VS CodeでXMLを効率よく編集したかった話
概要
サービスやソフトウェアの開発において、ある理由から、統一されたフォーマットで整えられたテキストデータが大量に必要となりました。ここで、賢い方ならCSVやJSONなどの有用なデータフォーマットの名称を挙げると思います。
当記事では、有用なデータフォーマットの中でも、最近影が薄くなったように感じるXMLをピックアップ。XMLの基本をおさらいしたうえで「それ専用のエディタを導入するのも面倒だな・・・」と考えた筆者が、普段使用しているVS Codeでなんとかできないか?と奮闘した記録です。途中、以下のサービスやテクノロジーが登場します。
- VSCode,VSCode Extentions(拡張機能)
- XML,XML Schema,.xml,.xmd
- XML(vscode-xmlもしくはXML Language Support by Red Hatとも. VSCodeの拡張機能)
拡張機能のXML(vscode-xml,XML Language Support by Red Hat)にのみ興味のある方は前半読み飛ばしてください。
筆者のPC環境
当記事の前提として、以下の作業環境を使用しています。
- macOS Monterey v12.3
- VSCode v1.65.0
- Java JDK 11(※)
※詳しくは後述しますが、拡張機能のXML(vscode-xml,XML Language Support by Red Hat)の動作時にJava JDK( or JRE)を利用するケースが存在します。なくても動作するとのことですが、当記事(筆者環境)では事前にJava JDKがインストール済みの環境下で動作確認を行なっています。
XMLって何でしたっけ?
Extensible Markup Languageの略称(XはExの発音記号とのこと。)で、和訳すれば「拡張可能なマークアップ言語」となります。
- <や>の記号で挟んだ"Element(要素)"
- Elementに付随する"Attribute(属性)"
- Elementの中身である"Text(内容)"
などから構成されています(サンプルは後述)。マークアップ言語と言えば、HTML(Hyper Text Markup Language)なども有名ですが、これはWebページ(Hyper Text)を表現するために最適化されており、
- h1は見出し
- pは段落
- brは改行
などのように要素の意味や使い方が決まりきっています。これに対して、XMLは「拡張可能」とだけあって、要素、要素と別の要素の関係性などを自由に決めることができ、データフォーマットとして広く利用されています。
他のテキストデータフォーマットとの違い
筆者の認識範囲で、パッと思いつく違いをCSV,JSON,XMLの順番で例と合わせて挙げてみます。
CSV
step,name,amount,unit
1,たまご,2.0,egg
2,塩,1.0,tsp
- フォーマットを実現するために必要な記述がカンマ(,)と改行だけでよく、構造もシンプルで覚えやすい
- 箇条書き、テーブル、行列、関係データベース(RDB)など1次元もしくは2次元情報の表現に適している
- シンプルなため、パーサー(解析器)の実装が低コストで済む
JSON
{
"recipe":{
"dishname":"スクランブルエッグ",
"material":[
{ "name":"たまご", "amount":2.0, "unit":"egg" },
{ "name":"塩", "amount":1.0, "unit":"tsp" }],
"procedure":[
"フライパンにたまごを割り入れて火にかける",
"適度に火が通ったら、塩で味付けをして混ぜた後に盛り付ける" ]
}
}
- フォーマットを実現するために必要な記述がCSVに比べると多い({}、:、"、[]、,など)
- 複雑な構造を表現することが可能
- 数字・文字列・配列など様々なデータ型を識別可能
- 基本的にはパーサー(解析器)の実装が必要だが、生まれ故郷のJavaScriptをはじめとした複数のプログラミング言語ではそのままデータ(オブジェクト)として処理可能
XML
<recipe>
<dishname>スクランブルエッグ</dishname>
<material amount="2.0" unit="egg">たまご</material>
<material amount="1.0" unit="tsp">塩</material>
<procedure>
<step>フライパンにたまごを割り入れて火にかける</step>
<step>適度に火が通ったら、塩で味付けをして混ぜた後に盛り付ける</step>
</procedure>
</recipe>
- <、>、/といった記号や要素を何度も書く必要があり、CSVやJSONよりも記述量が多くなりがち
- JSONに負けず劣らず汎用性が高く、複雑な構造を表現することが可能
- 多くのデータ型を識別できるほか、独自のデータ型も実現可能
- 多くの開発環境でパーサー(解析器)の実装が必要
- 構造を検証する機能を持つ
大雑把にまとめると次のようになります。
| フォーマット名 | データ作成負荷 | 汎用性 | 開発負荷 |
|---|---|---|---|
| CSV | 低い | 低い | 低い |
| JSON | 高い | 高い | 高い(環境によってはとても低い) |
| XML | とても高い | 高い | 高い |
こうしてみると、XMLはデータ作成の負荷(記述量の多さ、複雑な構造からくる手間)が高い事に加え、開発の負荷も高く、他のデータフォーマットに比べると見劣りするかもしれません。(もちろん、データ作成負荷はエディタやツールを活用することで軽減できますし、開発負荷も既存のソフトウェアや各種開発環境に用意されたライブラリやパッケージを導入することで大きく減らすことも可能です)
不便な技術は淘汰されるものですが、XMLは未だ強力なデータフォーマットとして知られています。では、それはなぜでしょう?
