はじめに
この記事では、Azure OpenAIを利用した、特定の文書に関するRAG(Retrieval-Augmented Generation)の構築について、特に各パラメータ・機能の役割や最適値に焦点を当てながら、解説していきたいと思います。
今回主に利用するサービスは以下の3つです。
- Azure OpenAI Service
- Azure AI Search
- Storage Account
想定している読者
- Azure OpenAI Serviceを触ったことのある方
- Azure OpenAI Serviceを使ってRAG構築をしてみたい方
- 社内規約を始めとしたpdf文書を元にカスタムチャットボットを作りたい方
- Azure上でRAGを組んでみたけど、パラメータの設定基準が曖昧な方
TL;DR
今回は公共事業についての質問に答えるようなチャットボットを作っていきます。
動いている様子はこちらです。

グラウンディングさせるデータには、CC BY 4.0ライセンスの北海道室蘭市公式HPから地域再生計画(航空機産業参入支援事業)と室蘭市公共施設等総合管理計画を採用しました。(HPはこちら)
冒頭でも少し触れましたが、今回の目的はRAGを利用したチャットボットを作ることではなく、
作成過程で設定するパラメータや機能の役割、及び最適値について解説することなので、くれぐれもご留意ください。
前提知識
Azure OpenAI
公開されているgptモデル
| モデル名 | 現時点でのオススメ | バージョン | 廃止予定日 | 出力性能 | マルチモーダル性能 |
|---|---|---|---|---|---|
