goqueryを使ってJR東日本の各駅の乗車人員データTOP100をcsv出力してデータ分析する


この記事で紹介していること
- Go言語でのWEBスプレイピングライブラリgoqueryの実用例
- goqueryでスクレイピング -> csv化の実用例
やりたいこと
JR東日本様が管轄している各駅の乗車人員とそのランキングのデータをWEB公開されていますのでそれをGo言語を使ってデータ分析しやすいCSV形式に保存したいと思います。
ページには21年度分の全駅!のデータまで載っています(素晴らしい😊)が今回は各年度のTOP100駅のデータをCSV化していきたいと思います。
Go言語でスクレイピングすることのメリット
- コンパイルした実行ファイルは シングルバイナリ になるのでWindows/Mac/Linuxなどのマルチプラットフォーム環境でも配布しやすく動かしやすい
- 上記と同様だがスクレイピングといえばPythonがスタンダードだが安定的にマルチプラットフォームで動かすにはDockerが必要になってくるので、配布先で動作させるにはまずDockerが必要になり準備に手間がかかるためGoに軍配があがる
開発環境
- go version go1.19 darwin/arm64
- スクレイピングライブラリ goquery
実際のコード
htmlダウンロード部分
HTMLパーサーのコード作成中にトライエンドエラーで何度もページを取得してWEBサーバー側に負荷をかけるのはマナー違反のため、ページの取得は1回ですませるためにローカルにHTMLファイルをまず保存します。
特殊なことはしていない普通のWEBページ取得コードです。
package main
import (
"fmt"
"io"
"log"
"net/http"
"os"
"path/filepath"
)
const startYear = 2000
const endYear = 2021
const baseUrl = "https://www.jreast.co.jp/passenger/"
const saveBaseDir = "htmls"
func main() {
// 存在しなければカレントディレクトリに保存フォルダを作成する
checkSaveDir(saveBaseDir)
var url string
for i := startYear; i <= endYear; i++ {
if i == endYear {
url = fmt.Sprintf("%s%s.html", baseUrl, "index")
} else {
url = fmt.Sprintf("%s%d.html", baseUrl, i)
}
fmt.Println(url)
download(url, fmt.Sprintf("%d.html", i))
}
}
