初めまして、AI Shiftのフロントエンドでインターンをしている井上ひかりと申します。
この記事はAI Shift Advent Calendar 2023の24日目の記事です。
AI Shiftでは、現在ChatbotやVoicebotを開発しています。
今回は、フロントエンドでFirestoreを効果的に利用するための設計について考察します。特に、オペレーターとのリアルタイム更新を実現するためにFirestoreを採用した点に着目し、Firestoreを直接クライアントが利用する場合の設計上の工夫について深掘りしたいと思います。
FirestoreのReadとWriteの責務の分離 ✍️
データの変更をリアルタイムにUIに反映したい場合、Firestoreをフロントから直接readすると便利です。具体的には、データベースの特定のcollectionに変更があった際に、Firestoreからイベントをプッシュし、クライアント側でこれをリッスンすることで、UIを動的に更新する場面です。
一方、データベースへの書き込み時にはREST API経由でバックエンドがFirestoreへの書き込みを行っています。
今回は、Firestoreをフロントから直接readする場合に注目したいと思います。下の図では、オレンジの枠線で囲まれている部分にあたります。
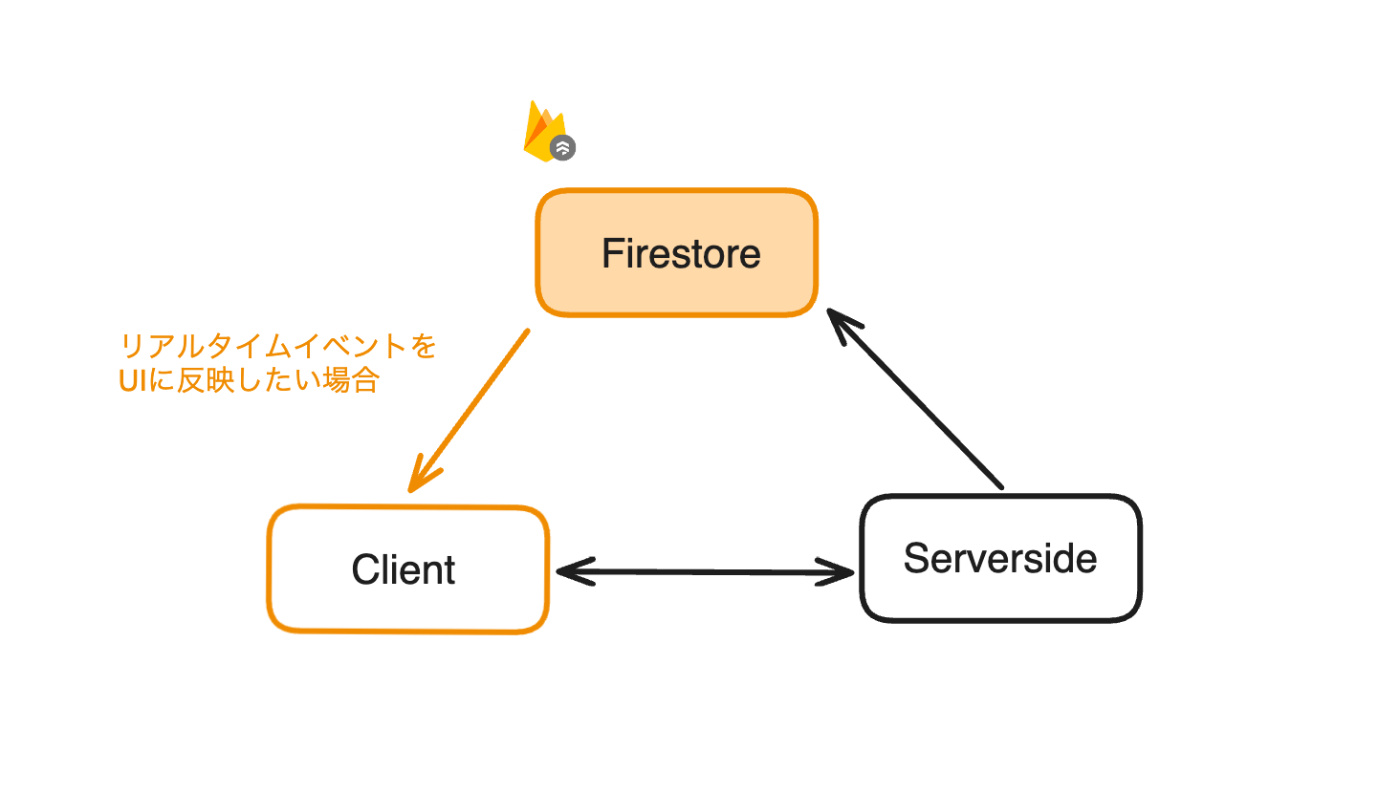
Firestoreをフロントから直接Readする際に注意すべきこと 🤔
1.データ整形の必要性
REST APIの利用と異なり、バックエンドを介さないFirestoreの直接通信では、フロントエンドでのデータ整形が必要になります。REST APIでは、バックエンドがデータベースから受け取ったデータをフロントエンドが扱いやすい形に加工することが多いと思います。しかし、今回のFirestoreとの直接的な通信ではそのプロセスを踏まないため、フロントエンド側でコンポーネントで直接表示するためのデータを選別し、適切な形に整える必要が生じます。
さらに、Firestoreがドキュメント指向データベースであるという特徴も大きく関与しています。RDBとの決定的な違いは指定したパス(テーブル)についてGETできるデータ構造の型が一意ではないという点です。Firestoreでは取得する対象のcollectionを選択しますが、このcollectionには様々な型のドキュメントを入れることができます。つまり、複数の型のドキュメントが同じcollectionに混在している場合、それらを仕分けるロジックをフロントで持つ必要があります。
