チュートリアルを通してDataflow試してみた
今回は、Dataflowをチュートリアルを通して実際に使ってみました。
そもそもDataflowとは?
Dataflowとは、公式の説明を引用させてもらうと、
Dataflow は、統合されたストリーム データ処理とバッチデータ処理を大規模に提供するサービスです。 Google Cloud Dataflow を使用して、1 つ以上のソースからデータを読み取り、変換し、宛先に書き込むデータ パイプラインを作成します。
Dataflow の一般的なユースケースは次のとおりです。
データの移動: データの取り込みやサブシステム間でのデータの複製
BigQuery などのデータ ウェアハウスにデータを取り込む ETL(抽出、変換、読み込み)ワークフロー。
BI ダッシュボードの強化。
ストリーミング データへの ML のリアルタイム適用。
センサーデータまたはログデータの大規模な処理。
ということです。非常に低レイテンシーでバッチ処理とストリーミング処理をできるという点で、MLとの相性も抜群でしょうし、リアルタイムに処理したいタスクやまとめてデータを処理したい場合に使えるサービスだと想定されます。また、Apache Beamを利用して構築されており、Pythonをはじめとするいくつもの言語をサポートしている点も特徴ではないでしょうか。
なぜDataflowを使ってみたのか
理由は大きく以下の二つになります。
- 実務でデータに関連する業務を担当する可能性が高く、事前に使い方を習得したかった
- Google Cloudの認定資格であるProfessional Data Engineer(以下、PDE)の範囲であり頻繁に質問に出てくるがどんなものかピンと来なかったため
1つ目の理由が一番大事ですが、MLエンジニアポジションとして普段活動していますが、Google Cloudのデータ周りのサービスについての実践経験がほぼなかったという状態です。そのため、まずはDataflowを触ってみようと思いました(Dataflowから選んだ理由は特にありません)。
二つ目の理由としては、5月中旬にPDEを受験予定であり、知識だけで回答するより実践経験がある方がいいと考えたためです。
チュートリアルやってみる
まずGoogle CloudのDataflowのページに行くと以下のような画面となり、画面右側にチュートリアルの提示がされました。そこで、今回は一番上のテンプレートで試すを利用してみようと思います。
