Reactチームが見てる世界、Reactユーザーが見てる世界
Reactはシンプルなサイトから複雑なアプリケーションまで、非常に幅広く採用されている人気のフレームワークです。OSS化から10年以上の歴史がありながら、昨今もReact Server Componentsなど革新的なアイディアを我々に提案し続けています。
一方で、React Server Componentsへの批判的意見やBoomer Fetching問題などを見ていると、Reactチームと一部Reactユーザーの間には意見の相違が見て取れます。この意見の相違はそれぞれが置かれた状況の違いから生じるもの、つまり「見てる世界が違う」ことに起因してると筆者は感じています。
本稿では「Reactチームの見てる世界」を歴史的経緯を踏まえながら考察し、Reactの根本にある思想やコンセプトに対する読者の理解を深めることを目指します。
要約
- ReactはMetaの大規模開発を支えるべく開発され、シンプルでスケーラブルなフレームワークであるために自律分散的アーキテクチャを重視している
- Reactユーザーの多くはMetaより小規模な開発でReactを採用しており、一部では中央集権的アーキテクチャが好まれている
- Reactチームの自律分散性重視と一部Reactユーザーの中央集権重視な姿勢の違いが、様々な意見の相違を生んでいる
Reactの誕生
「Reactチームが見てる世界」を深く理解するには、Reactの歴史的経緯を知る必要があります。
Reactが誕生する前、2012年頃のWeb開発周辺動向から振り返っていきましょう。当時はサーバーサイドではWeb MVC[1]、クライアントサイドではjQueryが良く採用されており、モバイルアプリの台頭もあってAPIとViewの分離ニーズが高まっていました。しかし、jQueryは開発者側で設計する余地が多分に残されていたため、開発体制やアプリケーションのスケールと共に複雑化しやすく、UI開発は課題になりがちでした。
このような状況を改善すべく、Backbone.jsなどのクライアントサイドMVC[2]フレームワーク需要が世間的にも高まっていました。
Bolt.jsとReact
Metaにおいても上述の状況は同様で、特にFacebookのWebサイトは革新的な機能と複雑なUIを必要としていました。そこでMetaでは、UI開発の多くの課題を解消すべくBolt.jsというフレームワークが開発されていました。
Bolt.jsは当初典型的なクライアントサイドMVCでしたが、改善が進む中で「UI開発で最も複雑なのはUIの更新である」という仮説がうまれ、それを関数型プログラミングのアイディアで解決しようという試みが行われました。具体的には、更新に応じてUIを再レンダリングするような変更です。これは当初FBolt.js(=Functional Bolt.js)と呼ばれてましたが、ここにさらにJSXのアイディアを加えたことで、Reactが誕生[3]しました。
誕生当初のReactのコンセプトは、今日においても受け継がれています。
- 関数型指向
- 更新に伴う再レンダリング
- コンポーネント指向
- JSX
これらのコンセプトにおいて重要なのは、Reactはシンプルなフレームワークの実現を目指していたということです。最も重視していたのは覚えやすさやパフォーマンスではなく、アプリケーション開発をスケールさせるシンプルさです。
Instagramでの採用とReactのOSS化
Reactが最初に採用されたのは、2013年に買収されたばかりのInstagramのWeb UIでした。当時Reactはまだ開発途上で、Instagramの開発と並行して改善が進められました。
Instagramで一定の成功が見えた後は、ReactのOSS化が進められました。最初の発表は2013年のJS Conf USでしたが、Reactチームはのちにこの発表を「失敗だった」と表現しています[4]。Reactは多くの面で非常に革新的なアイディアだったため、多くの人々が「うまくいくはずがない」と感じ、反発したようです。実際、Bolt.jsに再レンダリングのアイディアを組み込むことに対しても、当初は多くのチームメンバーが「うまくいかないだろう」と感じたほどなので、当時の価値観を考えると当然かもしれません。
