データ基盤を構築してデータの可視化や分析を行う




はじめに
初めまして。
アイディオットDX開発部インフラ担当の小野です。
今回はデータ基盤構築をしました。
S3においたExcelファイルの中身を分析したり任意のグラフとして可視化できるようにしています。
💡point
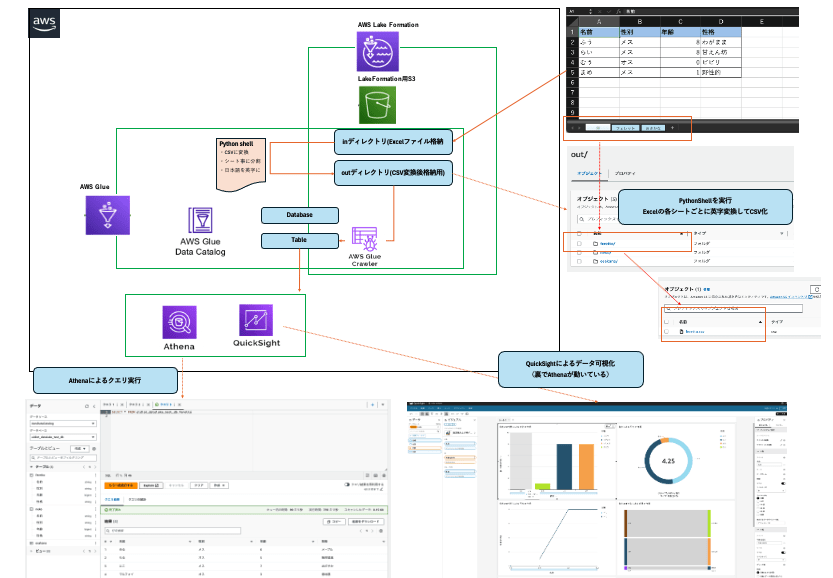
- データレイク: S3(
inディレクトリにデータを入れ、PythonShellによって加工されたものがoutディレクトリに格納される) - PythonShell:
inディレクトリ内のExcelファイルを各シートごとに分割しCSV変換(日本語は英字変換)し
outディレクトリに格納する処理を行う
※CSVファイルでないとcrawlerが読み込めず、日本語はアンダーバー表記になってしまうため - Crawler: データレイクからデータをDataCatalogのDB内のテーブルに格納する処理を行う
- QuickSight: テーブルからデータを読み取り、任意のグラフでデータの可視化が可能
- Athena: データベース・テーブルに対してクエリを実行できる
▼設定が少々複雑なのでまずは図を用意してみました。
前提
- Excelシートの1行目がテーブル格納時の"カラム"になります。空だとemptyとなりますのでご注意ください
- 長くなるので、実行ユーザ作成、Athenaの利用手順などは省略します。以下など参考にしてください
- 分析にはAthena,QuickSightを使用しますので費用など気をつけてください。
手順
データレイク用S3を作成
Excelファイルを入れるバケット。
配下に以下のディレクトリを作成する
- in/
- Excelファイルを入れる場所
- out/
- PythonShellの実行後、シートごとにCSV化されたファイルが格納される場所

