Hyperdrive試してみたよ
2023/09/28 Cloudflare Birthday Week のブログで Hyperdrive というサービスが発表された。

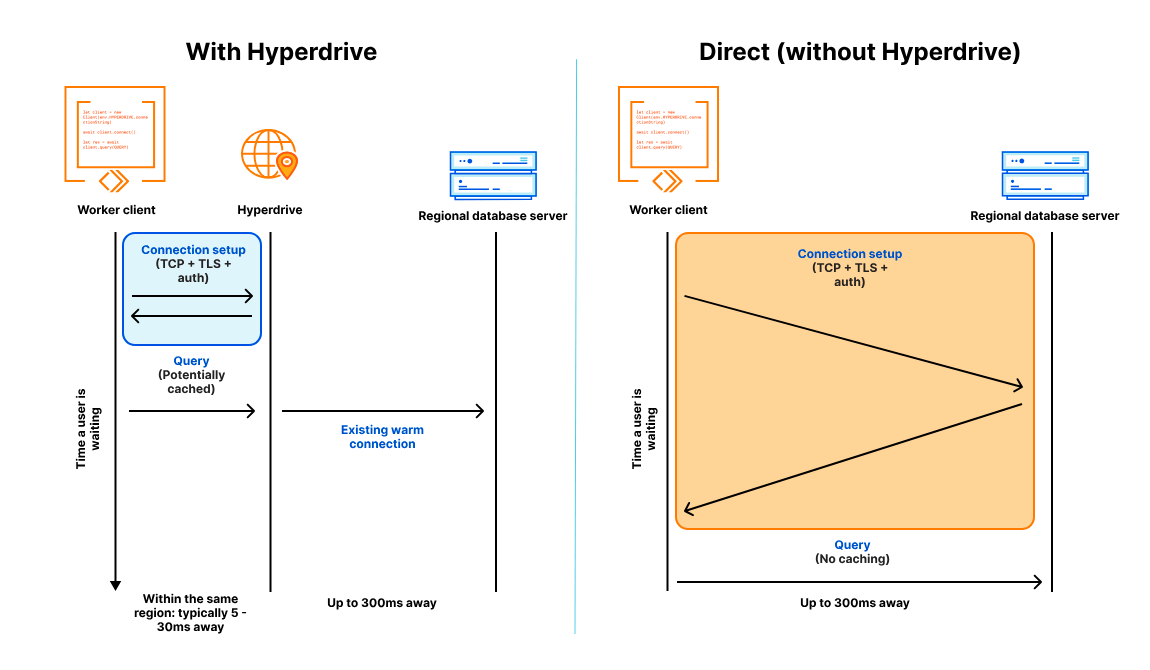
In a modern distributed cloud environment like Workers, where compute is globally distributed (so it’s close to users) and functions are short-lived (so you’re billed no more than is needed), connecting to traditional databases has been both slow and unscalable. Slow because it takes upwards of seven round-trips (TCP handshake; TLS negotiation; then auth) to establish the connection, and unscalable because databases like PostgreSQL have a high resource cost per connection.
Workers のような最新の分散クラウド環境では、コンピューティングがグローバルに分散され (そのため、ユーザーの近くにあり)、機能の有効期間が短く (そのため、必要な分だけ請求されません)、従来のデータベースへの接続は遅く、拡張性がありませんでした。 。接続を確立するのに 7 回以上の往復 (TCP ハンドシェイク、TLS ネゴシエーション、その後認証) がかかるため遅く、PostgreSQL のようなデータベースは接続あたりのリソース コストが高いため拡張性がありません。
Workersに限らず、一般的なサーバレスコンピューティングではDBとのコネクションが維持できないので、リクエストのたびにコネクションのオーバヘッドがかかってしまうのがよくある課題である。
昨今ではDBプロバイダ側がPgBouncerのようなコネクションプーリングプロキシを用意するケースは増えているが、それでもサーバレスコンピューティング側からプロキシにコネクションをはるオーバヘッドは残っていた。
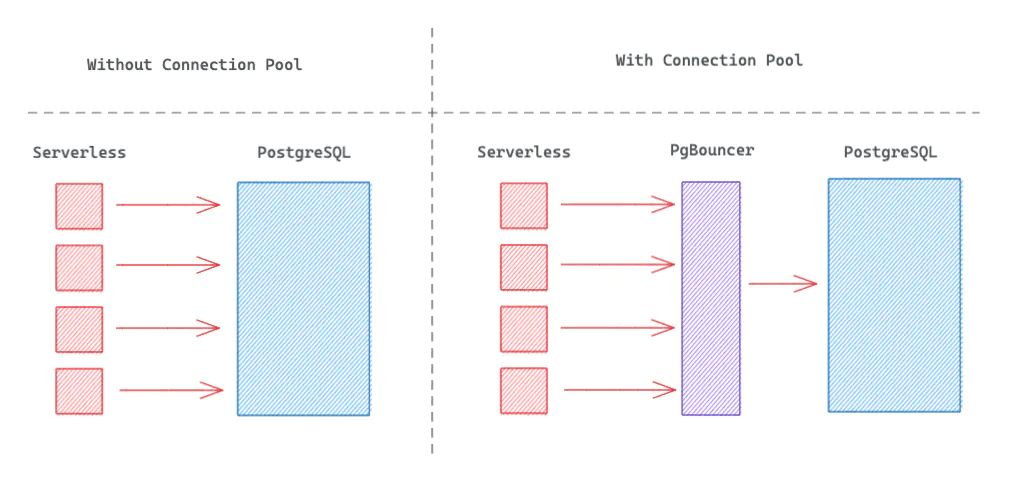
CloudflareはWorkers用にHyperdriveと呼ばれるサービスをクライアントに近い位置に立ち上げておき、事前にHyperdriveがDBとの接続を確立しておくことで、初回のコネクションにかかるオーバヘッドを大きく削減するらしい。
さらにクエリキャッシュを備えているので、キャッシュが効く状況下ではかなり高速化が期待できそう。
ということで早速試してみた。
ブログによれば、2023/09/29 現在、Workers有料プランユーザはオープンベータ版が使用可能であるとのこと。
たしかに、Webコンソールを覗いてみると、新たにHyperdriveが増えていることが確認できる。
ただ、ここはダッシュボードというわけではなく、使用開始方法がまとめられているだけ。
まずは、DBとサンプルデータを用意する必要がある。