func download(url, saveFilename string) {
resp, err := http.Get(url)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
out, err := os.Create(filepath.Join(saveBaseDir, saveFilename))
if err != nil {
log.Fatal(err)
}
defer out.Close()
_, err = io.Copy(out, resp.Body)
if err != nil {
log.Fatal(err)
}
}
func checkSaveDir(dir string) {
_, err := os.Stat(dir)
if err != nil {
if os.IsNotExist(err) {
err = os.Mkdir(dir, 0755)
if err != nil {
log.Fatal(err)
}
}
}
}
スクレイピング部分
コア部分を抜粋して記載
s.FindメソッドでCSSセレクタでHTMLの取得したい部分を指定。他の言語でスクレイピングやHTMLパーサーを書いていれば特段難しくないかと思います。
var stationList []string
var stationMap map[string]map[int]record
func scrape(path string, year int) {
f, err := os.Open(path)
if err != nil {
panic(err)
}
defer f.Close()
doc, err := goquery.NewDocumentFromReader(f)
if err != nil {
log.Fatal(err)
}
doc.Find("tbody > tr").Each(func(i int, s *goquery.Selection) {
rank := s.Find("td:nth-child(1)").Text()
station := s.Find("td.stationName").Text()
count := s.Find("td:nth-child(5)").Text()
if year <= 2012 {
station = s.Find("td:nth-child(2)").Text()
}
if year <= 2011 {
count = s.Find("td:nth-child(3)").Text()
}
if year <= 2019 {
station, _ = sjis2utf8(station)
}
if rank != "" {
if year == endYear {
stationList = append(stationList, station)