アクセス制御用のタグ作成(LF-TAG)
LF-TAGをIAMユーザやロール、Databaseなどに紐づけることで制御する
- LakeFormation > LF-Tags
- 以下を追加
- DatabaseをCrawlingするためのLF-Tag
Tag Key: maintenance Tag Values: cralwer,manual - ユーザ制御のためにTableに付与するLF-Tag
Tag Key: source Tag Values: product
- DatabaseをCrawlingするためのLF-Tag
テーブル作成をGlueのCrawler経由で行うため、Crawlerで利用するRoleを作成
-
以下のIAMロールを作成。
AWSGlueServiceRoleDefaultDataLakeDataAccess
※このロールにLF-TAGを紐づけることにより、このロールがアタッチされているサービスが
Crawlerを利用できる権限を持つ -
ポリシーは以下をアタッチ
-
マネージド:
AWSGlueServiceRole AmazonS3ReadOnlyAccess -
カスタマーポリシーその1:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "lakeformation:GetResourceLFTags", "lakeformation:GetDataAccess", "lakeformation:ListLFTags", "lakeformation:GetLFTag" ], "Resource": "*" } ] } -
カスタマーポリシーその2:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "iam:PassRole", "Resource": "*" } ] }
-
Data Locationの設定
データレイクとなる対象のS3バケットを指定する。
- AWSコンソール > LakeFormation > Administration > Data lake locations
- Register location を押下
- 以下のように設定
- S3: 上記で作成したS3バケットを指定
- IAM role: 初回は自動で
AWSServiceRoleForLakeFormationDataAccessが作成される - Permission mode:
LakeFormationにチェック - Register locationを押下
- S3がDataLake Locationに登録される

Data Locationのアクセス権限追加
Dat Locationに設定したS3パス配下のファイルを、データベースのテーブルに追加するためのCrawlerのロールに権限を付与する
- LakeFormation > Data locations
- 「Grant」を押下
- 以下のように設定
-
MyAccountにチェック - IAM User: 上記で作成したIAMロールを指定
- Storage locations: 上記で作成したS3バケットを指定
- Registered account location: AWSアカウントID
- Grantableにチェック
- 「Grant」を押下
-

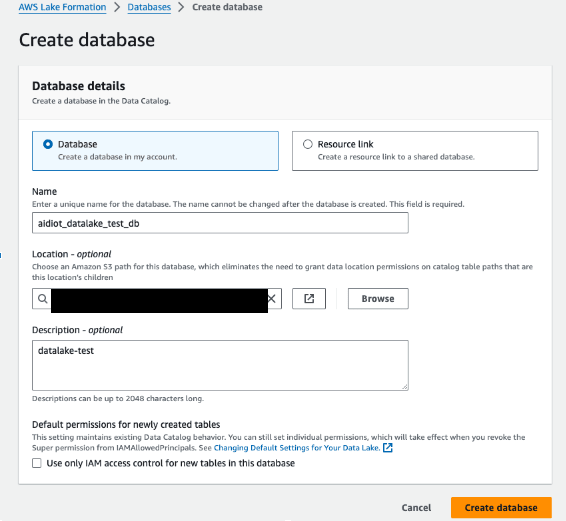
DataCatalogにDatabaseを追加
- LakeFormation > DataCatalog > Databases
- 「Add database」を押下
- 以下のように設定
-
Databaseにチェック - Name: 任意のデータベース名を入力
- Location: 上記作成のデータレイク用S3を指定
- 他はそのまま「Create database」を押下
-
- 作成したDatabaseを選択 > Edit LF-Tags
- 上記で作成したLF-TAGを付与する
Tag Key: maintenance Tag Values: cralwer,manual
Glue Crawler作成
- AWSコンソール > AWS Glue > Data Catalog > Crawlers
- Create crawlerを押下
- 以下のように設定
- Name: 任意のCrawler名
- 「Next」を押下
- S3パス: 上記で作成したデータレイク用S3
- 「Add an S3 data source」を押下
-
Not Yetにチェック - Role:
AWSGlueServiceRoleDefaultDataLakeDataAccess
※LF-TAGをこのロールに設定したのでCrawlerはデータベースに対する操作が可能 - 以下のようになっていたら「create crawler」を押下する