Hyperdrive works not only with PostgreSQL databases — including Neon, Google Cloud SQL, AWS RDS, and Timescale, but also PostgreSQL-compatible databases like Materialize (a powerful stream-processing database), CockroachDB (a major distributed database), Google Cloud’s AlloyDB, and AWS Aurora Postgres.
PostgresSQLならおおよおなんでも接続が可能。
We’re also working on bringing support for MySQL, including providers like PlanetScale, by the end of the year, with more database engines planned in the future.
MySQLも年末までに対応できるように頑張っているとのこと。
筆者は、以前Neonのアカウントを検証用に用意するだけしておいて、全く使っていなかったので、Neonを使ってみることにした。
Webのコンソールからぽちぽち操作してデータベースを立ち上げる。
今回は検証用にあえて遠いリージョン(オハイオ)を選択。
最終的にこんな感じのpostgres用のURLスキーマが得られるので、手元にコピーしておき、ChatGPTに用意してもらった簡易なテーブルとデータを流し込んで準備完了。
つづいてドキュメントにあるとおりに進めていく
worker用のプロジェクトを立ち上げる
$ npm create cloudflare@latest
# Call the application "hyperdrive-demo"
# Choose "Hello World Worker" as your template
wrangler hyperdrive createコマンドを使って、先程用意したDB用のHyperdriveを作成
# Using wrangler v3.10.0 or above
wrangler hyperdrive create a-faster-database --connection-string="postgres://user:password@neon.tech:5432/neondb"
# This will return an ID: we'll use this in the next step
wrangler hyperdrive list で確認可能。
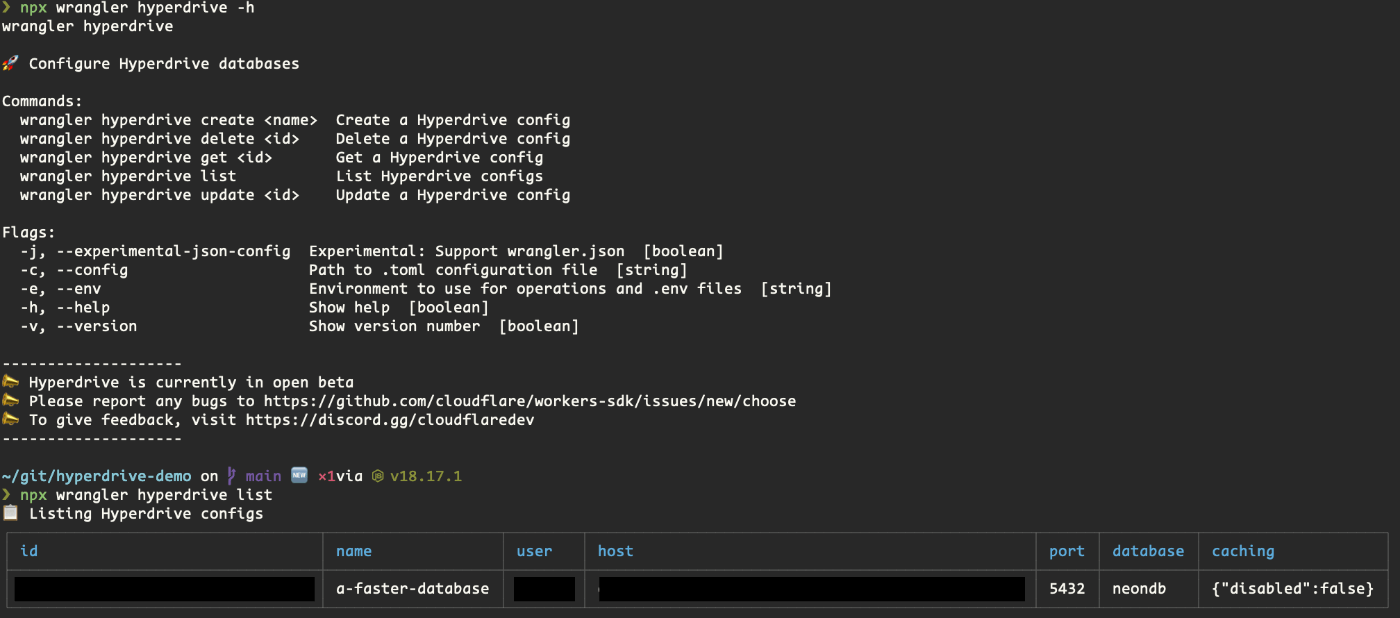
このIDをwrangler.tomlにbindingとして書き込む
name = "hyperdrive-demo"
main = "src/index.ts"
compatibility_date = "2023-09-22"
node_compat = true
[[hyperdrive]]
binding = "HYPERDRIVE"
id = "xxxxxxxxxxxxxxx"
そして、workerのコードを書いていく。
pg clientを利用するので、インストールが必要。
$ npm install pg
workerのコードはこんな感じ
// src/index.ts
import { Client } from 'pg';
export interface Env {
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
try {
await client.connect();
const result = await client.query({ text: 'SELECT * FROM users LIMIT 50' });
