DeepseekV3は何がすごいのか?何故ヤバいと言われているのかを解説
なぜDeepSeek V3は“破壊的”なのか?
大規模言語モデル(LLM)といえば、OpenAIのGPTシリーズやMetaのLlamaシリーズなど、膨大な学習コストと大手企業の潤沢なリソースが必要というイメージが強いかもしれません。しかし、2024年末にリリースされたDeepSeek V3は、その“常識”を一変させる存在として大きな注目を集めています。
- わずか数カ月・約558万ドルという圧倒的低コストで学習完了
- GPT-4oに匹敵する性能をうたうオープンソースモデルであり、APIも数分の1~十数分の1と圧倒的価格破壊を起こしている
- Mixture-of-Experts(MoE)を活用して370B級モデルを安価・高速に動作
こうしたインパクトは「破壊的」と評されるに十分でしょう。これまで「開発コスト」や「リソース」による参入障壁が高かったLLMの世界に、新たな扉を開く可能性を秘めているからです。AI agent時代に突入する1つのトリガーになると筆者も感じています。
本記事では、DeepSeek V3がどのようにしてこの低コスト×高性能を実現しているのか、そして実際の活用シーンや注意点は何かを、初心者にもわかりやすく解説していきます。最後まで読み進めることで、単なる話題性に留まらず、ビジネスや研究現場における具体的な利点が見えてくるはずです。
1. 圧倒的なコストパフォーマンスがもたらす衝撃
まずはどのくらいこのDeepseekが圧倒的なコスパなのかを見てください。
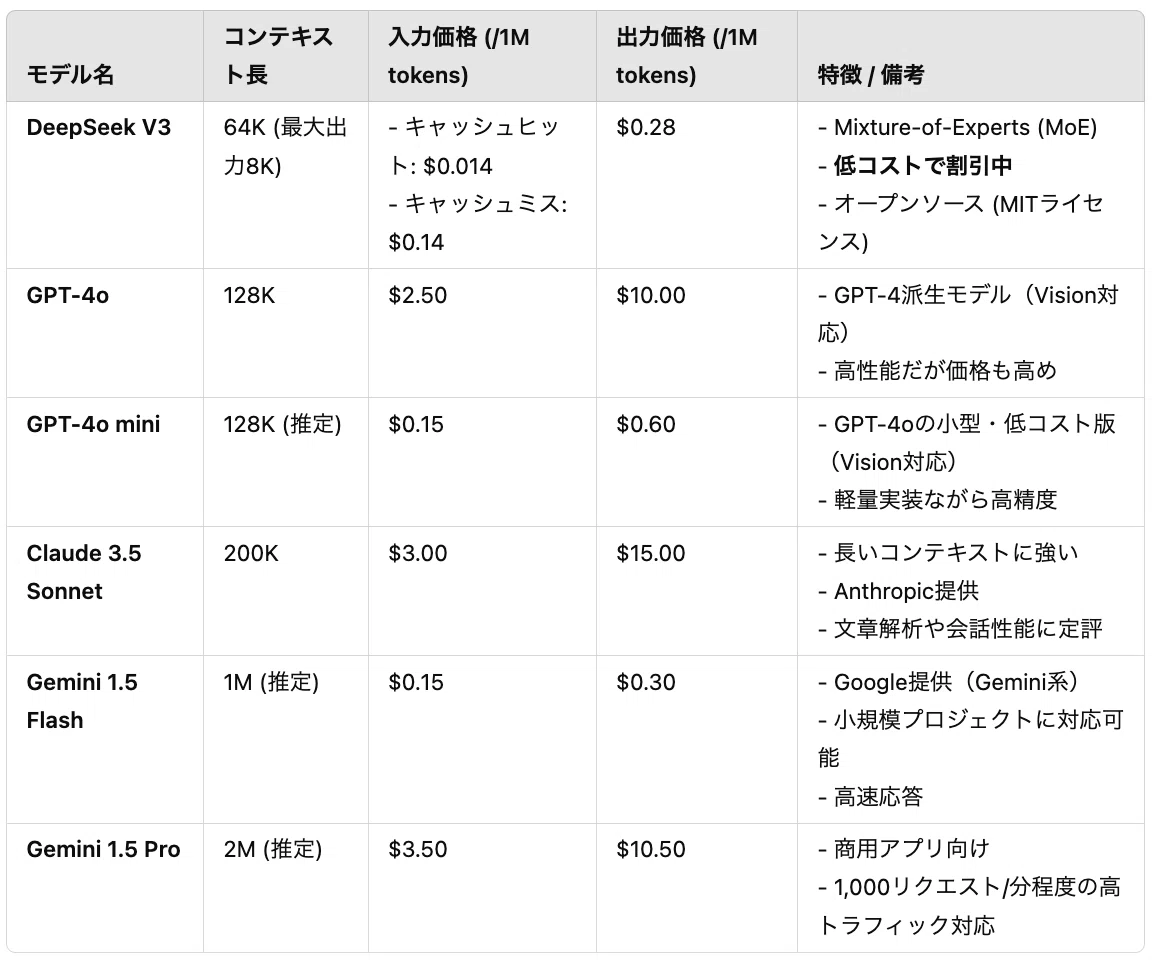
実際の個人開発レベルでLLMを組み込もうとすると、どうしてもコスト面から4o-miniやgemini1.5flashが選ばれがちです。しかし品質という観点でいくならばまだまだ伸び代を感じるのが正直な話でしょう。特にClaudeやChatGPTのサブスクに契約している方なら尚更です。
それらの低価格モデルよりも安いのがとにかくポイントと言えるでしょう。Claude3.5SonnetをAPI経由で使用し、AI Agent開発を1日中しようものならかなりの請求を覚悟する必要がありそうです(すぐに1万円2万円なくなる)。
そんなこともDeepseek V3 APIを使えば数百円とか数十円とか、そのレベルになるのです。AI agentの仕組みも裏側ではバンバンこれらLLMのAPIを叩いているのが一般的ですので、この低価格がAI Agentの発展に大きく影響する可能性は言うまでもないでしょう。
わずか2カ月・約558万ドルで学習
DeepSeek社によれば、DeepSeek V3は約2カ月間で学習を完了し、その費用は約558万ドル(6億円弱) とされています。オープンAIが4o(GPT-4)開発に“数十億ドル”、MetaがLlama 2に“数億ドル”規模を投じたと言われるなかで、この数字は破格と言えるでしょう。
大規模パラメータ+MoEによる効率化
