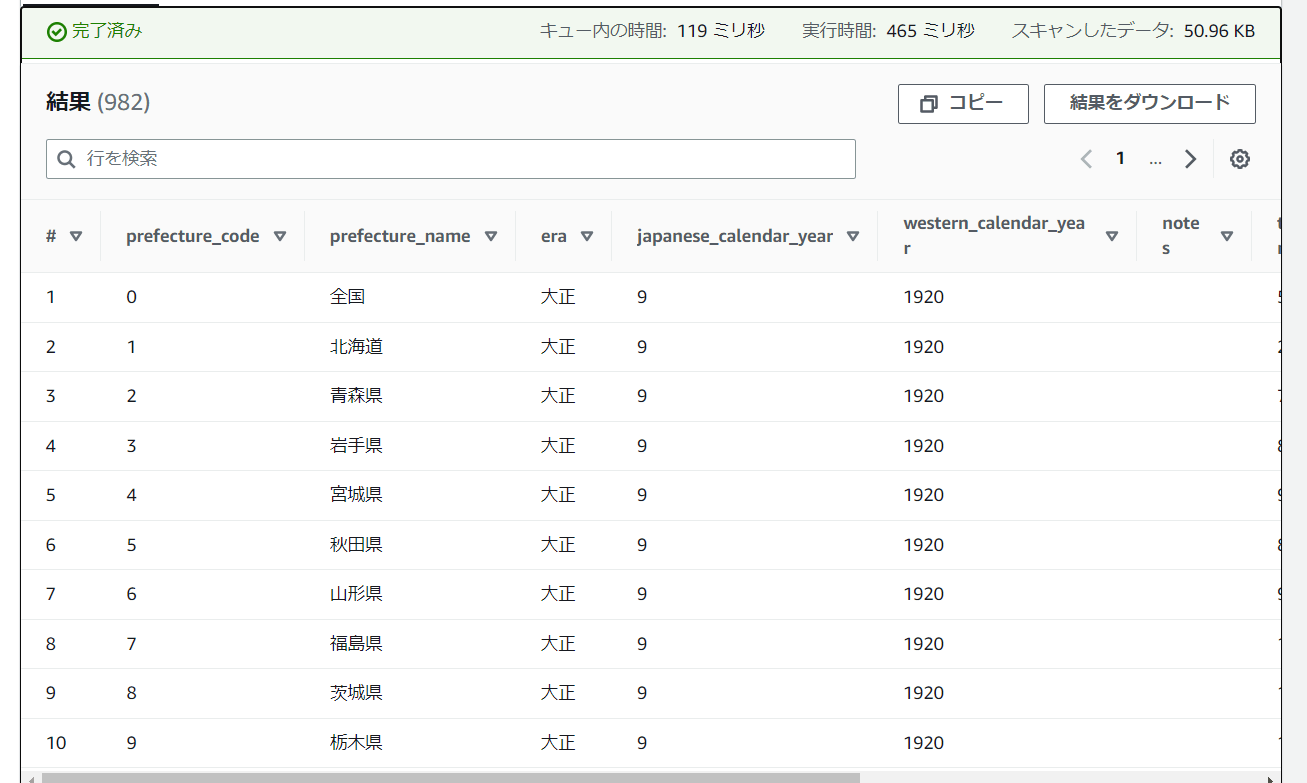
見切れていますがしっかり取れました。
効率的なクエリ実行
Athenaはスキャン量に応じて課金されるため、より効率的にクエリを実行することでコストカットを図ることができます。今回は効率的にスキャンを行うために「ビュー、CTAS、データパーティション」を試しました。
ビュー
まずはビューについてです。ビューとは実際のデータを持たない仮想的なテーブルのことです。自身で実行したクエリからビューを作成することで、そのビューをテーブルのように使うことができます。
前回作成したテーブルからビューを作成してみましょう。
まずはビューにしたいものをSELECTします。
SELECT "era","japanese_calendar_year","western_calendar_year",
"notes","total_population"
FROM "practice_crawler_zenn"."zenn_input"
WHERE "prefecture_name" = '東京都';
実行してみて問題ないことが確認できたら、次に画面下から 作成>クエリからの表示 を押下します。(直訳に違和感を感じますね)