return Response.json({ result: result });
} catch (e) {
console.error(e);
return Response.json({ error: JSON.stringify(e) }, { status: 500 });
}
},
};
続いてローカルでworkerを起動してみる。
$ npx wrangler dev --remote
コンソールに表示されたURLを開くとデータが取得できているのがわかる。
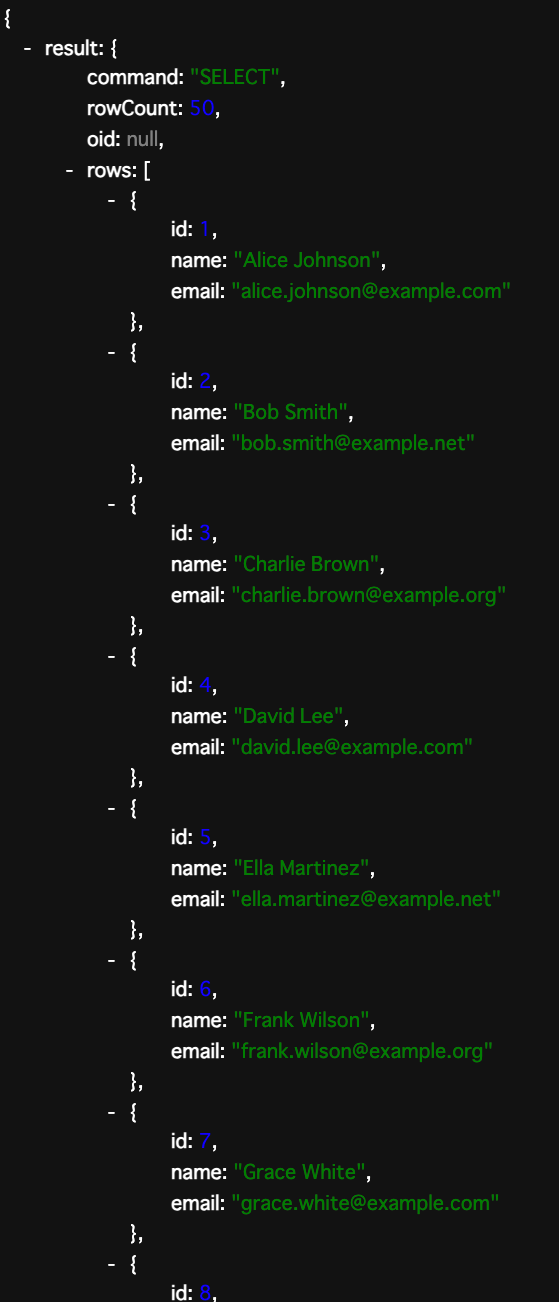
DBからデータが取れることは確認できたので、パフォーマンスを計測してみる。
条件は、
- Hyperdriveを使用せず、WorkerからDBへダイレクトにTCPコネクトするケース
- クエリキャッシュを無効化したHyperdriveを使用してDBへ接続するケース
- クエリキャッシュを有効化したHyperdriveを使用してDBへ接続するケース
1回のWorkerに対してのリクエスト内で、50件のレコードを取得するクエリを10回発行し、発行からデータ返却までの時間(コネクションを確立する時間を含む)を計測する。
なお、クエリキャシュは wrangler hyperdrive updateコマンドで制御できる。(デフォルトではクエリキャシュは有効)
$ npx wrangler hyperdrive update -h
wrangler hyperdrive update <id>
Update a Hyperdrive config
Positionals:
id The ID of the Hyperdrive config [string] [required]
Flags:
-j, --experimental-json-config Experimental: Support wrangler.json [boolean]
-c, --config Path to .toml configuration file [string]
-e, --env Environment to use for operations and .env files [string]
-h, --help Show help [boolean]
-v, --version Show version number [boolean]
Options:
--origin-host The host of the origin database [string]
--origin-port The port number of the origin database [number]
--origin-scheme The scheme used to connect to the origin database - e.g. postgresql or postgres [string]
--database The name of the database within the origin database [string]
--origin-user The username used to connect to the origin database [string]
--origin-password The password used to connect to the origin database [string] [required]
