AWSでデータレイクを学ぶ その2(Glue Crawler)



こんにちは、アキです!
さてさて、前回は少しの用語を確認して終わってしまいました。今回は少し踏み込んで、データカタログについて学習・作成したので、まとめたいと思います。
今回も引き続きこちらの本(AWSではじめるデータレイク)で学習をしたものをアウトプットします。
データカタログとは
データカタログとは、ファイル形式とかデータサイズなどのメタデータの一覧のことです。
データレイクにデータを保存しているだけでは、それぞれがどのようなデータなのかが分かりずらく、分析を効率的に行えません。そこで、データカタログを作成することで解消することができます。より具体的には以下のようなメリットがあります。
- データが発見しやすくなる
データカタログに集約されることで発見しやすくなる - 権限管理がしやすくなる
例えば個人情報など閲覧できる人が限られたデータが存在する場合、「どんなデータが存在しているか」はデータカタログから参照できる - 監視・監査がしやすくる
不正なアクセスはないか、誰がどのようにデータを利用しているかを把握できる - 通知
例えばあるテーブルにカラムが追加されたことを、ユーザにしらせる等
AWS Glue
私はAWS Glueを利用して、データカタログの作成を行いました。
データカタログを作成するにはGlue Crawlerを利用してクローリングします。
作成されるデータカタログはテーブルという単位で保存されます。
今回は、実際にデータカタログの作成を行ってみました。
事前準備
Glue Crawlerを使ってデータカタログを作成するために、今回は以下の事前準備を行いました。
- AWSアカウント作成
- 適当なIAMユーザーを作っておく(ルートユーザは使わない)
- データカタログを作成するために適当なデータファイルを用意しておく
今回はe-Statから「男女別人口-全国,都道府県(大正9年~平成27年)」をダウンロードして使っていこうと思います。