2. リアルタイム更新を行う処理の複雑性の解消
例えば、リアルタイム更新を行うためには、以下の手順が必要です。
- 対象のcollectionをパスで指定
- collectionに対してクエリを指定
- サブスクリプション(listen)するか、一回限りののクエリとして発行するかを決定
- クエリの実行(イベントのlisten)
先ほども触れましたが、Firestoreはドキュメント指向データベースのため、操作対象をファイルパス形式で指定します。このため、汎用化したメソッドを作成する際には、親子関係のパス指定などが複雑になりがちです。さらに、複数のcollectionを操作したり、更新内容によって処理を分岐させたりカスタムなエラー処理を追記する際には、クエリ記述やデータを取得する前後のコードが複雑になる傾向があります。
なんだかDBを操作している感覚に近く、バックエンドを書いているような芳ばしい香りがしてきました...👀
3.UIコンポーンネント部分との責務の分離
AI Shiftのプロダクトや解決したいドメインによる部分が大きいですが、UIコンポーネントがかなり複雑であるという課題点がありました。より厳密にはプロダクト的背景として、AI ShiftはChatbotの設定を細部にわたって管理画面で提供しており、対象ドメインの複雑さによってUIコンポーネントだけでも多重構造になりやすいという点がありました。
例えば、Chatbotに設定可能なシナリオの分岐は多岐にわたり、画像のようにそれぞれの問いに対する何種類もの分岐を設定することが可能です。
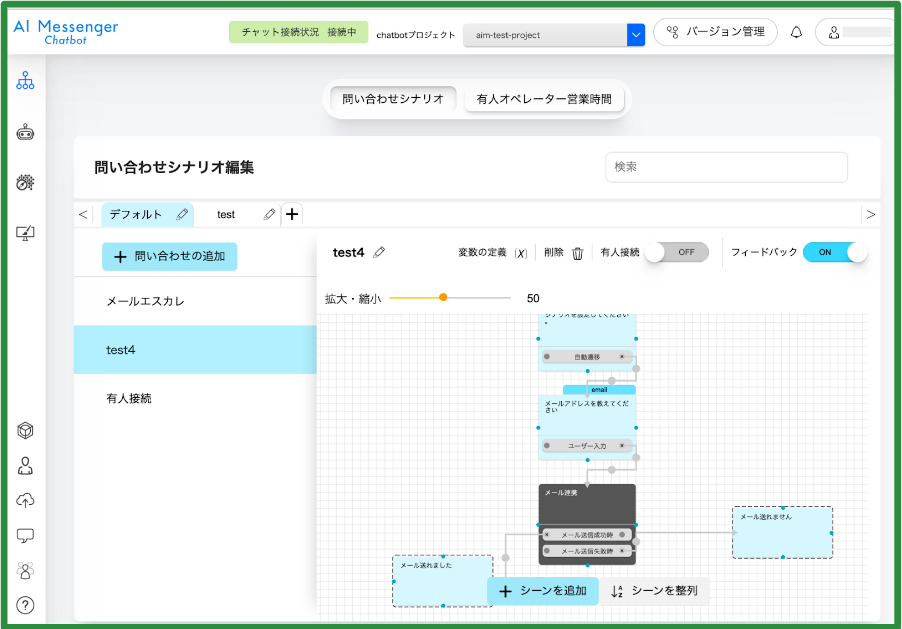
また、botそのもののデザインもクライアントの方々それぞれの意図した雰囲気に合うように柔軟にカスタマイズできるようになっています。
解決したい課題の要約
Firestoreとの直接通信では、フロントエンドでのデータ整形やリアルタイムイベントのハンドリングが複雑になることが予想されます。さらに、プロダクトの特性により、UIコンポーネントの複雑さも増加するため、データ処理とUI設計の間での責務の分離と疎結合を意識することが重要でした。
設計について 🛠️
上記に述べたような解決したい課題を踏まえた上で、使用している技術や工夫点について深ぼってみましょう。
使用技術
- 言語:Typescript
- UIフレームワーク:React
- 状態管理:Redux
- 認証:Firebase Auth