しかし、「失敗だった」とされるJS Conf USでReactに興味を持った方がいました。後にReactチームに参画するSophie Alpert氏です。Sophie Alpert氏はJS Conf US後、Reactに2000行ものコントリビュートを行い、Reactは多くの技術的課題を解消します。多くの改善を経たReactは、改めて同年のJS Conf EUで発表され、これ以降Reactは加速度的に大きな人気を得ていきます。
Reactの拡大
JS Conf EU以降、ReactはNetflixやAirbnbなど多くの企業で採用されました。関連ライブラリも発展し、Reactのエコシステムと人気は急速に拡大していきます。
その後も、Hooksの発明や並行レンダリングなど様々な改善が取り込まれますが、破壊的変更は最小限にとどめられ、Reactの人気は確固たるものになっていきます。
ReactとGraphQL
React同様、Metaが開発し現在でも広く使われている技術の1つにGraphQLがあります。
Metaでは昔からクライアントサイド・API Gateway(=BFF)・バックエンドの3層構成を基本としており、クライアントサイド〜BFF間にREST APIを採用すると以下のような課題が発生するため最適解ではないと考えられていました。
- 複数エンドポイントからデータ取得するとネットワーク効率が悪い
- Over-fetching: 取得するデータが過剰になる場合がある
- Under-fetching: 取得するデータが不足する場合がある
これらの課題を解決すべく開発されたのが、GraphQLです。
2013年にReactが本格的に採用されると、ReactとGraphQLを統合する必要が出てきました。これを実現すべく開発されたのがRelayです。RelayはFragment Colocationを用いて、Reactコンポーネントが必要とするデータを自身で定義できるようなアーキテクチャを採用しています。
const authorDetailsFragment = graphql`
fragment AuthorDetails_author on Author {
name
photo {
url
}
}
`;
export default function AuthorDetails({ author }: Props) {
const data = useFragment(authorDetailsFragment, author);
// ...
}
このことは以下Thinking in Relayや、初期のREADMEでも述べられています。
GraphQLとRelayは2015年にOSS化され、Meta社内ではReact&Relay(GraphQL)の構成がスタンダードとなりました。
Metaの考えるGraphQL
前述の通りMetaにとってGraphQLはBFFに対する通信、つまりフロントエンドの問題を解決する技術です。BFF〜バックエンド間の通信は、ThriftというRPCを開発し採用しています。
一方、Meta以外でGraphQLを採用してるケースでは、バックエンドへの通信プロトコルとして採用されることも多く見られます。

ここでも「見てる世界」の違いが見て取れます。GraphQL自体はBFF構成に依存する技術ではないのでバックエンド側でも採用は可能ですが、開発元であるMetaのモチベーションはあくまで、BFFありきのフロントエンド〜BFF通信の課題を解決することです。そのため、バックエンドとの通信には採用されていません。
自律分散的アーキテクチャ