stationMap[station] = make(map[int]record)
}
// 10,000 -> 10000
count = strings.Replace(count, ",", "", -1)
ci, _ := strconv.Atoi(count)
ranki, _ := strconv.Atoi(rank)
yearMapBySt := stationMap[station]
// yearMapByStがnilの時は最新の年度TOP100に存在しない駅名のためSKIP
if yearMapBySt != nil {
yearMapBySt[year] = record{count: ci, rank: ranki}
stationMap[station] = yearMapBySt
}
}
})
}
func main() {
var rankCsvPrint bool
flag.BoolVar(&rankCsvPrint, "r", false, "rankCsvPrint")
flag.Parse()
stationMap = make(map[string]map[int]record)
for i := endYear; i >= startYear; i-- {
path := fmt.Sprintf("%s%d.html", "./htmls/", i)
scrape(path, i)
}
genCSV(rankCsvPrint)
}
今回のコードでのポイントとなる所
1. ページの途中からSJISになる
今回のように2000年度から2021年度までのページをスクレイピングする場合、途中で文字コードが変わるというのはありがちだと思います。そのため年度での分岐が必要になってきます
if year <= 2019 {
station, _ = sjis2utf8(station)
}
//~略~
func sjis2utf8(str string) (string, error) {
ret, err := io.ReadAll(transform.NewReader(strings.NewReader(str), japanese.ShiftJIS.NewDecoder()))
if err != nil {
return "", err
}
return string(ret), err
}
}
2. ページの途中からHTML構造が変わる
1.と同じ理由ですが年度が長くなると途中からHTML構造がかわっていきます、そのためCSSセレクタを年度をみて分岐する必要がでてきます
if year <= 2012 {
station = s.Find("td:nth-child(2)").Text()
}
if year <= 2011 {
count = s.Find("td:nth-child(3)").Text()