筆者が思うその答えのひとつは、構造を検証する機能であると考えています。(筆者の趣味もあります。異論は認めます。)
スキーマ
"構造を検証"するとはどういう事でしょうか?
XMLファイルを作成するだけであれば、独自の要素名を思うがままに決め、<と>に挟んだり、要素の間に内容を書いたテキストを任意のテキストエディタで作成し、保存する際に拡張子を.xmlとするだけで問題はありません。しかし、このままでは後々困った問題が発生するかもしれません。
例えば、XMLで記述された「料理レシピ」のデータ作成者が複数名おり、各々が大量のデータをせっせと作成している場合を考えてみます。
<recipe>
<dishname>親子丼</dishname>
<material amount="2.0" unit="egg">たまご</material>
<!-- 以下略 -->
</recipe>
<recipe>
<!-- 書き忘れ -->
<material amount="2.0" unit="egg">たまご</material>
<!-- 以下略 -->
</recipe>
おっと、sampleB.xmlでは料理名を記載するdishname要素の記述を失念してしまったようです。これが仮にレシピを紹介するサービスやアプリに利用するデータであれば、「料理名が無い」というのは致命的です。
<recipe>
<disuname>天丼</disuname>
<memo>天丼食べたい</memo>
<material amount="2.0" unit="egg">たまご</material>
<!-- 以下略 -->
</recipe>
このsampleC.xmlにおいては、正しくはdishname要素であるべき部分が間違ってdisuname要素になっているうえ、開発側の想定していないmemo要素がなぜか追加(改竄)されてしまっています。こんなデータが開発側に渡った日には・・・考えるだけでもゾッとします。
- 要素間の関係性(親子関係や記述順序)
- 記述が必須の要素なのか、必須であれば何回記述すれば良いのか
- 属性の有無、必須なのか選択制なのか
- 属性に紐づいた値(=の右側)のデータ型はどんなものか
- 内容の有無
などなど、事前にXMLの中身について全体で合意形成を行い、都度チェック・・・つまり、"構造を検証"できていればこんなに困ることはありません。
XMLではスキーマと呼ばれる、要素・属性・内容(つまりはテキスト)の構造を記述・記録しておく仕組みを持つことで、前述の問題を次のような方法で改善することが可能です。
- データ作成時:スキーマを参照することで、入力ミス、入力忘れがないかのチェック
- 開発時:スキーマを参照することで、パーサーがきちんと動作しているかのチェック
スキーマ言語
XMLのスキーマを用意するには、専用のスキーマ言語であるXML Schemaを使用し、XSDファイルを生成する事が一般的です(かつてはDTDと呼ばれるスキーマ言語がありましたが、今はXML Schemaが主流のようです)。
XMLに加えて、さらにXML Schemaも覚えるの?つらっ!?と感じたそこのあなたっ!ご安心ください。後述するVSCodeの拡張機能の一つであるXML(vscode-xml,XML Language Support by Red Hat。名前紛らわしいのなんとかならんの・・・)を使用すれば、学習コストをかなり抑えることが可能です。
スキーマを参照する方法
では、スキーマはどのようにして参照するのでしょうか?