DeepSeek V3は6710億パラメータを持つ超大規模LLMですが、実際に推論に使われるのは370億パラメータ相当となるよう設計されています。これは「Mixture-of-Experts(MoE)」という技術により、トークンごとに必要な“専門家”モジュールだけを活性化させる仕組みのおかげ。膨大な総パラメータを抱えながらも、実行にかかるリソースを抑えることに成功しています。
GPT-4o級性能をオープンソース+激安APIで
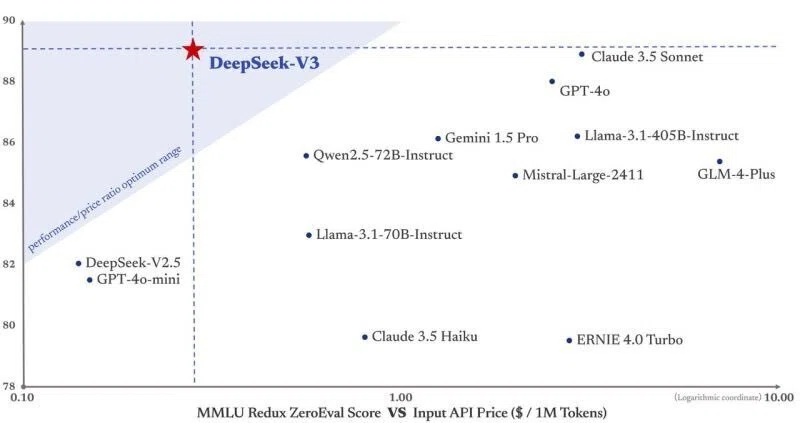
DeepSeek社自身のベンチマークや外部の初期検証によると、数学タスク・プログラミングタスクなど多方面でGPT-4oに肉薄あるいは同等以上の性能を示すケースが報告されています。しかもDeepSeek V3はMITライセンスの下、オープンソースとして公開されているため、自由にカスタマイズや再配布が可能です。
【宣伝】AI開発に関する最新トピックや、初心者からプロ向けのTIPSをX(旧Twitter)で日々発信しています。「もっと知りたい」「最新情報を逃したくない」と感じていただけたら、ぜひフォローをお願いします!👇👇
https://x.com/AI_masaou
2. 具体的にどんなタスクに使えるのか?
DeepSeek V3をはじめとするLLMが一般的に得意とするタスクは、多岐にわたります。しかし、このモデルが“破壊的”なのは、大掛かりなGPUリソースを必ずしも必要とせず、比較的少ない予算でこれらのタスクを実現できる点にあります。
2-1. RAG(Retrieval-Augmented Generation)による高度な情報検索
DeepSeek V3は128Kトークン相当のコンテキスト長をサポートします。これは、さらにRAG(Retrieval-Augmented Generation)という手法を組み合わせれば、事前に文書データを検索エンジンなどでピンポイントに取り出してから生成を行うことが可能です。
こうすることで、大量のテキストを無理やりモデルに食わせる必要がなくなり、トークンの浪費を抑えた効率的な応答が期待できます。
2-2. 感情評価や書評などの“定性処理”
生成AIの強みは、定量的な数値計算だけでなく、人間が読む文書のトーンや感情、意図を理解し、それに対する評価や所感を生成できる点にあります。たとえば、
- 書籍の内容を要約しつつ、感想や書評を付け加える
- SNSの投稿や製品レビューからユーザーの感情を分析する
- 映画のストーリーラインからテーマを抽出する
などの“定性処理”も、DeepSeek V3であれば低コストに実行できるでしょう。
2-3. チャットボット・QAシステム
ユーザーとの対話形式で情報をやりとりするチャットボットやQAシステムは、LLMの代表的なユースケースの一つです。DeepSeek V3が持つ大容量のコンテキスト処理は、長い会話履歴や複雑な問い合わせへの対応に向いており、ドキュメント検索×QAにも相性が良いです。
2-4. コード生成やデバッグ支援
コーディングタスクに強いことも、DeepSeek V3の特徴として挙げられています。ログイン機能や機械学習アルゴリズムのサンプルコード、さらにはバグ修正や最適化のヒントなど、開発現場での「もう少し詳しいアドバイスがほしい」というニーズにも応えてくれる可能性があります。
3. コスト比較のイメージ:本当に安いのか?