ダウンロードしたファイルの文字コードはSJISなので、事前にUTF-8に変更しました(Glue ETL ジョブで変換するスクリプトを作成したほうがスマートだったかも…)。
カラムが日本語で、そのままではAthenaでクエリする際に使いにくいので、
都道府県コード → prefecture_code
都道府県名 → prefecture_name
元号 → era
和暦(年) → japanese_calendar_year
西暦(年) → western_calendar_year
注 → notes
人口(総数) → total_population
人口(男) → male_population
人口(女) → female_population
と変換しました。
- 適当なS3バケットを作成しておく
(私は作成したS3バケットにinputディレクトリを作成しました。)
AWS Glue Crawlerを作成
ここまで準備が完了したら、いよいよGlue Crawlerを作成します。
(この記事は2023年5月時点での記事ですので、この記事を見ていただいたタイミングによっては、コンソールに表示される内容が変わっている場合があります。)
-
AWSコンソール上の検索タブでGlueを検索し、遷移すると下記の画面が表示されると思います。Glueを利用する際はリージョンを選択することができます。画面右上から任意のリージョンを選択してください。
リージョンを選択し終えたら、サイドバーメニューからCrawlersを選択し、次の画面でCreate Crawlerを押下して作成画面へ遷移します。 -
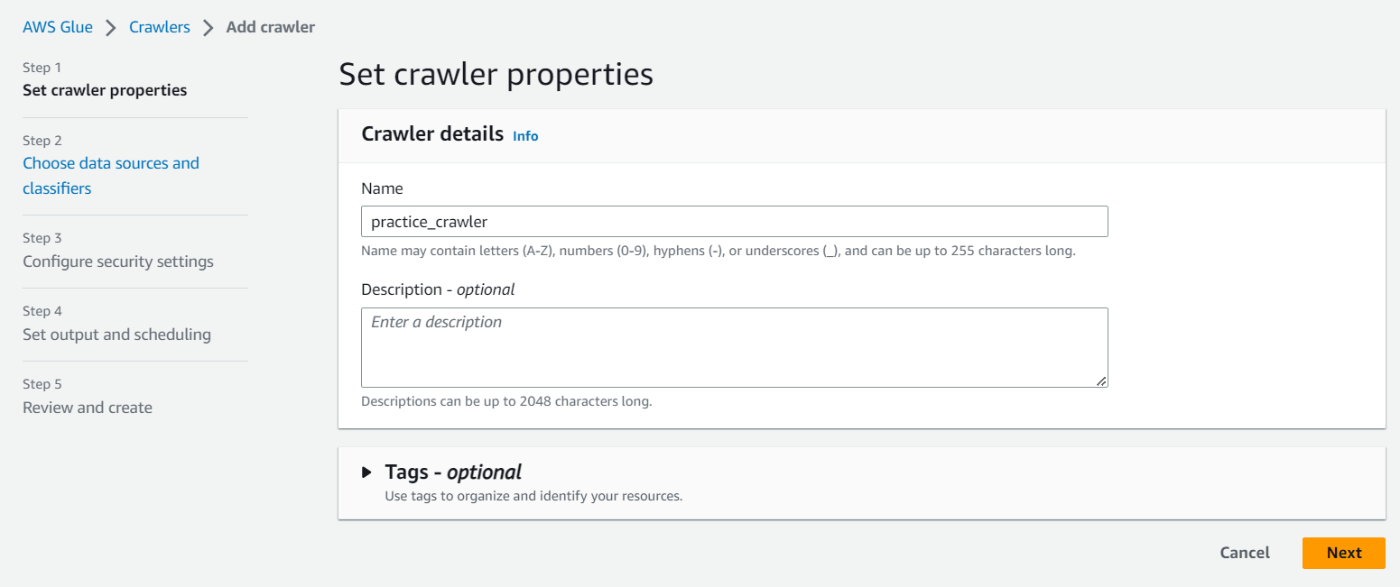
の画面からCrawlerの設定を行います。ここでは作成するデータカタログのテーブル名を入力します。
-
にどのデータを対象にするかを選択します。
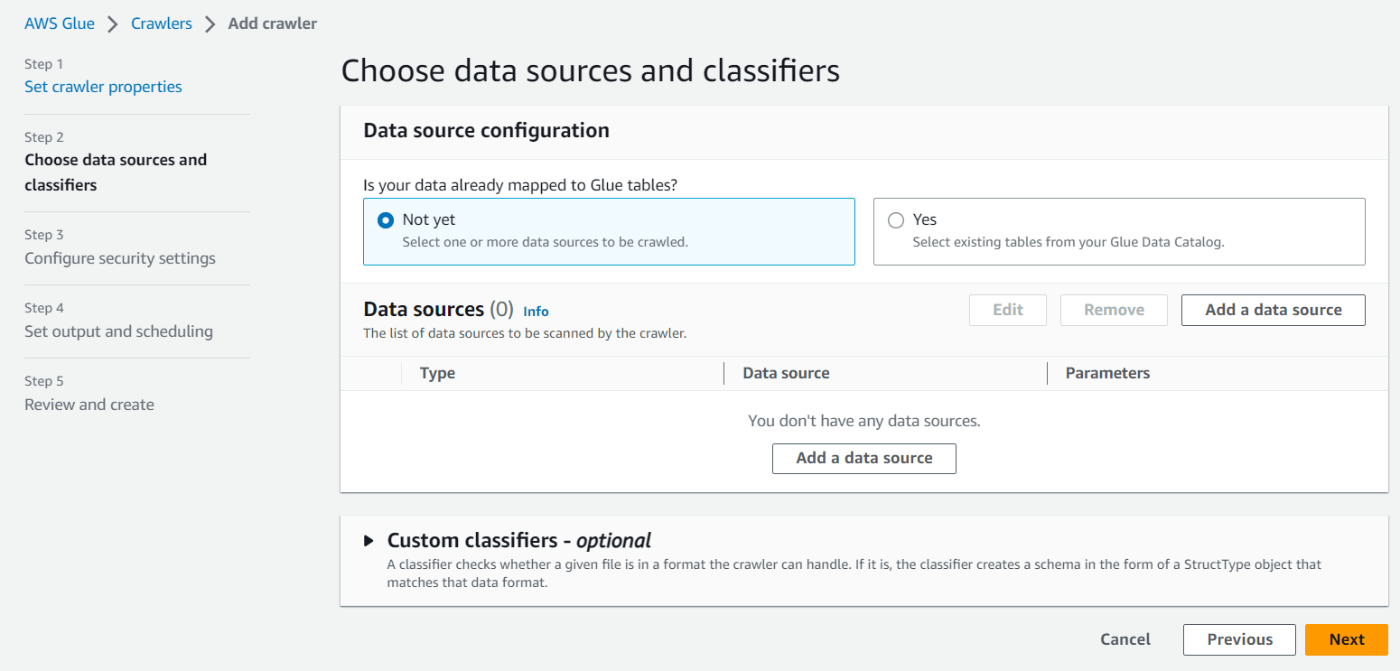
今回はS3に保存されているデータを対象にするので、Not Yetを選択した状態から、Add a data sourceを押下します。
