なぜ君はBenchmarkDotNetを使うべきか あるいはStopwatchで"ちゃんと"ベンチマークを取るために必要な諸々
はじめに
みなさん、ベンチマーク計っていますか?
.NetにおいてはBenchmarkDotNetというデファクトスタンダートなライブラリが存在しているので気軽に測定している方は多いかと思います。
一方、より古典的な処理速度評価の手法として標準ライブラリのタイマー機能(.NetではSystem.Diagnostics.Stopwatchクラス)を使い実行時間を計るものがあります。
少し詳しい人であればこの測定手法は不正確で信頼できないものであると知っていますが、この方法で計測した時間を掲示してしまっている記事も多く見かけます。
あるいは普段からBenchmarkDotNetを利用していても具体的にStopwatch測定の何がダメなのか把握していないかもしれません。
そこでここではあえてStopwatchでちゃんとマイクロベンチマークを計ることをやってみて、なぜBenchmarkDotNetを使うべきなのかを再考してみます。
実験コード
ここでは例として列挙型の文字列化メソッドを測定してみることにします。
測定対象
public enum SampleEnum { Foo, Bar, Baz, Qux, }
public static class BenchmarkTarget
{
// ToStringは直接コールする
public static string GetStringFromDictionary(this SampleEnum value)
=> _dict[value];
private static readonly Dictionary<SampleEnum, string> _dict = new()
{
{ SampleEnum.Foo, "Foo" },
{ SampleEnum.Bar, "Bar" },
{ SampleEnum.Baz, "Baz" },
{ SampleEnum.Qux, "Qux" },
};
public static string GetStringFromSwitch(this SampleEnum value)
=> value switch
{
SampleEnum.Foo => "Foo",
SampleEnum.Bar => "Bar",
SampleEnum.Baz => "Baz",
SampleEnum.Qux => "Qux",
_ => default!,
};
}
あらかじめBenchmarkDotNetで測定してStopwatchでの測定結果と比較していくことにします。
ベンチマーク
using BenchmarkDotNet.Attributes;
public class BenchmarkContext
{
public SampleEnum SampleEnum { get; init; } = SampleEnum.Foo;
[Benchmark]
public string ByToString()
=> SampleEnum.ToString();
[Benchmark]
public string ByDictionary()
=> SampleEnum.GetStringFromDictionary();
[Benchmark]
public string BySwitch()
=> SampleEnum.GetStringFromSwitch();
}
BenchmarkDotNet v0.14.0, Windows 11 (10.0.26100.3775)
Intel Core i7-14700KF, 1 CPU, 28 logical and 20 physical cores
.NET SDK 9.0.203
[Host] : .NET 8.0.15 (8.0.1525.16413), X64 RyuJIT AVX2
DefaultJob : .NET 8.0.15 (8.0.1525.16413), X64 RyuJIT AVX2
| Method | Mean | Error | StdDev |
|---|---|---|---|
| ByToString | 5.6837 ns | 0.1075 ns | 0.1005 ns |
| ByDictionary | 1.1955 ns | 0.0087 ns | 0.0072 ns |
| BySwitch | 0.3516 ns | 0.0084 ns | 0.0079 ns |
その1:まずはシンプルに
まずはシンプルにStopwatch.Restart()とStopwatch.Stop()で測定対象のメソッドを挟み時間を計ってみます。
1回の実行にかかる時間、という意図からはこれが一番想像しやすそうですね。
MyBenchmark1
using System.Diagnostics;
public class MyBenchmark1
{
public BenchmarkResult Measure()
{
var stopwatch = new Stopwatch();
stopwatch.Restart();
SampleEnum.Foo.ToString();
stopwatch.Stop();
var byToStringResult = stopwatch.Elapsed.TotalNanoseconds;
stopwatch.Restart();
SampleEnum.Foo.GetStringFromDictionary();
stopwatch.Stop();
var byDictionaryResult = stopwatch.Elapsed.TotalNanoseconds;
stopwatch.Restart();
SampleEnum.Foo.GetStringFromSwitch();
stopwatch.Stop();
var bySwitchResult = stopwatch.Elapsed.TotalNanoseconds;
return new BenchmarkResult(
byToStringResult,
byDictionaryResult,
bySwitchResult);
}
}
ByToString : 1192600.0000 ns/op
ByDictionary: 1227500.0000 ns/op
BySwitch : 19300.0000 ns/op
BenchmarkDotNetの結果と比較して異常に遅いですね。
予想通りではありますがろくな結果ではありません。
その2:反復による平均化
最初のコードでは、テスト対象の処理にかかる時間があまりにも短すぎてRestartやStop自身のオーバーヘッドが無視できていないようですね。
ループにより複数回実行して平均値をとるようにしてみましょう。
MyBenchmark2
using System.Diagnostics;
public class MyBenchmark2
{
public BenchmarkResult Measure()