| gpt-4o | ★ | ◯(高速・高精度) | ◯(画像・表の混合もok、英語以外の言語とビジョンタスクに優れる) | ||
| gpt-4-turbo-2024-04-09 | ★ | ◯(高精度) | △(一部機能がサポート外) | ||
| gpt-4 (0125-Preview) | preview | △(コード出力の性能が高い) | ×(gpt-4-turbo-2024-04-09の前身モデル) | ||
| gpt-4 (vision-preview) | preview | △(テキストと画像の出力が可能) | △(gpt-4-turbo-2024-04-09の前身モデル) | ||
| gpt-4 (1106-Preview) | preview | △(低速・中精度) | ×(gpt-4-turbo-2024-04-09の前身モデル) | ||
| gpt-4 と gpt-4-32k (0314ver.) | 2024/07/05 | △(低速・中精度) | × | ||
| gpt-4 と gpt-4-32k (0613ver.) | 2024/09/30 | △(低速・中精度) | × | ||
| gpt-3.5以下 | ×(低精度) | ×(自然言語orコードのみ対応) |
embeddingモデル[1]
embedding(埋め込み)モデルとは高次元のデータ(テキスト、画像、音声など)を低次元のベクトル空間に変換する機械学習モデルです。これにより、データの意味的な情報を保持しつつ、類似度計算が容易になり、分類や検索などの多様なタスクに適用可能です。
Azureが提供しているembeddingモデルには、text-embedding-ada-002、text-embedding-3-small、text-embedding-3-largeの3種類があります。