下記の画面のようにData sourceとS3 Pathを選択し、Add an S3 data sourceを押下。
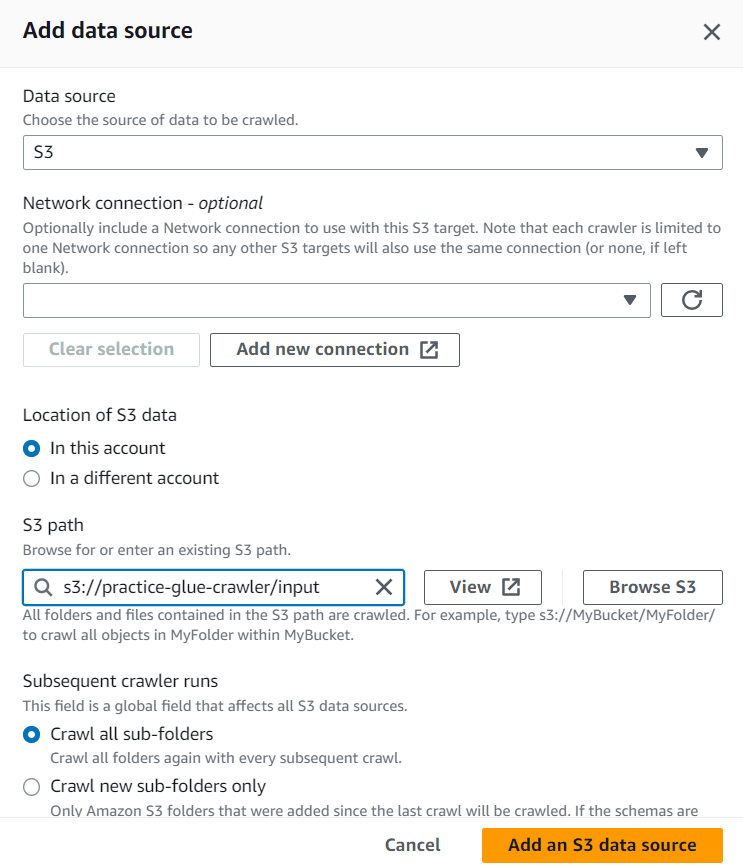
※ちなみに、Custom classfiersは今回設定しません。これは、例えばCSVだとカンマ区切りのフォーマットですが、独自のフォーマットからスキーマを抽出する際は、ここで設定することでクローリングをすることができます。設定は、サイドバーメニュー内のClassifiersから設定し、この画面から選択することができます。CSVファイルは特に設定する必要がないのでスキップします。 -
次にIAMロールの作成を行います。Create new IAM roleを選択し、名前を入力するだけで必要なロールを作成してくれます。
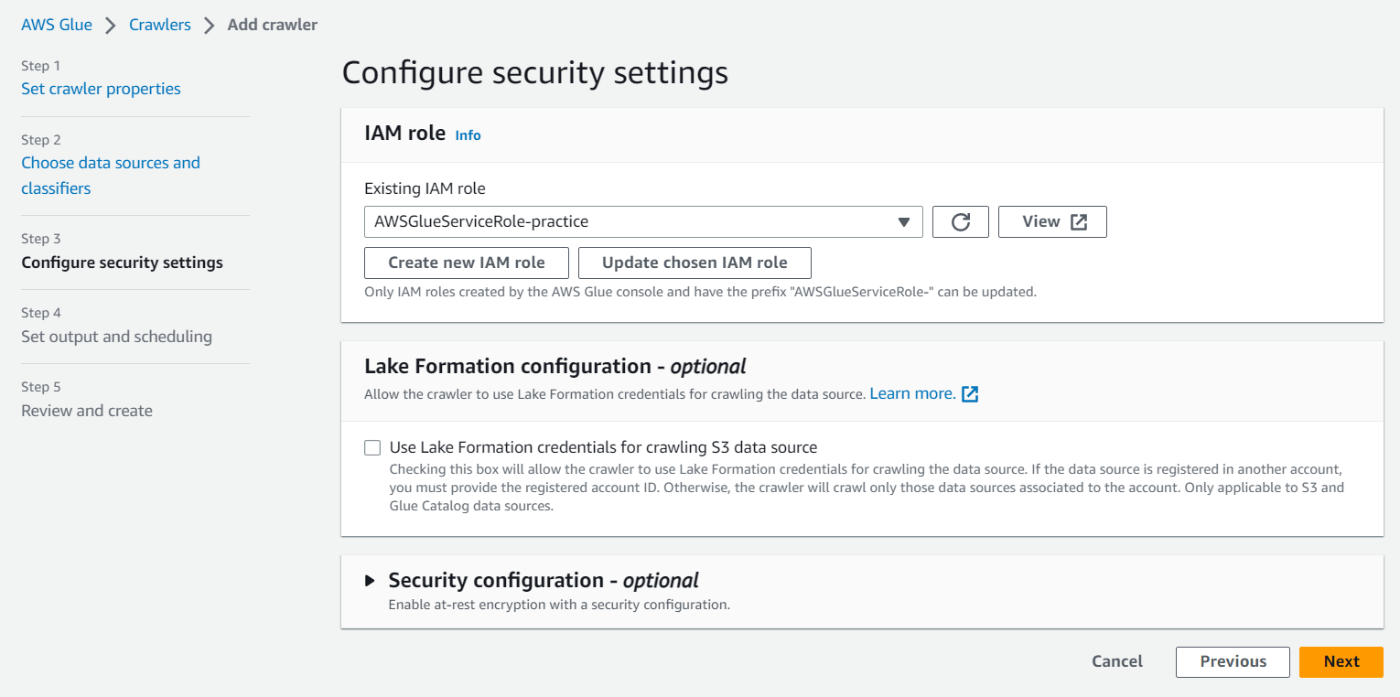
-
次はデータカタログのアウトプット先になるデータベースを作成します。Add databaseを選択し、適当な名前を入力しCreate databaseを押下します。