{
const int iteration = 1 << 24;
var stopwatch = new Stopwatch();
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
SampleEnum.Foo.ToString();
}
stopwatch.Stop();
var byToStringResult = stopwatch.Elapsed.TotalNanoseconds / iteration;
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
SampleEnum.Foo.GetStringFromDictionary();
}
stopwatch.Stop();
var byDictionaryResult = stopwatch.Elapsed.TotalNanoseconds / iteration;
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
SampleEnum.Foo.GetStringFromSwitch();
}
stopwatch.Stop();
var bySwitchResult = stopwatch.Elapsed.TotalNanoseconds / iteration;
return new BenchmarkResult(
byToStringResult,
byDictionaryResult,
bySwitchResult);
}
}
ByToString : 5.9518 ns/op
ByDictionary: 13.8555 ns/op
BySwitch : 1.6717 ns/op
最初のよりは幾分かマシになりました。
それでもBenchmarkDotNetと比較するとまだ結構な違いがありますね。
相対順位が入れ替わってしまっているのもマイナス点です。
その3:余計な最適化の抑制
その2の結果からより信頼性の高いものにするために考慮すべきものを潰していきましょう。
第一にはJIT最適化の影響が考えられます。
テスト対象のコードはコードサイズが非常に小さいため、JIT後には処理全体がfor文の中にインライン展開されてしまうのです。
本番環境では非常にありがたいのですが、パフォーマンスの測定においては最適化があったりなかったりするというのは結果が不公平になりやすくよろしくありません。
MethodImplOptions.NoInliningをベンチマークメソッドに指定したり、戻り値をvolatileに参照してあげて確実に意図した回数のメソッド呼び出しを経るようにしてみます。
こうすることでメソッド呼び出しのジャンプ命令+評価対象のロジックが確実に測定されるようにします。
ジャンプ命令のオーバーヘッドも測定して差分を取ればより正確にできるでしょう。
また、現代のJITではTiered Compileが導入されており、実行頻度によって最適化レベルが変わります。
マイクロベンチマークを取るようなロジックは高頻度で実行されることを前提としているので最適化は最大に効かせるのが無難かと思います。
本計測の前にウォーミングアップ呼び出しをして最適化レベルを最大限引き上げましょう。
MyBenchmark3
using System.Diagnostics;
using System.Runtime.CompilerServices;
public class MyBenchmark3
{
public BenchmarkResult Measure()
{
const int iteration = 1 << 24;
var stopwatch = new Stopwatch();
var sink = string.Empty;
for (var i = 0; i < iteration; i++)
{
Volatile.Write(ref sink, Overlhead());
Volatile.Write(ref sink, ByToString());
Volatile.Write(ref sink, ByDictionary());
Volatile.Write(ref sink, BySwitch());
}
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
Volatile.Write(ref sink, Overlhead());
}
stopwatch.Stop();
var overhead = stopwatch.Elapsed.TotalNanoseconds / iteration;
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
Volatile.Write(ref sink, ByToString());
}
stopwatch.Stop();
var byToStringResult = stopwatch.Elapsed.TotalNanoseconds / iteration;
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
Volatile.Write(ref sink, ByDictionary());
}
stopwatch.Stop();
var byDictionaryResult = stopwatch.Elapsed.TotalNanoseconds / iteration;
stopwatch.Restart();
for (var i = 0; i < iteration; i++)
{
Volatile.Write(ref sink, BySwitch());
}
stopwatch.Stop();
var bySwitchResult = stopwatch.Elapsed.TotalNanoseconds / iteration;
return new BenchmarkResult(
byToStringResult - overhead,
byDictionaryResult - overhead,
bySwitchResult - overhead);
}
[MethodImpl(MethodImplOptions.NoInlining)]
public string Overlhead()
=> "";
[MethodImpl(MethodImplOptions.NoInlining)]
public string ByToString()
=> SampleEnum.Foo.ToString();
[MethodImpl(MethodImplOptions.NoInlining)]
public string ByDictionary()
=> SampleEnum.Foo.GetStringFromDictionary();
[MethodImpl(MethodImplOptions.NoInlining)]
