Webassemblyコンパイラを自作しよう
この記事はBuild your own WebAssembly Compilerを翻訳・意訳したものです。また独自の説明を加えた部分もあります。
前置き
もしあなたがWebAssemblyについて聞いたことがなく、本当に詳しい紹介をしてほしいのであれば、Lin Clark氏のCartoon Guideを読むことをお勧めします。
このブログ記事ではWebAssemblyが「何か」を学ぶことができますが、「なぜ存在するのか」についても簡単に触れておきたいと思います。
私の視点では、この図が非常に簡潔にまとめられています。
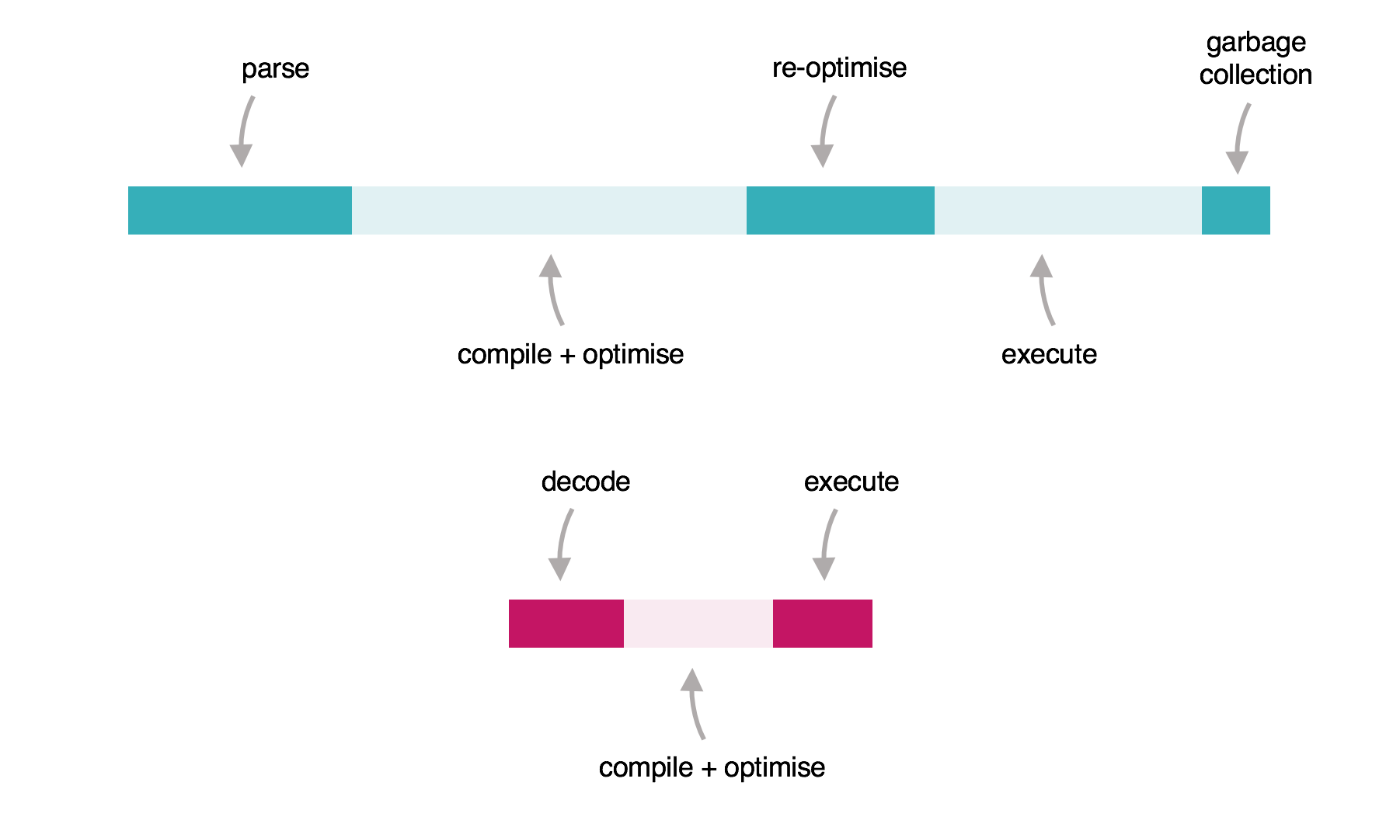
上の図は、ブラウザ内での JavaScriptコードの実行を簡略化したタイムラインです。左から右に向かって、コード(一般的にはminifyされた状態で提供されます)は AST に解析され、最初はインタプリタで実行され、徐々に最適化/再最適化されて、最終的には非常に高速に実行されます。最近のJavaScriptは高速ですが、スピードアップするのに時間がかかります。
下の図は、WebAssemblyに相当するものです。さまざまな言語(Rust、C、C#など)で書かれたコードは、WebAssemblyにコンパイルされ、バイナリ形式で提供されます。これは非常に簡単にデコード、コンパイル、実行され、高速で予測可能なパフォーマンスを提供します。
なぜ自作するのか?
