🐧
CloudWatchLogsのログを日次でS3に転送(差分)
はじめに
初めまして。
アイディオットDX開発部インフラ担当の小野です。
特定のCloudWatchLogsから日次で差分のみをS3に転送する処理を実装しましたので共有します。
誰かのお役にたてると幸いです。
💡point
- 1つのCloudWatch Logsのログから日次で差分をS3に転送
- 複数のCloudWatch Logsから1つのバケットへも転送可能(例: accesslogとerrorlogのLogグループから日次で特定のバケットへ転送など)
- 以下のサービスを使用する
- CloudWatch Logs/S3/EventBrige/Lambda

前提
- CloudWatch Logsに必要なログを抽出する設定が済んでいること
- 保存用のS3バケットが作成してあること
手順
Lambda用のIAMロール作成
- CloudWatch LogsとS3へのポリシーを設定したIAMロールを作成する
バケットポリシーの設定
- 以下のとおり設定
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logs.ap-northeast-1.amazonaws.com"
},
"Action": [
"s3:GetBucketAcl",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::{S3バケット}",
"arn:aws:s3:::{S3バケット}/*"
],
"Condition": {
"StringEquals": {
"aws:SourceAccount": "{12桁のAWSアカウントナンバー}"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:logs:*:{12桁のAWSアカウントナンバー}:log-group:*"
}
}
}
]
}
Lambda関数の作成
- ランタイム:Python
- ロール:上記で作成したロール
- メモリ: 256(適宜変更してください)
- タイムアウト: 15分(適宜変更してください)
- コードは以下
import boto3
import datetime
import time
def LogsExport(bucket_name, log_groups):
