SQLアンチパターン EAVと4つの解決策
この記事はなに?
SQLアンチパターンの第5章を読んで簡単にまとめたものです。
エンジニアであれば、SQLアンチパターンを一度は目を通すことをオススメします。
EAVとは
EAVとはエンティティ・アトリビュート・バリュー(Entity Attribute Value)の略で、可変属性をサポートするなど、柔軟な設計を目指したことに起因するDB設計のアンチパターンのことです。
あなたが何かのスクールを経営していて、体験者・受講生・卒業生からアンケートを回収し、アンケート回答テーブルにデータを保存するとします。
質問したい項目が年齢と満足度であればこんな感じのテーブルになるでしょう。
| アンケートid | 年齢は? | 満足度は? |
|---|---|---|
| 1 | 25歳 | 大変満足している |
| 2 | 30歳 | やや満足している |
しかし受講生と卒業生でアンケートの質問項目が異なる場合はどうでしょうか?
その質問が回答されない場合には、nullのカラムが増えてしまうことになります。
| アンケートid | 年齢は? | 満足度は? | 良かった所は? | 体験日は? | 詰まっている所は? | 卒業日は? |
|---|---|---|---|---|---|---|
| 1 | 25歳 | 大変満足している | メンターが良かった | 2023-10-31 | null | null |
| 2 | 30歳 | やや満足している | 料金が安かった | null | DB設計 | null |
| 3 | 35歳 | 大変満足している | カリキュラムが良かった | null | null | 2023-10-31 |
この状態を防ぎたいとなった場合に出てくる一つのDB設計方法が、EAVです。
Entity: 親テーブルに対応する外部キー
Attribute: 列の名前に相当、行ごとに格納したい属性名を指定
Value:属性の値
属性と値の対応関係を入れていくことになります。
今回のアンケート回収におけるEAVだと、以下のようになるでしょう。
| アンケートid | 質問 | 回答 |
|---|---|---|
| 1 | 年齢は? | 25歳 |
| 1 | 満足度は? | 大変満足している |
| 1 | 良かった所は? | メンターが良かった |
| 1 | 体験日は? | 2023-10-31 |
| 2 | 年齢は? | 30歳 |
| 2 | 満足度は? | やや満足している |
| 2 | 良かった所は? | 料金が安かった |
| 2 | 詰まっている所は? | DB設計 |
| 3 | 年齢は? | 35歳 |
| 3 | 満足度は? | 大変満足している |
| 3 | 良かった所は? | カリキュラムが良かった |
| 3 | 卒業日は? | 2023-10-31 |
このように仮に質問項目が違うとしても、テーブルにカラムを追加する必要がない&先ほどのようにnullが生まれることはないでしょう。(やったね!)
また、受講者と卒業生に対するアンケート項目が違っていても、EAVでもうまく対応できます。
ただし、このEAVには欠点が存在します。
欠点1 データ型を指定できない
EAV設計では、複数のデータ値が入ってきます。
そのため、データ型を文字列とすることが通常ですが、そうしてしまうと日付を表すDATE型や数値を表すInt型などのデータ型を指定できなくなってしまいます。
何が起きるでしょう?
たとえば日付でグルーピングした結果を見たい場合、入ってくる値が以下のようなものだと、かなり難しいでしょう。
(もちろん正規化する処理を入れたり、フロントで値を入れる際にバリデーションすることもできますが、今回はDBに特化しているのでそこはご放念を)
2023/10/31
2023年10月31日
2023年10月末
自由に入れることができる反面、全て文字列でデータを格納してしまうと後で辛くなってしまいます。
欠点2 データを取得するSQLが冗長になる
たとえば満足度を知りたい場合、アンケート回答テーブルに「満足度」というカラムが存在していれば、基本的に1文でデータを取得できます。