昨年、WebAssemblyは大きな反響を呼びました。Stack Overflowの開発者調査では、「最も愛されている」言語の第5位に選ばれたほどです。
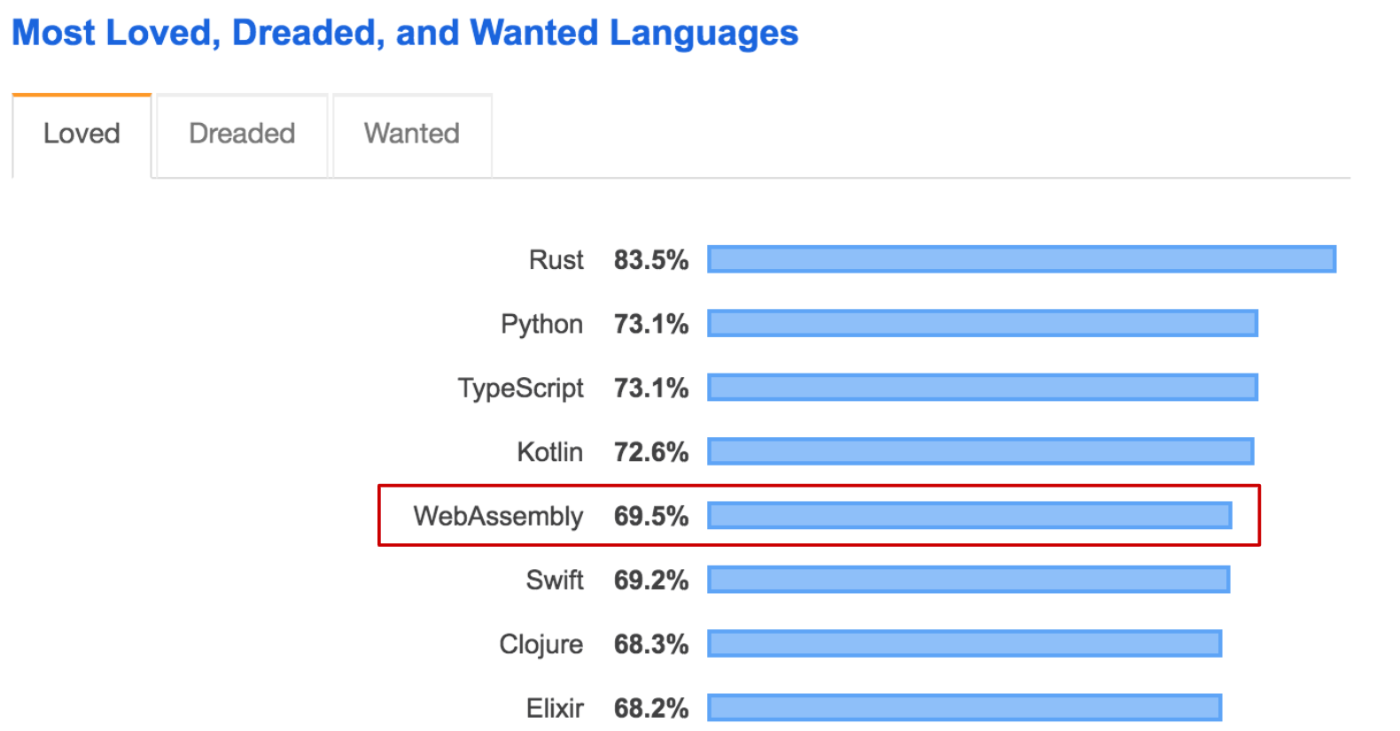
ほとんどの人にとって、WebAssemblyは直接使う言語ではなく、コンパイルの対象であることを考えると、興味深い結果です。
WebAssemblyの技術的な側面はとても魅力的ですが、ほとんどの人はWebAssembly自体に触れる機会はないでしょう。
コンパイラを書くことは、WebAssemblyが何であり、どのように機能するのかを知るために、WebAssemblyの詳細を掘り下げるとても良い機会です。そして、それは楽しいことでもあります。
最後に、私の目的は、完全な機能を持ったプログラミング言語や、実際に優れた言語を作ることではありませんでした。
私の目標は、マンデルブロ集合をレンダリングするプログラムを書けるのに「十分な」言語を作ることでした。この言語は、私がTypeScriptで開発したブラウザ上で動作するコンパイラを使ってWebAssemblyにコンパイルされます。

私はこの言語を「chasm」と名付けました。 ここで試すこともできます!