なお、チュートリアルの内容は以下のようです
- Google Cloud プロジェクトで Dataflow を有効にします
- 出力データ用の Cloud Storage バケットを設定します。
- Google 提供の WordCount テンプレートを使用します。
- ジョブをモニタリングします。
- ジョブの出力を表示します。
- 課金が発生しないようにするため、クリーンアップします。
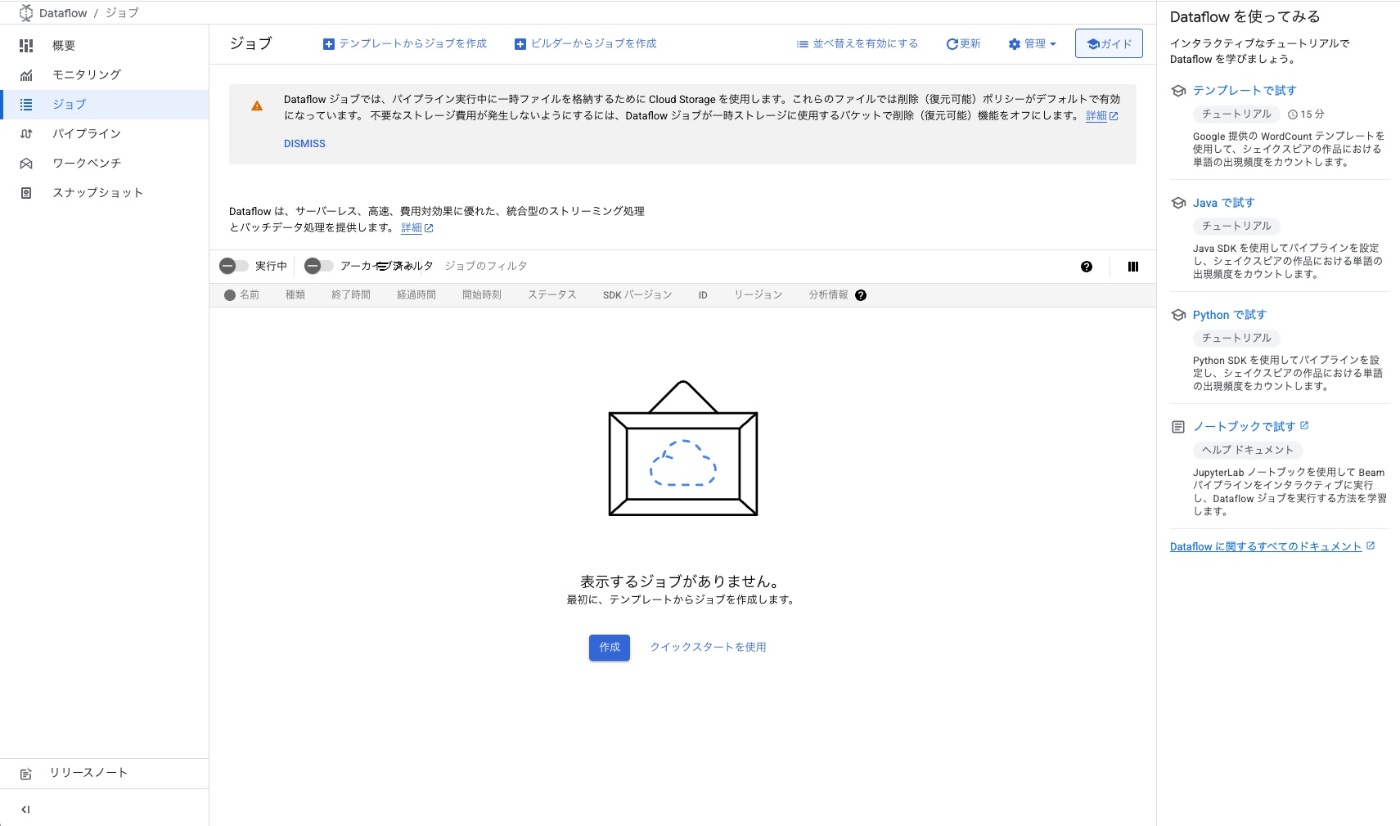
※ プロジェクトを作成するといったDataflowとは切り離せる部分については解説は省略させてもらいます。
チュートリアルの準備
基本的な準備は以下になります。
- プロジェクトの作成
- Dataflowに関わるAPIの有効化
- Compute Engine用のサービスアカウントに対して、Dataflowに対応するためのIAMロールを付与する
それでは順番に対応しましょう。プロジェクトについては作成済みの前提で進めます。
まずはDataflowに関わるAPIの有効化を実施します。利用されるAPIは以下のように提示してくれておりますので、何が使われているのか確認しましょう。私の環境はすでに他の作業に使っていたこともあり一部有効済のものがありまして、今回はDataflow API、Compute Engine APIそしてCloud Resource Manager APIを有効化しました。

それでは次にCompute Engineのサービスアカウントを作成し、利用するロールを割り当てます。なぜCompute Engineが利用されるかというと、Dataflowでパイプラインを作成してプロビジョニングする際に、Compute Engine VMインスタンスが起動され、その上で実行されるからのようです。チュートリアルにて利用されるロールは
- Dataflow ワーカー
- Dataflow 管理者
- ストレージのオブジェクト管理者
ということですので、サービスアカウントにこれらのロールを割り当てます。追加すると以下のようにCompute Engineのデフォルトサービスアカウントにロールが付与されます(プリンシパルは隠しております)。

