🌴
HTTPエンドポイントからAWSのデータベース(Timestreamなど)にデータを書き込むシンプルな方法
Amazon Timestream は、AWSの時系列データベースサービスで、IoTなどのデータシンクとしてよく利用されるようです。
今回、InfluxDB で運用しているデータシンクを Amazon Timestream に置き換えるため、HTTP(S)のエンドポイントを介して Amazon Timestream に最も簡単に書き込む方法を検討しました。その中でもっとも簡単そうな構成である、AWS Lambda の Function URL を利用する方法ついて情報を共有します。
構成の概要
外部サービス ⇒ Function URL ⇒ AWS Lambda ⇒ Timestream
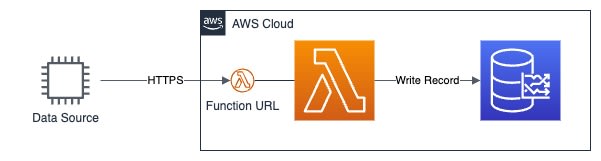
Google 等で検索すると Function URLの代わりに API Gateway を使う方法が比較的多く見つかりますが、 2022年4月から提供開始された AWS Lambda を HTTP エンドポイントから直接呼び出す機能である Function URL を利用すると AWS Lambda と Timestream だけで構成できるため、より簡易な実装が可能になります。
基本的な作業の流れ
LambdaとTimestreamを接続する基本的な手順は以下の記事によくまとまっており、参考にしました:
- Timestreamに書き込み先のテーブルを作ります
- Timestreamに書き込み権限のあるロールをIAMで作成します。今回の例では以下の2つの権限を付与すれば良いでしょう:
- AWSLambdaBasicExecutionRole — Lamda実行時のログなどで必要
- AmazonTimestreamFullAccess — Timestreamに書き込む際に必要
- AWS Lambdaを作成し、コードの中でTimestreamに書き込む関数を作成し、その関数に上記のIAMロールを割り振ります。
関数の中身はPythonだとライブラリboto3を利用する事になり、以下のような感じになります(詳細後述):import boto3 import json import time def lambda_handler(event, context): data = json.loads(event['body']) # データをRequest Bodyから取る場合 current_time = str(int(round(time.time() * 1000))) # Timestampは必須。形式は文字列 client = boto3.client('timestream-write') # 書き込みに使うオブジェクト database = 'SOME_DATABASE' table = 'SOME_TABLE' dimensions = [{ 'Name': 'hoge', 'Value': 'fuga' }] records = [{ 'Dimensions': dimensions, 'MeasureName': 'foo', 'MeasureValue': 'var', 'Time': current_time }] try: result = client.write_records( DatabaseName=database, TableName=table, Records=records, CommonAttributes={}) return { "statusCode": 200, "body": str(result) } except Exception as err: print("Error:", err) return { "statusCode": 500, "body": str(err) } - 上記のLambdaに、Function URLを設定します。Function URLに認証を設定しない場合は生成したURLを他の人に漏らさないようにしましょう。必要であれば、IAMや、CROS などを用いてアクセスコントロールを行うこともできます。
- 作成した Function URL にデータをPOSTすると、Timestreamにデータを書き込むことができます。とりあえず cURL でテストする場合(前述の Lambda の関数は、実際にはBodyの内容を利用していないので、ここで渡すJSONデータはダミーです):
url=https://${URL_ID}.lambda-url.${AWS_REGION}.on.aws/ curl --verbose --request POST --url $url \ --header 'content-type: application/json' \ -d@- <<EOM { "some": "json-data", } EOM
この例ではデータシンクを Timestream (時系列データベース) にしていますが、これは DynamoDB (NoSQL)、Amazon Aurora (RDS) など置き換えることも可能です。
AWS Lambda Function URLを使う上での技術的なポイント(Pythonの場合)
- 基本的に、Function URLにアクセスがあると、設定した関数が起動されます。
- 起動される関数は、Python の場合、標準の Lambda ハンドラの 仕様 に従い、に2つの変数 (通常
eventとcontextとする場合が多い) を取ります。- HTTPリクエストに関係するパラメータは基本的に
eventの方に入っています。 -
contextの内容の詳細が知りたい場合は AWS Lambda context object in Python
などを見ましょう。
- HTTPリクエストに関係するパラメータは基本的に
- HTTP POSTでURLに渡されたBodyは、
event['body']で取り出せます。 - Python の標準出力は Lambda のログに接続されていますので、
print()などで書き出したログは、Lambda のコンソールにあるログから読むことができます。 - 関数のもどり値は、HTTPレスポンスで利用されます。フォーマットについては Lambda function response format に従いますが、多くの場合はサンプルのように
statusCodeとbodyを要素に持つ辞書形式のデータを返せば十分です。
InfluxDB と Timestream の概念のマッピング
InfluxDB のユーザの方は、だいたい以下のマッピングと解釈すると Timestream の概念が理解できます。
| InfluxDB | Timestream |
|---|---|
| timestamp | time field |
| tags | dimensions |
| fields | measures |
| measurements | table name |
Discussion