最小限のWasmモジュール
まずはコンパイラに取り組む前に、もっと簡単な、最小のWebAssemblyモジュールを作成してみましょう。
ここでは、最小の有効なWebAssemblyモジュールを作成するエミッタを紹介します。(エミッタ: ターゲットシステム用の命令を出力するコンパイラの一部に使われる用語)
const magicModuleHeader = [0x00, 0x61, 0x73, 0x6d];
const moduleVersion = [0x01, 0x00, 0x00, 0x00];
export const emitter: Emitter = () => {
return Uint8Array.from([
...magicModuleHeader,
...moduleVersion
]);
}
これは、ASCII文字列で0asmを表すマジックヘッダと、バージョン番号の2つの部分で構成されています。
これらの8バイトは有効なWebAssemblyモジュールを形成します。より一般的には、これらはブラウザに .wasm ファイルとして配信されます。
WebAssemblyモジュールを実行するには、以下のようにインスタンス化する必要があります。
const wasm = emitter();
const instance = await WebAssembly.instantiate(wasm);
上のコードを実行すると、インスタンスが実際には何もしていないことに気づくでしょう。なぜなら、wasmモジュールには命令が含まれていないからです
このコードを自分で試してみたいという方は、GitHubにすべてのステップのコミットがあります。
Add関数
2つの浮動小数点数を足す関数を実装して、wasmモジュールにもっと便利なことをさせてみましょう。
WebAssemblyはバイナリ形式で、(少なくとも人間には)あまり読みやすくありませんので、通常はWebAssembly Text Format (WAT)で書かれています。
以下はWAT形式のモジュールで、2つの浮動小数点パラメータを受け取り、それらを加算して返す$addというエクスポート関数を定義しています。
(module
(func $add (param f32) (param f32) (result f32)
get_local 0
get_local 1
f32.add)
(export "add" (func 0))
)
WATを試してみたい方は、WebAssembly Binary Toolkitのwat2wasmツールを使って、WATファイルをwasmモジュールにコンパイルすることができます。
上記のコードは、WebAssemblyに関するいくつかの興味深い詳細を示しています。
- WebAssemblyは低レベルの言語で、小さな(約60)命令セットを持ち、多くの命令がCPUの命令に非常によく似ています。これにより、wasmモジュールをCPU固有のマシンコードにコンパイルすることが容易になります。
- I/Oが内蔵されていません。端末や画面、ネットワークに書き込むための命令もありません。Wasmモジュールが外界と対話するためには、ホスト環境(ブラウザの場合はJavaScript)を介して行う必要があります。
- WebAssemblyはスタックマシンです。上の例では、
get_local 0は0番目のインデックスのローカル変数(この場合は関数のparam)を取得し、後続の命令と同様にそれをスタックにプッシュしています。f32.add命令は、スタックから2つの値をポップし、それらを足して、その値をスタックに戻します。 - WebAssemblyには、2つの整数型と2つの浮動小数点型の4つの数値型しかありません。これについては後で説明します。
このハードコードされたWebAssemblyモジュールを出力するように、エミッタを更新してみましょう。
WebAssemblyモジュールは、あらかじめ定義された省略可能なセクションで構成されており、それぞれのセクションの前には数字の識別子が付いています。
これらには、型シグネチャをエンコードする型セクションと、各関数の型を示す関数セクションがあります。
wasmモジュールは数バイトのヘッダと「セクション」と呼ばれる領域が複数連なる形で構成されます。
wasmモジュールの先頭は、必ず 0x00 0x61 0x73 0x6D の 4 バイトから始まります。いわゆるマジックナンバーで、ASCIIコードで表すと"\0asm"となります。その次の 4 バイトはバージョンを表します。本誌執筆時点でのバージョンは 1 のみで、0x01 0x00 0x00 0x00 です。
