私たちはCloudアプリケーションによって、リアルタイムでのCollaboration(共同作業)や複数デバイスからのデータアクセスを可能にしてきました。それはあらゆるデータをサーバに集中させることによって実現していますが、同時にデータのOwnership(所有権)を失っていることを意味します。
もし使用しているサービスが停止してしまったら、そのソフトウェアは機能しなくなり、それまでに作成していたデータは失われてしまいます。
またCloudアプリケーションによって私たちはどこからでもデータにアクセスできるようになりましたが、それは全てサーバを経由する必要があり、データを取得するにはサーバの許可が必要になります。

私たちがデータを他人のコンピュータに保存している以上は、そのデータに対するOwnershipをある程度奪われてしまっていると考えることができます。
Cloudアプリケーションはデータをサーバに集中させ、どこからでもアクセス可能にすることでCollaborationを実現しました。しかしその結果ユーザからデータのOwnershipを奪ってしまったのです。
このような背景から"Local-First"という考えが生まれました。
はじめに
本記事はLocal-Firstの概念を理解することを目的とするため、具体的な実装や特定のライブラリを紹介することはしません。
ここでは「Local-first software You own your data, in spite of the cloud」(April 2019)の論文を参考にして説明をします。この論文はまさにLocal-Firstの概念における基礎と言えるものです。
さらに詳細な実装やLocal-Firstを実現するためのツールを知りたい方は下のサイトが参考になります。
実際にLocal-Firstを採用していることで有名なアプリケーションとしてLinearが挙げられます。ユーザ体験がどれくらい向上するのか体感したい方はぜひ一度試してみてください。
*また今後はCloudアプリケーションをLocal-Firstと対比してCloud-Firstと呼びます。
基本概念と7つの目指す理想
Cloud-Firstによって私たちはデータのOwnershipを失いました。しかし、Collaborationを実現することと、データのOwnershipを保持することは決して相反するものではありません。
Local-FirstはCloudによって得られた利点を残しつつ、データのOwnershipをユーザが完全に保持することを目的とします。
Cloud-Firstではサーバのデータを最も尊重し(Primary Copy)、クライアントのデータはサーバデータのキャッシュとして扱われてきました(Secondary Copy)。そのため、私たちがデータを更新する際にはサーバへのリクエストが必要になっていました。
しかし、Local-Firstではこの立場を逆転させます。
ローカルに存在するデータを最優先に扱い(Primary Copy)、サーバは複数ユーザからのアクセスを補助するためのデータ管理を役割とします(Secondary Copy)。
この視点の変化は非常に重要であり、その上で7つの理想を実現します。
1. No spinners: your work at your fingertips
今日のソフトウェアの多くはCPUが高速化しているにも関わらず、旧世代のものに比べて遅いと感じることがあります。それはCloud-Firstにおいてデータがサーバに集中していることが影響しており、データの取得や更新のためにサーバとの通信を往復する必要がありました。
対してLocal-FirstはデータのPrimary Copyをローカル上に保存するため、ユーザはサーバへのリクエストが完了するまで待つ必要がなくなります。
全ての操作がローカル上で完結し、他デバイスとのデータの同期はバックグラウンドで行われます。これ自体がソフトウェアの速度を保証するものではありませんが、ローカル上で操作が完結するため待ち時間に表示するSpinnerを削除することができます。
2. Your work is not trapped on one device
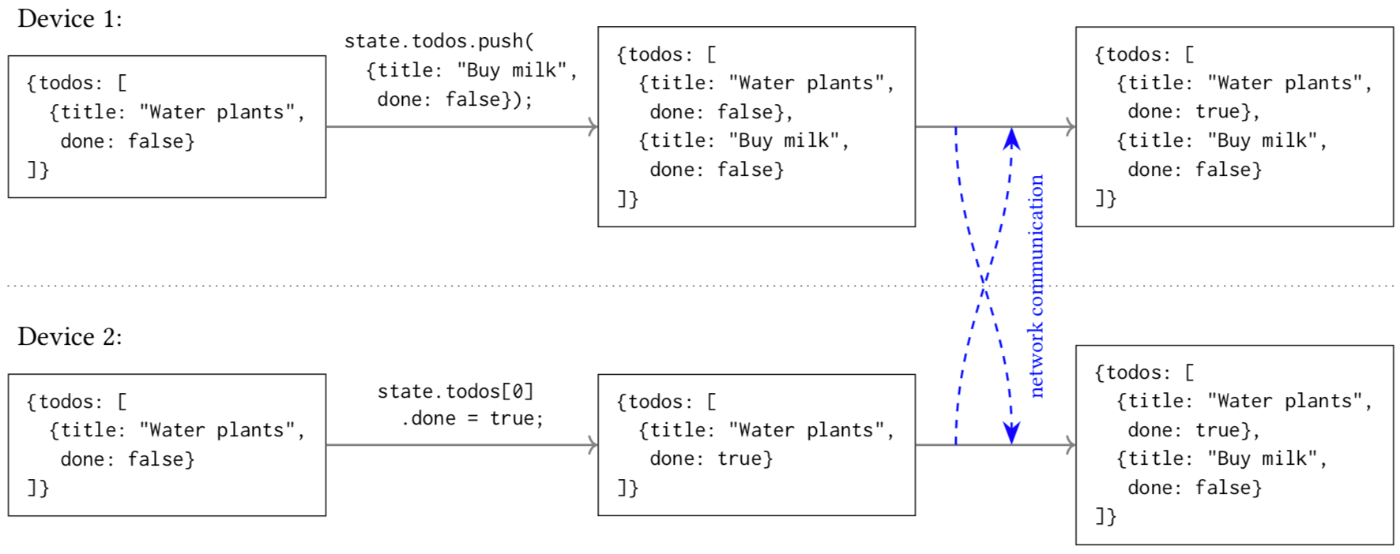
私たちは何かの作業をする際に複数デバイスに跨って行うことがあります。Local-Firstにおいてもこの機能はサポートするべきであり、そのためには複数デバイス間でのデータの同期が必要になります。