public string BySwitch()
=> SampleEnum.Foo.GetStringFromSwitch();
}
ByToString : 4.7937 ns/op
ByDictionary: 1.5384 ns/op
BySwitch : 0.0044 ns/op
だいぶ見れる数字になりました。
BySwitchが異常に速いことがやや気になりますが、一応は『ベンチマークを測った』とのたまっても許されるような気がします。
その4:グローバルな状態に対する配慮
さて、他に測定に悪影響を及ぼす要素は残っているでしょうか。
ここで一つ思い出していただきたいのですが、.Netの実行環境は基本的にはグローバルにステートフルです。
それもそのはず、背後ではマークアンドスイープ方式のリッチなガベージコレクタが控えており、逐次変化するオブジェクトの寿命をすべて管理しているのです。[1]
GCが背後にいるということはベンチマークの測定結果は実行順序に大きく依存するというわけです。
一方でGCを完全に止めてしまうとGC負荷の高いロジックが不当に有利となってしまうためこれもよくありません。
ここではいっそのことプロセスごと分けてしまうようにします。
自身のバイナリを再起的に立ち上げて起動オプションで切り分けるようにします。
雑な実装ではありますが
MyBenchmark4
using System.Diagnostics;
using System.Runtime.CompilerServices;
public class MyBenchmark4
{
private const int measurement = 16;
private const int workload = 1 << 24;
private static Semaphore _semaphore = new(1, 1, "BenchmarkTrial");
public async Task<object> MeasureAsync(string[] args)
{
switch (args.FirstOrDefault())
{
default:
_semaphore.WaitOne();
try
{
var overhead = await MeasureCoreAsync("overhead");
var byToStringResult = await MeasureCoreAsync("byToString");
var byDictionaryResult = await MeasureCoreAsync("byDictionary");
var bySwitchResult = await MeasureCoreAsync("bySwitch");
return new BenchmarkResult(
byToStringResult - overhead,
byDictionaryResult - overhead,
bySwitchResult - overhead);
}
finally
{
_semaphore.Release();
}
case "overhead":
return new OverheadCase().Measure();
case "byToString":
return new ByToStringCase().Measure();
case "byDictionary":
return new ByDictionaryCase().Measure();
case "bySwitch":
return new BySwitchCase().Measure();
}
}
private static async Task<double> MeasureCoreAsync(string option)
{
var elapseds = new double[measurement];
for (var i = 0; i < measurement; ++i)
{
elapseds[i] = await MeasureOnceOnSubprocessAsync(option, measurement);
Console.WriteLine($"{option} {i + 1}: {elapseds[i]:0.000} ns");
}
return elapseds.Average();
}
private static Task<double> MeasureOnceOnSubprocessAsync(string option, int measurement)
{
var proc = new Process() {
StartInfo = {
WorkingDirectory = AppContext.BaseDirectory,
FileName = "dotnet",
Arguments = $"BenchmarkTrial.dll {option} {measurement}",
RedirectStandardOutput = true,
},
EnableRaisingEvents = true,
};
var tcs = new TaskCompletionSource<double>();
proc.Exited += (sender, e) => {
var stdout = proc.StandardOutput.ReadToEnd().TrimEnd();
tcs.SetResult(double.Parse(stdout));
};
proc.Start();
return tcs.Task;
}
private abstract class BenchmarkCase()
{
public double Measure()
{
var sink = string.Empty;
var stopwatch = new Stopwatch();
var ticks = new List<double>();
for (var j = 0; j < measurement; ++j)
{
GC.Collect(2);
GC.WaitForPendingFinalizers();
GC.WaitForFullGCComplete();
stopwatch.Restart();
for (var i = 0; i < workload; i++)
{
Volatile.Write(ref sink, GetString());
}
stopwatch.Stop();
ticks.Add(stopwatch.Elapsed.TotalNanoseconds / workload);
}
return ticks.Average();
}
public abstract string GetString();
}
private sealed class OverheadCase()
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> string.Empty;
}
private sealed class ByToStringCase