残念なことに、ただXMLファイルを書いたり、XSDファイルを用意するだけでは参照はかないません。この参照を実現するためには、検証対象を渡すことで検証結果を返す専用のサービス(以下、Language Server)を作成する必要があり、これを個人で実現する事はあまり現実的ではありません。
そこで、Language Serverを内包したエディタを使用しましょう!!と、いうのがXMLでデータを作成する際の主流となっているようです。
今回筆者は、これ以上使うツールを増やしたくない一心で愛用していたVS CodeにXML用のLanguage Serverを持つ拡張機能を発見したので、それに飛びつく事を決めました。
VSCode拡張機能のXML(vscode-xml,XML Language Support by Red Hat)
前置きが長くなりましたが、いよいよ本題です。VSCodeでXMLのLanguage Serverを持つ拡張機能を導入して使います。
当記事の作成時点ではver0.19.1で、preview版でありながらも愛用者はかなり多い模様です。
Javaについて
かつてこの拡張機能のLanguage Server実行にはJava(JDK)が必要とされていましたが、ここ近年のアップデートで、必ずしもJavaをインストールする必要がなくなりました。導入が手っ取り早くて嬉しいですね。
導入ステップ
VSCodeの拡張機能画面を開き、検索窓にXMLと入力します。私の場合は、検索結果の筆頭として出現しました。
installボタンをクリックします。
install完了後は、適当なXMLファイルを作成し、VSCodeで開くだけです。インストール直後だけでも、編集効率のアップが図れる次の機能が即時利用可能です。
- シンタックスエラー
- 共通コード(1行目の<?xml?>,コメントアウトなど)の自動補完