前述の通り、Relayはコンポーネントが必要とするデータを自身で定義できるようなアーキテクチャを採用しています。Reactのコンポーネント指向やGraphQLのResolver、Relay、これらに一貫して見て取れるのは強いカプセル化であり、いわば自律分散性です。Metaでは、大規模開発でスケールするにはこれらを重視した自律分散的アーキテクチャこそ最適だと考えていることがわかります。
一方、自律分散的アーキテクチャと対立的な立場として考えられるのは中央集権的アーキテクチャです。何かしら中央集権な層を配置し、一元管理するようなアーキテクチャです。先述のMVCやReduxは中央集権的アーキテクチャの1種であると考えられます。
- 自律分散的アーキテクチャ: 責務を末端に分散配置し、自律性を重視するアーキテクチャ
- 中央集権的アーキテクチャ: 責務を中央に集約し、一元管理を重視するアーキテクチャ
データフェッチの中央集権と自律分散性
中央集権的アーキテクチャの思考でデータフェッチを考えると、データフェッチを一括管理する層が必要になります。Reactにおいてはルートコンポーネントなどの祖先コンポーネントがこれを担うことになるため、データフェッチの結果はトップダウンにバケツリレーされます。

一方RelayではFragment Colocationを用いて、必要なデータを自身で定義できます。さらに言えば、GraphQLサーバーの各Resolverも自律的にデータフェッチを行います。
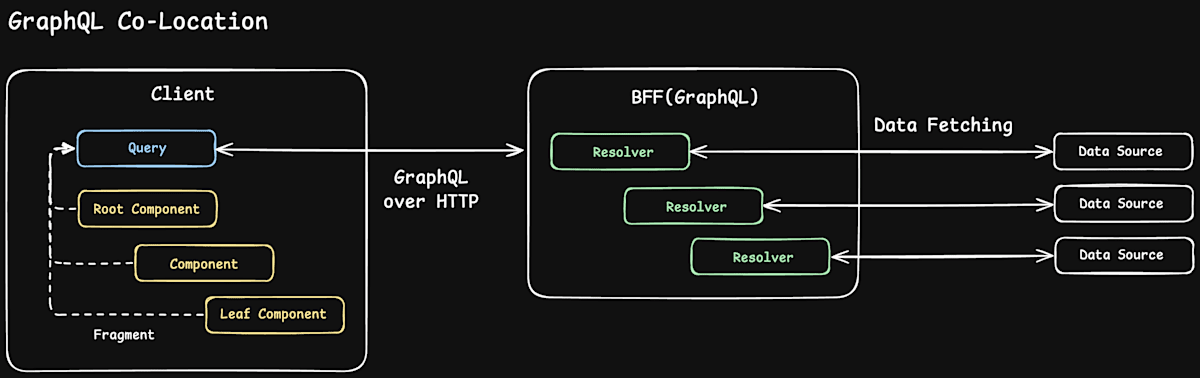
クライアントサイド〜BFFの通信は1つにまとめられていますが、これはRelayがFragmentをまとめて1つのQueryに集約していることで成り立っています。
Flux/Reduxに見る中央集権的アーキテクチャ
Reactチームは最初から中央集権的アーキテクチャを否定していたわけではありません。
Hooksが登場するまで、Reactは典型的な中央集権的アーキテクチャであるFluxアーキテクチャと組み合わせて使うことがベストプラクティスとされていました。このことからReactチームはMVCを否定しつつも、当初はFluxによる中央集権的アーキテクチャ+Reactの自律分散的アーキテクチャを併用した、複合的なアーキテクチャに理想を見ていたように感じられます。2016年にFlux系ライブラリとして最も人気だったReduxの作者であるDan Abramov氏とAndrew Clark氏をReactチームに招いていることからも、中央集権的アーキテクチャを当初から否定していたわけではないことが伺えます。
しかし実際には、彼らが参画しHooksやReact Fiberなど多くの発展があった中に中央集権的アーキテクチャは見られなくなっていきました。研究が進むにつれて、Metaのような大規模開発においては自律分散的アーキテクチャこそが最適であると、Reactチームは考えるようになったものと思われます。
React Server Components
Metaの大規模開発はReact+Relay(GraphQL)により安定した成長を続け、現在でもこれらの技術は多くのプロダクトを支えています。
しかし、当然ながら全く問題がなかったわけではありません。Reactアプリケーションが肥大化するにつれ、様々な問題が見えてきました。
- バックエンドアクセス
- 冗長な実装
- セキュリティ
- パフォーマンス
- バンドルサイズ
- 不要なバンドル、冗長なバンドル
- 最適化コスト
- 抽象化コスト
- etc...
Reactチームはこれらの問題に対して個別の対処を検討しますが、最終的にはこれらの問題は一貫して「Reactがサーバーを活用できてない」ことに起因してると結論付けられました。この問題に対処すべく新たに設計されたのが、2020年に発表されたReact Server Componentsです。
React Server Componentsにより、上記の問題は以下のように解決されました。
- バックエンドフルアクセス
- 0バンドルサイズ(ただし、バンドルサイズは必ずしも減るわけではない)
- 自動コードスプリッティング
- 0コスト抽象化
- etc...