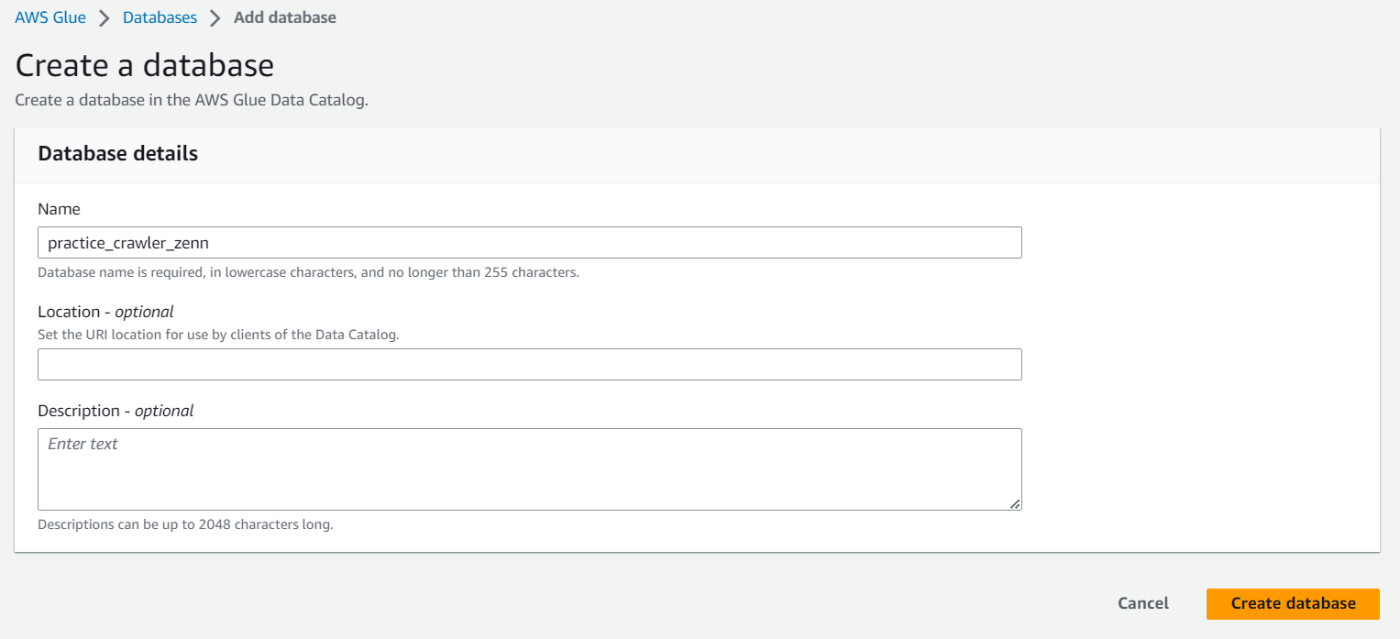
データベースの作成が完了したら設定画面に戻り、作成したデータベースを選択します。
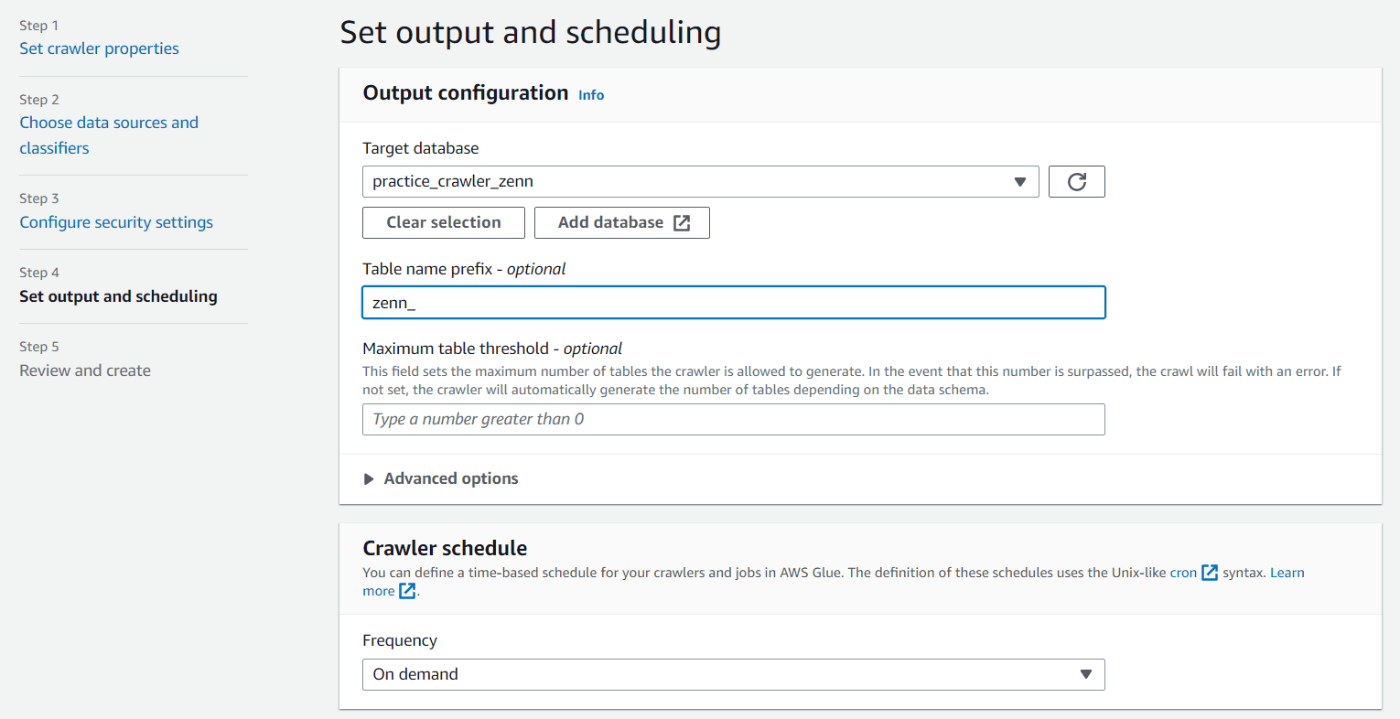
オプションでテーブル名にプレフィックスをつけることができます。今回私は zenn_ をつけています。
今回はオンデマンドで実行しますが、Crawler Scheduleを設定することで、その時間にクロールを行うことができるようです。(個人的にはS3のデータが更新されたら、それがトリガーとなって自動でクロールするみたいなのがいいかなと思いましたが、その場合はLambdaとかを使う必要があるみたいです。) -
さて、ここまで設定が完了すれば、設定は完了です。次の画面で設定内容を確認し、問題がなければCreate crawlerを押下して作成しましょう!
クローラを実行
