BigQueryMLを用いてtitanic生存者予測タスクをやってみた
今回はタイトルにあるように、BigQueryMLを用いてtitanicの生存者予測タスクに取り組めるモデルを開発してみました。なお、今回BigQueryMLを利用するにあたり、クエリの生成にはGPT-5を存分に利用しました。
実際にやってみる!
BigQueryにデータセットをアップロードする
まずはtitanicのデータセットをBigQueryにアップロードします。以下の手順でデータを準備します。
- titanicデータセットをダウンロードする
- BigQueryにて
titanicデータセットを作成する -
titanicデータセットに対してtrainとtestというテーブルを登録する。なお、データは1でダウンロードしたCSVファイルを読み込んで自動登録させる
なお、1についてはこちらから取得できます。
学習の実行
まずはtitanic.trainを読み込んでモデルを学習させます。モデルはブーストツリーモデルを採用します。
-- 学習: 勾配ブースティング木(XGBoost)
CREATE OR REPLACE MODEL `PROJECT_ID.titanic.titanic_bst`
OPTIONS(
model_type = 'BOOSTED_TREE_CLASSIFIER',
input_label_cols = ['Survived'],
auto_class_weights = TRUE, -- クラス不均衡の自動重み付け
data_split_method = 'AUTO_SPLIT', -- 自動で学習/評価を分割
max_iterations = 50 -- 木の本数の上限(過学習抑制の簡単パラメータ)
) AS
WITH base AS (
SELECT
Survived,
Pclass,
-- 性別を数値化
CASE WHEN Sex = 'male' THEN 1 ELSE 0 END AS is_male,
-- 年齢欠損を (Pclass × Sex) グループ平均で補完
COALESCE(Age, AVG(Age) OVER (PARTITION BY Pclass, Sex)) AS Age,
SibSp,
Parch,
-- 家族サイズ
(SibSp + Parch + 1) AS FamilySize,
-- 運賃の欠損をPclass平均で補完
COALESCE(Fare, AVG(Fare) OVER (PARTITION BY Pclass)) AS Fare,
-- 乗船港の欠損は 'S' で補完(最頻)
COALESCE(Embarked, 'S') AS Embarked
FROM `PROJECT_ID.titanic.train`
),
feats AS (
SELECT
Survived,
Pclass,
is_male,
Age,
SibSp,
Parch,
FamilySize,
Fare,
-- Embarkedはワンホット(数値化)
CAST(Embarked = 'S' AS INT64) AS Embarked_S,
CAST(Embarked = 'C' AS INT64) AS Embarked_C,
CAST(Embarked = 'Q' AS INT64) AS Embarked_Q
FROM base
)
SELECT * FROM feats;
最初にモデルを作成するための情報を設定します。モデル名は以下の部分で設定しています。
CREATE OR REPLACE MODEL `PROJECT_ID.titanic.titanic_bst`
次にモデルの設定を以下のようにOPTIONSで設定しています。ここではモデルの種類(model_type)やラベルデータとするカラム(input_label_cols)などを指定しています。
OPTIONS(