工夫点
1. 依存性の方向を統一する
Firestoreを直接readする処理を記述する上で重視しているのは、依存性の方向性を一貫させることです。下記の図では、設計における各レイヤー間の依存関係の向きを示しています。
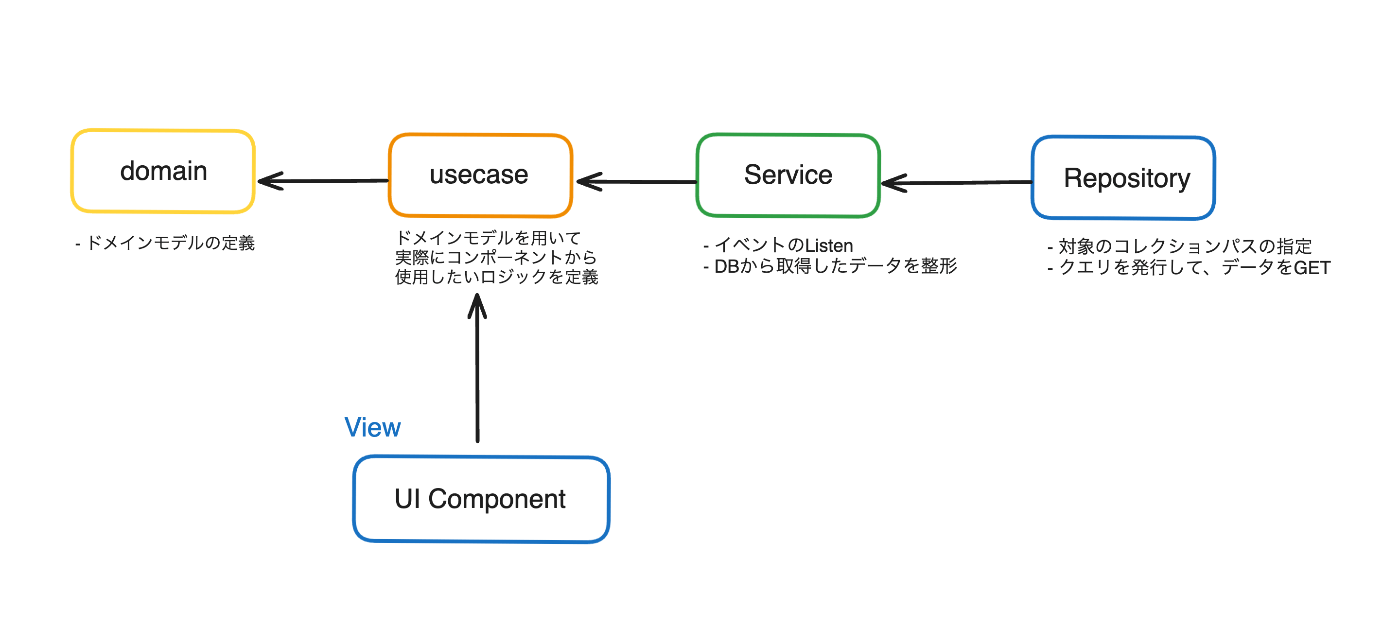
usecase, service, repositoryの各層でインターフェイスを定義し、クラスのコンストラクターを用いて依存性の注入を行い、依存関係の逆転を実現しています。
これにより、各層の責務が明確化され、ドメインロジックやFirestoreへのアクセス処理に集中することが可能になりました。また、このアプローチは関数のテスト容易性を高め、モックの作成が容易になるなど、テスタブルな関数の実現に貢献しています。
2. service層にリアルタイム処理についての責務を持たせる
AI ShiftがFirestoreを用いて複雑なリアルタイム処理を管理し、コードの可読性を保つための鍵は、service層にあります。この層では主に以下の処理を行っています。
-
onSnapshotメソッドを用いたリアルタイムイベントのリッスン - オペレーターやクライアントの状態に応じた処理の分岐
- changeイベントの
typeパラメーターに基づく処理の分岐
db.collection("cities").where("state", "==", "CA")
.onSnapshot((snapshot) => {
snapshot.docChanges().forEach((change) => {
if (change.type === "added") {
console.log("New city: ", change.doc.data());
}
if (change.type === "modified") {
console.log("Modified city: ", change.doc.data());
}
if (change.type === "removed") {
console.log("Removed city: ", change.doc.data());
}
});
});
Reference : https://firebase.google.com/docs/firestore/query-data/listen?hl=ja#view_changes_between_snapshots