}
3. Windows環境を考えてCSV作成コードは手抜きせず書く(fmt.Print禁止)
最初はCSV化のコードは書かずにfmt.Printで v[0]+","+v[1]+","のように出力しファイルへリダイレクトする形で実装していましたがそれだとWindowsのPowerShellでの実行の場合悲しいことに文字化けしてしまいます(文字コードがUTF16になってしまうため)。なのでGo言語側でCSVファイル作成までやってちゃんとしたUFT8ファイルを作成する必要があります。このファイルがSJISでないのでExcelで開けないなどは別の話、今回はCSVをGoogleスプレッドシートで開く想定なのでこのままで良いですがExcelで開きたい場合はGo側でファイルをSJISで作成するコードの追記が必要になります。
func genCSV(rank bool) {
var filePath string
records := [][]string{}
checkSaveDir(csvDir)
if rank {
filePath = filepath.Join(csvDir, rankCsvFn)
} else {
filePath = filepath.Join(csvDir, countCsvFn)
}
// ヘッダ行処理
header := []string{}
header = append(header, "年度")
header = append(header, stationList...)
records = append(records, header)
for i := startYear; i <= endYear; i++ {
record := []string{}
record = append(record, strconv.Itoa(i))
for _, stationName := range stationList {
cs := stationMap[stationName]
var v int
if rank {
v = cs[i].rank
} else {
v = cs[i].count
}
record = append(record, strconv.Itoa(v))
}
records = append(records, record)
}
f, err := os.Create(filePath)
if err != nil {
log.Fatal(err)
}
w := csv.NewWriter(f)
err = w.WriteAll(records) // calls Flush internally
if err != nil {
log.Fatalln(err)
}
if err := w.Error(); err != nil {