- 閉じタグの自動記述
- 要素間の関係性を考慮した自動インデント
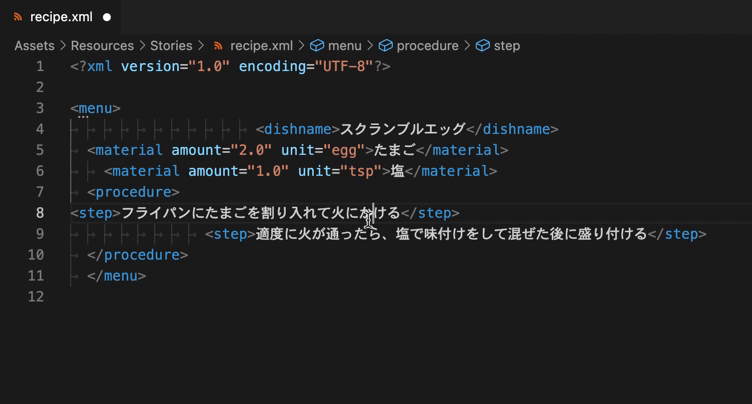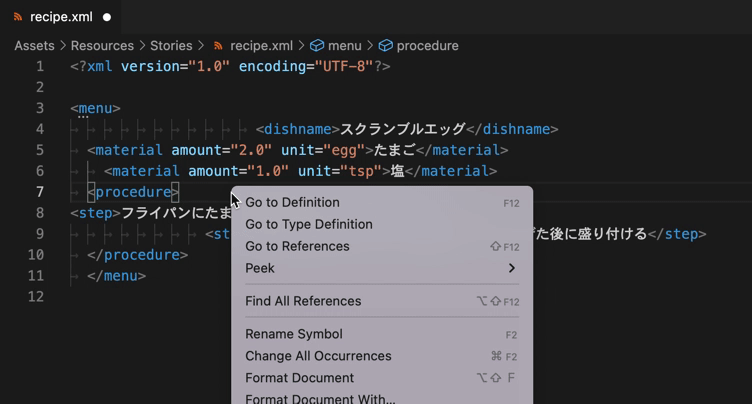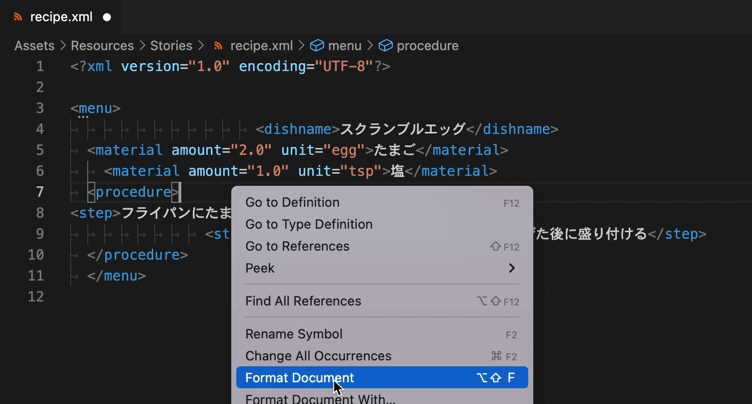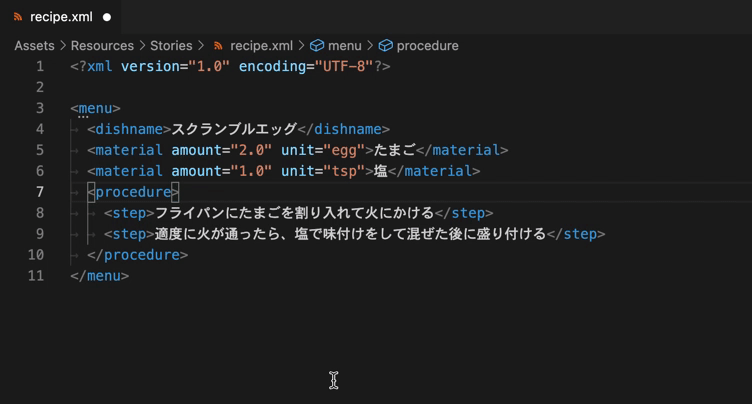
- シンボルハイライト(記号、要素、属性、値、内容の色分け)
- 要素の折りたたみ表示
- 要素のリネーム(同じ文字列の一斉変更も可能)
- 変なインデント、スペースや不要な改行などを一瞬で綺麗に整形
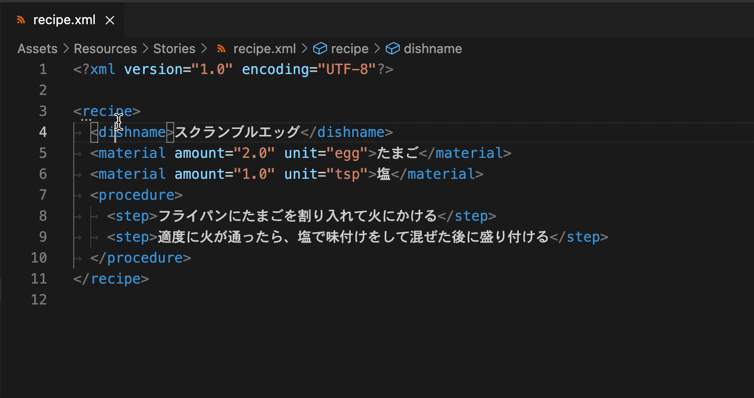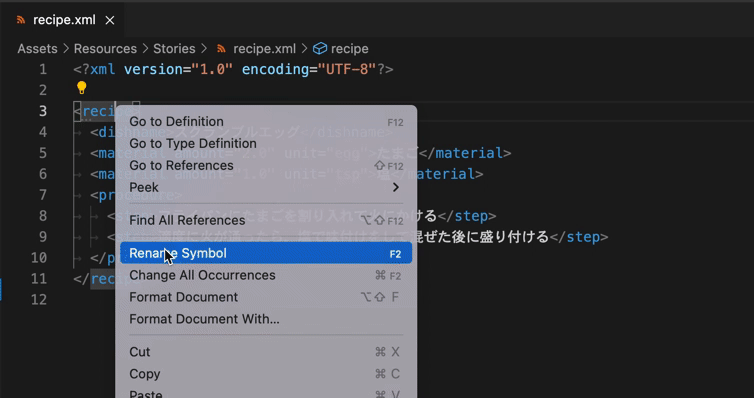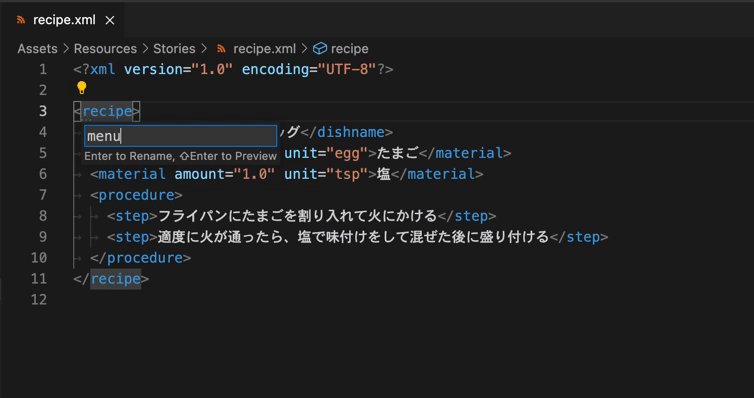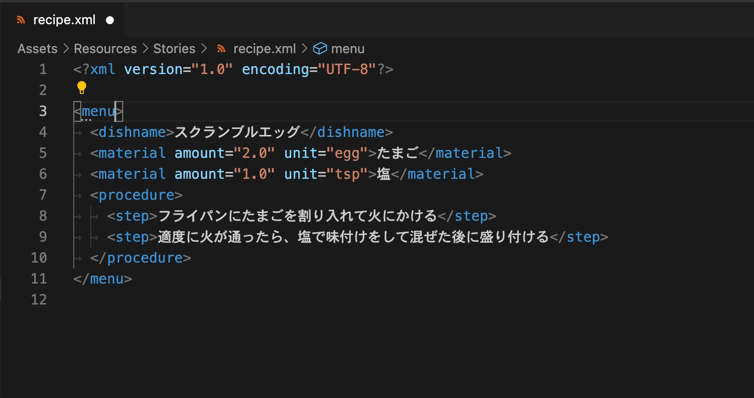
続けて、XML Schemaによって記述されたスキーマ(以下、XSDファイル)を用意し、構造を検証する機能(XSD validation)や自作構造による自動補完(XSD based code completion)を利用してみます。
スキーマの準備
XSDファイルについてですが、この拡張機能にはなんと既に出来上がっているXMLファイルから自動生成する機能がついています。これで1から文法を理解してわざわざ作り上げる手間が省けます。
試しに前述のrecipe.xmlからXSDファイル(recipe.xmd)を生成してみます。
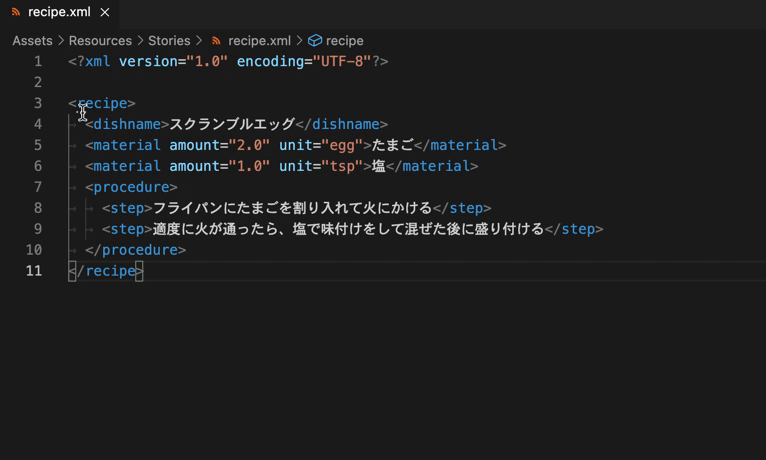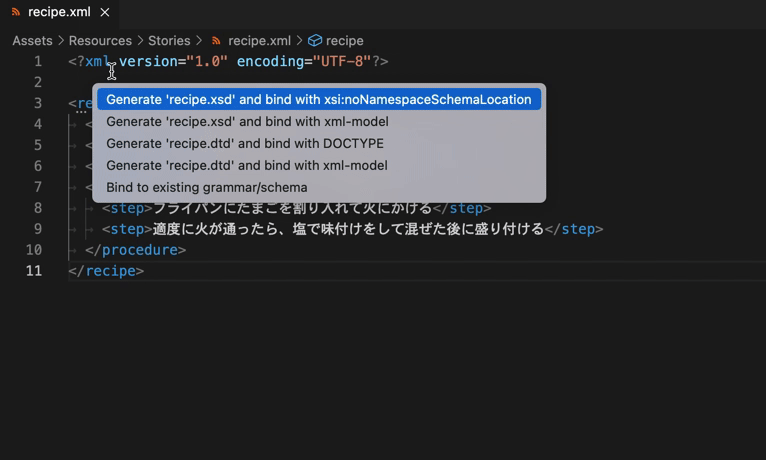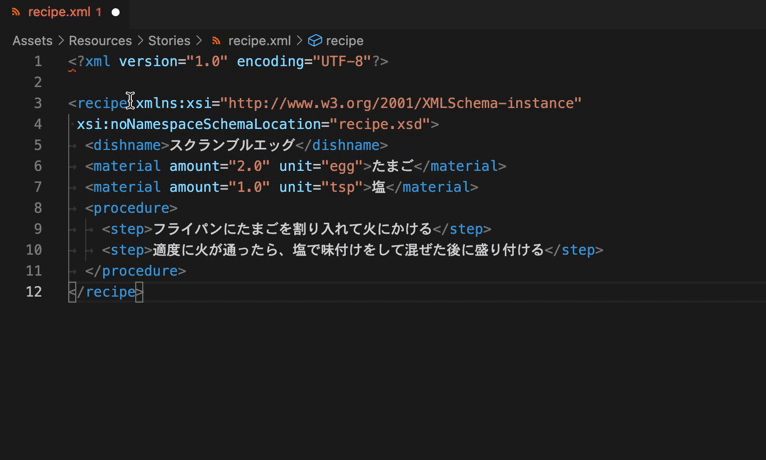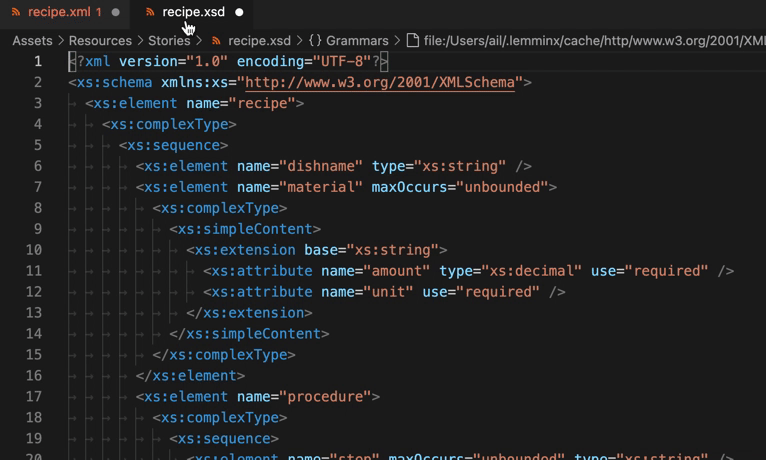