しかし、Microsoft公式によると、バグが見つかり、2024年6月18日現在、text-embedding-ada-002しか利用できないそうです。(Microsoft Q&Aより引用)
As you rightly pointed it out, text-embedding-ada-002 is only available.
Our Product Group team is aware of this Bug and they have a workitem created to fix this.
...
Azure AI Search
レプリカ × パーティション[2][3]
(レプリカ × パーティション = 検索ユニット)
- レプリカ(ユーザー側の視点)
- 多くのユーザーが同時に利用する際に処理速度を維持
- システム障害が発生しても、他のレプリカが動作するため、サービスの停止を防ぐことができる
- パーティション(ストレージ側の視点)
- 膨大なデータを効率的に扱うため、インデックスを分割し、検索性能を向上させる
- データ量の増加に応じてパーティションを追加し、システムの拡張を容易にする
以上を踏まえると…
- RAGを使用するユーザーが多い → レプリカの拡張
- RAGに取り込むデータ量が多い → パーティションの拡張
※実際はユースケースに応じて調整してください。
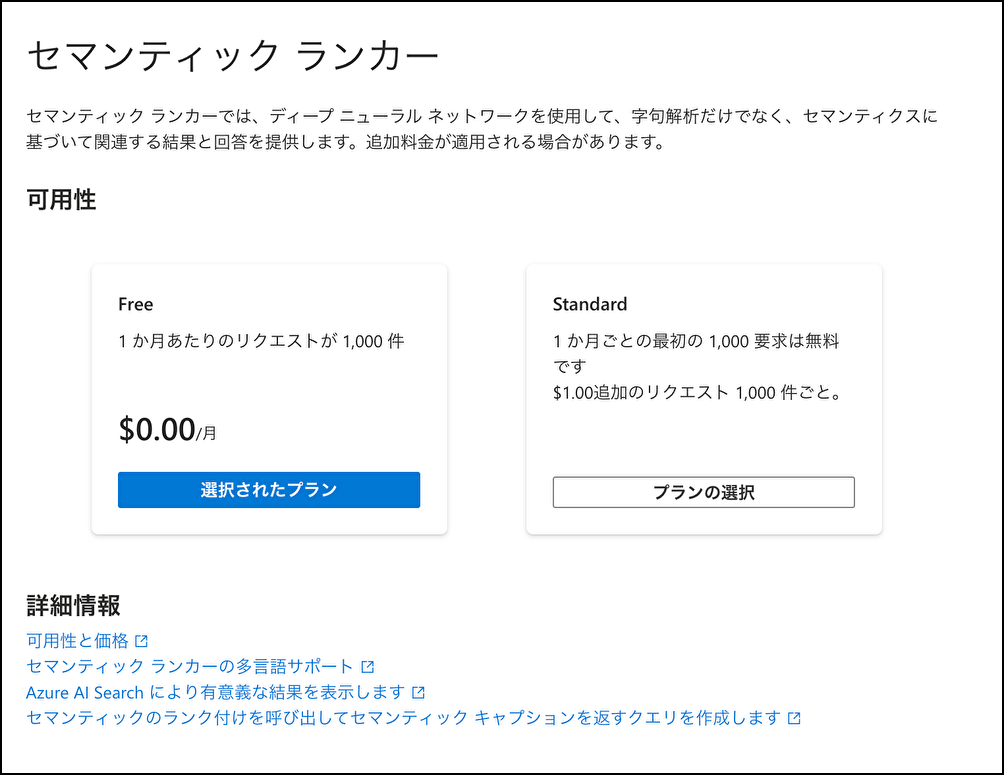
セマンティックランカー
セマンティックランカーとは(参考資料より引用)