log.Fatalln("error writing csv:", err)
}
}
実行
HTMLのダウンロード
./bin/download
TOP100駅の20年分の乗客数の推移をCSV出力
./bin/jre-passenger-data
TOP100駅の20年分のランキングの推移をCSV出力
./bin/jre-passenger-data -r
実行結果
出力されたCSVの文字コードはUTF8です、今回はGoogleスプレッドシートで読み込みしました。
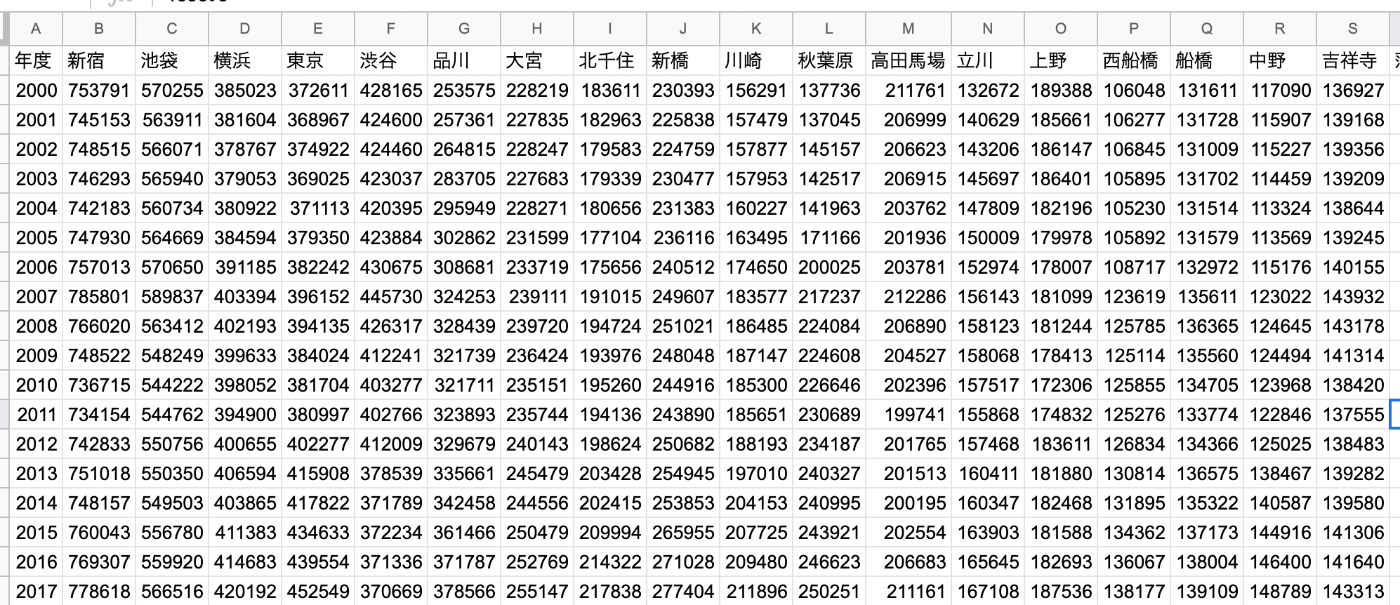
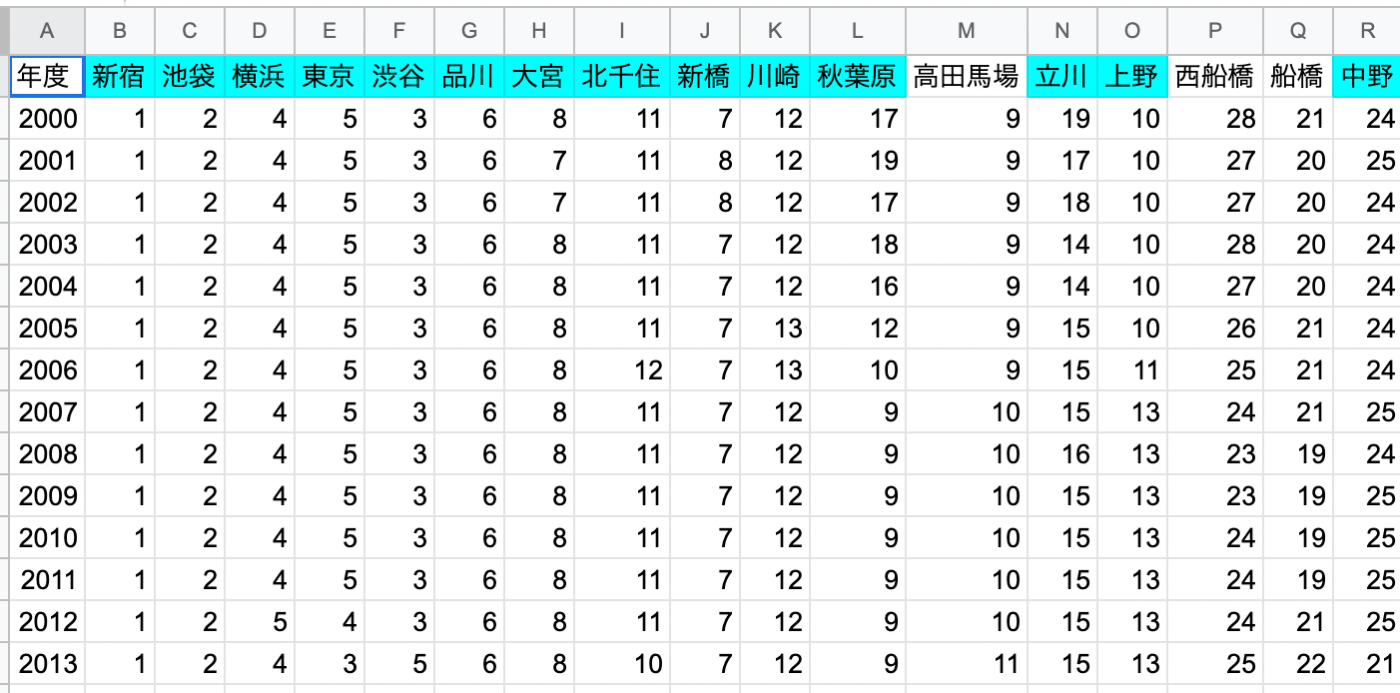
TOP100駅の20年分の乗客数の推移
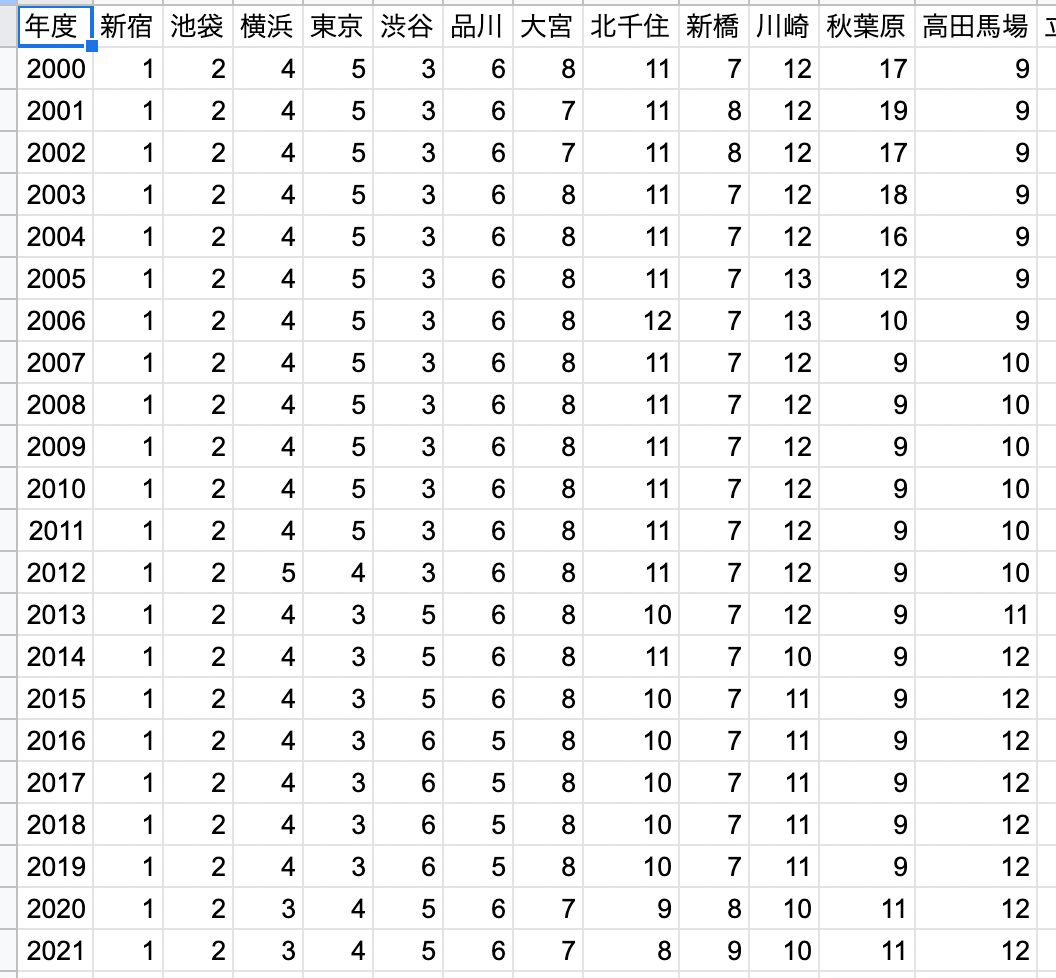
TOP100駅の20年分のランキングの推移
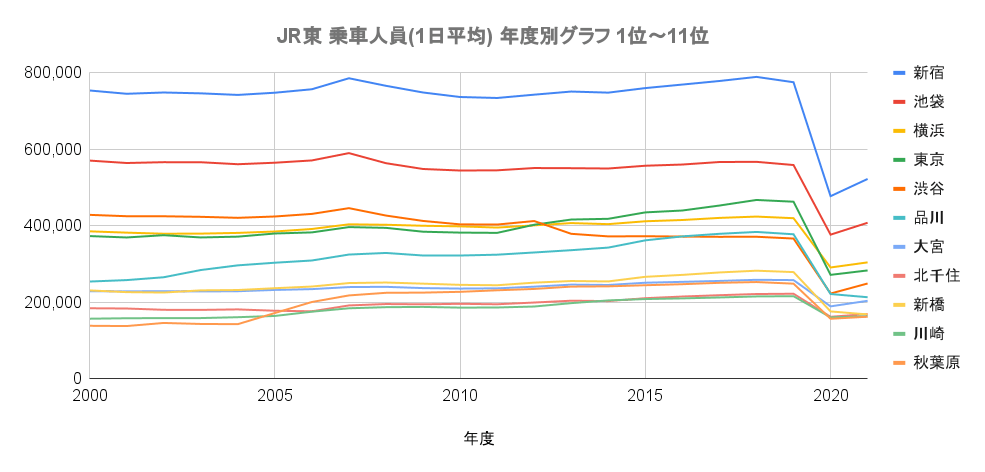
乗客数推移をグラフ化するとこんな感じです、コロナの影響が一目瞭然となります。
2022年度(今年度)でどこまで復活できるか、私気になります。
ランキング推移をグラフ化するとこんな感じです。Googleスプレッドシートの場合グラフ化する場合は全数値に*-1してグラフの表記をマイナスがでないようにいじる必要があります。
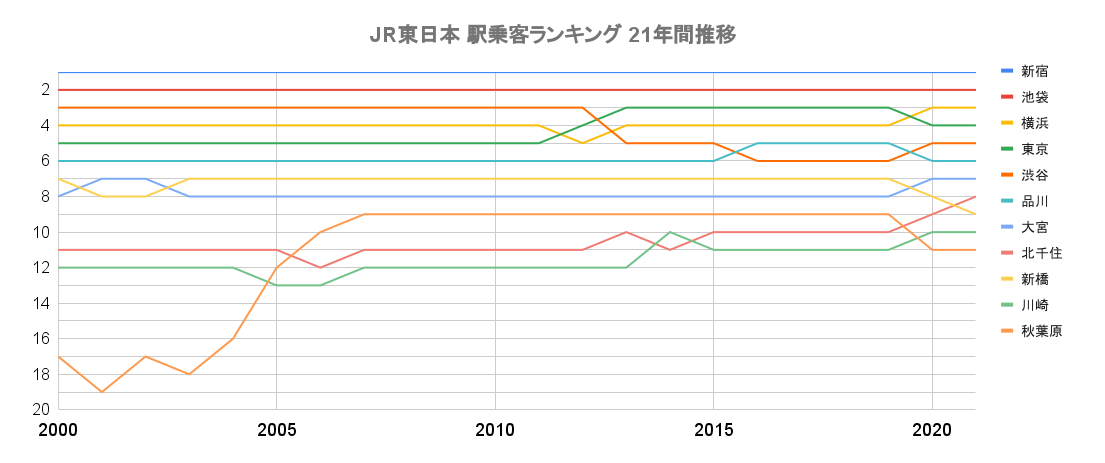
秋葉原がここ20年で異常な伸びをしているのがわかります(近年はコロナの影響で少しダウン)
出力したデータの使い道
- 引っ越し先の基準に使う =>引っ越し先の最寄り駅がどれだけ活発なのかをチェック。
- 地域経済のウォッチにつかう =>乗り入れが多い駅が活発な駅だ!という解釈で。
- 自身が行ったことがある駅かをTOP100からチェックする。TOP100コンプリートを目指す。
行った駅に色を塗ってみました。高田馬場駅は行ったことありません・・
コードを改良してみよう(したい)
TOP100の遷移に関しては年度ごとの1ページ目を取得するだけで実装できますが(20年間なら20ページ)、乗客数ワースト100駅の20年の変化を同じように生成するには全ページの取得が必要になる(とはいってもそこまでページ数はないですが)ため、サーバー側の負荷を考えてSleepをHTML取得部分に盛り込む必要があります。またデータも増えるためSQLiteなどの導入を検討してもよいでしょう。ワースト100駅推移を出すと、準秘境駅(※)めぐりに使えたり、インスタ映え駅めぐりなどができるかもしれません。ちょうどJR東日本が2万円台で新幹線込の乗り放題切符を販売しているのでそれを使って行ってみると面白いのではないでしょうか。
※秘境駅には定義があるようなので、単純に乗客数が少ない=秘境駅ではない
今回記事のソースコード
ここに配置しています
Discussion