複数デバイス間でのデータ同期の仕組みは、各ファイルを一度に一人が編集する限りうまく機能します。しかし、複数人が同じファイルを同時に編集するとコンフリクトが起きる可能性があり、この課題は解決する必要があります。
この解決策としてCRDTが挙げられますが、その紹介は後の章にて行います。
3. The network is optional
Cloud以前ではインターネットの通信を必要とせずともアプリケーションを使用することができました。しかしCloud-Firstでは基本的にネットワークの通信が前提になります。
最近ではオフラインをサポートする流れがあり、Progressive Web Appsなどのアプローチが改善策として挙げられていますが、Cloud-Firstにオフラインのサポートを組み込むことは大変です。
その一方で、Local-FirstはデータのPrimary Copyを各デバイスに保存するため、ユーザはオフラインの状態でもデータにアクセスできます。そしてネットワーク接続が可能になった時点で他デバイスとの同期が行われます。
4. Seamless collaboration with your colleagues
Cloud以前のアプリケーションでは複数のユーザが同時に同じファイルを編集することは難しく、共同作業時にはあらかじめ誰がどのファイルで作業するかを認識しておく必要がありました。
その一方で、Google DocsのようなCloud-Firstでは複数のユーザが同時にドキュメントを編集可能で、かつコンフリクトを心配する必要がないため有効なCollaboration機能を提供することが可能になりました。
Local-FirstにおいてもCloud-Firstと同等かそれ以上のリアルタイムCollaborationを実現することが理想的です。しかし、このCollaborationを実現することはLocal-Firstの最大の課題の一つです。
5. The Long Now
データのOwnershipを持つことの重要な側面は、将来にわたってそのデータにアクセスし続けられることです。Local-Firstではそのソフトウェアを作った会社が無くなった後でもデータにアクセスし続けることができます。
Cloud以前のアプリケーションでは、データとソフトウェアを実行する方法がある限りは永遠に動き続けました。しかし、Cloud-Firstではサービスの利用可否に依存しており、サービス終了とともにそのソフトウェアで作成したデータにもアクセスできなくなります。
つまり、あなたは使用しているソフトウェアが長期的に続くことに賭けてデータを保存しているということになります。
その一方でLocal-Firstでは各自のデータはローカルに保存されるため、より長く使用することが保証されます。これはユーザ自身のためでもありますが、同時に未来にそのデータを読みたいと思う人にとっても重要です。
将来の歴史家や研究者が現代のデジタルデータへのアクセスや解読ができなくなる可能性をVint Cerf氏は"digital Dark Age"と危惧しています。
6. Security and privacy by default
Cloud-Firstの問題点の一つに、全ユーザのデータを一元化してDBに保存していることが挙げられます。もしもハッカーが会社のサーバにアクセスできた場合、全てのデータを閲覧して改ざんすることができてしまいます。
当然Googleのような世界トップレベルのセキュリティチームを持つ会社であれば安心ですが、ほとんどの会社がそうではありません。
それに対してLocal-Firstでは、より優れたセキュリティとプライバシーを保護する仕組みが組み込まれています。
ローカルに自分自身のデータが保存され、サーバが全てのデータを保持するデータの一元化を避けることができます。そして、End-to-Endで暗号化することによってユーザのデータは暗号化された状態でサーバに保存され、サーバ上での読み取りを防ぐことができます。

7. You retain ultimate ownership and control
Cloud-Firstでは自らのデータにアクセスするためにもサービス・プロバイダーのAPIや利用規約によって制限されていました。しかし、Local-Firstではデータは全てローカルのデバイスに保存され自由にアクセスすることができます。