model_type = 'BOOSTED_TREE_CLASSIFIER',
input_label_cols = ['Survived'],
auto_class_weights = TRUE, -- クラス不均衡の自動重み付け
data_split_method = 'AUTO_SPLIT', -- 自動で学習/評価を分割
max_iterations = 50 -- 木の本数の上限(過学習抑制の簡単パラメータ)
) AS
次にデータの前処理を実施します。欠損地の保管や家族サイズの計算などをするために以下のbaseを取得します。
WITH base AS (
SELECT
Survived,
Pclass,
-- 性別を数値化
CASE WHEN Sex = 'male' THEN 1 ELSE 0 END AS is_male,
-- 年齢欠損を (Pclass × Sex) グループ平均で補完
COALESCE(Age, AVG(Age) OVER (PARTITION BY Pclass, Sex)) AS Age,
SibSp,
Parch,
-- 家族サイズ
(SibSp + Parch + 1) AS FamilySize,
-- 運賃の欠損をPclass平均で補完
COALESCE(Fare, AVG(Fare) OVER (PARTITION BY Pclass)) AS Fare,
-- 乗船港の欠損は 'S' で補完(最頻)
COALESCE(Embarked, 'S') AS Embarked
FROM `PROJECT_ID.titanic.train`
),
そしてfeatsとしてbaseから実際に学習に利用するカラムを取り出しています。
feats AS (
SELECT
Survived,
Pclass,
is_male,
Age,
SibSp,
Parch,
FamilySize,
Fare,
-- Embarkedはワンホット(数値化)
CAST(Embarked = 'S' AS INT64) AS Embarked_S,
CAST(Embarked = 'C' AS INT64) AS Embarked_C,
CAST(Embarked = 'Q' AS INT64) AS Embarked_Q
FROM base
)
こちらのクエリを実行するとモデルの学習が実行されます。学習が完了するとtitanic.モデルの部分に登録されます。それを選択すると以下のようなトップ画面が表示されます。

学習結果トップ画面
またスクロールすると以下のように利用されたカラム情報や正則化含めたトレーニングパラメータが表示されます。

学習パラメータや特徴量カラムなど
また、トレーニングタブや評価タブで学習結果の詳細も表示されます。
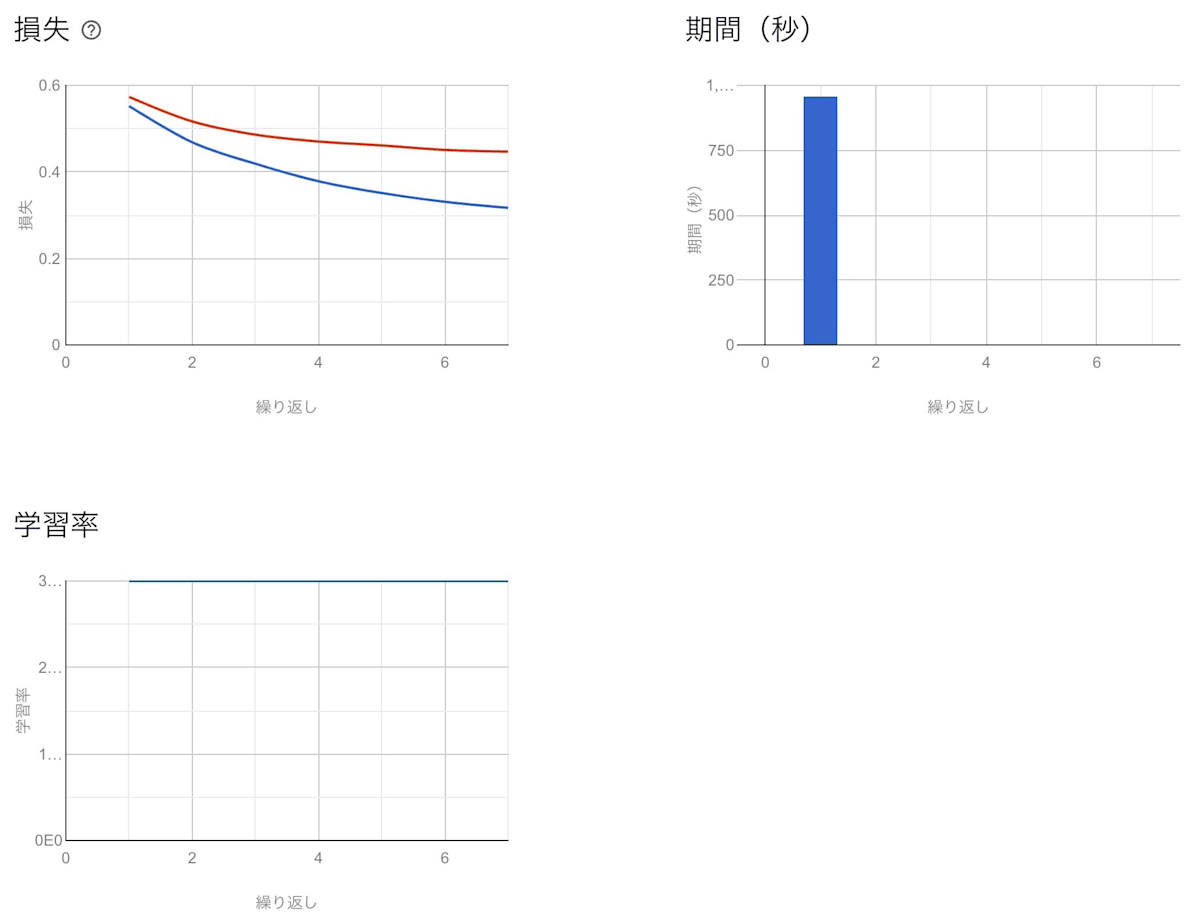
トレーニングタブ
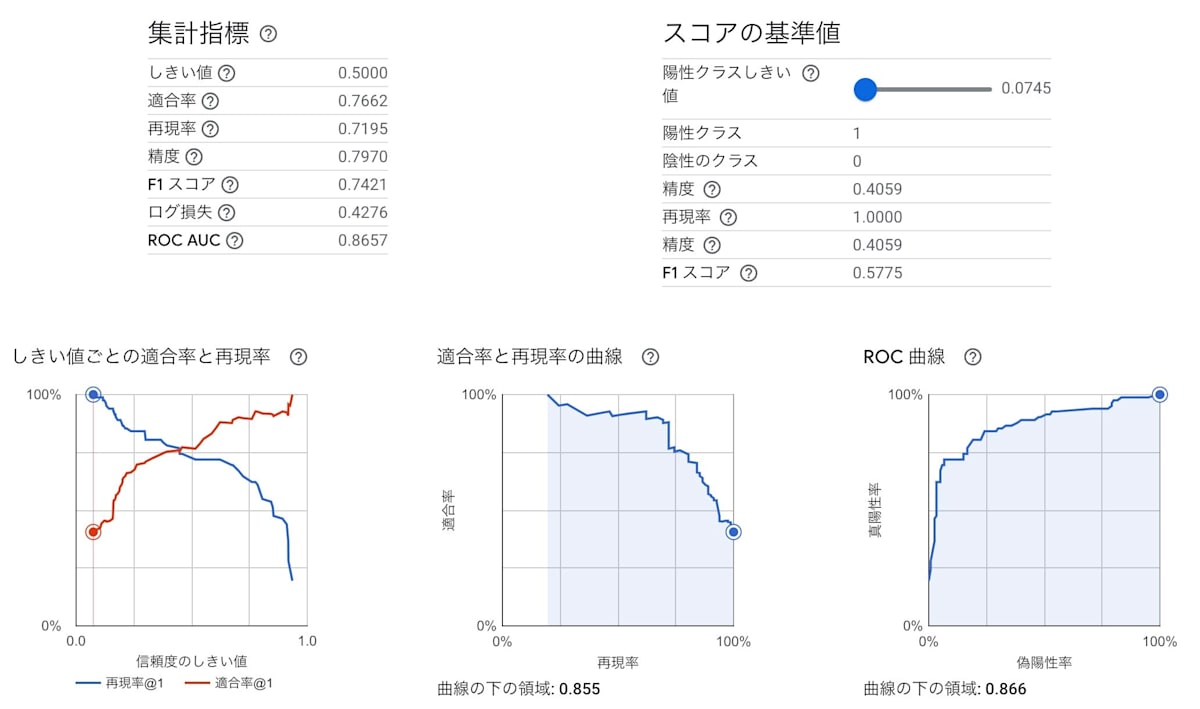
評価タブ
結果をみると、イテレーションが進むごとに損失は下がって胃入るものの下がりはばが比較的穏やかであることや、AUCが0.866で極端に悪いモデルではないことが考えられます。
検証の実行
学習に利用したデータを利用して検証を実行するには、以下のようにクエリを実行します。
SELECT * FROM ML.EVALUATE(MODEL `PROJECT_ID.titanic.titanic_bst`);
ML.EVALUATEで先ほど作成したモデル名を指定することでそのモデルを対象とすることができ、この呼び出しでは学習データに対して検証結果を取得することができます。
こちらを実行すると以下のような結果が取得できます。

検証結果
結果を見ると、学習の評価タブと同じAUCが得られていること、precisionやrecallなど一般的な指標が計算されていることが確認できます。
テストデータを使った評価