以下は自動生成されたrecipe.xmdの内容です。このまま使う分には問題はありませんが、内容を変更したりするケースではXML Schemaへの理解が必要です。記事末尾のリンクをご参照ください。
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="recipe">
<xs:complexType>
<xs:sequence>
<xs:element name="dishname" type="xs:string" />
<xs:element name="material" maxOccurs="unbounded">
<xs:complexType>
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="amount" type="xs:decimal" use="required" />
<xs:attribute name="unit" use="required" />
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
<xs:element name="procedure">
<xs:complexType>
<xs:sequence>
<xs:element name="step" maxOccurs="unbounded" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
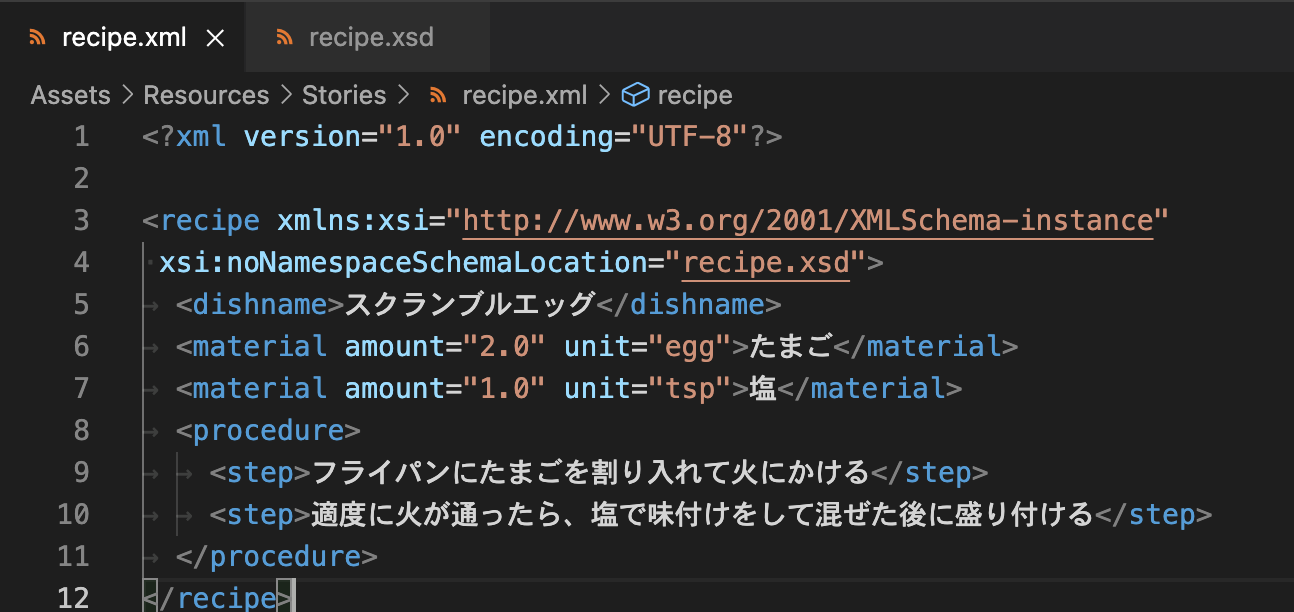
生成に成功すると、生成元のrecipe.xmlのルート要素であるrecipe要素に参照先を示す属性が追加されています。これが意味するところは後述します。