ビューに適当な名前(私はtokyoとしました)をつけてから作成をすると完成です。ちなみに、このビューを登録すると勝手にGlueのデータカタログに登録されるので、すぐにクエリを実行することができます。では実際にビューに対してクエリを実行してみましょう。
SELECT "western_calendar_year","total_population"
FROM "practice_crawler_zenn"."tokyo";
するとビューに登録したものからデータを取得することができます。
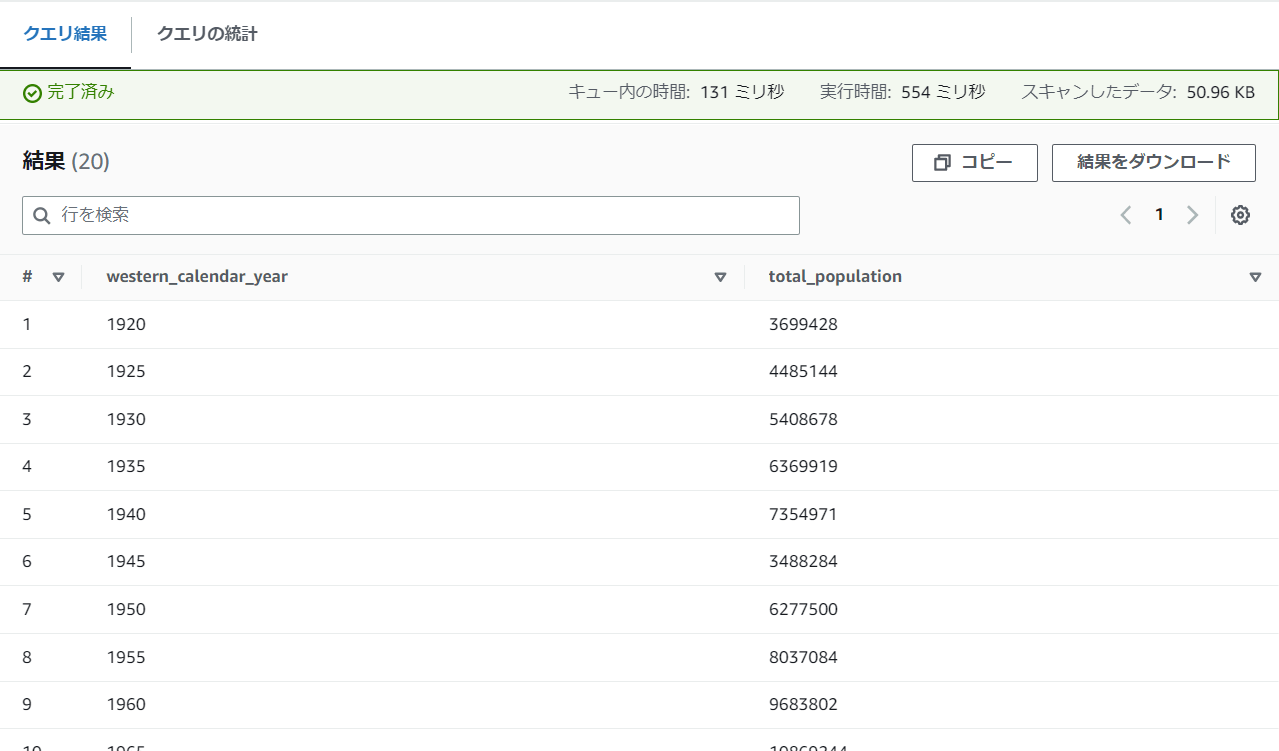
実際にビューを登録することで直接的にスキャン量を減らすことはできません。ビューを使用する目的は、複雑なクエリをシンプルにすることができ、これから紹介するCTAS、データパーティショニングと組み合わせることで大きなメリットを発揮します。
CTAS
次にCTAS(Create Table As Select)についてです。読んで字のごとくSelectの結果からテーブルを作成します。作成手順もビューを作成したときとほぼ同様に、画面下にある 作成>クエリからのテーブル を押下します。作成する際にCTASで作成するテーブルの保存形式や保存先を聞かれます。CTASで作成するテーブルはビューとは異なり、クエリ結果をテーブルとして保存します。この点がビューとの違いです。今回はデフォルトの設定のまま(私が作成したときは保存形式がParquetでした)保存します。
先ほど同様に、
SELECT "era","japanese_calendar_year","western_calendar_year",
"notes","total_population"
FROM "practice_crawler_zenn"."zenn_input"
WHERE "prefecture_name" = '東京都';
からctas_tokyoという名前でテーブルを作成しました。
ではビューに実行したクエリとおなじクエリを実行してみましょう。
SELECT "western_calendar_year","total_population"
FROM "practice_crawler_zenn"."ctas_tokyo";
当然得られる結果は変わりません。が、おわかりいただけたでしょうか…?
▼ビューでクエリ