その一方でデータのOwnershipを得ることはその責任を負うことを意味します。データのバックアップやランサムウェアからの保護などは各ユーザが意識する必要が生まれるということです。
既存サービスの分析
Local-FirstはシームレスなCollaborationとデータへのOwnershipを双方実現することを目標にしていました。次に、この目標と紹介した7つの理想がどの程度実現可能なのかを考えていきます。
Git・GitHub
Git・GitHubは現状最もLocal-Firstに近いアプリケーションであると紹介されています。
Gitは完全にオフラインで高速に動作し、データのOwnershipはユーザにあります。そのため、データの寿命は長期的です。これはローカル上のGitリポジトリがデータのPrimary Copyであり、サーバに依存していないことが要因です。
また、GitHubでは複数デバイスからのアクセスとCollaborationを可能にしています。
しかし、Gitのモデルには2つの弱点があります。
-
リアルタイムのCollaborationができない
- GitにはPull Requestを用いた非同期のCollaboration機能があります。これによってコンフリクトを解消しながら共同作業をすることができます。しかし、Google DocsやFigmaなどのようなリアルタイムのCollaborationを行う機能はありません。
-
テキストファイル以外のデータが扱いづらい
- コードやそれに似た行ベースのテキストファイルは最適化されている一方で、その他のファイル形式は適していません。
クラウドベースのエディタは受け入れられなかった
ではGitの弱点であるリアルタイムのCollaborationを実現するという意味では、Cloud9のようなクラウドベースのエディタが存在します。
しかし、大半のエンジニアはクラウドベースの開発ソフトウェアに対して消極的で、理由を尋ねると「遅いから」「信用できないから」といった言葉が挙げられました。
つまり、先ほど紹介したLocal-Firstの7つの理想というのはユーザが求める需要とある程度一致していると考えることができます。
Local-Firstの実現可能性
Local-FirstはシームレスなCollaborationとデータへのOwnershipを実現するために、優秀なローカルのDBとデバイス間でリアルタイムにデータを同期する仕組みが必要になります。
そして論文の中ではCRDT(Conflict-free Replicated Data Types)がLocal-Firstを実現するための基盤技術になり得ると紹介しています。
CRDTは複数ユーザを想定した汎用的なデータ構造として2011年に初めて論文で書かれました。私自身完璧に理解できているとは言えないためCRDTの深い解説は省きますが、それはGitのようなバージョン管理システムに似ておりテキストファイルだけでなく豊富なデータ型を扱うことができます。
以下の資料を参考にして簡単にCRDTの概要を押さえます。
CRDTとは
CRDTとはコンフリクトしない複製可能なデータ型です。当初はデータサイズなどの懸念点がありましたが、コンピューティング技術の進歩に伴って実用可能になりました。
CRDTと対比されるアルゴリズムにOT(Operational Transform)が挙げられます。OTは複数の処理の結果生まれる矛盾を吸収し解決する機能を持っています。
OTは30年ほどの歴史のある技術で直感的な実装な一方、複雑なデータを扱う場合には実装がハードになってしまう弱点があります。また、中央にサーバーがあることを前提としていることもデメリットとして挙げられます。
それに対してCRDTは複雑なデータに対応可能なだけでなく、サーバによる中央集権化されたデータ管理を行いません。
また、OTとは違い入力結果ではなく操作履歴を保存します。そのためオフラインでもデータの操作が可能になり、オンラインに復帰した際にデータの整合性が保証されます。
動画を通じてCRDTの概要を把握したい方は以下のYouTubeがおすすめです。
Local-Firstを用いた実験結果
論文の中ではLocal-Firstがどの程度実現可能であるかを調査するために、実際のプロトタイプ開発を通じて実験が行われました。実験の目的は以下3つの観点でそれぞれの疑問を明らかにすることです。
- Technology viability (技術的実現可能性)