ここまででプロジェクトとIAMの設定は完了ですので次のステップに進みます。
出力データ用の Cloud Storage バケットの設定
次のステップでは出力データ用のCloud Storageバケットを設定します。今回は以下の設定でバケットを作成しました。
- 名前:dataflow-tutorial-buc
- データの保存場所:asia-northeast2のシングルリージョン構成
- ストレージクラス:Standardクラス
- アクセス制御の方法:きめ細かい管理
パイプラインの実行
それではいよいよパイプラインを作成していきます。
まずはDataflowのジョブを作成しますが、今回はテンプレートからジョブを作成します。ジョブ画面からテンプレートからジョブを作成を選択します。

するとジョブの情報の入力が求められるので、以下のように入力します。
- ジョブ名:
word-count - リージョンエンドポイント:私は
asia-northeast2を選択しました - Dataflowテンプレート:
Word Countを選択
テンプレートを選択すると以下のように新たに入力を求められます。主にCloud Storageの情報の入力なので、今回は以下のように設定しました。
- Input file(s) in Cloud Storage: gs://dataflow-samples/shakespeare/kinglear.txt
- Output file(s) in Cloud Storage: gs://dataflow-tutorial-buc/counts/output
- 一時的な場所: gs://dataflow-tutorial-buc/temp/
今回はデータリネージなどは使わないので、ここまで設定したらジョブを実行します。ちなみに、実行時点でゾーンに利用可能なインスタンスがないとエラーになってしまいました。そのため、基本設定は同じで、リージョンだけasia-northeast1に、ゾーンをオプションでasia-northeast1-aに指定して実行しました。

実行すると以下のような画面が表示され、このDataflowパイプラインで設定されているグラフが表示されます。
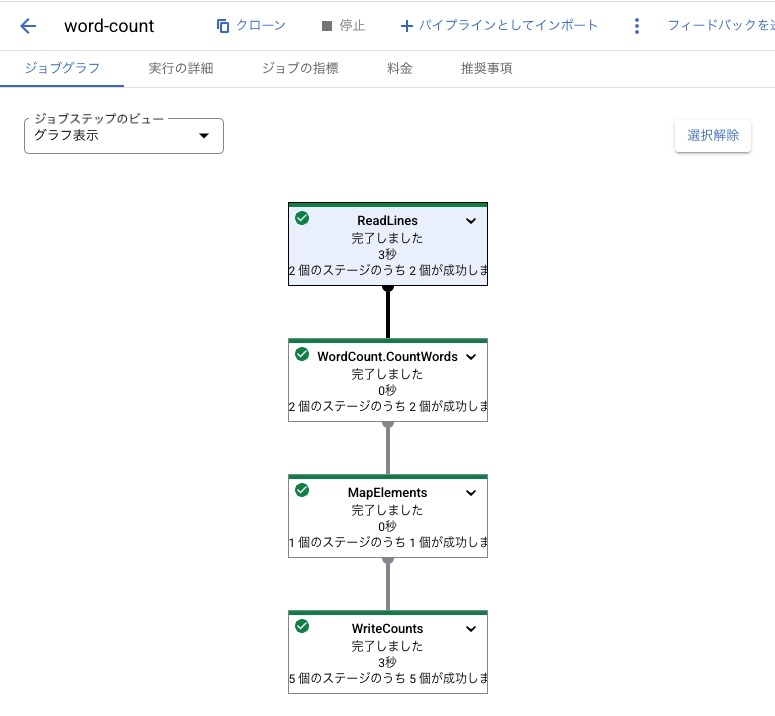
こちらの表示形式だと各コンポーネントで何が実行されているかわかりにくいですが、ジョブステップのビューを表形式に変更すると以下のような表示に切り替わります。