React Server Componentsの自律分散性
Server Componentsの登場により、データフェッチもまたコンポーネントにカプセル化することが可能となりました。これは、React Server Componentsもまた自律分散性アーキテクチャを重視していることを示しています。
言い換えると、React Server ComponentsがGraphQLの精神的後継であるとも言えます。事実、React Server Componentsの最初のRFCは、RelayやGraphQLの発展をリードしてきたJoe Savona氏が提案していることからもこのことは見て取れます。
先述のGraphQLの図と、React Server Componentsにおけるデータフェッチを表した図を以下にしまします。

自律分散性を維持するためにRelayが担っていた層がなくなり、よりシンプルな設計になったと筆者は感じます。
Reactチームが見てる世界、Reactユーザーが見てる世界
Metaが自律分散的アーキテクチャを重視しているのは、異次元な大規模開発が最も大きな理由だと考えられます。Metaは独自のデータセンターを世界中に保有しており、専用のネットワークを持ち、社内のReactコンポーネントは数万以上あるそうです。そして、それら大量のコンポーネントの修正はcode modのようなツールで自動化されてるそうです。
このような異次元な大規模開発においては、中央集権的アーキテクチャではなく自律分散的アーキテクチャこそが最適でスケールできる設計であると、Metaは考えているようです。この辺りの考え方は、ReactチームがComposable(構成可能)という言葉を多用していることからも見て取れます。Metaでは実際に10年以上自律分散的アーキテクチャで開発を続け、React Server Componentsでもこの姿勢は変わってないことからも、一定の成功を収めていると言えるでしょう。
一方、我々一般的なReactユーザーの多くは、はるかに小規模なアプリケーションでReactを採用してることと思います。Reactが小規模から大規模まで幅広く通用する技術であることは疑いようはないですが、誰しもが自律分散的アーキテクチャを好んでいるわけではなく、中央集権的アーキテクチャこそシンプルだと考える人も一定数います。
| 目線 | 対象 | 自律分散的アーキテクチャ | 中央集権的アーキテクチャ |
|---|---|---|---|
| Reactチーム | 大規模開発 | 重視 | 成り立たない |
| Reactユーザー | 小規模〜中規模開発 | 一定数が重視 | 一定数が重視 |
このように、Reactチームは大規模開発で成り立つ自律分散的アーキテクチャの世界を目指しているのに対し、Reactユーザーの一部は小規模から中規模でのみ成り立つ中央集権的アーキテクチャを好んでいるため、「見てる世界が違う」と筆者は感じています。
Boomer Fetching
このように「見てる世界が違う」ことで紛糾した問題の1つが、React19 RCにおけるBoomer Fetching問題です。
GraphQLやRSCではColocationによって、コンポーネントが自身で必要なデータを定義できることを述べました。同様に、REST APIの場合にも末端でデータフェッチするようにすれば自律分散的アーキテクチャが成立します。以下は末端に配置される<UserCassette>内でデータフェッチを行う例です。
function UserCassette({ id }: { id: string }) {
const { isPending, error, data } = useQuery({
queryKey: ["user", id],
queryFn: () => fetch(`https://.../users/{id}`).then((res) => res.json()),
});
// ...