--caching-disabled Whether caching query results is disabled for this Hyperdrive config [boolean]
--------------------
📣 Hyperdrive is currently in open beta
📣 Please report any bugs to https://github.com/cloudflare/workers-sdk/issues/new/choose
📣 To give feedback, visit https://discord.gg/cloudflaredev
--------------------
結果(※ QC=クエリキャシュ)
| # | Hyperdriveなし | Hyperdriveあり(QC無効) | Hyperdriveあり(QC有効) |
|---|---|---|---|
| #1 | 1,563ms | 242ms | 264ms |
| #2 | 195ms | 243ms | 61ms |
| #3 | 194ms | 240ms | 50ms |
| #4 | 195ms | 240ms | 48ms |
| #5 | 196ms | 240ms | 51ms |
| #6 | 195ms | 239ms | 49ms |
| #7 | 195ms | 239ms | 53ms |
| #8 | 195ms | 239ms | 48ms |
| #9 | 195ms | 238ms | 52ms |
| #10 | 196ms | 239ms | 47ms |
「Hyperdriveなし」の場合、初回のコネクションのオーバヘッドが著しく大きいことが確認される。2回目以降は約200msでレスポンスを返しているため、単純に計算すると、コネクション確立に約1,300msかかっていると解釈できる。このオーバヘッドはWorkerにリクエストするたびに発生するだろう。
「Hyperdriveあり」の状況を観察すると、前述の「Hyperdriveなし」の場合に確認されたオーバヘッドが消失している。しかし、クエリキャッシュが無効の状態では、クエリがデータを返却するまでの時間が「Hyperdriveなし」と比較して40〜50msほど遅延している。これは、Hyperdriveがコネクションのオーバヘッドを先取りしているものの、WorkerとHyperdriveの間の通信時間が増加しているためだと考えられる。
前述の画像からも、WorkerとHyperdrive間に5〜30msのレイテンシが存在することが示されている。これが上記の遅延の原因である可能性が高い。

実際の使用シーンでは、1リクエスト内でのクエリ発行は数回になるだろう。そして、非同期処理を利用して並列リクエストを行うなどの工夫をすれば、1クエリあたりの応答は遅くなるかもしれないが、全体としては大幅に速度向上が期待できる。
また、クエリキャッシュが有効かつヒットしている場合、約50msでデータが返却されている。キャッシュが効かないケースを除けば、Hyperdriveの効果は非常に大きいと言えるだろう。
料金に関して
2023/09/29現在は、コネクションプーリング・クエリキャッシュ両方が無料で使えるとのこと。
ただし、クエリキャッシュに関しては今後(多分オープンベータが外れるとき?)有料化の可能性があるとのこと。
制限に関して(一部抜粋)
- データベース数: アカウントあたり10個
- 初期接続タイムアウト: 15秒
- アイドル接続タイムアウト: 10分
- 多分10分間リクエストがないとHyperdrive-DB間の接続が切られるということか?