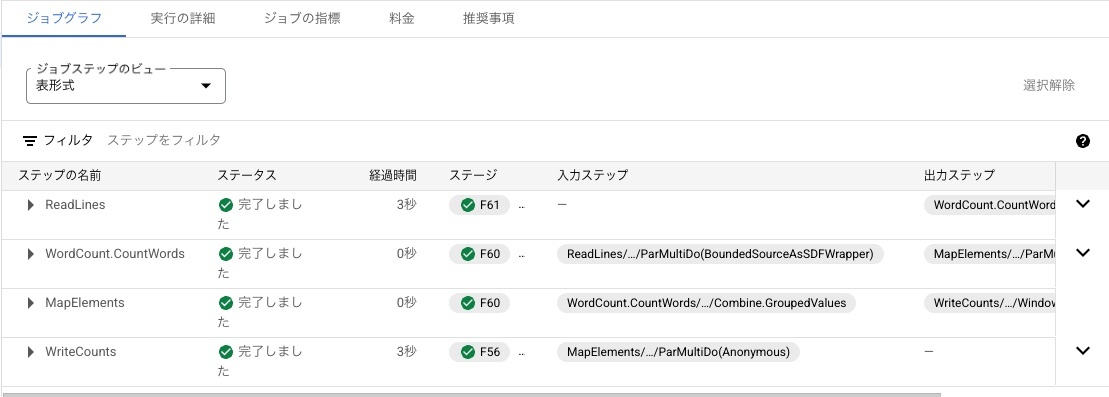
こちらのビューでは各コンポーネントの中身を掘り下げて表示することができ、例えば今回のチュートリアルのファイルの内容を読み込むコンポーネントは以下の構成のようです。

結果ファイルについては作成したCloud Storageに保存されています。
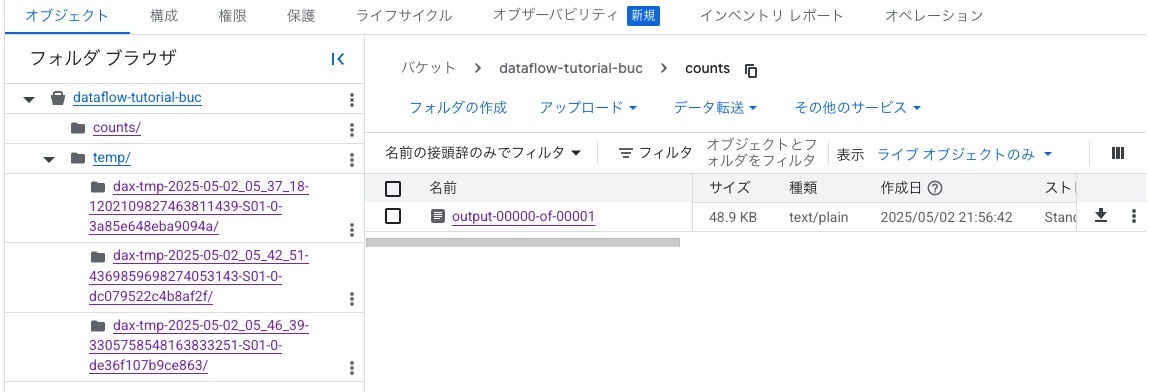
アウトプットファイルdataflow-tutorial-buc/counts/output-00000-of-00001を開いてみると以下のようにワードをカウントした結果が保存されていました。結果をみるとカウント順でソートされているなどがなさそうなので、パイププラインにソートして保存するように保存してみたいところです(今回の記事のスコープからは外しますが、将来的にやってみたいです)。
feature: 1
block: 1
Cried: 1
scatter'd: 1
she: 44
sudden: 1
silly: 1
More: 6
'twill: 2
out: 68
believe: 3
extreme: 1
Blanket: 1
ones: 3
duteous: 1
sword: 17
pity: 10
law: 5
o'erpaid: 1
clay: 1
unfortunate: 1
Alack: 12
horrible: 2
All: 16
oldest: 1
nonny: 1
any: 18
Camelot: 1
blot: 1
trunk: 2
naked: 4
Do: 23
safer: 1
pluck'd: 1
remediate: 1
ought: 1
banners: 1
diffidences: 1
Are: 11
claim: 1
world's: 1
cap: 3
provoke: 1
pen: 1
meanest: 1
Tremble: 1
* 以下省略 *
実行ログについては画面下部にあるログの表示を選択することで、以下のように表示できます。

まとめ
今回はテンプレートを用いたDataflowのチュートリアルをしてみました。次回はPythonを利用してパイプラインを構築するチュートリアルを試してみようと思います。
Discussion