こんにちは、AIQ株式会社のフロントエンドエンジニアのまさぴょんです!
今回は、Seleniumを使って、電話番号から会社名を特定する方法や、Google検索して情報を取得する方法について、解説します。
Seleniumとは?
Seleniumは、主にWebアプリケーションのブラウザ操作を自動化するためのフレームワークです。
ブラウザでの操作を自動化するスクリプトを作成することができるため、テスト自動化やWebスクレイピングに使用されます。
Seleniumの特徴をまとめると次のような内容になります。
- オープンソース: Selenium はオープンソースのテストフレームワークで、無償で利用することができます。
- ブラウザの操作自動化: Web ブラウザの操作を自動化し、ユーザーのアクションをシミュレートすることが可能です。
- 多言語対応: Python の他にも、Java、C#、Ruby など複数のプログラミング言語でスクリプトを記述できます。
- サポート環境の幅広さ: 多様なブラウザや OS で動作し、幅広いテストシナリオに対応しています。
Seleniumの環境構築
それでは、実際にSeleniumの環境構築をしていきます。
- Selenium を install する
pip install selenium
- ChromeDriver を install する
Seleniumでクローリングする際に、Google Chromeを使う場合Chromedriverが必要です。
Macの場合は、Homebrewでchromedriverをインストールできます。
brew install chromedriver
- ChromeDriver の install確認(バージョン情報)を確認する
ChromeDriver の install確認(バージョン情報)を確認するには、次のコマンドを実行します。
chromedriver --version
## [出力結果] ##
# ChromeDriver 120.0.6099.109 (3419140ab665596f21b385ce136419fde0924272-refs/branch-heads/6099@{#1483})
Docker ComposeでSeleniumの環境構築をする方法
Docker ComposeでSeleniumの環境構築をする方法は、こちらの記事で紹介しています。
電話番号から会社名を特定するWebスクレイピング
Seleniumで、電話番号から会社名を特定するWebスクレイピングを実施してみます。
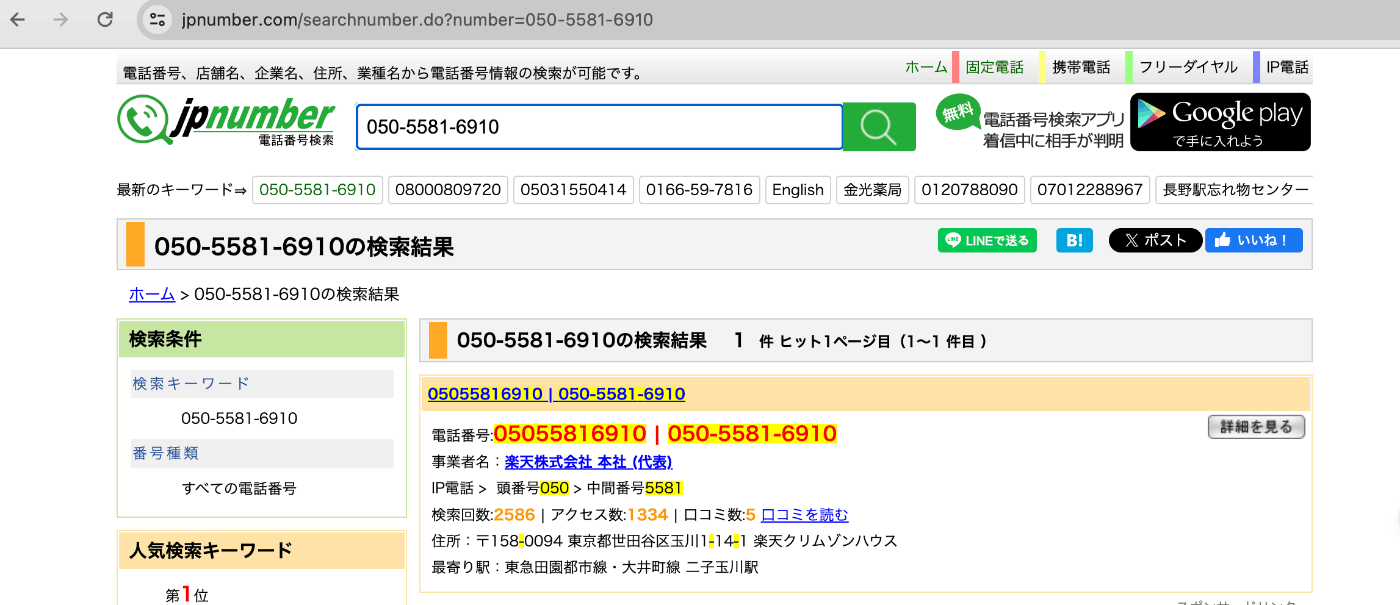
電話番号から会社名を特定するために、日本の電話番号検索Webサイトを使わせてもらいます。
例えば、このページで、050-5581-6910という電話番号で、検索をすると「楽天 株式会社」がヒットします。
今回取得する要素は、検索結果として、「事業者名」の欄に記載される会社名になります。
ちなみに、この時のURLは、https://www.jpnumber.com/searchnumber.do?number=050-5581-6910になります。
DevToolsを使って、該当箇所の要素のXPATHを取得します。
プログラムでは、これを活用します。

電話番号から会社名を特定するWebスクレイピング処理のSampleCodeは、次のとおりです。
from selenium import webdriver
from selenium.webdriver.common.by import By
import traceback
from selenium.webdriver.chrome.options import Options