これらは先程の最小限のwasmモジュールとして実装したものです。
そしてそれ以降は「セクション」と呼ばれる領域が末尾まで連続します。ざっと図にすると以下のようなイメージです。
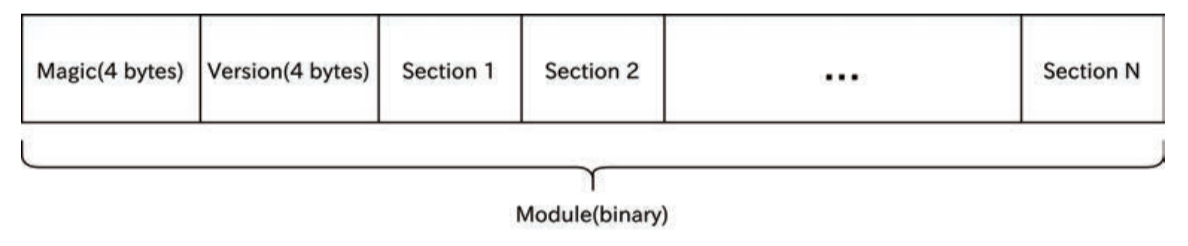
興味深いのは、コードセクションです。ここでは、上記のadd関数がバイナリでどのように作られているかを紹介します。
const code = [
Opcodes.get_local /** 0x20 */,
...unsignedLEB128(0),
Opcodes.get_local /** 0x20 */,
...unsignedLEB128(1),
Opcodes.f32_add /** 0x92 */
];
const functionBody = encodeVector([
...encodeVector([]) /** locals */,
...code,
Opcodes.end /** 0x0b */
]);
const codeSection = createSection(
Section.code, /** 0x0a */
encodeVector([functionBody])
);
ここではTypeScriptでOpcodes enumを定義しました。この中には、すべてのwasm命令が含まれています。unsignedLEB128関数は、標準的な可変長エンコーディングで、命令のパラメータをエンコードするのに使われます。
関数の命令は、その関数のローカル変数(この場合はありません)と、関数の終了を知らせるendというオペコードを組み合わせます。
最後に,すべての関数がセクションにエンコードされます。encodeVector関数は、バイト配列の集合の前に全長を付けるだけです。
以上で、合計約30バイトのモジュールが完成しました。
JavaScriptのホストコードは、このエクスポートされた関数を含むように更新することができます。
const { instance } = await WebAssembly.instantiate(wasm);
console.log(instance.exports.add(5, 6));
興味深いことに、エクスポートしたadd関数をChrome Dev Toolsで検査すると、「ネイティブ関数」として識別されます。
ユニットテストも含めたこのステップの完全なコードはGitHubで見ることができます。
コンパイラを作ろう
wasmモジュールを動的に作成する方法がわかったところで、今度はコンパイラを作成する作業に目を向けてみましょう。
まず、用語の説明から始めます。
ここでは、言語の主要なコンポーネントを示すために注釈を付けたchasmのコードを紹介します。
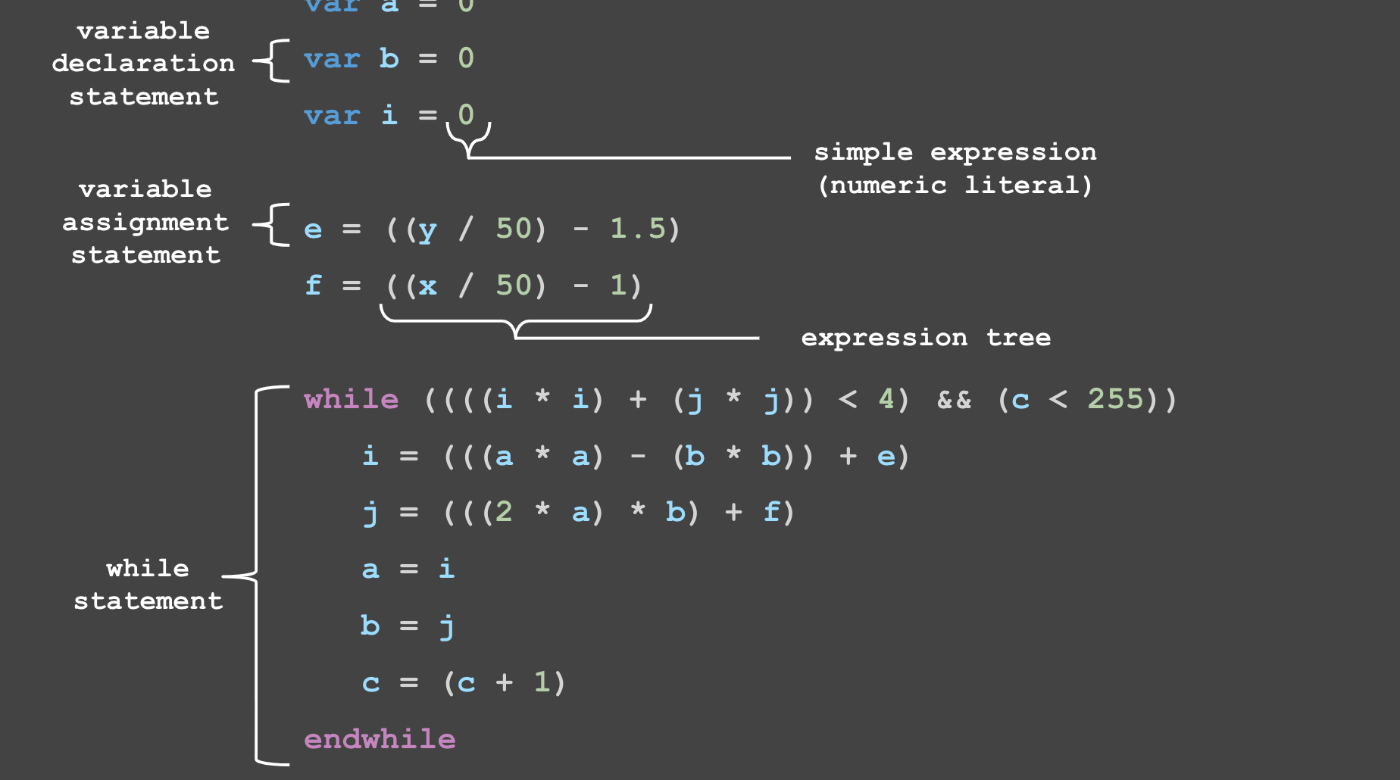
それぞれについて教科書的な定義をするのではなく、コンパイラが進化していく中で、それらに精通していくことになります。
コンパイラ自体は3つの部分から構成されています。
- 入力プログラム(文字列)をトークンに分割するトークナイザ
- これらのトークンを抽象構文木(AST)に変換するパーサ
- そして最後にASTをwasmのバイナリモジュールに変換するエミッタ
です。
これは、ごく標準的なコンパイラのアーキテクチャです。
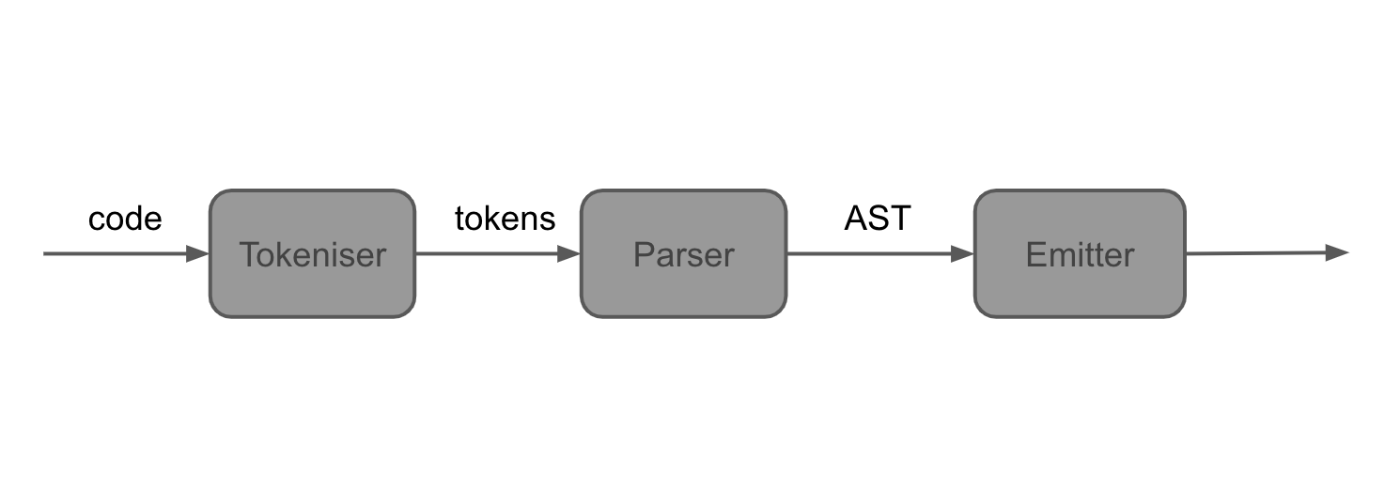
ここではwasmコンパイラの完全な実装を目指すのではなく、小さなサブセットの実装に取り組むことにします。
今回の目標は、chasm言語の単純な数値リテラルを表示するprint文をサポートするだけのコンパイラを作成することです。
print 22
print 45
トークナイザ
トークナイザは、入力文字列を1文字ずつ進めていき、特定のトークンタイプを表すパターンにマッチさせます。
次のコードでは、単純な正規表現を使って、3つのマッチ(number、keyword、whitespace)を作成しています。
const keywords = ["print"];
// returns a token if the given regex matches at the current index
const regexMatcher = (regex: string, type: TokenType): Matcher => {
return (input: string, index: number) => {
const match = input.substring(index).match(regex);
return (