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> SampleEnum.Foo.ToString();
}
private sealed class ByDictionaryCase
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> SampleEnum.Foo.GetStringFromDictionary();
}
private sealed class BySwitchCase
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> SampleEnum.Foo.GetStringFromSwitch();
}
}
ByToString : 4.8721 ns/op
ByDictionary: 2.2558 ns/op
BySwitch : 0.8532 ns/op
これもだいぶまともな数字に見えます。
取り込んだ配慮の分量的にはその3よりも正確な予感もしますが、現実問題として厳にどちらが正確なのかは判断しがたいところがあります。
その5:イテレーション回数依存性
さて、その2以降、イテレーション回数については特になんの説明もなく2^24という値を設定していました。
しかしよくよく考えてみるとこの値が適切であるという証拠はどこにもありません。
という訳なので、その4で書いたコードでイテレーション回数を振ってみて測定してみました。
その結果が以下のグラフのようになります。
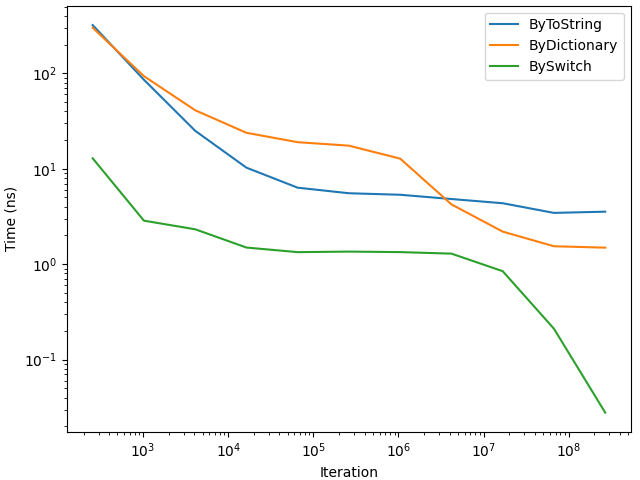
イテレーション回数が増えるごとに1実行あたりの時間が短くなっていく傾向があります。
しかも方式ごとに減少の仕方が異なり、単純な線形減少でもありません。
そこで、イテレーション回数を振って予備測定をして十分に飽和するパラメータを探索するようにしてみます。
MyBenchmark5
using System.Diagnostics;
using System.Runtime.CompilerServices;
public class MyBenchmark5
{
private const int measurement = 16;
private static Semaphore _semaphore = new(1, 1, "BenchmarkTrial");
public async Task<object> MeasureAsync(string[] args)
{
switch (args.FirstOrDefault())
{
default:
_semaphore.WaitOne();
try
{
var byToStringResult = await MeasureCoreAsync("byToString");
var byDictionaryResult = await MeasureCoreAsync("byDictionary");
var bySwitchResult = await MeasureCoreAsync("bySwitch");
return new BenchmarkResult(
byToStringResult,
byDictionaryResult,
bySwitchResult);
}
finally
{
_semaphore.Release();
}
case "overhead":
return new OverheadCase().Measure(int.Parse(args[1]));
case "byToString":
return new ByToStringCase().Measure(int.Parse(args[1]));
case "byDictionary":
return new ByDictionaryCase().Measure(int.Parse(args[1]));
case "bySwitch":
return new BySwitchCase().Measure(int.Parse(args[1]));
}
}
private static async Task<double> MeasureCoreAsync(string option)
{
var workload = 65536;
var prevWorkloadElapsed = double.MaxValue;
var clearTime = 0;
while(true)
{
var workloadElapsed = await MeasureOnceOnSubprocessAsync(option, workload);
Console.WriteLine($"{option} workload {workload}: {workloadElapsed:0.000} ns ({workloadElapsed / prevWorkloadElapsed})");
if (workloadElapsed / prevWorkloadElapsed > 0.9)
{
if (++clearTime >= 4) { break; }
}
else
{
clearTime = 0;
}
prevWorkloadElapsed = Math.Min(workloadElapsed, prevWorkloadElapsed);
workload *= 2;
}
var operationElapseds = new double[measurement];
for (var i = 0; i < measurement; ++i)
{
operationElapseds[i] = await MeasureOnceOnSubprocessAsync(option, workload);
Console.WriteLine($"{option} {i + 1}: {operationElapseds[i]:0.000} ns");
}
var overloadElapseds = new double[measurement];
for (var i = 0; i < measurement; ++i)
{
overloadElapseds[i] = await MeasureOnceOnSubprocessAsync("overhead", workload);
Console.WriteLine($"overhead {i + 1}: {overloadElapseds[i]:0.000} ns");
}
return operationElapseds.Average() - overloadElapseds.Average();
}
private static Task<double> MeasureOnceOnSubprocessAsync(string option, int workload)
{
var proc = new Process()
{
StartInfo = {