スキーマの参照
XSDファイルの参照を行うためには、Language Serverのつくりに合わせた手続きが生じます。幸いな事にこの拡張機能では様々な参照方法が用意されており、データ作成環境に合わせて柔軟な選択肢が取れるようになっています。
- xsi:noNamespaceSchemaLocation属性を使用する
- xsi:schemaLocation属性を使用する
- XML Catalogを使用する
上記以外にも参照方法は様々存在しますが、当記事ではほんの一部しか取り上げませんので他の方の記事や公式をご参照下さい。
今回は、難しい事を考えずにひとつ目に提示した「xsi:noNamespaceSchemaLocation属性を使用する」方法を試してみたいと思います。
ネームスペース
xsi:noNamespaceSchemaLocation属性を使用する方法を確認する前に、ネームスペースについておさらいします。
XML(及び、その仕様を忠実に再現したLanguage Server)では、複数のスキーマ間の関係性を明確化するため、ネームスペース(名前空間)を作成します。例えば、" http://www.w3.org/2001/XMLSchema "などがこれにあたります(URL及びドメインはグローバルな環境であっても基本的に重複する事がないと知られているためよく使用されます)。こうする事により、複数のXMLが混在するデータ作成や開発においても同名の要素を区別することが可能です。
例えば、次のような要素が混在するデータの作成が生じたとします。(良いアイデアが思いつかなかったので、無理やり感ありますが・・・)
- 「料理レシピ」内の「材料」を示すmaterial要素
- 「洋裁」内の「素材」を示すmaterial要素