match && {
type,
value: match[0]
}
);
};
}
const matchers = [
regexMatcher("^[.0-9]+", "number"),
regexMatcher(`^(${keywords.join("|")})`, "keyword"),
regexMatcher("^\\s+", "whitespace")
];
(これらの正規表現は割とガバガバです)
Matcherインターフェイスは、入力文字列inputとインデックスindexが与えられ、マッチした場合にトークンを返す関数を定義します。
トークナイザの本体は、文字列の文字を繰り返し処理して、最初にマッチしたものを見つけ、提供されたトークンを出力配列に追加します。
export const tokenize: Tokenizer = input => {
const tokens: Token[] = [];
let index = 0;
while (index < input.length) {
const matches = matchers.map(m => m(input, index)).filter(f => f)
const match = matches[0];
if (match.type !== "whitespace") {
tokens.push(match);
}
index += match.value.length;
}
return tokens;
};
このトークナイザにprint 23.1という文字列を食わせてみると次のような出力が得られます。
[
{
"type": "keyword",
"value": "print",
"index": 1
},
{
"type": "number",
"value": "23.1",
"index": 7
}
]
上記の入力からわかるように、トークナイザは(今回は)意味のないホワイトスペースを削除し、入力文字列のすべてが有効なトークンであることを確認します。
しかし、入力が文法上正しいかどうかは保証されていません。
例えば、今回実装したトークナイザは "print print" を喜んで扱いますが、これは文法的に明らかに間違っています。
出力されたトークンの配列は、次にパーサに渡されます。
パーサ
パーサの目的は,トークン間の関係をコード化した木構造である抽象構文木(AST)を作成することです。その結果、インタプリタに送られて直接実行される可能性のあるフォームができあがります。
パーサは、与えられたトークンを繰り返し処理し、eatToken関数でトークンを消費します。
export const parse: Parser = tokens => {
const iterator = tokens[Symbol.iterator]();
let currentToken = iterator.next().value;
const eatToken = () => {
currentToken = iterator.next().value;
return currentToken;
};
[...]
const nodes: StatementNode[] = [];
while (index < tokens.length) {
nodes.push(parseStatement());
}
return nodes;
};
eatTokenの命名のトークンを食べるという概念がどこから来ているのかはわかりませんが、標準的なパーサの用語のようです。
上記のパーサの目的は、トークンの配列をステートメント(statement, 文)の配列に変えることです。
ステートメントは、この言語の中心的な構成要素です。与えられたトークンがこのパターンに適合していることを期待し、適合していない場合はエラー(上には表示されていません)を投げます。
parseStatement関数は、各ステートメントがキーワードで始まることを期待し、キーワードによって処理を切り替えます。
const parseStatement = () => {
if (currentToken.type === "keyword") {
switch (currentToken.value) {
case "print":
eatToken();
return {
type: "printStatement",
expression: parseExpression()
};
}
}
};
現在,サポートされているキーワードはprintのみで,この場合,関連する式を解析したprintStatementタイプのASTノードを返します.