それではtitanic.testを利用してテストデータを使って性能を評価します。
CREATE OR REPLACE TABLE `PROJECT_ID.titanic.titanic_predictions` AS
SELECT
PassengerId,
-- Kaggle提出用に 0/1 で出力
CAST(predicted_Survived AS INT64) AS Survived,
predicted_Survived_probs
FROM ML.PREDICT(
MODEL `PROJECT_ID.titanic.titanic_bst`,
(
WITH base AS (
SELECT
PassengerId,
Pclass,
CASE WHEN Sex = 'male' THEN 1 ELSE 0 END AS is_male,
COALESCE(Age, AVG(Age) OVER (PARTITION BY Pclass, Sex)) AS Age,
SibSp,
Parch,
(SibSp + Parch + 1) AS FamilySize,
COALESCE(Fare, AVG(Fare) OVER (PARTITION BY Pclass)) AS Fare,
COALESCE(Embarked, 'S') AS Embarked
FROM `PROJECT_ID.titanic.test`
),
feats AS (
SELECT
PassengerId,
Pclass,
is_male,
Age,
SibSp,
Parch,
FamilySize,
Fare,
CAST(Embarked = 'S' AS INT64) AS Embarked_S,
CAST(Embarked = 'C' AS INT64) AS Embarked_C,
CAST(Embarked = 'Q' AS INT64) AS Embarked_Q
FROM base
)
SELECT * FROM feats
)
);
BigQueryMLでは、推論された結果はpredicded_<目的変数名>とpredicted_<目的変数名>_probsに設定されるので、その値をPassengerIdとともにテーブルとして保存しています。前処理やカラムの整理は学習時と同じロジックを利用します。
推論結果はテーブルに保存されますが、今回はKaggleにSubmissionするためのフォーマットにするために、以下のようにしてテスト結果テーブルをCSVにエクスポートしました。
EXPORT DATA OPTIONS(
uri = 'gs://<bucket name>/submission_*.csv',
format = 'CSV',
header = TRUE
) AS
SELECT PassengerId, Survived
FROM `PROJECT_ID.titanic.titanic_predictions`
ORDER BY PassengerId;
先ほどのテスト結果はtitanic_predictionsに保存されているので、そのデータを整形してCloud Storageに格納します。通し番号が自動で設定sら得るため、uriには*を入れる必要があります。
クエリを実行するとCloud Storageにファイルが保存されるので、それをダウンロードしてKaggleにアップロードしました。その結果正答率は以下のように0.7488となりました。

Kaggleへのサブミッション結果
まとめ
今回はtitanicの生存者予測モデルをBigQueryMLを利用して学習し、その結果をKaggleにサブミッションしてみました。BigQueryMLではクエリは書く必要がありますがモデルのコードなどを書く必要なくモデルを開発することができます。BigQueryでデータを蓄積していて機械学習モデルを分析してみたいと思っていた方はぜひ使ってみてください。
Discussion