検索結果から、より関連性の高い結果を抽出するためのAI Searchのプレミアム機能です。(昔はセマンティック検索と呼んでいたものがセマンティックランカーと名前を変えました)Microsoft Bing から派生したディープ ラーニングモデルを用いて、検索結果を関連性の高い順番に再ランキングします。
選択肢は以下の2つ
- Free(無料):リクエスト数が、1000件 / 月まで
- Standard:リクエスト数が、1000件 / 月 まで無料、その後1000件毎に$1.00課金
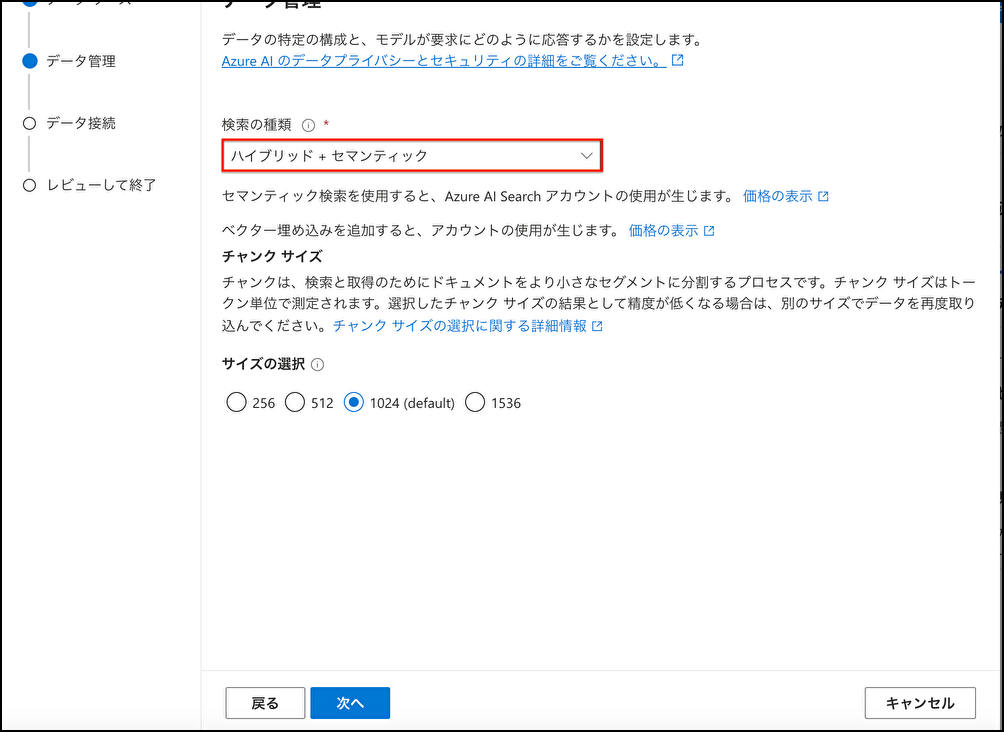
検索の種類
検索の種類は主に以下3つあります。
| 検索の種類 | 一問一答形式に対する性能 | 長文に対する性能 | 抽象的な質問に対する性能 | 値段 |
|---|---|---|---|---|
| ベクトル | ◯ | △ | △ | ◯ (追加料金なし) |
| ハイブリッド | ◯ | ◯ | △ | ◯ (追加料金なし) |
| ハイブリッド+セマンティック | ◯ | ◯ | ◯ | △ (Free: リクエスト数が、1000件/月まで。 Standard: 1000件/月まで無料、その後1000件毎に$1.00課金) |
詳しくは以下の記事を参照ください。各検索手法について丁寧に解説してくださっています。
Storage Account
階層型名前空間
フラット型名前空間 or 階層型名前空間が選べます。
一言で言うと、階層型の元ではストレージ内にディレクトリを作成しドキュメントを仕分けたり、ディレクトリ単位での削除が可能になります。反対にフラット型空間の下では一つのコンテナ内に並列にドキュメントを格納する形になります。