そして,これが式(expression)のパーサです.
const parseExpression = () => {
let node: ExpressionNode;
switch (currentToken.type) {
case "number":
node = {
type: "numberLiteral",
value: Number(currentToken.value)
};
eatToken();
return node;
}
};
現在の形式では、この言語は1つの数字で構成された式、つまり数値リテラルのみを受け入れます。
そのため、上記で実装した式のパーサは、次のトークンが数字であることを期待しており、これが一致すると、numberLiteral型のノードを返します。
"print 23.1"を対象として実行すると、パーサは次のようなASTを出力します。
[
{
"type": "printStatement",
"expression": {
"type": "numberLiteral",
"value": 23.1
}
}
]
この言語のASTは、ステートメントノードの配列であることがお分かりいただけると思います。
構文解析(パーサによるAST生成処理)は、入力されたプログラムが文法的に正しいこと、つまり適切に構築されていることを保証しますが、プログラムが正常に実行されることを保証するものではないことに注意してください。つまりランタイムエラーが発生するかもしれません。
いよいよ最後のステップに入ります!
エミッタ
現在、エミッタはハードコードされたadd関数を出力しています。これからは、このASTを受け取って、次のように適切な命令を出力する必要があります。
const codeFromAst = ast => {
const code = [];
const emitExpression = node => {
switch (node.type) {
case "numberLiteral":
code.push(Opcodes.f32_const);
code.push(...ieee754(node.value));
break;
}
};
ast.forEach(statement => {
switch (statement.type) {
case "printStatement":
emitExpression(statement.expression);
code.push(Opcodes.call);
code.push(...unsignedLEB128(0));
break;
}
});
return code;
};
エミッタは、ASTのルートを形成するステートメントを繰り返し処理し、唯一のステートメントタイプであるprintにマッチします。
WebAssemblyはスタックマシンなので、式の命令が最初に処理され、結果がスタックに残ることを思い出してください。
print関数は call オペレーションによって実装され、インデックス0で関数を呼び出します。
前回までに、wasmモジュールがどのように関数をエクスポートできるかを見てきましたが、逆にwasmモジュールをインスタンス化する際に、関数をwasmモジュールへとインポートすることもできます。ここでは、コンソールにログを出力する env.print 関数を提供しています。
const instance = await WebAssembly.instantiate(wasm, {
env: {
print: console.log
}
});
この関数は、インデックスでアドレス指定できます。つまりcall 0です。
この時点でのコンパイラの完全なコードはGitHubで見ることができます。また、オンラインのchasm compiler playgroundでもこの例を試すことができます。
また、理解を深めるためにプログラムがコンパイラの様々な段階を経て進行する様子を示します。

これまで、かなり多くのデータ構造を導入してきましたが、その効果はあまり感じられませんでした。現時点ではトークナイザ、パーサ、エミッタを別々に用意することは、単純な数値を表示するだけの言語にとっては過剰な作業です。
しかし、言語の複雑さが増してくると、このアーキテクチャが大きな効果を発揮するようになります!
式の実装
次は、二項演算式(binary expression)の実装について見てみましょう。
これにより、言語で簡単な数値演算を実行できるようになります。例えば、((42 + 10) / 2)を実行して結果を表示できるようになります。
トークナイザの変更点は非常に些細なもので、括弧や演算子のためにいくつかの正規表現のMatcherを追加することです。ここではそれらのコードは省いて、結果の出力を示すだけにしておきます。
[
{ "type": "keyword", "value": "print" },
{ "type": "parens", "value": "(" },
{ "type": "parens", "value": "(" },
{ "type": "number", "value": "42" },
{ "type": "operator", "value": "+" },
{ "type": "number", "value": "10" },
{ "type": "parens", "value": ")" },
{ "type": "operator", "value": "/" },
{ "type": "number", "value": "2" },
{ "type": "parens", "value": ")" }
]
次は、パーサの変更点を見てみましょう。今回、式のパーサは、numberとparensのどちらのトークンにも遭遇する可能性があるのでparensを処理するコードを追加しましょう。
const parseExpression = () => {
let node: ExpressionNode;
switch (currentToken.type) {
case "number":
[...]