Glueスクリプト格納バケットにPythonの依存関係の外部ライブラリアップロード
テーブルが作成される際に、日本語だとアンダーバー表記となってしまいます。
そのため、PythonShellでpykakasiを使用してExcelファイル名やシート名の英字変換を行います。
PythonShellには標準搭載されていないので、パッケージをS3にアップロードします。
- pykakasiインストール(ローカル実行)
pip3 download pykakasi --only-binary=:all: - S3へアップロード(ローカル実行)
aws s3 cp {ファイルパス}/pyarrow-5.0.0-cp36-cp36m-manylinux2010_x86_64.whl s3://aws-glue-scripts-{your_aws_account_id}-ap-northeast-1/libs/
PythonShellジョブが使用するIAMロールの作成
- 以下の通り作成
- ロール名: pythonshell-etl-change-csv-role(任意)
- ポリシー:
- マネージド: AWSGlueServiceRole
- カスタマー管理: 以下のように設定
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::{データレイク用バケット名}/*"
}
]
}
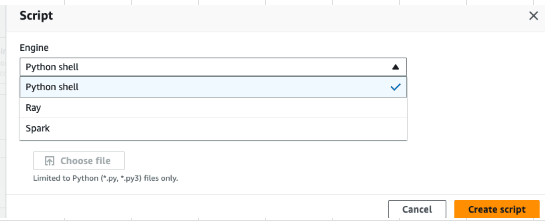
Glue ジョブ(Python Shell)の作成
- AWS Glue > Visual ETL > Script editor
- プルダウンよりPython Shellを選択
- 「Create Script」を押下
Job detailsの設定
- [Job details]タブを開く
- 以下のように設定
- Name: 任意
- IAM Role: 上記で作成した
pythonshell-etl-change-csv-roleを選択 - Type: Python Shell
- version: Python3.9(2024年4月現在)

- Libraries: 先ほどアップロードしたpyrowパッケージのS3フルパスを指定

Scriptの記述
以下の処理を実現させるコードです
- データレイク用S3の
inディレクトリに入れられたExcelファイル名及びシート名を英字に変換 -
outディレクトリに各シートごとに分割してCSVに変換し格納する - Crawlerの設定を変更し、Crawlerが実行される場所のパスを指定する(outディレクトリに作成されたCSVファイルが置かれたディレクトリのパスを自動で設定に登録)
※Crawlerで指定するパスは、CSVファイルが置かれたディレクトリを直接指定する必要がある。
そのため、このPyrhonShellを実行すると、outディレクトリ配下に以下のようにCSVが吐かれるようにコーディングしている
例)`in`ディレクトリ配下にあるExcelファイルのnekoというシートの場合
S3バケット/out/neko(ディレクトリ)/neko.csv
- 以下のコードを[Script]に記載する
※バケット名とcrawler名は適宜環境に合わせて変更ください
import boto3
import pandas as pd
import io
import pykakasi
import re
# ソースバケットの設定(ターゲットも同じバケット)
bucket_name = '{データレイクのバケット名}'
# クローラー名を変数として設定
crawler_name = '{作成したcrawler名}'
# S3 クライアントの初期化
s3 = boto3.client('s3')
# pykakasiの初期化
kakasi = pykakasi.kakasi()
kakasi.setMode('H', 'a') # ひらがなをアルファベットに
kakasi.setMode('K', 'a') # カタカナをアルファベットに
kakasi.setMode('J', 'a') # 漢字をアルファベットに
conv = kakasi.getConverter()
# S3バケット内の 'in/' ディレクトリからExcelファイルを取得する関数
def get_excel_files(bucket):
files = []
response = s3.list_objects_v2(Bucket=bucket, Prefix='in/')
for item in response.get('Contents', []):
if item['Key'].endswith('.xlsx'):
files.append(item['Key'])
return files
# クローラーの設定を更新する関数
def update_crawler_with_new_path(crawler_name, new_path):
glue_client = boto3.client('glue')
crawler_info = glue_client.get_crawler(Name=crawler_name)
current_targets = crawler_info['Crawler']['Targets']
if not any(target['Path'] == new_path for target in current_targets['S3Targets']):
current_targets['S3Targets'].append({'Path': new_path})
glue_client.update_crawler(Name=crawler_name, Targets=current_targets)
print(f"Updated crawler '{crawler_name}' with new path: {new_path}")
# Excelファイルの各シートをCSVに変換してS3バケット内の 'out/' ディレクトリに保存する関数
def convert_and_upload(file_key):
obj = s3.get_object(Bucket=bucket_name, Key=file_key)
excel_data = io.BytesIO(obj['Body'].read())
xls = pd.ExcelFile(excel_data)
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name)
base_filename = file_key.split('/')[-1].replace('.xlsx', '').lower()
converted_sheetname = conv.do(sheet_name).replace(' ', '_').lower()
converted_sheetname = re.sub(r'[ ()()]', '_', converted_sheetname)
converted_sheetname = re.sub(r'_{2,}', '_', converted_sheetname)
converted_sheetname = re.sub(r'_$', '', converted_sheetname)
converted_sheetname = converted_sheetname.lower()
out_key = f'out/{converted_sheetname}/{converted_sheetname}.csv'
buffer = io.StringIO()
df.to_csv(buffer, index=False)
buffer.seek(0)
s3.put_object(Bucket=bucket_name, Key=out_key, Body=buffer.getvalue())
print(f'created {out_key}')
# クローラーを更新
new_s3_path = f's3://{bucket_name}/out/{converted_sheetname}/'
update_crawler_with_new_path(crawler_name, new_s3_path)
# メイン関数
def main():
files = get_excel_files(bucket_name)
for file_key in files:
convert_and_upload(file_key)
# スクリプトの実行エントリーポイント
if __name__ == "__main__":
main()
- 「Save」を押下
- ジョブが作成されていることを確認する