設定が完了すればあとは画面上部にあるRun crawlerを押して実行するだけです。
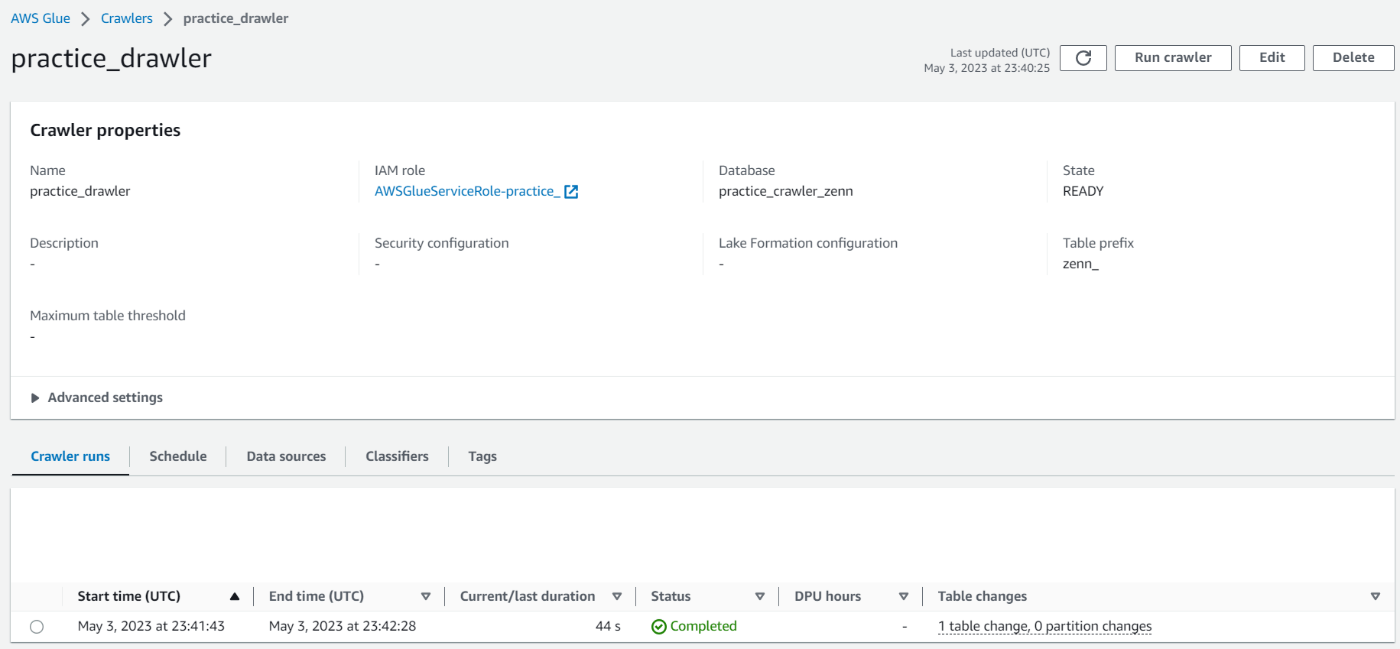
画像のように、StatusがCompletedとなっていれば成功です。
データカタログを確認するには、サイドバーメニューからTablesを選択し、そこから作成したテーブルを選択します。テーブル名は先ほど設定したプレフィックス+S3バケットのディレクトリ名となっていました。
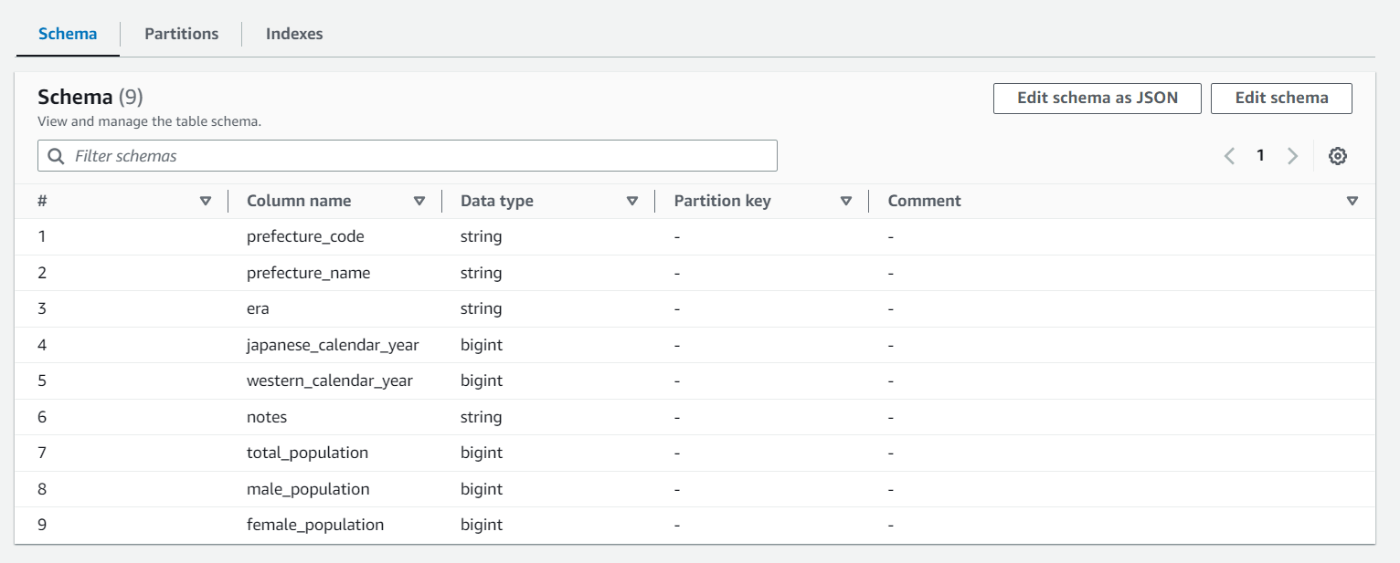
このようにCSVデータがデータカタログになっていることが分かります。
AWS Athenaを使ってクエリする
さて、データカタログを作成することができたので、このデータカタログに対してクエリを実行してみましょう。
私はここで「データカタログにクエリを実行できるってことは、データカタログにデータが入っているってこと?でもデータカタログはメタデータのみを持っているはず?あれ?」となりました。今考えると的外れもいいところですね(苦笑)。