}
しかし、このような実装は規模が大きくなるにつれてアプリケーションのパフォーマンスを著しく劣化させます。クライアントサイドからBFFやBackend APIへの通信は、一般的に低速なネットワーク[5]を介して行われるため、リクエスト数が多いほど顕著にパフォーマンス劣化を引き起こします。GraphQLやRSCではColocationによって最終的にリクエストが1つにまとめられますが、REST APIではColocation相当な技術がないため、多数のリクエストが発行されパフォーマンス劣化が起こりやすくなります。

このように、低速なネットワーク上でリクエストを多数発行することをReactチームではBoomer Fetchingと呼んでいます。前述の通り、GraphQLやRSCではColocationによってリクエストは1つにまとめられるため、Boomer Fetchingは発生せずパフォーマンス劣化を抑えることができます。そのため、ReactチームにとってBoomer Fetchingは避けるべき状態であることは変わらず、GraphQLやRSCによって解決済みの問題という認識でした。
しかし、現実には多くのReactユーザーがBoomer Fetching相当な実装を好んでしていました。このような実装が好まれた背景にはいくつかの要因が考えられますが、以下の2つが要因として多かったのではないかと筆者は考えています。
- 自律分散的アーキテクチャを好むが、GraphQLやFragment Colocationを採用していなかった
- Boomer Fetchingによるパフォーマンス影響を許容したり、軽視したり、もしくは認識できてなかった
このように、「Reactチームにとってはアンチパターン、しかし一部Reactユーザーの間では好んで使われている」というすれ違いが、React19 RCでの破壊的変更に関する議論を引き起こしました。
React18までは<Suspense>配下に複数の子コンポーネントがレンダリングされた場合、それらの子コンポーネントは並行に実行され、それぞれの子コンポーネントが行うデータフェッチも並行に開始することができていました。しかし、React19 RCでは<Suspense>配下の子コンポーネントを直列実行するような破壊的変更が行われました。
export function Page({ id }) {
// `<Author>`と`<Post>`はそれぞれSuspendするものとする
// React18: `<Author>`と`<Post>`は並行に実行される
// React19(RC): `<Author>`と`<Post>`は直列に実行される
return (
<Suspense>
<Author id={id} />
<Post id={id} />
</Suspense>
);
}
このReact19 RCにおける破壊的変更はBoomer Fetchingで顕著なパフォーマンス劣化を引き起こすため、大きな議論になりました。この問題はReact19の正式版で、兄弟要素をwarm upするという仕様を追加することでReact18以前と比較しても影響が最小限になるように改善されました。
本稿では詳細な説明を割愛しているので、より詳細な内容を知りたい方は公式ブログを参照ください。
筆者の見解
最後に誤解なきよう、筆者なりの見解も述べておきます。Reactチームが重視しているのが自律分散的アーキテクチャだからと言って、必ずしもReactにおける中央集権的アーキテクチャが悪いというわけではないと、筆者は考えています。むしろ開発者の慣れや状況によって、中央集権の方が好ましいケースは往々にしてあるはずだと考えています。
筆者が重要だと思うのは、我々開発者に様々な選択肢があることです。React Server Componentsは自律分散的アーキテクチャを重視して設計されていますが、中央集権的アーキテクチャが実現できないわけではありません。Next.js Pages RouterのgetServerSideProps()や、Remix v2のloader()など、中央集権的アーキテクチャを採用したフレームワークは今後も登場することと思いますし、選択肢が増え議論が活発になることは、技術の発展にも不可欠だとも考えています。
個人的に良くないと思うのは、過剰な批判や無理解です。生産的な議論のためには、相手の状況や思想の理解に努めることが非常に重要だと考えてます。
今後、Next.js App Routerのような自律分散的アーキテクチャと、既存もしくは今後出てくる中央集権的アーキテクチャなフレームワーク、どちらが多くのReactユーザーに受け入れられていくのかは非常に興味深いところです。自律分散性アーキテクチャと中央集権的アーキテクチャ、これらの設計思想を念頭に今後のReact界隈の動向に注目していきましょう。
Discussion
FE系のアーキテクトや同僚のシニアフロントが、Reactチーム的にはRedux推しじゃないから、という感じで、ReduxからContextに移行しました。(現在はrecoilを経てjotai)そのときに感じた、Reduxみたいにステート一個しかないほうが、開発スケールしないんじゃない?と思っていた「感じ」が見事に言語化されていて、読んでしまいました。
私はReactを7年書いてきてその思想を理解していたつもりですが、改めて歴史を振り返り理解を深めることができたと思います。ありがとうございました!
React歴の浅いメンバーと仕事をしていると関数型という切り口でレビューコメントを書くことが多かったのですが、それだけでは伝え切れていない何かを言語化できずモヤモヤしていました。
自律分散型・中央集権型という視点を持つことでより俯瞰的に設計を考えることができそうです。
良記事をありがとうございます。
注1に関連して、元同僚が本来の MVC について以前発表したことがあり、WebのMVCフレームワーク(いわゆるMVC2)ではない方に興味があればこちらもご覧ください!