実行
下準備がほぼ終わりました。実際に動かしていきましょう。
S3のin/ディレクトリに以下のExcelファイルを格納(DEMO)

今回は猫シートをベースに話を進めていきます。
(フェレット、おさかなシートにも同じようにデータが入っています。漢字・カタカナ
ひらがなに対応してます)
PythonShellの実行
inディレクトリ内のExcelファイルを各シートごとに分割しCSV変換(日本語は英字変換)し
outディレクトリに格納する処理でしたね。
- 作成したPythonShell > 右上の「Run」を押下
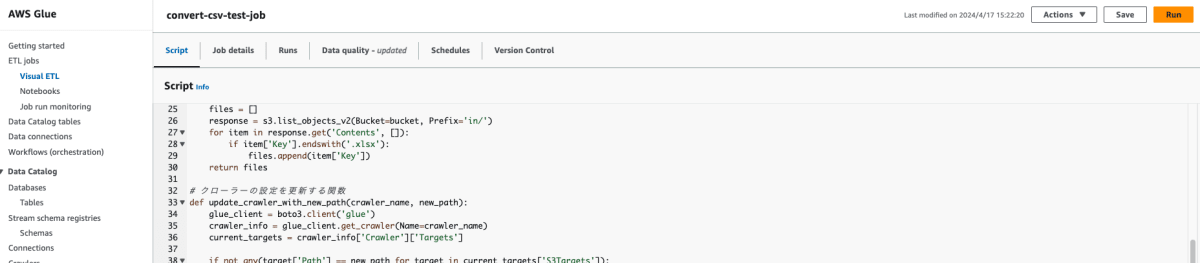
- 実行結果は[Runs]タブで見れる(エラーがあれば調査する)
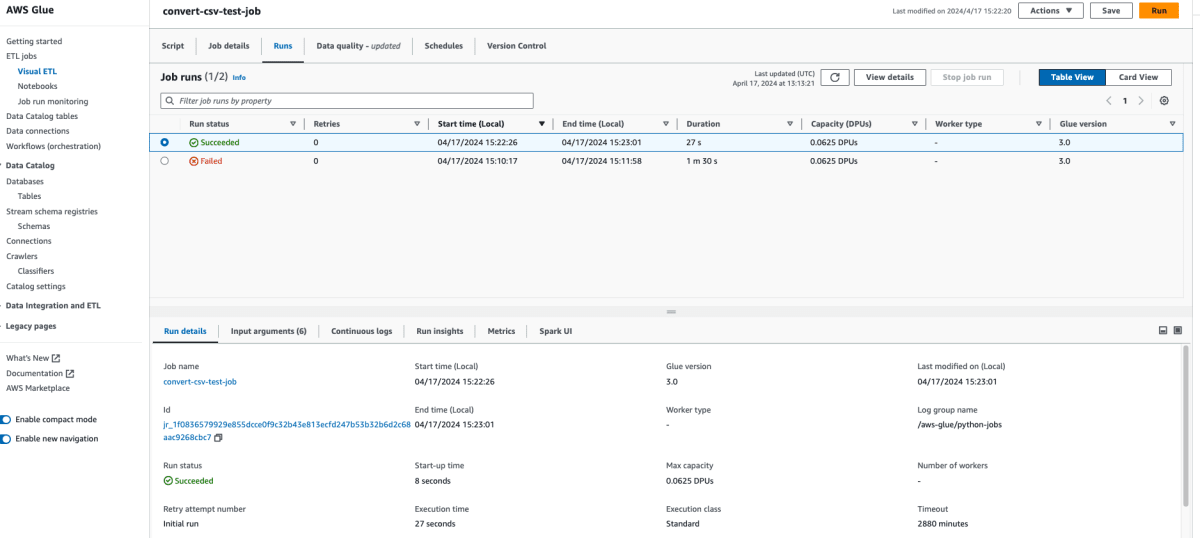
- S3の
outディレクトリを確認
outディレクトリ配下のシート名ディレクトリ直下にシート名でCSVファイルが配置されている