ドキュメントの数が多い場合や、年度やカテゴリ別で分けて格納したい場合は階層型名前空間の方が整理しやすいでしょう。
実際に作ってみよう
今回つくるものについて
それでは前述のサービスを使ってAzureで完結する形でRAGを組んでいきます。
定期的にドキュメントの更新があることを想定し、RAGで用いるインデックスは自動更新に対応できるようにします。[4]
- 題材:北海道室蘭市公式HPから室蘭市公共施設等総合管理計画と地域再生計画(航空機産業参入支援事業)
- 期待するinput:当該管理計画や支援事業に関する質問
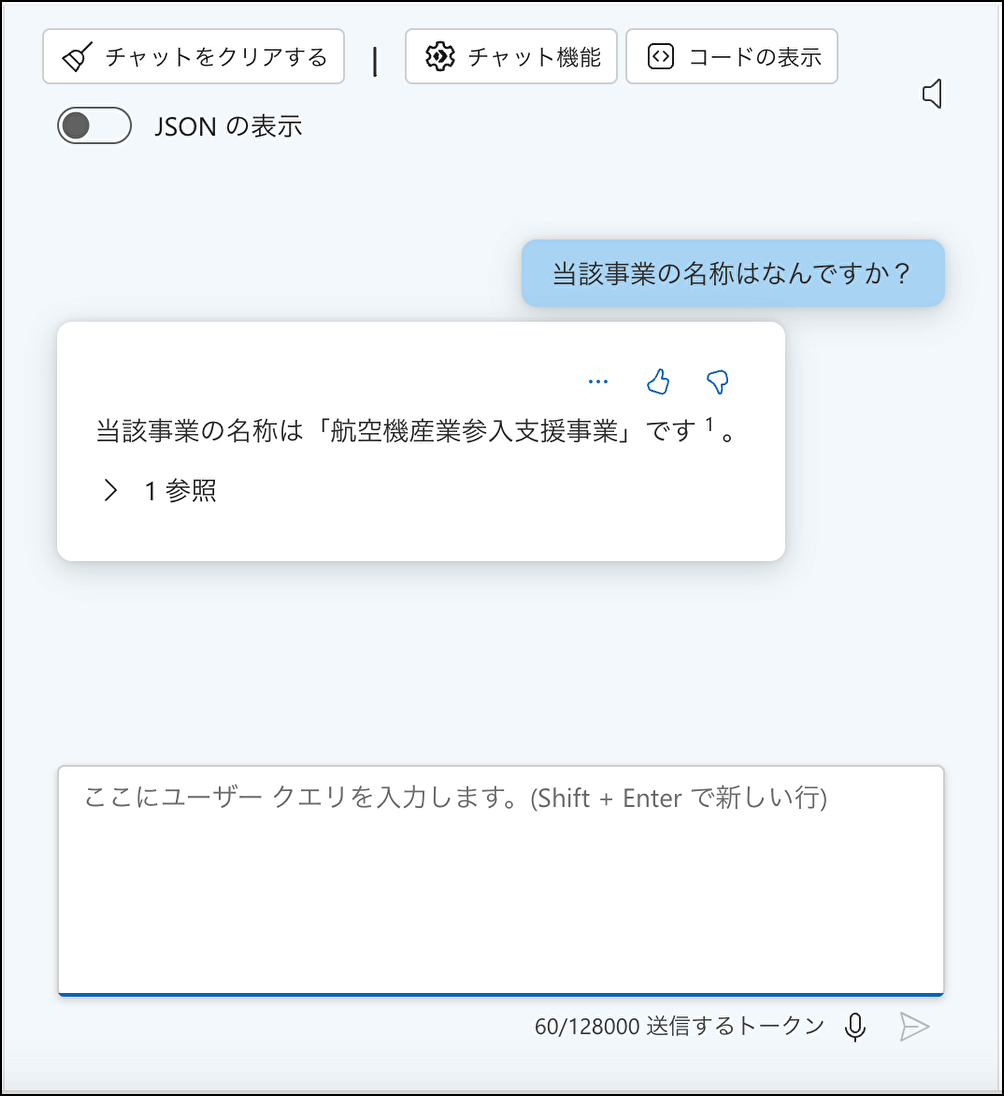
- 例:『当該事業の名称はなんですか?』
- 期待するoutput:当該文書内に記載のある範囲での適切な回答
- 例:『当該事業の名称は「航空機産業参入支援事業」です。』
考える順番
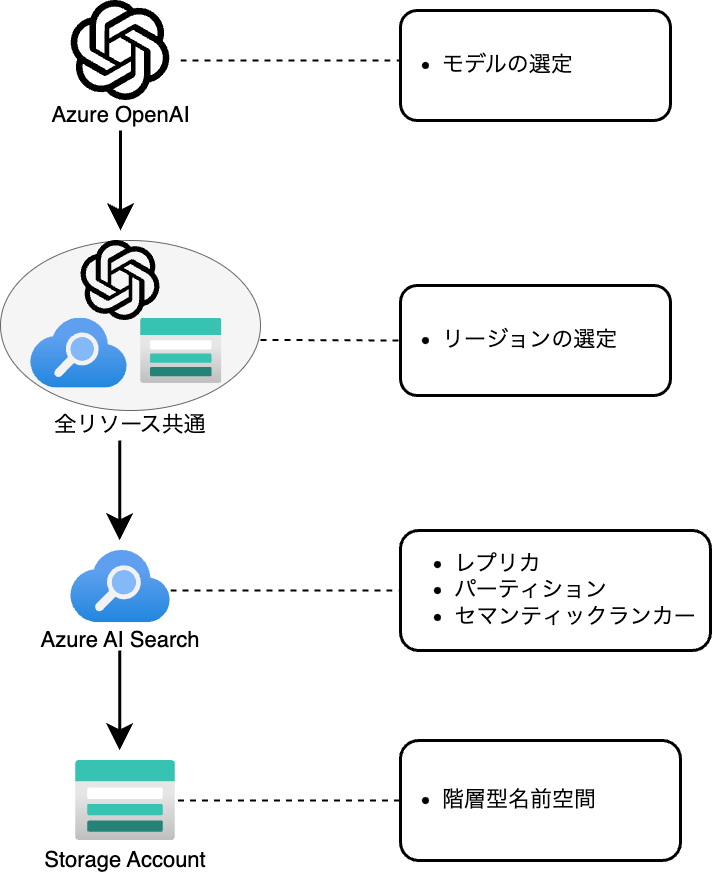
Azure OpenAI・リージョンの設定
- 前提条件
- データソース:BLOB Storage
- 価格レベル:Standard S0
- ベースのLLMにgpt-4o、Embeddingモデルにtext-embedding-ada-002を採用
- gpt-4oを使うために[5]、今回は他サービスも含め、リージョンはWestUSで統一[6]することとします(text-embedding-ada-002は全リージョンに対応しているので、リージョン選定には影響なし)
セットアップはこんな感じ
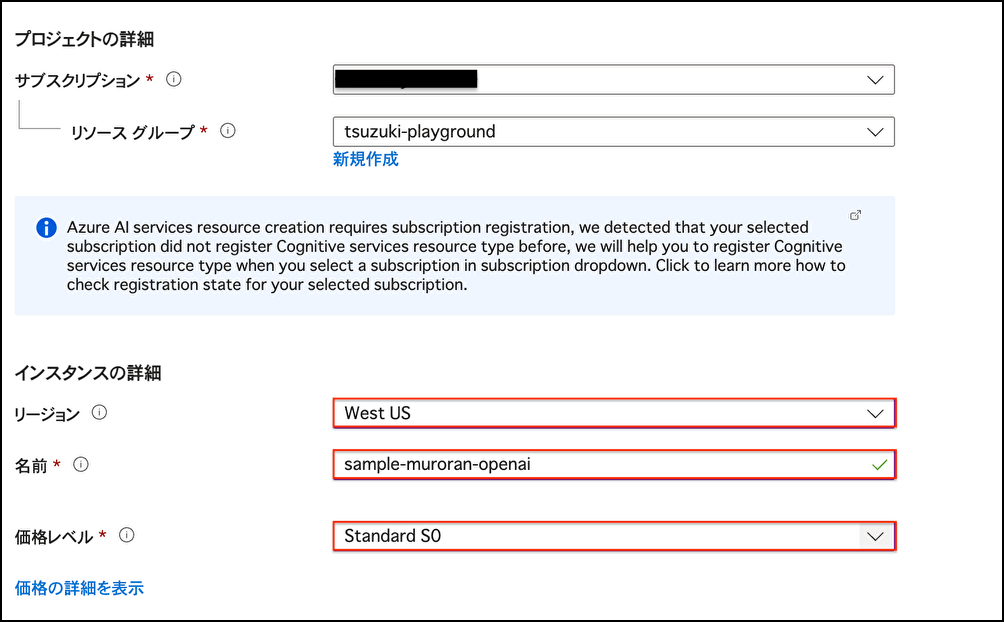
Marketplaceより[Azure OpenAI]を作成