▼CTASでクエリ

スキャンした量が大幅に減っています!先ほどにも記載したように、CTASはデータを保存します。頻繁に実行するクエリをテーブルにしておくことで大幅にコストを削減することができます。
ただし注意も必要です。CTASを実行したタイミングまでのデータしか登録されないため、元のテーブルが更新されても、自動的には更新されません。
データパーティショニング
さて、最後はデータパーティショニングです。これはAthenaの機能ではなく、効率的にクエリを実行するために、データを決まった方式で分割して保存することです。
今回使っているデータをもとに考えてみます。
▼5年毎の全国、各県の人口
| prefecture_code | prefecture_name | era | japanese_calendar_year | western_calendar_year | notes | total_population | male_population | female_population |
|---|---|---|---|---|---|---|---|---|
| 0 | 全国 | 大正 | 9 | 1920 | 55963053 | 28044185 | 27918868 | |
| 1 | 北海道 | 大正 | 9 | 1920 | 2359183 | 1244322 | 1114861 | |
| 2 | 青森県 | 大正 | 9 | 1920 | 756454 | 381293 | 375161 |
例えばこのデータを西暦毎にパーティショニングを行うことを考えます。パーティショニングの対象になるカラムはパーティションキーといいます(今回の例だとwestern_calendar_year)。パーティショニングされ、S3に保存されたときのイメージは次の通りです。
s3://your-bucket/example/
│
├── year=1920/
│ └── data_1920.csv
├── year=1925/
│ └── data_1925.csv
├── year=1930/
│ └── data_1930.csv
~
~
└── year=2015/
└── data_2015.csv
このように決まった方式で(西暦で)分割する方式をデータパーティショニングといいます。
この方式で保存することのメリットは、この例だと1920年からデータを取得するクエリを実行した場合、そのデータのみがスキャンされ、スキャン量を大幅に削減することができる点です。
以上がパーティショニングとそのメリットなのですが、手作業でパーティショニングしたくないので、Glue Jobを使ってサクっとテーブル作成を行いました。
Glue Job
コンソールからGlueのETL Jobへ進み、Visual with a source and targetを選択してCreateを押します。
作成できたら detailsに進み設定を行います。ここで設定するのは、IAMロールと、このJobのファイル名です。
まずIAMロールですが、S3とGlueの権限があれば問題ありません。前回作成したロールを使用します。
次にJobのファイル名です。Jobのプログラムはデフォルトで新規S3バケットに保存されます。保存先を指定したい場合はここで選択しておきましょう。
画面右上のSaveボタンで保存したら、次にScriptに進みます。(私はなぜか遷移したときにS3にアクセス権限がないみたいなエラーが出ましたが、いったんページを離れてから、再度Scriptを確認すると消えていました。)
先ほどのパーティションの例に習い、西暦でデータをパーティショニングするスクリプトを作成しました。
最終的に、
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Glue データカタログのテーブルから読み込む
datasource0 = glueContext.create_dynamic_frame.from_catalog(database="practice_crawler_zenn", table_name="zenn_input")
# 型を定義
apply_mapping = ApplyMapping.apply(frame=datasource0,
mappings=[
("prefecture_code", "string", "prefecture_code", "string"),
("prefecture_name", "string", "prefecture_name", "string"),
("era", "string", "era", "string"),
("japanese_calendar_year", "bigint", "japanese_calendar_year", "bigint"),
("western_calendar_year", "bigint", "western_calendar_year", "bigint"),
("notes", "string", "notes", "string"),
("total_population", "bigint", "total_population", "bigint"),
("male_population", "bigint", "male_population", "bigint"),
("female_population", "bigint", "female_population", "bigint")
])
datasink4 = glueContext.write_dynamic_frame.from_options(
frame=apply_mapping,
connection_type="s3",
connection_options={
"path": "s3://practice-glue-crawler/population_by_prefecture_year_partitioned/",
"partitionKeys": ["western_calendar_year"]
},
format="parquet"
)
job.commit()
となりました。出力はcsv形式ではなく、Parquet形式にしています。
ここで特に注意したいのは型付けはしっかり行うことです。型付けを行わなくてもパーティショニング自体はできてしまいますが、意図しない型でテーブルに登録されてしまう場合があります。
このJobを実行すると下記のようにS3上にディレクトリと、

ファイルが作成されています。

クエリを実行したいので、Glue Crawlerを使ってテーブルを作成しましょう。作成方法は前回と同様です。
Athenaでクエリ
では1920年の人口を取得するクエリをパーティショニングされたテーブルから取得してみましょう。
※なぜかwestern_calendar_yearをbigintに指定したのにstring型になっています。調査しましたが原因は不明…
SELECT "total_population"
FROM "practice_crawler_zenn"."zenn_population_by_prefecture_year_partitioned"
WHERE "western_calendar_year" = '1920';
▼パーティショニングしたテーブル

最初に登録したテーブルで同じクエリを実行すると、
▼最初に登録したテーブル

となり、スキャン量が大幅に減っていることが分かります。
このように、データパーティショニングを行うことで効率的にクエリを実行することが可能です。
以上
今回はAthenaのスキャンをより効率的に行う方法を学習しました。
作業についてはおおむね理解できましたが、どのデータをパーティショニングするか、CTASするか、ビューに登録するかの判断が難しそうだなといった印象です。
次回はRedshiftをまとめようかなと思います!
料金が高額なため別なリソースを検討します…
Discussion