usecase層でこれらの処理、特に前述したようなaddedなどのtypeによる分岐を記述すると、コードが肥大化しドメインロジックに集中できなくなる可能性があります。Service層はドキュメントの種類に応じた処理分岐を通じてドメインロジックに部分的に関わっており、これがrepository層との責務の違いです。
さらに、この層はドキュメントの種類に基づいて柔軟に型を変換できるアダプターのロジックも保持しています。これによって、service層はrepository層が取得したデータをusecase層が使いやすい形に変換する緩衝材としても機能しています。
service層があることによって、Firestoreの特徴的なリアルタイム更新の処理とUIコンポーネントとの密結合を防ぎそれぞれの層の責務の分離を行うことが可能となっているのです。
実際にコードを書いてみて感じたこと 🌱
恩恵を受けた点
- 目的としていたUI部分とFirestoreと通信するAPI部分との密結合を防ぐことができる
- Firestoreの実装はすでに汎用化されているのでFirestoreを意識することなくクエリやサブスクリプションの実装のみに注力することができる
- API部分を切り出せたことで、テストのモックが書きやすい
デメリット・改善が見込めそうな点
- 単純にファイルやディレクトリの数が増加する
- 上に付随して、1つのAPIを作成・編集するために複数のファイル(体感5ファイル以上)の変更が必要になり、レビューが大変
- アーキテクチャに慣れていないエンジニアにとっては学習コストがかかる可能性がある
まとめ
今回は、フロントエンドでFirestoreを効果的に利用するための設計について考察しました。クライアントサイドでのFirestoreとのリアルタイム更新では、クライアントサイドでのデータ整形とリアルタイムイベントの管理が複雑化するため、データ処理とUI設計の間それぞれでの明確な責務の分離と疎結合が重要でした。
AI Shiftではそれぞれの層が依存する方向を統一したり、依存性の逆転や層ごとの責務の分離によってこれらの複雑性を改善しています。
プロダクト毎にベターな設計は変わってくると思いますし、必ずしも正解があるわけでもありません。直近で新規機能の追加も始まり試行錯誤の日々ですが、少しでもこの記事が皆様のお役に立てれば幸いです。
最後に
AI Shiftではエンジニアの採用に力を入れています!
少しでも興味を持っていただけましたら、カジュアル面談でお話しませんか?
(オンライン・19時以降の面談も可能です!)
【面談フォームはこちら】

Discussion