リージョン、名前、価格レベルを設定し[作成]を押下
(名前は任意の文字列)
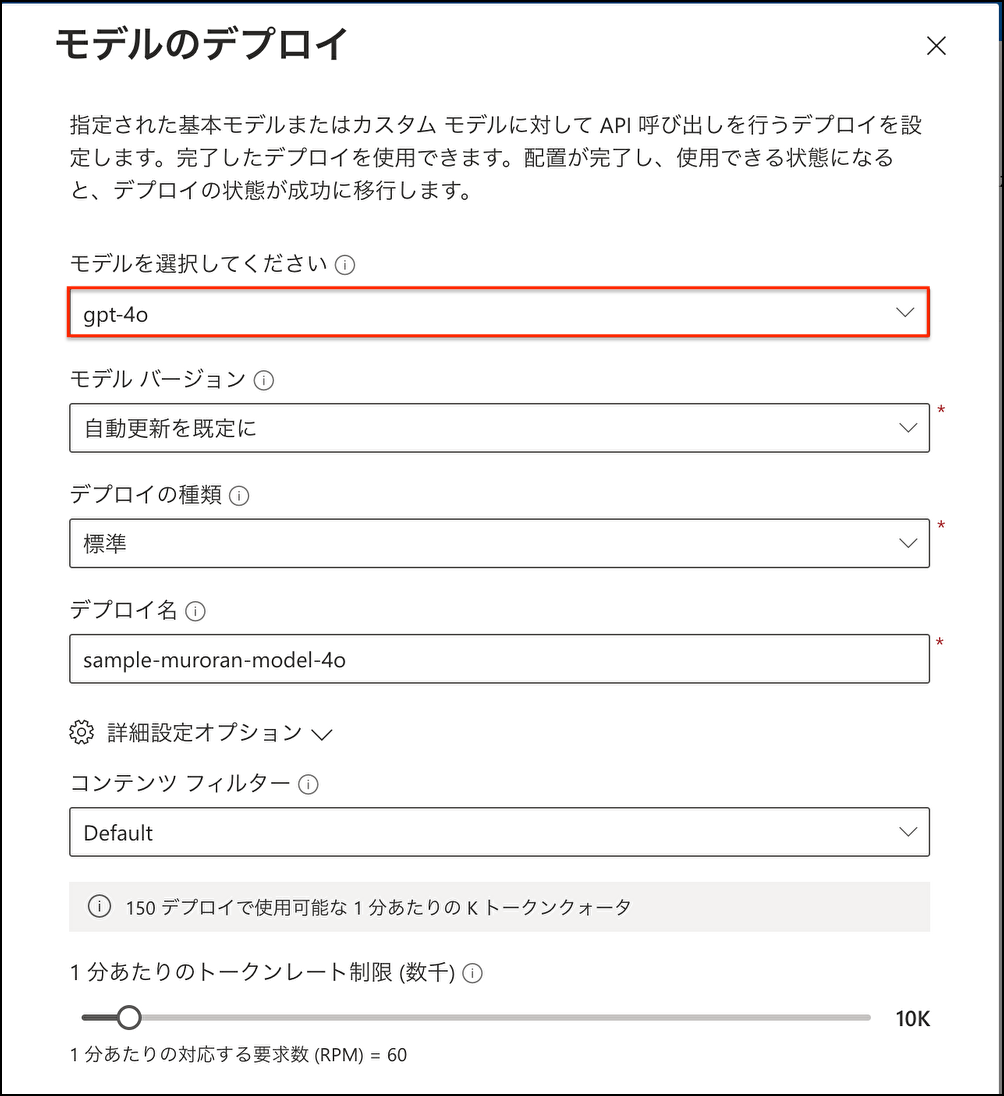
リソースグループにデプロイされたらAzure OpenAI Studioを開く
Azure OpenAI Studio左側の[デプロイ]タブを押下 → [新しいデプロイを作成] → gpt-4oを選択 → [作成]
※同様の方法でtext-embedding-ada-002も作成
Azure AI Searchの設定
- 前提条件
- 価格レベル:Standard
- レプリカ×パーティションに1 × 1、セマンティックランカーにFreeを採用
セットアップはこんな感じ
サービス名に任意の文字列、レプリカ×パーティションを1 × 1に設定しAzure AI Searchを作成

portalにデプロイされたAzure AI Searchを押下し、左タブ下部の[セマンティックランカー]を押下
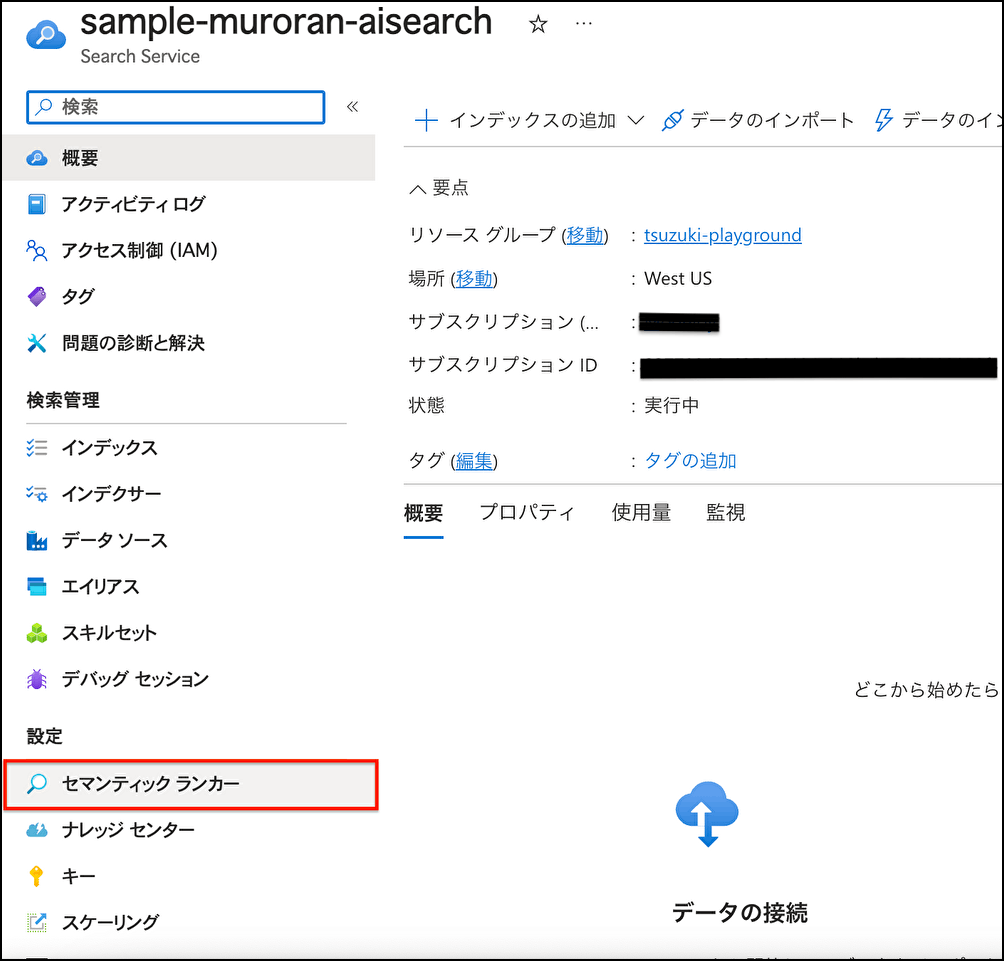
デフォルトで[Free]が選択さえれていることを確認
Storage Accountの設定
- 前提条件
- パフォーマンス:Standard
- 冗長性(レプリケーション):LRS
- 匿名アクセス:有効
- アクセス層:ホット
- 今回扱うドキュメントが2種類だけなので、フラット型名前空間を採用
セットアップはこんな感じ
Marketplaceより[Storage Account]選択
パフォーマンス、レプリケーション、階層型名前空間、アクセス層、BLOB匿名アクセスを以下のように設定し[作成]