この場合、次のようにネームスペースを分けて記載方法を工夫します。(ネームスペースは仮のものです。実際に該当するURLは存在しません。)
| ネームスペースの定義 | 使用するとき |
|---|---|
| xmlns:ck="http://cooking.now/" | <ck:material> |
| xmlns:dm="http://dressmaking.now/" | <dm:material> |
上記における、ckとdmは該当するネームスペースを呼び出すための別名です。
xsi:noNamespaceSchemaLocation属性を使用する
スキーマの参照方法に話を戻しますが、「xsi:noNamespaceSchemaLocation属性を使用する」方法は、既存のネームスペースを間借りすることで新しくネームスペースを作ることなく、XSDファイルを直接参照してしまおう!という方法です。
実はこの方法、つい先程スキーマの準備を行う過程で、recipe.xmlに自動で付与された文字列の事を指しています。
つまり、新しい「料理レシピ」データを用意したくなったら、recipe.xmlに付与された文字列と同じものを書き足せば良いという事になります。とってもお手軽です。
構造を検証
では実際に、新しいXMLファイル(以下、recipe2.xml)を用意し、生成されたXSDファイル(以下、recipe.xsd。前述のrecipe.xsdと同様)を参照することで"構造を検証"できることを確認します。
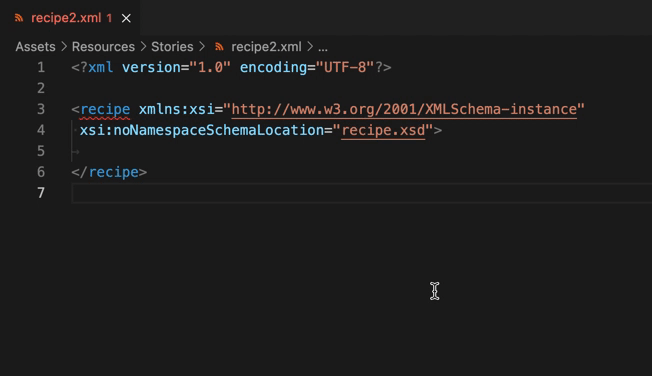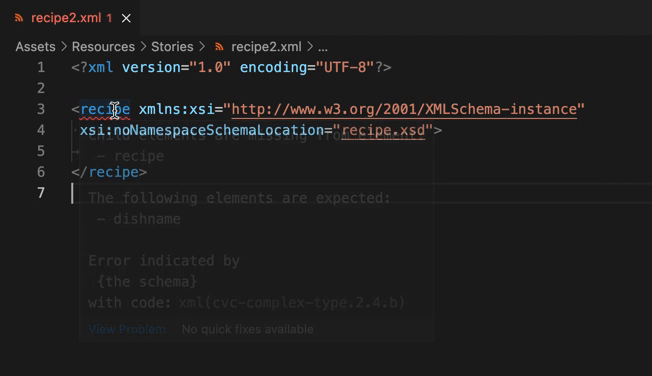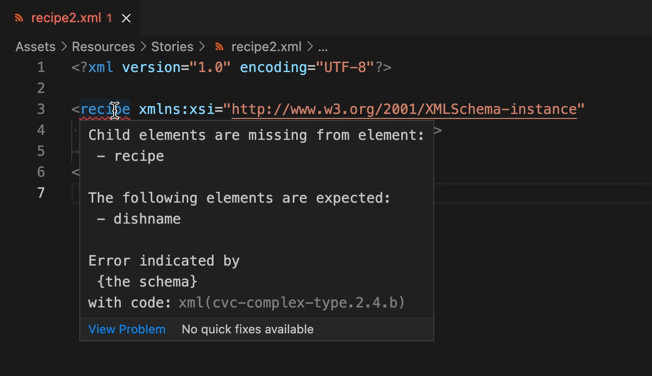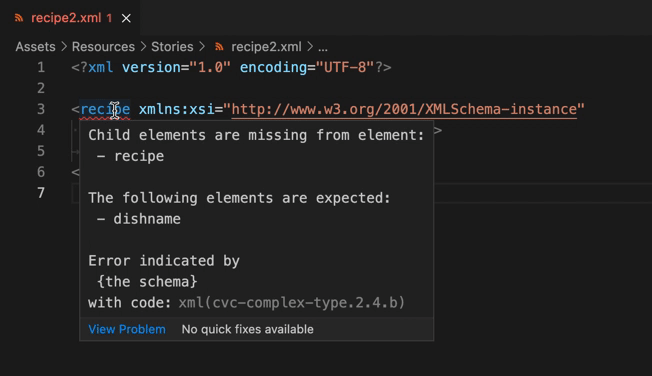