select 満足度 from アンケート回答テーブル;
しかしEAVの場合には、わざわざwhere文でquestionを指定しないと、取得できません。
select 質問
from アンケート回答テーブル
where 質問 = "満足度は?";
その他に考えられるのは、受講生から「アンケートの満足度の部分に関して、何に関する満足度か分からない!」と言われ、アンケート項目を修正する場合です。
満足度の聞き方を「満足度は?」から「カリキュラムの満足度は?」と聞き方を変えると、questionカラムには「満足度は?」と「カリキュラムの満足度は?」の同じ意味を指すレコードが存在することになります。
これらをまとめて取得しようとすると以下のようなSQLになりますが、このようなことが積み重なっていくと辛くなってしまうのが想像できます。整合性が取れなくなってしまいますね、、
select 質問
from アンケート回答テーブル
where 質問 = "満足度は?" or 質問 = 'カリキュラムの満足度は?';
解決策
欠点を上げてきましたが、これらを解決する方法が4つあります。
1つずつ簡単に紹介していきます。
STI
STI(Single Table Inheritance)は単一テーブル継承の略です。
複数の関連するエンティティを1つのテーブルに結合して、共通のカラムを持つ親クラスと、それに特有の属性を持つ子クラスを含む階層的なデータモデルを作成することです。
「アンケートタイプ」のようなカラムを追加することで、どのアンケートか分かるようにします。
| アンケートタイプ | 年齢は? | 満足度は? | 良かった所は? | 体験日は? | 詰まっている所は? | 卒業日は? |
|---|---|---|---|---|---|---|
| 体験者 | 25歳 | 大変満足している | メンターが良かった | 2023-10-31 | null | null |
| 受講生 | 30歳 | やや満足している | 料金が安かった | null | DB設計 | null |
| 卒業生 | 35歳 | 大変満足している | カリキュラムが良かった | null | null | 2023-10-31 |
テーブルのイメージはこんな感じ。
ただ、オレンジで囲んだ部分は擬似的なテーブルであり、実際に作成されるテーブルではありません。
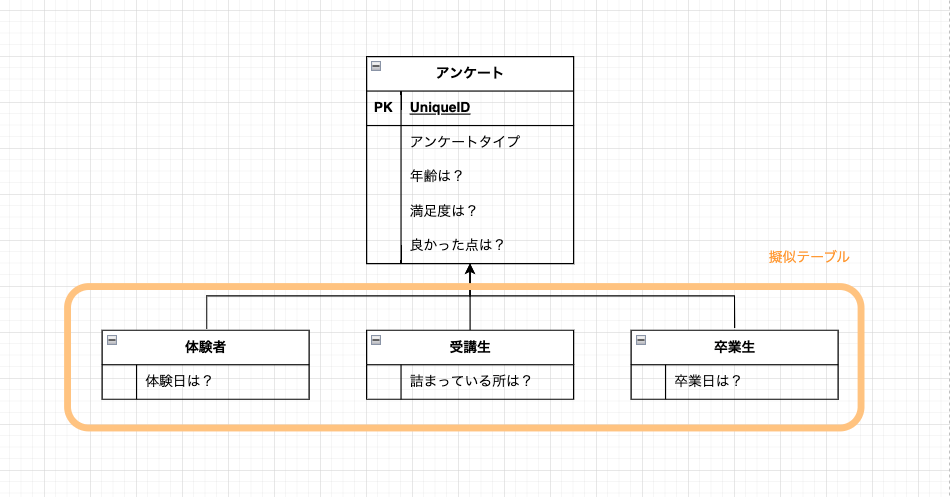
全てのデータはアンケートテーブルに保存され、「アンケートタイプ」というカラムで、どのアンケートなのかを判別します。
メリット
- データの型をカラムごとに定義できる
- 異なるタイプのアンケートを1つのテーブルにまとめることができるため、テーブル数が減り、DBの構造がシンプルになる
- 1つのテーブルを参照するだけでデータを取得できる
- 共通の属性を1つのテーブル(アンケートテーブル)で定義できる
デメリット
- 新しいタイプを作ると新しいカラムが必要
- たとえばメンターにアンケートを取りたいとなった時は、メンター用の質問項目をアンケートテーブルのカラムに追加しないといけない
- そうなると、メンター以外の体験者や受講生のレコードはnullが増えてしまう
- カラムがどのタイプと関連づくのかを設定できない
- 体験者は「体験日」、受講生は「詰まっている所」、卒業生は「卒業日」など、アンケートタイプがどのカラムと紐づくのか、必要としているのかを知りたいです
- しかしSTIでは親テーブルで全てのカラムを管理するため、体験者は卒業日を入力してはいけないのに、誤った値が追加されてしまう可能性があります
| アンケートタイプ | 年齢は? | 満足度は? | 良かった所は? | 体験日は? | 詰まっている所は? | 卒業日は? |
|---|---|---|---|---|---|---|
| 体験者 | 25歳 | 大変満足している | メンターが良かった | 2023-10-31 | null | 2020-04-01 |
| 受講生 | 30歳 | やや満足している | 料金が安かった | null | DB設計 | null |