デプロイできたら、portalよりStorage Accountを押下し左タブ[コンテナー] → 画面左側の[+コンテナー]と遷移し、任意の名前及び[匿名アクセスレベル]を[BLOB(BLOB専用の匿名読み取りアクセス)]に設定
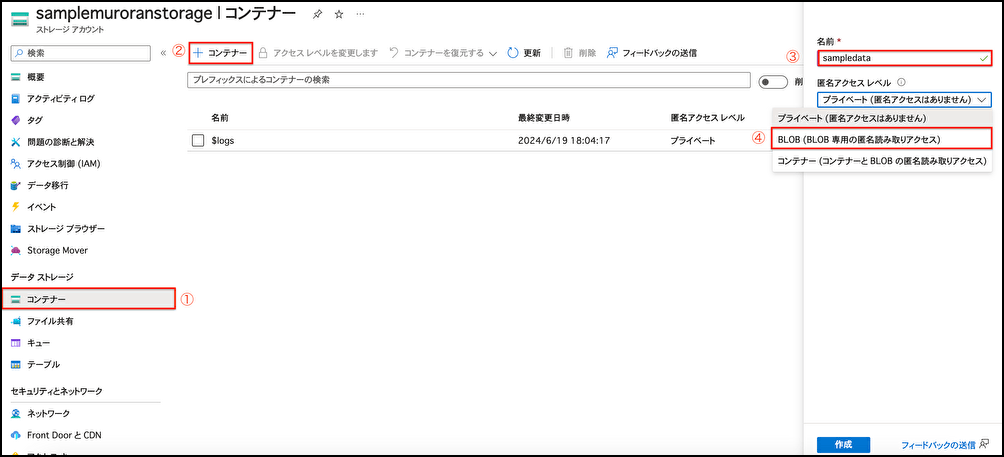
作成したコンテナーを選択し[アップロード]から[ファイルを参照] → 地域再生計画(航空機産業参入支援事業)を選択しアップロードする。
動作確認
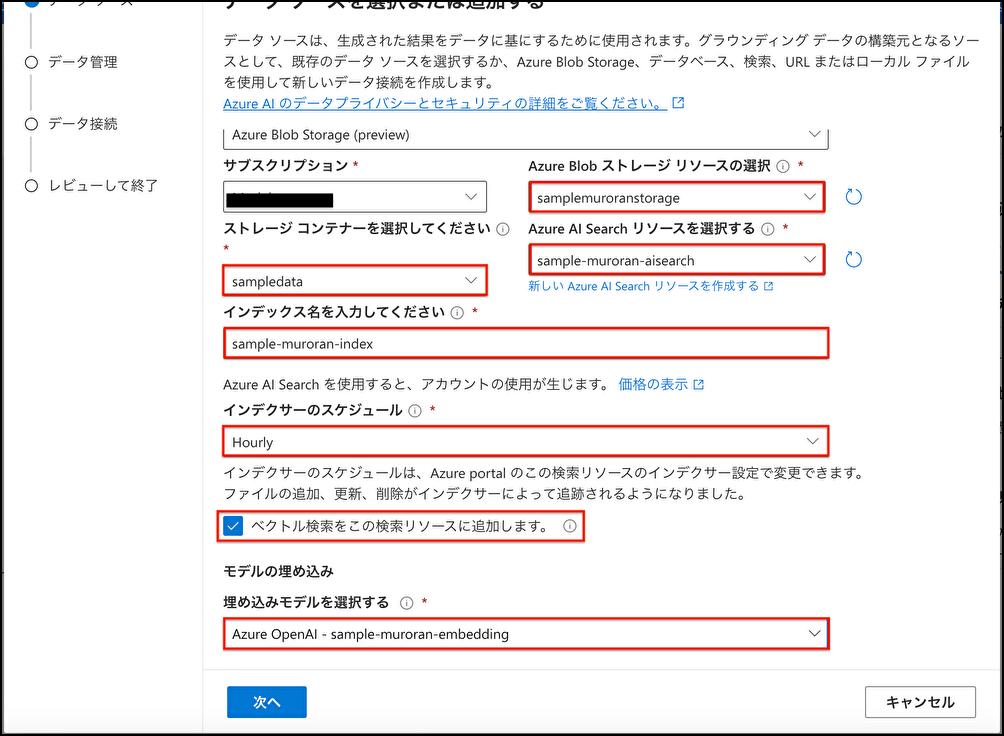
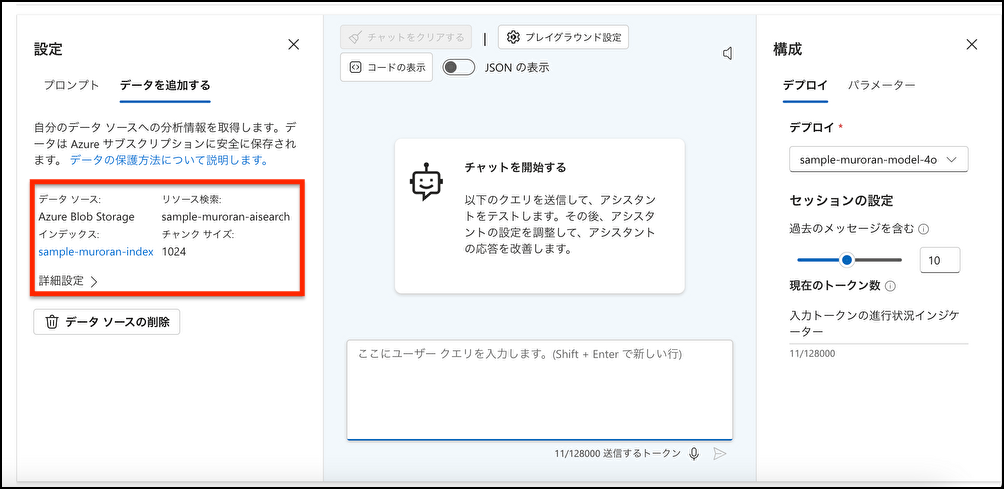
Azure OpenAI Studioから → [データの持ち込み] → [Azure BLOB Storage(preview)]を選択
以下の赤枠のように設定する
(インデックス名は任意の文字列、[ベクトル検索をこの検索リソースに追加します]に✅)
検索の種類は[ハイブリッド+セマンティック]
Azureリソース認証は[APIキー]を選択し[保存して閉じる]を押下
画面が以下のようになったら準備完了
質問にも適切に回答できている
応用:インデックスの自動更新
最後に、インデックスの自動更新の方法について解説いたします。
先ほどの地域再生計画に加え室蘭市公共施設等総合管理計画の文書を使っていきます。
インデックスの自動更新は、新たにストレージにアップロードされた文書に関するインデックスを自動で作成し、チャットボット上でも応対が可能になる機能です。[7]
最初に、室蘭市公共施設等総合管理計画だけに記載のある内容の質問を用意します。