- Glue > crawler > EditよりChose data source and classifiersを見に行くと、上記のCSVのパスがそれぞれ追加されている
※最初に作成したときのバケット直下パス指定が残っていた場合は削除してください。
以下の画像のようにシート名のディレクトリを直接指定しているパスだけになっていること。

crawlerの実行
データレイク(今回はS3のoutディレクトリ配下のSCVファイル)からデータを
DataCatalogのデータベース内のテーブルに格納する機能でしたね
- Glue > crawler > 作成したcrawler
- 「Run crawler」を押下
- CompletedになればOK

- LakeFormation > Tables
- DB名で絞る
- シート名ごとの名前でtableに格納されていることがわかる

QuickSightでデータ可視化
- AWSコンソール > QuickSight
- データセット
- 「Athena」を選択
- データソース名: 任意
- 「データソースを作成」を押下
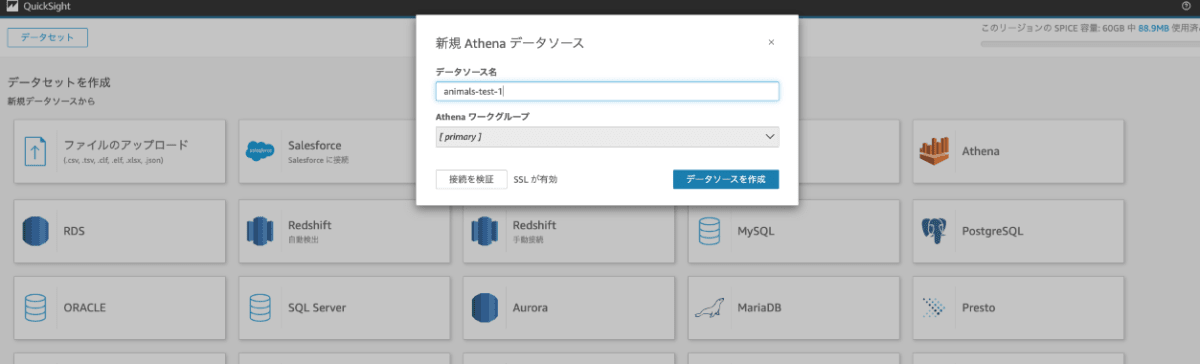
- プルダウンよりデータベースを選択
- データ分析したいテーブル名(シート名)を選択
- 「選択」を押下
-
迅速な分析のためにSPICEへインポートにチェックを入れる - 「Visualize」を押下

- 可視化したいグラフを選択する
- 左側のデータセットがExcelシートの1行目の項目(テーブルのカラムになっている)