OpenAIのGPTシリーズやAnthropicのClaudeシリーズと比べても、数分の1〜10分の1程度の推論コストで利用でき、特にリリース直後は割引価格が適用されるためさらに導入しやすくなっています。
たとえばDeepSeek公式サイトのAPI料金表を見ると、入力・出力ともに100万トークンあたり数十セント〜数ドルという水準で提供されており、GPT-4oの数分の1に収まるケースもあるようです。
もちろん利用形態や負荷量によって最適な選択は異なりますが、「高性能LLMをリーズナブルに試してみたい」というニーズには、まさに“破壊的”な価格設定と言えるでしょう。
4. DeepSeek V3導入時の注意点
4-1. 本当に“宣伝どおり”の性能か?
急速に注目を集めているモデルだけに、「学習コストや性能が誇張されているのでは?」と疑問視する声もあります。ベンチマーク結果はまだ発展途上であり、実際のユースケースで本当にGPT-4o級のパフォーマンスを発揮できるかは慎重に検証が必要でしょう。
私まさおが使っている感じだと、4oよりも好きになれそうなレスポンスを返してくれますし、ちょっとした問題を解決する能力も非常に優れていると感じられます。
4-2. 安全性・コンプライアンス対応
DeepSeek V3はMITライセンスで提供されているため、利用にあたって特定の制限は少ない反面、出力コンテンツの安全性確保や著作権・プライバシーの取り扱いなどは利用者の責任となります。業務に導入する場合、フィルタリングやポリシー設定をしっかり検討することが不可欠です。
4-3. 大容量モデルのホスティング
Hugging Face上でモデルをダウンロードしようとすると、数百GB規模のファイルを多数落とす必要があり、オンプレ環境やGoogle Colabなどで動かすのは容易ではありません。基本的にはDeepSeek提供のAPIやChat版を使うのが無難でしょう。自前ホスティングを検討する場合は、GPUクラスタやストレージ要件などを十分に確保する必要があります。
5. “破壊的”なLLMがもたらす未来
DeepSeek V3のような低コスト・高性能のLLMが普及していくと、次のような進展が期待されます。
-
中小企業や個人開発者による参入
従来はAI分野で「大企業ほど優位」が常識でしたが、学習・推論コストのハードルが下がることで、小規模組織や個人開発者でも高度なAIサービスを開発・展開できるようになります。 -
エージェント化の加速
生成AIが、ユーザーと対話しながらタスクを自律的にこなす“エージェント”として進化する流れが加速するでしょう。RAGや複数APIの連携を組み合わせれば、カスタマーサポートから業務フローの自動化まで、幅広い分野で多様なエージェントが活躍できます。 -
特化型モデルの続々登場
オープンソースとして公開されることで、専門分野向けにファインチューニングされた“特化型DeepSeek V3”の登場が予想されます。たとえば医療、法律、学術研究など、それぞれの領域に最適化されたモデルが容易に作られる可能性があります。
まとめ:DeepSeek V3で広がる新たな可能性
DeepSeek V3は、
- 数カ月・数百万ドル規模で最先端級モデルを実装
- オープンソース+商用利用も可、APIも激安で提供されている
- サービス開発やエージェント開発が激変する可能性がある
- RAGやエージェント化にも相性抜群
といった要素を兼ね備えた**“破壊的”な大規模言語モデル**です。これまで大手企業の独壇場だったLLM開発が、一気に裾野へと広がる契機となり得るでしょう。
一方で、性能の信頼性や安全性対応など、実務・現場で使ううえでは慎重な検証が必要です。ただ、そのハードルをクリアした先には、「低予算で企業や個人が強力なAIサービスを生み出す未来」や、「あらゆる業務領域を一気通貫で自動化するエージェント活用」という壮大な可能性が見えてきます。
深い知見や大きな決断がなくとも、“とりあえず試してみる”というアプローチが許容できるコスト水準であることが、何より大きな魅力といえるでしょう。ぜひ一度、その力を体感してみてはいかがでしょうか。
ここまでお付き合いいただき、ありがとうございます。
今後もAI分野の新しい活用方法や開発テクニックを、X(旧Twitter)でいち早く紹介していきます。
少しでも興味があれば、ぜひフォローして最新情報をチェックしてくださいね!
Discussion