### 作成・Module ########################################################
# 1. 電話番号(会社の代表番号: 固定電話)から、会社名を特定する
########################################################################
# 電話番号
tell = '050-5581-6910' # 楽天株式会社・Tell
# tell = '0277-46-1111' # 桐生市役所・Tell
# 電話番号検索の Web サイト URL に 検索パラメーター(電話番号)を付与する
phone_number_search_web_url = f'https://www.jpnumber.com/searchnumber.do?number={tell}'
print('検索パラメーター付きの URL')
print(phone_number_search_web_url)
try:
# Chrome Browser Instance
browser = webdriver.Chrome()
# ページに移動する
browser.get(phone_number_search_web_url)
# 会社名の要素を取得する
result_element = browser.find_element(By.XPATH, '//*[@id="result-main-right"]/div[2]/table/tbody/tr/td[1]/div/dt[2]/strong/a')
print(result_element.text)
# 会社名を取得する
result = result_element.text
except Exception as error:
# traceback.format_exc() で例外の詳細情報を取得する
error_msg: str = traceback.format_exc()
print(error_msg)
# 例外を無視したい場合は、pass を使用する
pass
finally:
# ブラウザを閉じる (エラーが発生しても必ず実行)
browser.quit()
print('処理完了')
上記ファイルを実行した結果は、次のとおりです。
電話番号から、会社名を特定することができました。
python company_judge.py
## [実行結果] ##
検索パラメーター付きの URL
https://www.jpnumber.com/searchnumber.do?number=050-5581-6910
楽天株式会社 本社 (代表)
処理完了
会社名と電話番号から事業内容・業種情報を取得するWebスクレイピング
続いて、Seleniumで、会社名と電話番号から事業内容・業種情報を取得するWebスクレイピングを実施してみます。
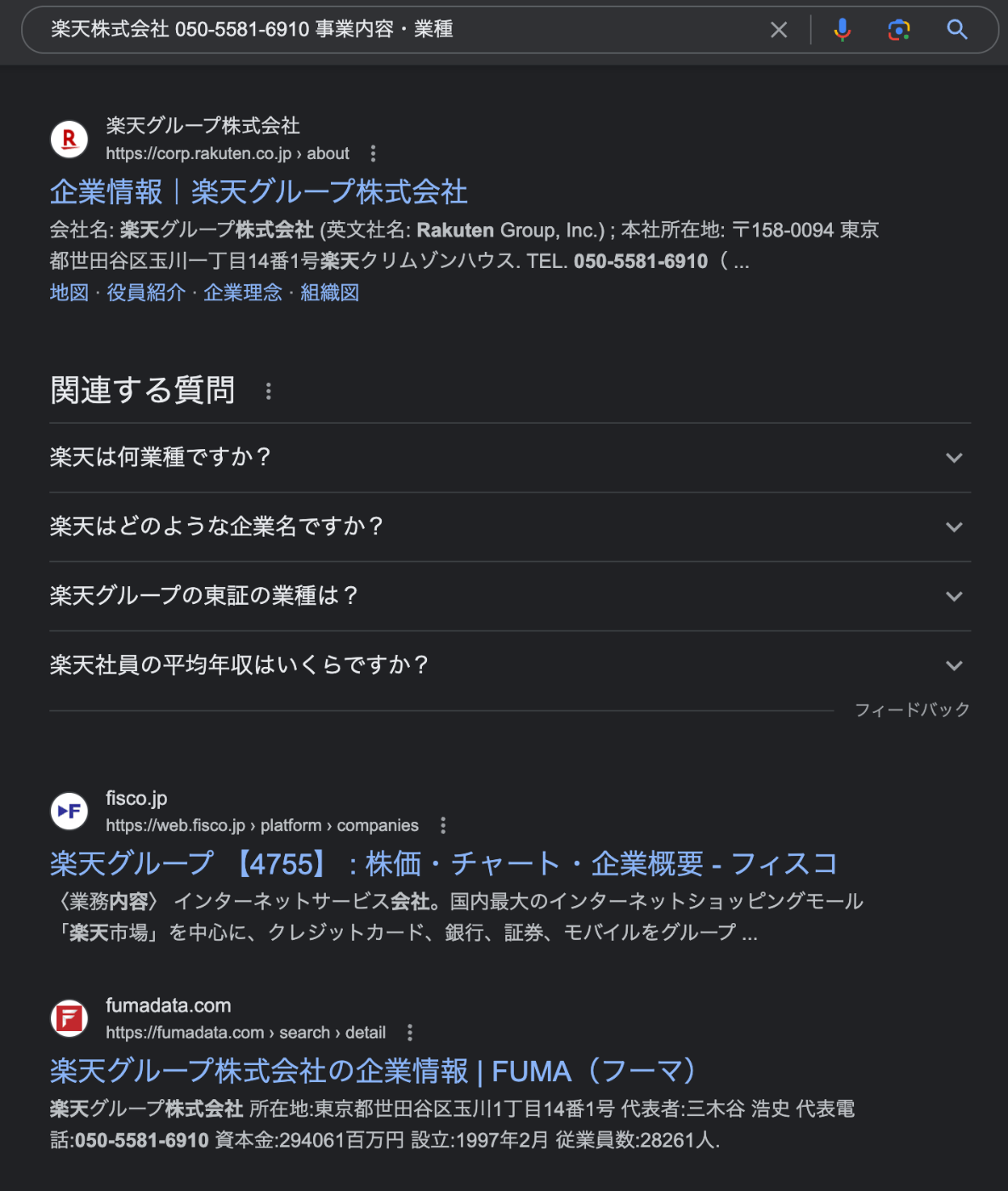
今回は、SeleniumでGoogle検索を実施して、その検索結果のdescription部分(説明文)を取得するような処理をしてみます。
(すべて取得すると、Text量が多くなるので、取得するのは、上から3つまでとします)
会社名と電話番号から事業内容・業種情報を取得するWebスクレイピング処理のSampleCodeは、次のとおりです。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import traceback
### 作成・Module ########################################################
# 1. 電話番号(会社の代表番号: 固定電話)と会社名から「事業内容・業種」の情報を取得する
########################################################################