# 実行日取得
to_time = datetime.datetime.now()
# 1日前取得
from_time = datetime.datetime.now() - datetime.timedelta(days=1)
# エポック時刻取得(float型)
epoc_from_time = from_time.timestamp()
epoc_to_time = to_time.timestamp()
# エポック時刻をミリ秒にしint型にキャスト
m_epoc_from_time = int(epoc_from_time * 1000)
m_epoc_epoc_to_time = int(epoc_to_time * 1000)
client = boto3.client('logs')
# ロググループに保存されているログをS3にエクスポート
for item in log_groups:
client.create_export_task(
logGroupName=item,
fromTime=m_epoc_from_time,
to=m_epoc_epoc_to_time,
destination=bucket_name,
destinationPrefix=item
)
# ログエクスポートが実行中か確認し、実行中の場合処理を5秒停止
time.sleep(5)
export_tasks = client.describe_export_tasks(statusCode='RUNNING')
while len(export_tasks['exportTasks']) >= 1:
export_tasks = client.describe_export_tasks(statusCode='RUNNING')
time.sleep(5)
def lambda_handler(event, context):
# 各S3バケットに対してエクスポートするロググループのマップ
buckets_to_logs = {
# 一つのバケットに複数のログ(例えばaccesslogとerrorlogなど)を抽出したい場合は以下のように配列で書く。
# 複数バケットを設定も可能
"{S3バケットA}": ["{CloudWatchのロググループA}", "{CloudWatchのロググループB}"],
"{S3バケットB}": ["{CloudWatchのロググループC}", "{CloudWatchのロググループD}"]