- User experience (ユーザ体験)
- Developer experience (開発者体験)
具体的な実験内容については以下のリンクからご覧ください。
調査結果
CRDTがうまく機能した
CRDTの導入は比較的簡単に行うことができ、その自動Mergeもほとんどのケースにおいてシンプルにかつシームレスに実行することができました。
オフライン時のユーザ体験が素晴らしかった
オフライン時に作業を続け、ネットワークが復活した際にデータを同期するというプロセスが機能しました。また、Cloud-Firstのようにネットワーク接続が切れたことを示す「offline! warning!」といったような警告を出す必要もなくなりました。
Functional Reactive Programming(FRP)と好相性で開発者体験が良かった
実験結果からReactのようなFRPモデル(関数型リアクティブプログラミング)との相性の良さがわかりました。
CRDTに基づくデータ層では、データの更新はローカルによる変更だけでなく、ネットワークを通じて他ユーザの更新を受け取ることがあります。
FRPモデルはアプリケーションのUIと共有データの状態を確実に同期させるため、開発者は他のユーザーからの変更を追跡して、現在のUIと調整する作業をする必要がなくなります。
コンフリクトは思ったより脅威ではなかった
自動Mergeの仕組みを導入する際にコンフリクトが発生する可能性をほとんどの人が懸念していました。そのため、アプリケーションに合ったコンフリクト解決方法を考える必要があると考えていました。
しかし、検証してみると滅多にコンフリクトは発生せず、基本的なコンフリクト解決方法で十分機能することがわかりました。
考えられる要因は二つあります。
- きめ細かいレベルで変更を追跡し自動Mergeします。そのため、たとえ2人のユーザが同時に操作したとしても、正しい順序で配置することが可能でした。
- ユーザは共同作業における衝突を直感的に理解して避けることができました。
もちろん複数ユーザーが同じオブジェクトの同じプロパティを同時に変更した場合にはコンフリクトが発生する可能性があります。
その際にはアプリケーションの要件に合ったコンフリクト解決方法が必要になりますが、基本的にはデフォルトの方法で十分であり、カスタマイズされた方法を必要とするケースは今のところ確認されていません。
CRDTはパフォーマンス上の懸念がある
CRDTは文字単位のテキスト編集を含むすべての履歴を保存するため、パフォーマンスとメモリ/ディスクの使用量が問題になります。
また、これらデータを簡単に破棄することはできません。なぜなら、誰かが半年後に再接続し、その時点からの変更をマージする可能性がないとは限らないからです。
CRDTのパフォーマンス改善とその最適化に関しては現在進行形の課題と捉えられています。
Cloudサーバは依然として必要である
Local-Firstにおいてもサーバは役割を持ちます。それは、中央管理するというCloud-Firstの役割とは異なり、あくまでClientをサポートするための"Cloud Peer"としてのものです。
またLocal-Firstにおいてサーバは以下の役割を担います。
- アーカイブ・バックアップとしての場所
- 従来のサーバーAPIへの架け橋
- より大きいコンピューティングリソースの提供
つまり、Cloud-Firstとの大きな違いはサーバを必要としないことではなく、サーバの役割が変わったということです。
まとめ
本記事ではLocal-Firstの基本となる論文を元にその概念を説明してきました。内容は以前までのCloud-Firstと比べ全く新しいものであり、ユーザ体験を格段に向上させる可能性を秘めている一方、実用化するために解決すべき課題はまだ残っています。
とはいえ、論文中の実験によるとシームレスなCollaborationとデータへのOwnershipの双方を両立することは可能であるとわかりました。
論文が書かれた2019年時点ではまだLocal-Firstをサポートするためのツールが少なく、とてもプロダクトで置き換えを勧められるような状況ではありませんでしたが、2024年になりLocal-Firstを実現するためのライブラリや知見も増え現在改めて注目が集まっているように思います。
また、AI ShiftではLocal-Firstを実プロダクトへ導入するために積極的に検証を行っています!

Discussion