| 卒業生 | 35歳 | 大変満足している | カリキュラムが良かった | null | null | 2023-10-31 |
CCI
CCI(Concrete Class Inheritance)は具象クラス継承の略です。
STIから、全てのタイプに共通のカラムも含めて、タイプごとにテーブルを分けたものです。
テーブルのイメージはこんな感じ。

メリット
- タイプごとにテーブルを分けているため、タイプとカラムの紐付きが明確になる
- STIのデメリット解消
- タイプごとにテーブルを分けているため、先ほどまで入っていたnullが入らなくなる
- そのテーブルに特有の新しいカラムを増やしたい場合には、該当のテーブルに増やせば他のテーブルにはそのカラムが存在しないのでnullにならない
デメリット
- 全てのテーブルに共通のカラムと、そのテーブル特有のカラムの区別がつかなくなる
- 共通のカラムを追加したい時は、全てのテーブルにカラムを追加する必要がある
- 今回のケースで言うと「使っているパソコンは?」という質問を全員に聞きたい場合に、体験者・受講者・卒業生の全てのテーブルにカラムを追加しなければならない
- タイプが増えるとテーブルが増える
CTI
CTI(Class Table Inheritance)はクラステーブル継承の略です。
全てのタイプに共通のカラムを持つ抽象クラス、そのタイプ特有のカラムを持つ具象クラス、という形でテーブルを分けたものです。
テーブルのイメージはこんな感じ。
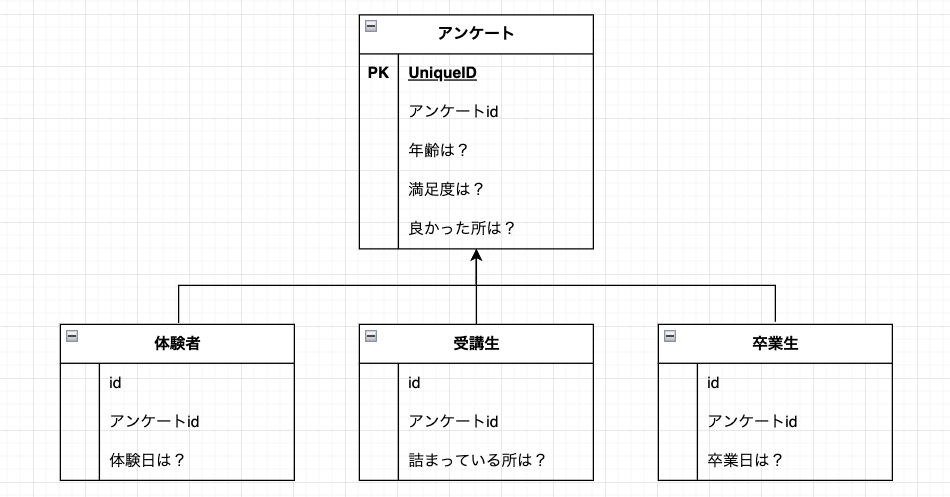
メリット
- 共通のカラムとそのテーブル特有のカラムの区別がつく
- 共通のカラムを追加する時は、抽象クラスのテーブルに追加することで完結する
- タイプごとに追加しなくて良い
- タイプごとにテーブルを分けているため、nullが入らなくなる(CCIと同様)
デメリット
- タイプが増えるとテーブルが増える(CCIと同様)
半構造化データ
これはEAVと若干考え方が似ていますが、、、
XMLやJSONで属性と値を一つのカラムに格納する方法です。
たとえばJSONで格納する場合は以下のようになります。
(MYSQLではカラムにJSON型を指定することができます)
| id | 値 |
|---|---|
| 1 | { "年齢は?" : "25歳", "満足度は?" : 大変満足している", "良かった所は?" : "メンターが良かった", "体験日は?" : "2023-10-31" } |
| 2 | { "年齢は?" : "30歳", "満足度は?" : やや満足している", "良かった所は?" : "料金が安かった", "詰まっている所は?" : "DB設計" } |
| 3 | { "年齢は?" : "35歳", "満足度は?" : 大変満足している", "良かった所は?" : "カリキュラムが良かった", "卒業日は?" : "2023-10-31" } |
メリット
- 拡張性が非常に高い
- 質問が頻繁に変更される場合でも対応可能
- EAVは質問数に応じてレコードが追加されるのに対して、JSONは1レコード内に値が全て格納される
デメリット
- SQLで特定の属性にアクセスする手段がほぼない
- インデックスを貼れないので目的のレコードを効率よく取得できない
最後に
(あくまで個人的感想ですが、)SQLアンチパターンはエンジニアであれば一度は目を通すことをオススメします。
今回あげたEAVとその解決策は、ソフトウェアの設計において非常に重要な観点だと思っています。
今回挙げたEAVがSQLアンチパターンだからといって、絶対に使ってはいけないというものではなく、ビジネスサイドが求める要件と照らし合わせると、EAVという意思決定をすることになるかもしれません。
どのような意思決定をするにせよ、本書の内容を知っている、知っていないで、DB設計で考慮すべき点や、考える観点がかなり変わると今回感じました。
設計って面白い。
Discussion
参考になる記事をありがとうございます。
列数がものすごい量、例えば300列を超えるような場合、EAVの選択肢もありますかね?
例)データテーブル
ID
型式
データA1~10
データB1~10
・
・
・