# 電話番号
tell = '050-5581-6910' # 楽天株式会社・Tell
# 会社名
company_name = '楽天株式会社'
browser = webdriver.Chrome()
try:
browser.get('https://www.google.com/')
# 検索ボックスを見つける
search_box = browser.find_element(By.ID, 'APjFqb')
# 検索キーワード
search_word = f'{company_name} {tell} 事業内容・業種'
print(search_word)
# 検索キーワードを入力
search_box.send_keys(search_word)
# 検索を実行する(Enterキーを送信して検索を実行)
search_box.send_keys(Keys.RETURN)
# submit() でも検索できる
# search_box.submit()
# 検索結果画面が表示されるまで待機
WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.ID, 'search'))
)
# description (説明文)のTextを格納する List
search_result_list = []
# 上から、3つまでの description (説明文)を取得する
target_max = 3
# find_elements で、検索結果の description (説明文)をすべて取得する
description_lists = browser.find_elements(By.CLASS_NAME, 'VwiC3b')
# print(description_lists)
# 各要素の中の <span> タグからテキストを取得する (上から、3つまで)
for index in range(len(description_lists)):
try:
if index + 1 > target_max:
break
else:
element = description_lists[index]
span_text = element.find_element(By.TAG_NAME, 'span').text
print(span_text)
print('-------------------------------------------------------------')
search_result_list.append(span_text)
except Exception as error:
# 例外を無視したい場合は、pass を使用する
pass
except Exception as error:
# traceback.format_exc() で例外の詳細情報を取得する
error_msg: str = traceback.format_exc()
print(error_msg)
pass
finally:
# ブラウザを閉じる (エラーが発生しても必ず実行)
browser.quit()
print('取得した説明文・Text の List')
print(search_result_list)
上記ファイルを実行した結果は、次のとおりです。
SeleniumでGoogle検索を実施して、その検索結果のdescription部分(説明文)を取得できていることがわかります。
python industry_judge.py
## [実行結果] ##
楽天株式会社 050-5581-6910 事業内容・業種
会社名: 楽天グループ株式会社 (英文社名: Rakuten Group, Inc.) ; 本社所在地: 〒158-0094 東京都世田谷区玉川一丁目14番1号楽天クリムゾンハウス. TEL. 050-5581-6910( ...