上記の検証で立てたデータベースはオハイオリージョンだったが、実際に日本人である私がサービスを作るときは、ほとんどのケースで国内のリージョンを選択することになる。
その前提でどの程度の効果が得られるのか再度検証することにした。
しかし残念なことにNeonには日本リージョンはないので(最寄りはシンガポール)、Supabaseで東京リージョンを利用することにする。更に、サービスが違うとなると、上記のデータと比較するのはあまりフェアではないため、ロケーションが離れたデータベースも再度Supabseで構築して計測し直す。
前提
1回のWorkerに対してのリクエスト内で、50件のレコードを取得するクエリを10回発行し、発行からデータ返却までの時間(コネクションを確立する時間を含む)を計測
- ケース
- Hyperdrive未使用
- Hyperdrive使用(クエリキャッシュ無効化)
- Hyperdrive使用(クエリキャッシュ有効化)は、ロケーションの影響をあまり受けないため今回は省略
- ロケーション
- 遠距離: Supabaseバージニアリージョン
- 近距離: Supabase東京リージョン
結果
遠距離ロケーション(バージニア)
| # | Hyperdrive未使用 | Hyperdrive使用(QC無効) |
|---|---|---|
| #1 | 916ms | 353ms |
| #2 | 183ms | 327ms |
| #3 | 182ms | 326ms |
| #4 | 183ms | 327ms |
| #5 | 182ms | 327ms |
| #6 | 182ms | 329ms |
| #7 | 182ms | 341ms |
| #8 | 182ms | 327ms |
| #9 | 182ms | 326ms |
| #10 | 183ms | 327ms |
遠距離ロケーション(バージニア)での測定では、全体的な傾向はNeonのオハイオリージョンのケースと大差はない。
しかし、#2以降(コネクション確立後)の処理時間にHyperdriveの有無で100ms以上の差が見られる。Hyperdriveの設置位置はCloudflareが決定するため、今回のケースでのWorkerやDBとの位置関係が最適化されていなかった可能性がある。
近距離ロケーション(東京)
| # | Hyperdrive未使用 | Hyperdrive使用(QC無効) |
|---|---|---|
| #1 | 54ms | 19ms |
| #2 | 9ms | 12ms |
| #3 | 9ms | 11ms |
| #4 | 9ms | 12ms |
| #5 | 9ms | 11ms |
| #6 | 10ms | 12ms |
| #7 | 9ms | 12ms |
| #8 | 9ms | 11ms |
| #9 | 9ms | 11ms |
| #10 | 10ms | 11ms |
近距離ロケーション(東京)での結果は興味深い。
#2以降はHyperdriveの有無に関わらず10ms前後での応答ができており、数ms程度の違いはあれど遠距離ロケーションのときのような差はない。これは物理的な距離がパフォーマンスへ与える影響が非常に大きいことを示している。
国内サービス提供のみを考えるのであれば、Hyperdriveの導入のメリットは少なく見えるが、#1(コネクション確立時)のオーバヘッドにおいて、Hyperdrive使用時は30〜40ms程度の短縮が確認されるので、完全に効果がないわけではなさそう。
実際のユースケースでは、Workerの数が増加する可能性があり、それに伴いコネクションが上限に達する危険性がある。
この問題に対して、Hyperdriveをコネクションプーリングのツールとして活用することは有効な手段と考えられる。特に、無料で使用できる点も魅力的だ。
ただし、最近のDBサービスはサーバレスコンピューティングを前提に、独自のコネクションプーリング機構を提供していることも多いため、選択する前にそれらとバッティングしないかは考慮する必要がある。