}
for bucket, logs in buckets_to_logs.items():
LogsExport(bucket, logs)
EventBrigeの設定
以下のように設定
- 名前・説明: 任意
- イベントパス: default
- ルールタイプ: スケジュール
- 「続行してルールを作成する」を押下

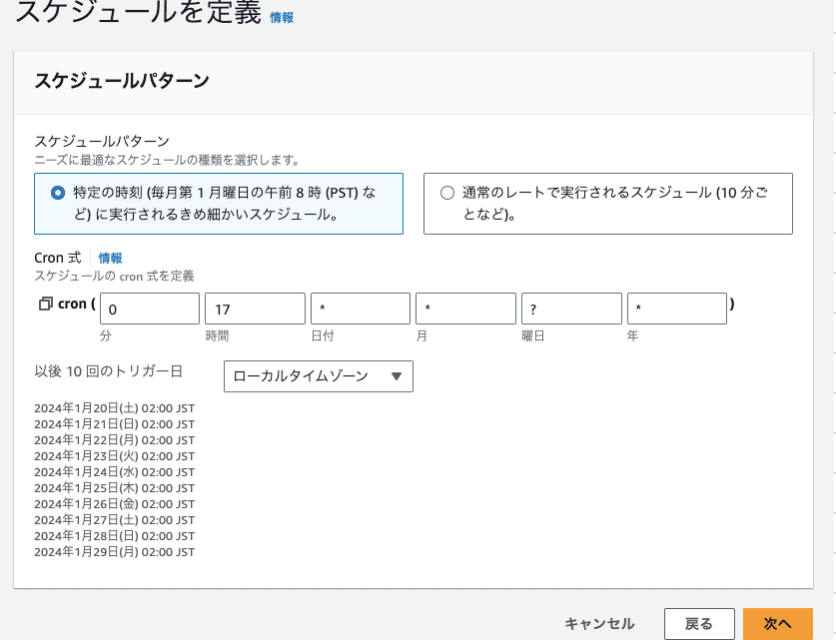
- スケジュールパターン: 特定の時刻
- Cronで任意の時間(日次)を設定
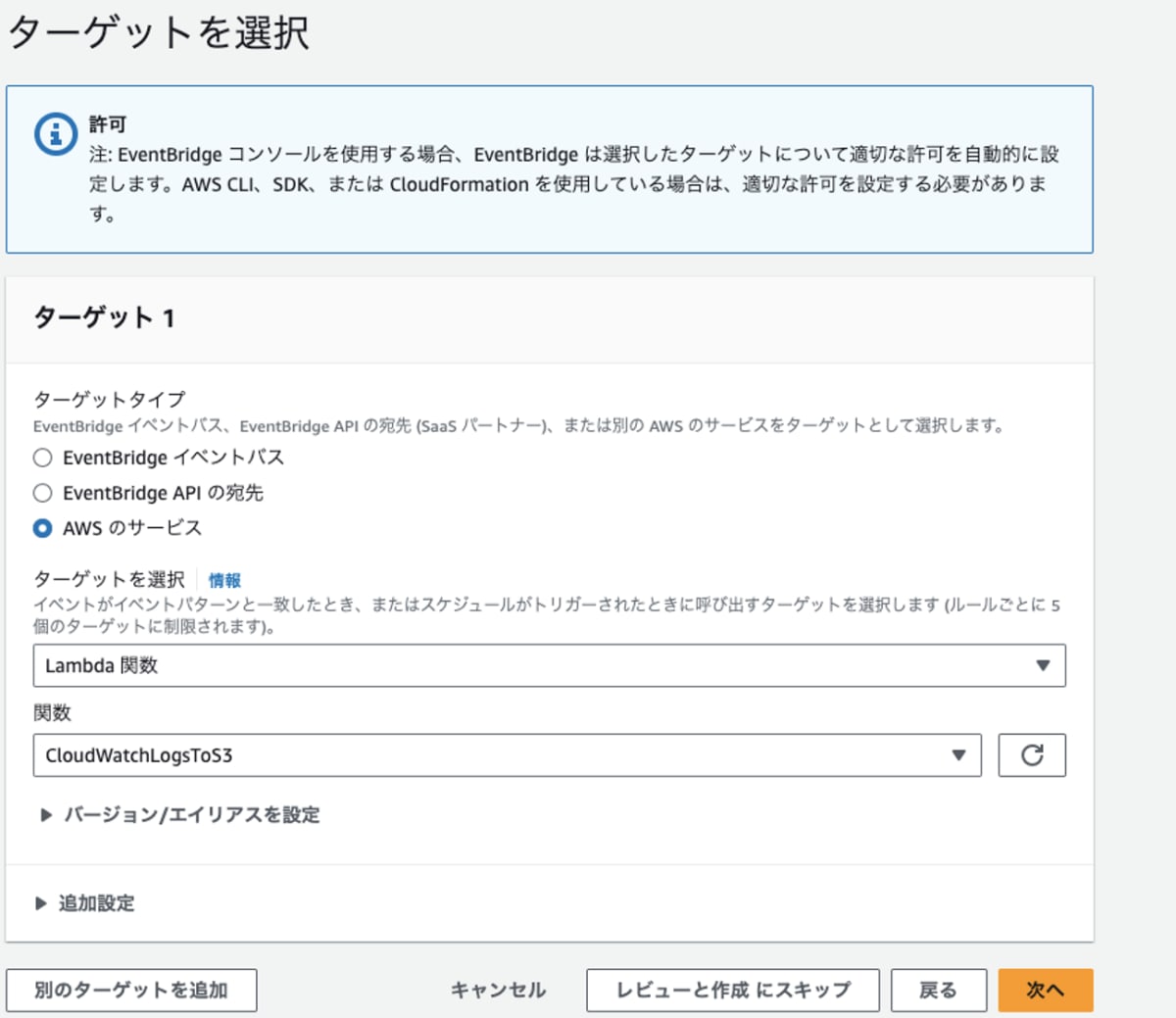
- ターゲットタイプ: AWSのサービス
- ターゲットを選択: プルダウンより[Lambda関数]を選択
- 関数: 上記で作成したものを選択
- 任意のタグを設定し、「ルールの作成」を押下
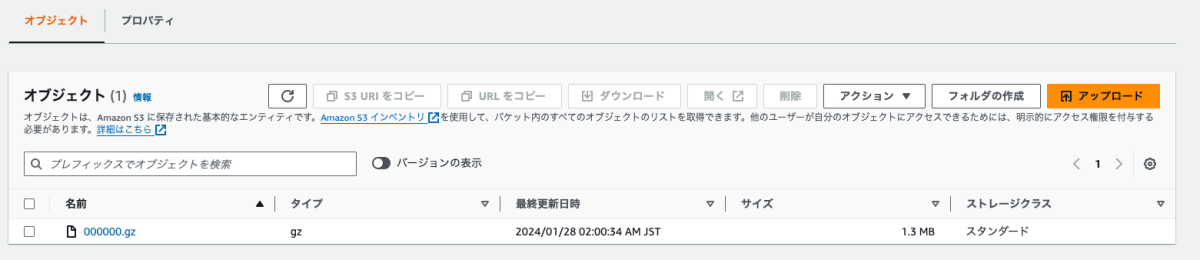
日次でログが取得できているか確認する

最後に
1つのCloudWatch Logs全体から毎日バックアップしているとS3の容量や転送量が大変なことになりかねないですからね。よければ参考にしてみてください。
また、S3やCloudWatch Logsでライフサイクルルールを設定することにより一定期間以上立ったログは消すように設定することをおすすめします。
もっと良いやり方などあればぜひ教えて下さい!
あとがき
AI・データ利活用をリードし、世界にインパクトを与えるプロダクトを開発しませんか?
アイディオットでは、今後の事業拡大及びプロダクト開発を担っていただけるエンジニアチームの強化を行っております。
さらに会社の成長を加速させるため、フロントエンドエンジニア、バックエンドエンジニア、インフラエンジニアのメンバーを募集しております!
日本を代表する企業様へ自社プロダクトを活用した、新規事業コンサルティング、開発にご興味のある方はお気軽にご連絡ください。
【リクルートページ】
https://aidiot.jp/recruit/
【募集ポジション一覧】
https://open.talentio.com/r/1/c/aidiot/homes/3925
【採用についてのお問合せ先】
株式会社アイディオット 採用担当:大島
メールアドレス:recruit@aidiot.jp
Discussion