-------------------------------------------------------------
〈業務内容〉 インターネットサービス会社。国内最大のインターネットショッピングモール「楽天市場」を中心に、クレジットカード、銀行、証券、モバイルをグループ ...
-------------------------------------------------------------
楽天グループ株式会社 所在地:東京都世田谷区玉川1丁目14番1号 代表者:三木谷 浩史 代表電話:050-5581-6910 資本金:294061百万円 設立:1997年2月 従業員数:28261人.
-------------------------------------------------------------
取得した説明文・Text の List
['会社名: 楽天グループ株式会社 (英文社名: Rakuten Group, Inc.) ; 本社所在地: 〒158-0094 東京都世田谷区玉川一丁目14番1号楽天クリムゾンハウス. TEL. 050-5581-6910( ...', '〈業務内容〉 インターネットサービス会社。国内最大のインターネットショッピングモール「楽天市場」を中心に、クレジットカード、銀行、証券、モバイルをグループ ...', '楽天グループ株式会社 所在地:東京都世田谷区玉川1丁目14番1号 代表者:三木谷 浩史 代表電話:050-5581-6910 資本金:294061百万円 設立:1997年2月 従業員数:28261人.']
Seleniumの仕様変更の対応について
- Seleniumの仕様が変わっており、少し前の記事を参考にすると、エラー祭りになります。。。🥺
- 詳細は、こちらの記事が参考になります。
find_element_by_XXX系の新しい書き方・チートシート
[Python] seleniumの仕様が変わっていた!?(2023/06時点)の記事から、find_element_by_XXX系の新しい書き方を引用します。
| 検索 | 旧記述 | 新記述 |
|---|---|---|
| id | .find_element_by_id("id") |
.find_element(By.ID, "id") |
| name | .find_element_by_name("name") |
.find_element(By.NAME, "name") |
| xpath | .find_element_by_xpath("xpath") |
.find_element(By.XPATH, "xpath") |
| リンクのテキスト | .find_element_by_link_txt("link text") |
.find_element(By.LINK_TEXT, "link text") |
| リンクのテキスト(部分一致) | .find_element_by_partial_link_text("partial link text") |
.find_element(By.PARTIAL_LINK_TEXT, "partial link text") |
| タグ名 | .find_element_by_tag_name("tag name") |
.find_element(By.TAG_NAME, "tag name") |
| クラス名 | .find_element_by_class_name("class name") |
.find_element(By.CLASS_NAME, "class name") |
| CSSセレクタ | .find_element_by_css_selector("css selector") |
.find_element(By.CSS_SELECTOR, "css selector") |
まとめ
Seleniumは、情報が多いため、実施したいことを実現するための情報にすぐにアクセスできて楽でした。
作成中のWebアプリでは、Seleniumを活用したWebスクレイピング機能を導入する予定なので、それが完成したら、ご紹介したいと思います。
個人で、Blogもやっています、よかったら見てみてください。
注意事項
この記事は、AIQ 株式会社の社員による個人の見解であり、所属する組織の公式見解ではありません。
求む、冒険者!
AIQ株式会社では、一緒に働いてくれるエンジニアを絶賛、募集しております🐱🐹✨

詳しくは、Wantedly (https://www.wantedly.com/companies/aiqlab)を見てみてください。
参考・引用

AIQ 株式会社 に所属するエンジニアが技術情報をお届けします。 ※ AIQ 株式会社 社員による個人の見解であり、所属する組織の公式見解ではありません。 Wantedly: wantedly.com/companies/aiqlab
Discussion