case "parens":
eatToken();
const left = parseExpression();
const operator = currentToken.value;
eatToken();
const right = parseExpression();
eatToken();
return {
type: "binaryExpression",
left, right, operator
};
}
};
今回のパーサは再帰下降構文解析を採用しています。つまりparens式の構文解析は再帰的に行われ、左と右のノードがもう一度parseExpression関数を呼び出していることに注意してください。
プログラムprint ((42 + 10) / 2)のASTは以下の通りです。
[{
type: "printStatement",
expression: {
type: "binaryExpression",
left: {
type: "binaryExpression",
left: {
type: "numberLiteral",
value: 42
},
right: {
type: "numberLiteral",
value: 10
},
operator: "+"
},
right: {
type: "numberLiteral",
value: 2
},
operator: "/"
}
}];
この例では、ツリー構造がより明確になっています。
最後に、エミッタはbinaryExpressionノードタイプを処理できるように、次のように更新します。
const emitExpression = (node) =>
traverse(node, (node) => {
switch (node.type) {
case "numberLiteral":
code.push(Opcodes.f32_const);
code.push(...ieee754(node.value));
break;
case "binaryExpression":
code.push(binaryOpcode[node.operator]);
break;
}
});
上記コードのtraverse関数は、各ノードに対して与えられたビジターを起動して木構造をトラバースします。
線形な構造の場合は論理的に一つの方法でしか走査できませんが、木構造はいくつもの異なる方法で走査できます。
つまり、各ノードに遭遇すると、左、右、ルートの順に訪問します。この順序により、スタックマシンに対して正しい順序でwasm命令が出力されることになり、オペランド、演算子の順になります。
以上で、式をサポートするために必要なすべての変更が完了しました。オンラインで試してみてください。
コンパイラのアーキテクチャがその価値を証明し始めています。
変数
次は、変数を追加しましょう。
変数を追加することで、次のようなより面白いchasmプログラムが可能になります。
var f = 2
print (f + 1)
変数はvarキーワードで宣言され、識別子として式の中で使用することができます。
トークナイザの変更点についてはここでは触れませんが、これは単なる正規表現の追加です。
トークン配列から連続した文を読み取るパーサのメインループは、出会ったキーワードに基づいて文の種類を決定します。
const parseVariableDeclarationStatement = () => {
eatToken(); // var
const name = currentToken.value;
eatToken();
eatToken(); // =
return {
type: "variableDeclaration",
name,
initializer: parseExpression()
};
};
const parseStatement: ParserStep<StatementNode> = () => {
if (currentToken.type === "keyword") {
switch (currentToken.value) {
case "print":
return parsePrintStatement();
case "var":
return parseVariableDeclarationStatement();
}
}
};
変数宣言の解析は非常に簡単です。parseVariableDeclarationStatement関数は、式パーサも利用しており、var f = (1 + 4)などの式から変数を宣言して初期値を割り当てることができるようになっています。
次は、エミッタです。WebAssemblyの関数はローカル変数を持つことができ、これらは関数定義の最初に宣言され、関数のパラメータを取得するget_local関数とset_local関数を介してアクセスされます。
ASTの変数はその識別子名で参照されますが、wasmはローカル変数をそのインデックスで識別します。
エミッタはこの情報をシンボルテーブルに保持する必要がありますが、これはシンボル名からインデックスへの単純なマップです。
const symbols = new Map<string, number>();
const localIndexForSymbol = (name: string) => {
if (!symbols.has(name)) {
symbols.set(name, symbols.size);
}
return symbols.get(name);
};
ノードのtraverseの中で、変数宣言に遭遇すると、その式が出力され、set_localを使って、それぞれのローカル変数に値を割り当てます。
case "variableDeclaration":
emitExpression(statement.initializer);
code.push(Opcodes.set_local);
code.push(...unsignedLEB128(localIndexForSymbol(statement.name)));
break;
式の中で、識別子が見つかった場合は、get_localを使って値を取得します。
case "identifier":
code.push(Opcodes.get_local);
code.push(...unsignedLEB128(localIndexForSymbol(node.value)));
break;
また、最初に見た関数のエンコーディングが更新され、エミッタが構築する関数のロケールが追加されます。chasm言語の変数の型は1つで、すべて浮動小数点です。
変数を定義し、print文で使用してみましょう。いつものようにオンラインで試すことができます!
whileループ
マンデルブロ集合のレンダリングという目標を達成するために必要な最終的な言語構成の1つは、ある種のループです。
chasmではwhileループを選択し、0から9までの数字を印刷するこのシンプルなプログラムで示しています。
var f = 0
while (f < 10)
print f
f = (f + 1)
endwhile
WebAssemblyには様々な制御フロー命令(branch, if, else, loop, block)があります。次のWATはwhileループがどのように構成されるかを示しています。
(block
(loop
[loop condition]
i32.eqz
[nested statements]
br_if 1
br 0)
)
WebAssemblyでの分岐はスタックの深さに基づいています。外側のblockとloop命令は、control-flowスタックにエントリをプッシュします。br_if 1命令はスタック深さ1への条件付き分岐を行い、br 0はスタック深さ0への無条件分岐を行い、loopを繰り返します。
以下は、エミッタが上と同じものをバイナリ形式で生成する様子です。
case "whileStatement":
// outer block
code.push(Opcodes.block);
code.push(Blocktype.void);
// inner loop
code.push(Opcodes.loop);
code.push(Blocktype.void);
// compute the while expression
emitExpression(statement.expression);
code.push(Opcodes.i32_eqz);
// br_if $label0
code.push(Opcodes.br_if);
code.push(...signedLEB128(1));
// the nested logic
emitStatements(statement.statements);
// br $label1
code.push(Opcodes.br);
code.push(...signedLEB128(0));
// end loop
code.push(Opcodes.end);
// end block
code.push(Opcodes.end);
break;
画面描画
私たちはゴールのもうすぐそこまで来ています!