そもそもクエリを実行するためにはスキーマが必要になります。S3に保存されたファイルをGlueのデータカタログに登録することで、そこが参照ポイントとなりクエリを実行することができます。もちろんデータそのものはデータカタログに保存されているわけはなく、今回だとS3から取得されます。
実際にクエリを実行してみます。
まずは全件表示させてみます。
SELECT * FROM "practice_crawler_zenn"."zenn_input";
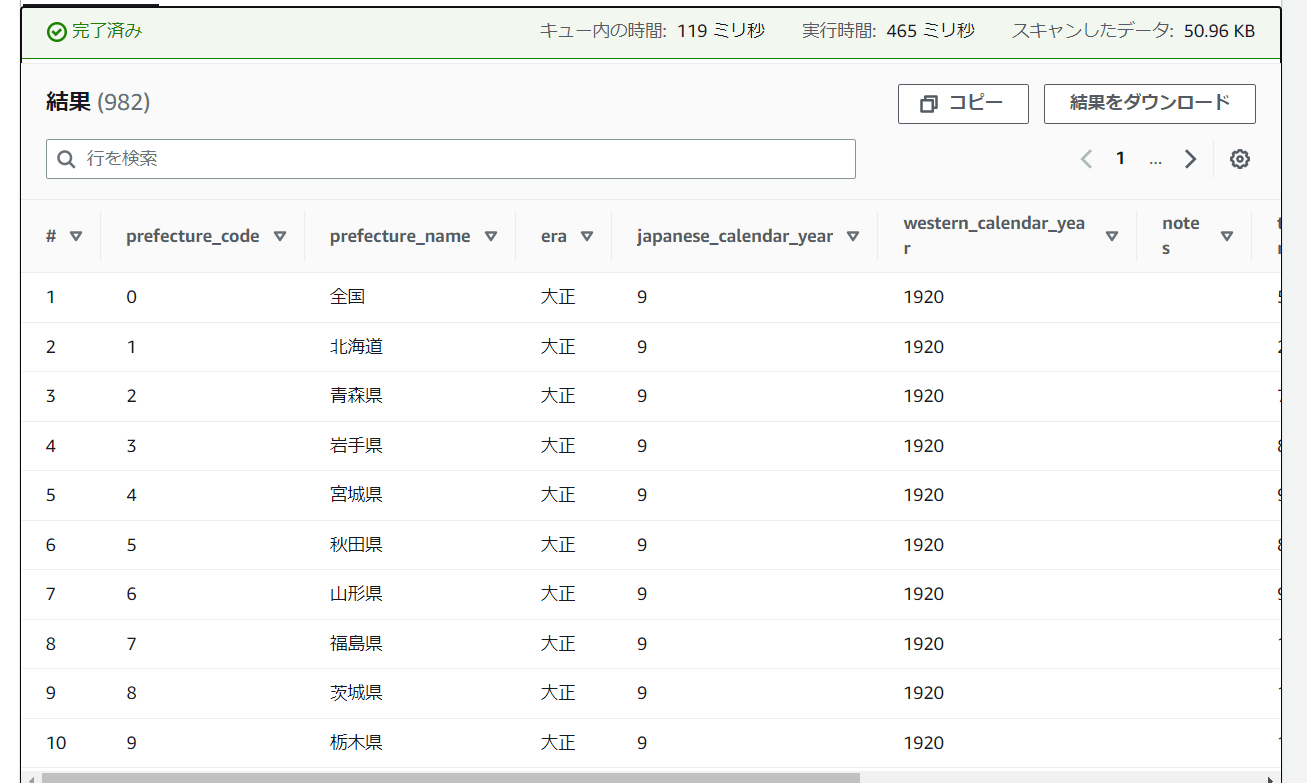
画像だと見切れていますが実行できました!
以上
今回はGlue Crawlerを使ってデータカタログを作成しました。
はじめはすべて英語表記で面食らいましたし、書籍に載っているコンソール画面が変わっていて面食らいましたが、慣れると案外簡単でした。
次回はAthenaのビューとCTASとかについてまとめてみようと思います。
Discussion