WorkingDirectory = AppContext.BaseDirectory,
FileName = "dotnet",
Arguments = $"BenchmarkTrial.dll {option} {workload}",
RedirectStandardOutput = true,
},
EnableRaisingEvents = true,
};
var tcs = new TaskCompletionSource<double>();
proc.Exited += (sender, e) => {
var stdout = proc.StandardOutput.ReadToEnd().TrimEnd();
tcs.SetResult(double.Parse(stdout));
};
proc.Start();
return tcs.Task;
}
private abstract class BenchmarkCase()
{
public double Measure(int workload)
{
var sink = string.Empty;
var stopwatch = new Stopwatch();
var ticks = new List<double>();
for (var j = 0; j < measurement; ++j)
{
GC.Collect(2);
GC.WaitForPendingFinalizers();
GC.WaitForFullGCComplete();
stopwatch.Restart();
for (var i = 0; i < workload; i++)
{
Volatile.Write(ref sink, GetString());
}
stopwatch.Stop();
ticks.Add(stopwatch.Elapsed.TotalNanoseconds / workload);
}
return ticks.Average();
}
public abstract string GetString();
}
private sealed class OverheadCase()
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> string.Empty;
}
private sealed class ByToStringCase
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> SampleEnum.Foo.ToString();
}
private sealed class ByDictionaryCase
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> SampleEnum.Foo.GetStringFromDictionary();
}
private sealed class BySwitchCase
: BenchmarkCase
{
[MethodImpl(MethodImplOptions.NoInlining)]
public override string GetString()
=> SampleEnum.Foo.GetStringFromSwitch();
}
}
多モード性の動作を誤検知してしまわないよう予想以上に複雑になってしまいました。
ByToString : 5.5225 ns/op
ByDictionary: 1.3381 ns/op
BySwitch : 1.1803 ns/op
やはりというか、これでもBenchmarkDotNetと一致する結果にまでは追い込めていません。
そのほか、考えなければならないこと
ビルドコンフィギュレーション
意外とよく見かける測定ミスとして、Debugビルドのまま測定を進めてしまっているケースがあります。[2]
DebugビルドではILもJITも最適化はゆるゆるで到底実情に即した値は得られません。
BenchmarkDotNetではDebugビルドで実行しようとするとエラーが出て測定できないのでこのミスに気づくことができます。
自分で書くコードに配慮を入れるなら#if DEBUG/#endifディレクティブでデバッグモードでの実行をできなくするようにしましょう。
バックグラウンド環境の統一
冷静に考えると当然のことなのですが、実際にコードを走らせて測定するベンチマークはバックグラウンドプロセスの影響を強く受けます。
余計なものを立ち上げっぱなしだと当然測定の精度も損なわれる訳なので、常駐アプリなども含め落とせるものは落とすほうが理想的です。
とはいえ手間の多さは膨れ上がるし、この点についてはBenchmarkDotNetも特に配慮してくれはしません。
どこまで厳密に測定環境を整えるかは人によりけりという部分にもなってくるかもしれません。
プロセッサ自身の最適化
コンピュータの最適化はアセンブリレベルのみならずCPUにも仕込まれています。
L1/L2/L3の階層化キャッシュであったり、分岐予測であったり、その技術は多岐にわたります。
今回のベンチマークコードでもジャンプ先のアドレスがキャッシュに残ることで呼び出しが高速化する場合があるので、実行順序を入れ替えるだけで結果が変動したりします。
これも嫌うのでもあればやはりその4のようにプロセスそのものを独立すべきかもしれません。
流石に全体像の予測が難しい上に環境依存性も強いため、今回のコードではプロセッサ最適化を厳密に配慮した処理は入れられませんでした。
ベンチマークツールとしてもサポートの難しい領域になるため、現実的にはプロセス独立と測定環境の明記によって妥協する場合も多いようです。
最後に
ベンチマークに悪影響を及ぼす要素をいろいろ想定し可能な限り排除できるよう努めて見ましたが、やはりBenchmarkDotNetの作りに及ぶ物を書くことは難しそうです。
ノイズ要因を潰していこうと書き進めるごとに継ぎ足し継ぎ足しで処理を足していったため極めて見通しの悪いコードになってしまいました。
筋よく設計すればその5相当のコードももっときれいに書けるとは思いますが、Stopwatchで手軽にベンチマークというモチベーションにはもはやそぐわない物になっています。
BenchmarkDotNetでは精度と再現性のためにベンチマーク対象のメソッドをIL解析して測定用のコードに書き換えるところまでやっており、一朝一夕でこれに匹敵するものを書くことは不可能と言っていいと思います。
精度以外にも、
- 実行環境の情報収集(ハードウェア、OS、ランタイムなど)
- ランタイム間の比較
- メモリ使用量の測定
- 統計値の算出
- 結果のフォーマット
など幅広い機能をカバーしてくれており、測定作業全体を通して効率化が見込めます。
そのデファクトスタンダード性により、BenchmarkDotNetを使ったということ自体が他者からの評価を決定づける一因ともなっています。
マイクロベンチマークを取るときは必ずBenchmarkDotNetを使いましょう。
Discussion