まずはお作法的に、recipe2.xmlの1行目にXMLファイルお決まりの文字を記載します。続けて、ルート要素のみを記述します。
<?xml version="1.0" encoding="UTF-8"?>
<recipe>
</recipe>
ここで、 recipe要素の開始タグへ記述を足します。なお、xsi:noNamespaceSchemaLocation=の右側にはrecipe.xmdへのファイルパスを記載して下さい。
<?xml version="1.0" encoding="UTF-8"?>
<recipe xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="recipe.xsd">
</recipe>
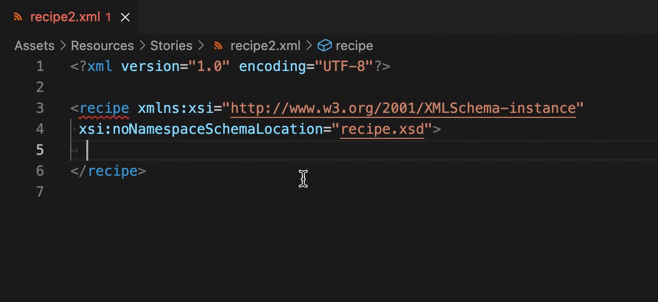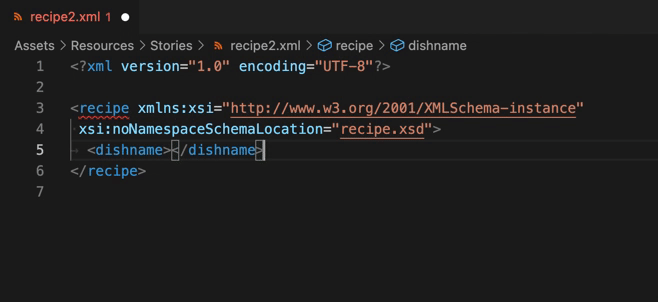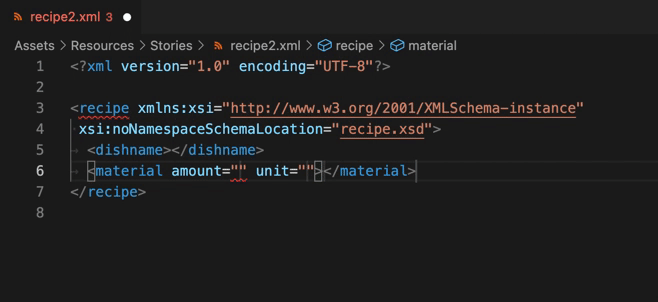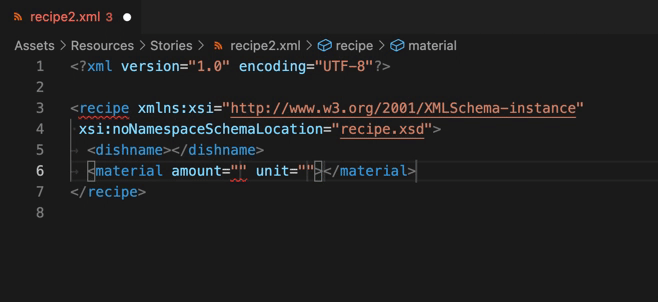
ここまで入力を進めると、「xsi:noNamespaceSchemaLocation属性を使用する」方法が採用されていることがLanguage Serverに理解され、recipe要素の開始タグに赤いアンダーラインが引かれ、構造を検証する機能(XSD validation)が有効になっていることがわかります。
またこの状態で要素を書き足そうとすると、自作構造による自動補完(XSD based code completion)も有効になります。
終わりに
ふぅ、これでXML量産体制の土台作りが出来ました。捗って助かるうううう。
参考
当記事の執筆にあたり、下記URLを参考にさせていただきました。感謝。
Discussion