X軸やY軸など、好きなようにカラムをセットする。
グラフ化が出来ていることがわかる

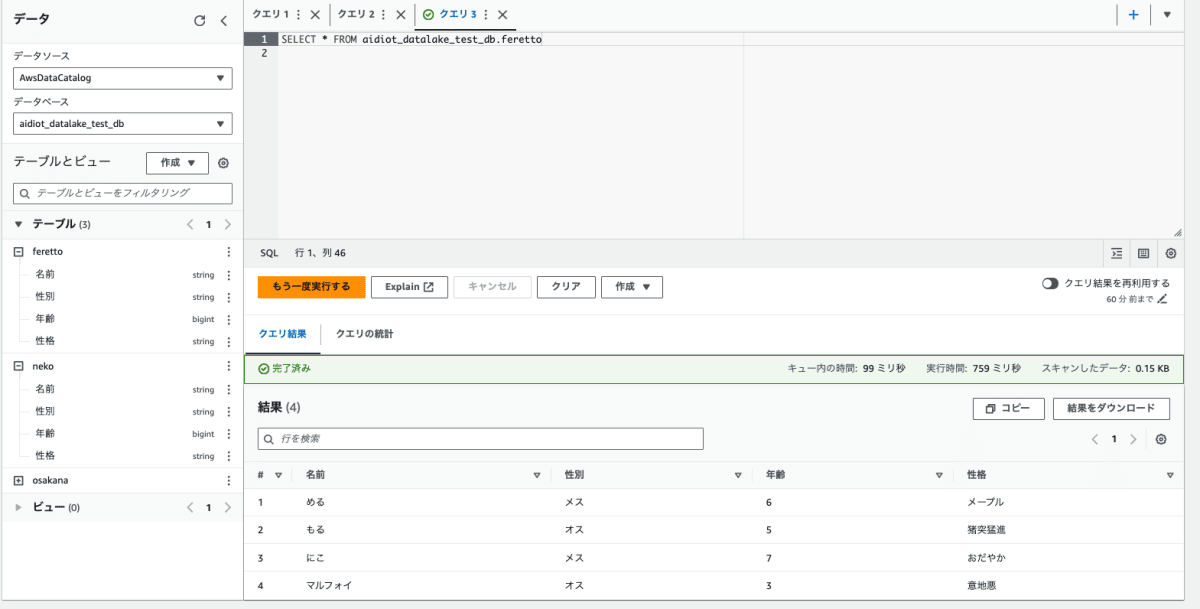
Athena
Athenaを使用してクエリを実行することによる分析やつなぎ込みなどもできる(詳細は今回は略)
最後に
今回はじめてデータ基盤の構築をしてみて思ったのが、ロールだけの権限管理でなく、
LF-TAGやGrantPermissionを使用して細かく制御しなければならずエラーが出てハマることが多かった印象です。
あとPythonShellを使うとGlueで管理できるのでLambdaを使わずともよいのがいいですね。
苦戦はしましたが、良い機会になったのでこれからも精進していきます。
もっとこうしたほうがいいよ!などアドバイスありましたら嬉しいです。
あとがき
AI・データ利活用をリードし、世界にインパクトを与えるプロダクトを開発しませんか?
アイディオットでは、今後の事業拡大及びプロダクト開発を担っていただけるエンジニアチームの強化を行っております。
さらに会社の成長を加速させるため、フロントエンドエンジニア、バックエンドエンジニア、インフラエンジニアのメンバーを募集しております!
日本を代表する企業様へ自社プロダクトを活用した、新規事業コンサルティング、開発にご興味のある方はお気軽にご連絡ください。
【リクルートページ】
https://aidiot.jp/recruit/
【募集ポジション一覧】
https://open.talentio.com/r/1/c/aidiot/homes/3925
【採用についてのお問合せ先】
株式会社アイディオット 採用担当:佐藤
メールアドレス:recruit@aidiot.jp
Discussion