現在、私たちがchasmプログラムからの出力を見るためには、WebAssemblyモジュールによってインポートされた関数を介してコンソールに接続されたprintステートメントを利用するのが唯一の方法です。
マンデルブロ集合では、文字ではなく、画像をスクリーンに表示する必要があります。
これを実現するために、WebAssemblyモジュールのもう一つの非常に重要なコンポーネントである線形メモリを利用します。
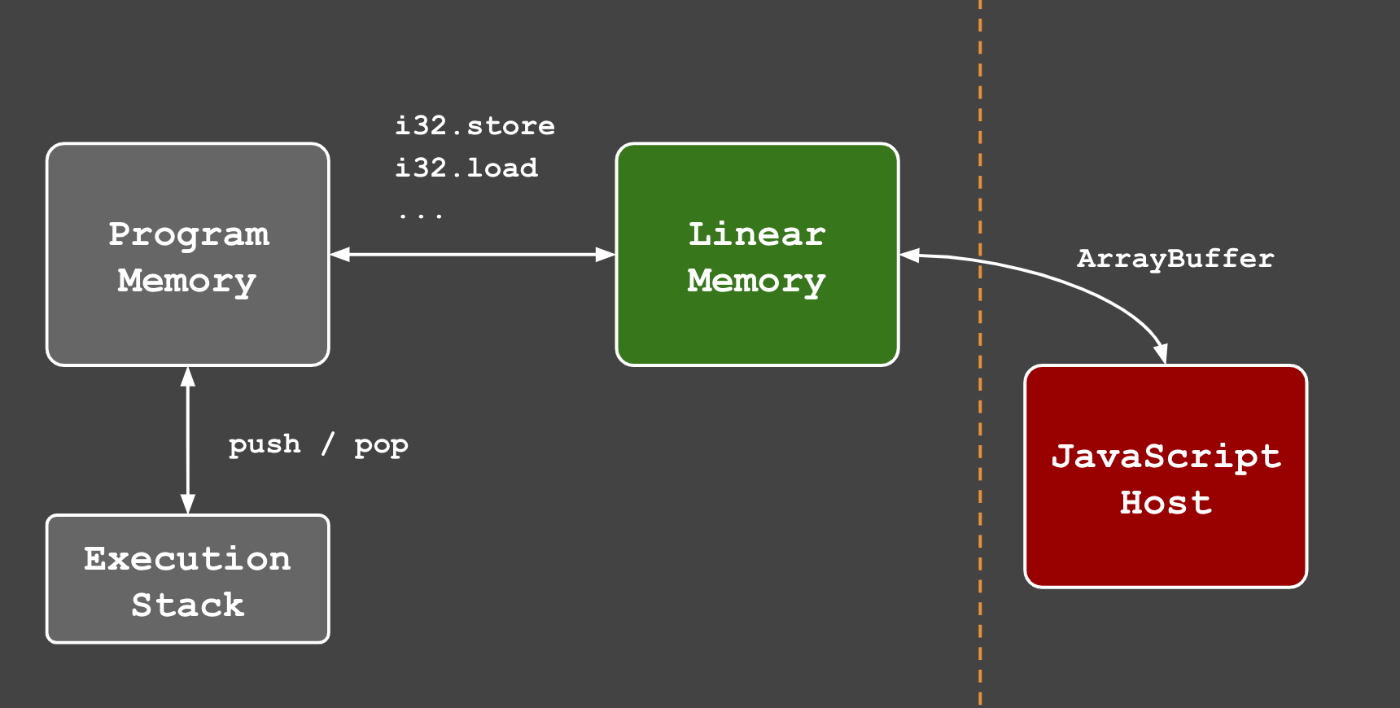
先に述べたように、WebAssemblyには4つの数値データ型しかありません。
豊富な型システム(文字列、構造体、配列など)を持つ言語がどのようにしてWebAssemblyにコンパイルできるのか不思議に思われるかもしれません。
WebAssemblyモジュールは任意で線形メモリのブロックを定義(またはインポート)することができます。
これはwasmモジュールとそのホストのJavaScriptで共有される連続したメモリのブロックです。したがって、WebAssemblyモジュールに文字列を渡したい場合は、線形メモリに文字列を書き込むことで行います。
chasmでは、ある種の表示をしたいだけなので、Video RAMの一形態として線形メモリを使用します。
chasm言語は、x位置、y位置、色の3つの式を取る単純なset-pixelコマンドをサポートしています。例えば、次のプログラムでは、画面を水平方向のグラデーションで埋めます。
var y = 0
while (y < 100)
var x = 0
while (x < 100)
setpixel x y (x * 2)
x = (x + 1)
endwhile
y = (y + 1)
endwhile
setpixelコマンドは、線形メモリに書き込むwasmのstore命令を使って実装されています。JavaScript のホスティング側では、この同じ線形メモリが読み取られ、HTMLのcanvasにコピーされます。コードの変更点はここでは説明しませんが、いつものようにGitHubで見ることができます。
以上で、chasm言語が完成し、マンデルブロ集合をレンダリングできるようになりました!

まとめ
このチュートリアルを楽しんでいただき、WebAssemblyやコンパイラの仕組みについて少しでも理解していただけたなら幸いです。
私にとって、このプロジェクトはとても楽しいものでした。これまでコンパイラを書いたことはありませんでしたが、ずっと書きたいと思っていました。
今後はメモリ管理のようなもっと複雑なトピックについても検討したいと思っています。例えば、文字列や配列、線形メモリ内に保存するためのメモリアロケータなどを導入したいと考えています。
これらの話題はすべて、将来の記事にしたいと思います。
Discussion
(原文からこうなってますが)wat表現は
get_localではなくlocal.getだと思います。