室蘭市公共施設等総合管理計画5ページに以下のような記載があります。これは地域再生計画に記載されていないものになります。

ここから引用して、以下のような質問にします。
室蘭市が保有する公共建築物における市民一人当たりの延床面積はいくつですか
次に、インデックスの自動更新の設定をしていきます。
チャットプレイグラウンドを保持したまま、新たなウィンドウでportalを開きAzure AI Search → [インデクサー]に進みます。
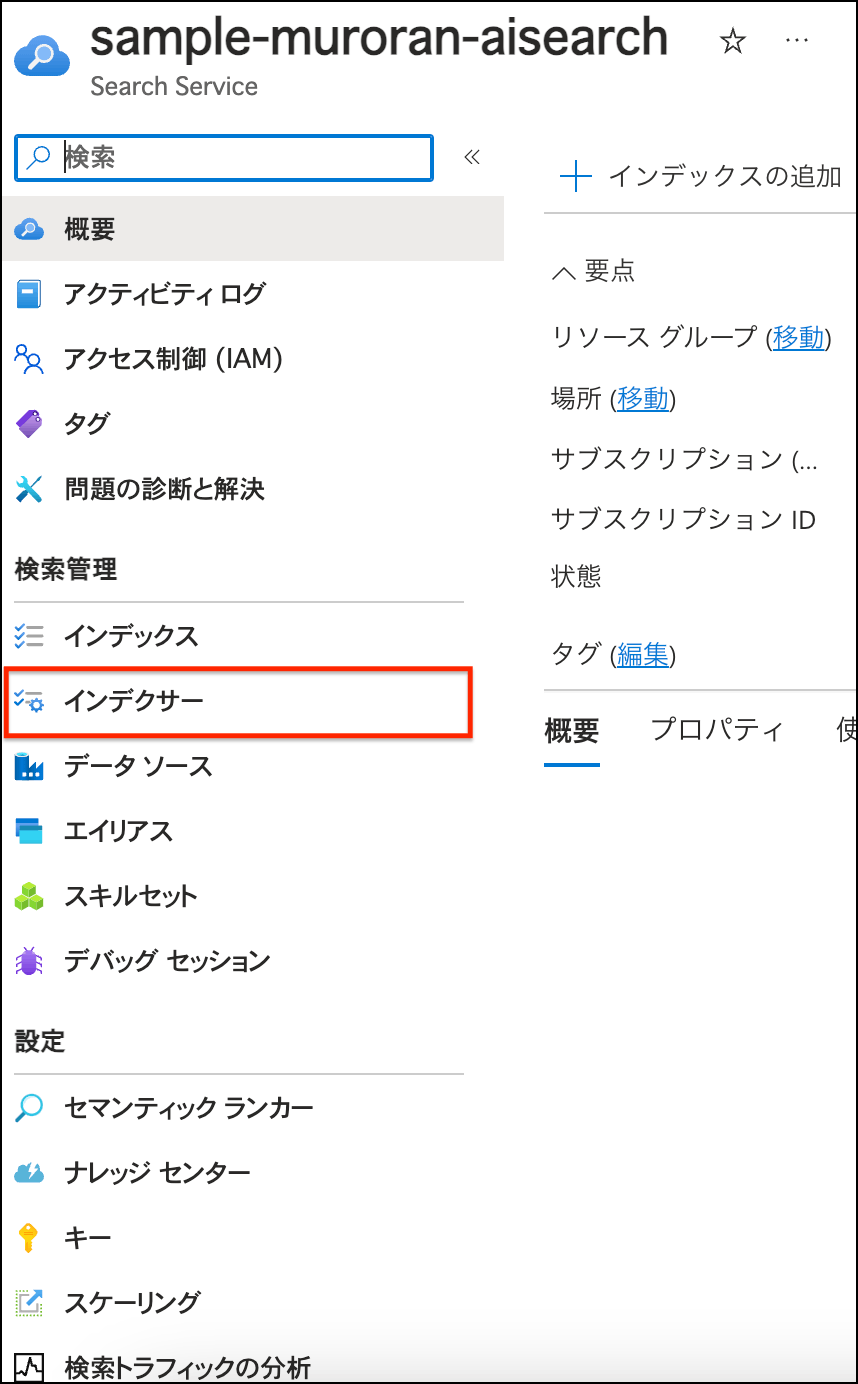
インデクサーが2つあるのでまずは下部を押下

左上の[設定]より[スケジュール]をカスタム、[間隔(分)]を5分に設定し、左上[保存] → [実行]の順で押下

同様の方法でもう片方のインデクサーも設定
これで準備は完了です。
※更新頻度はユースケースに応じて要検討ですが、今回はデモンストレーションなので最短間隔の5分に設定しています。
実際に動かしてみましょう。
まずは、地域再生計画しか取り込んでいない状態で先程決めた質問を投げてみます。
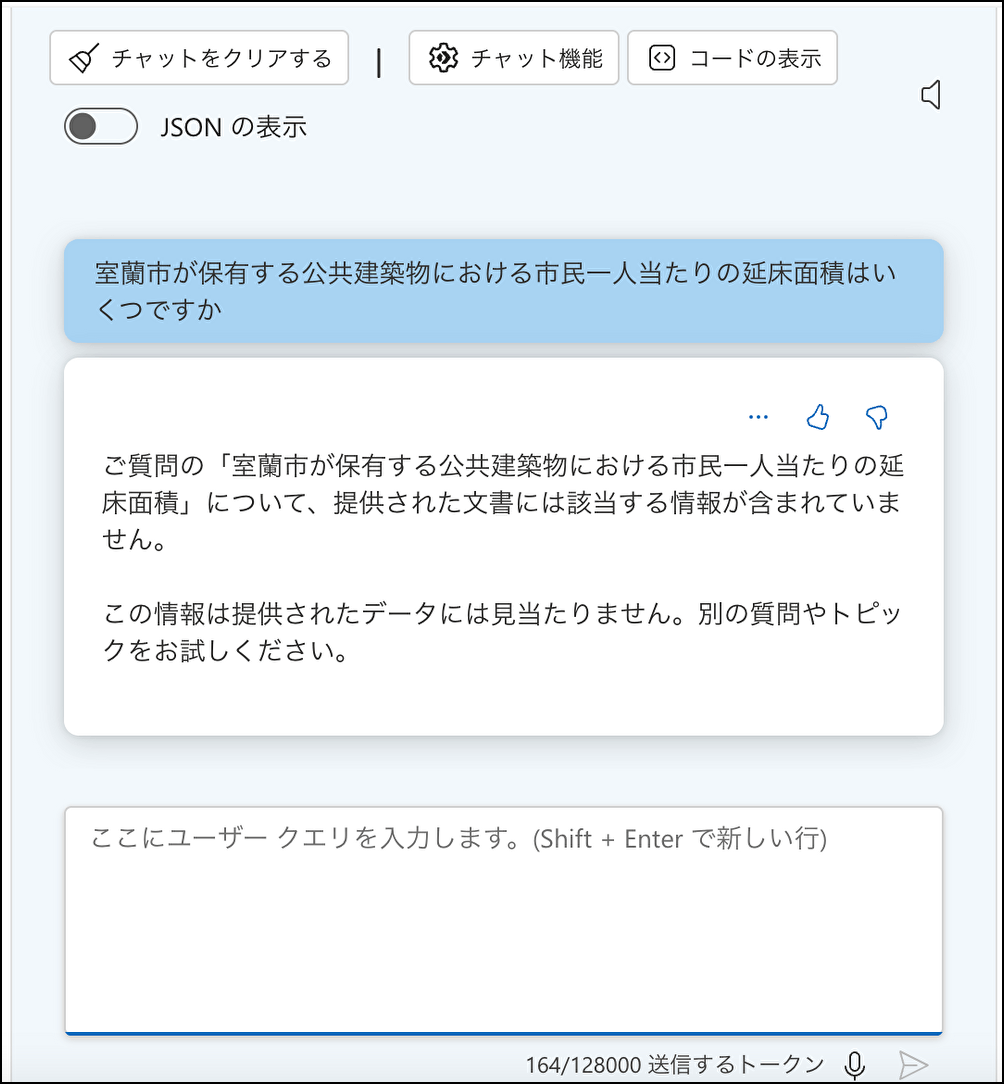
地域再生計画には記載がないので、適切に回答できません。
では、Storage Accountに室蘭市公共施設等総合管理計画の文書をアップロードしてみましょう。
地域再生計画と同じコンテナーに室蘭市公共施設等総合管理計画をアップロードします。
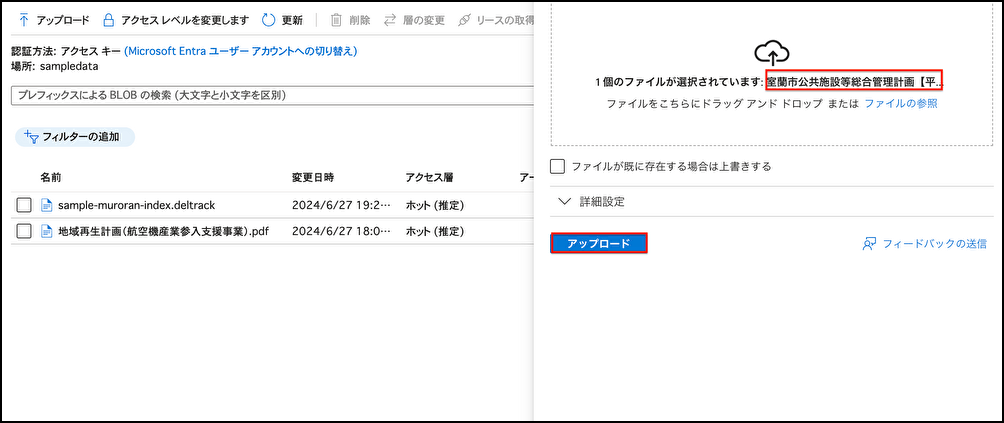
Azure AI Searchの左側[インデックス]を開き5分ほど待ちます。
正常に更新されるとドキュメント数が変わります。
BEFORE

AFTER

同じ質問をしてみると...
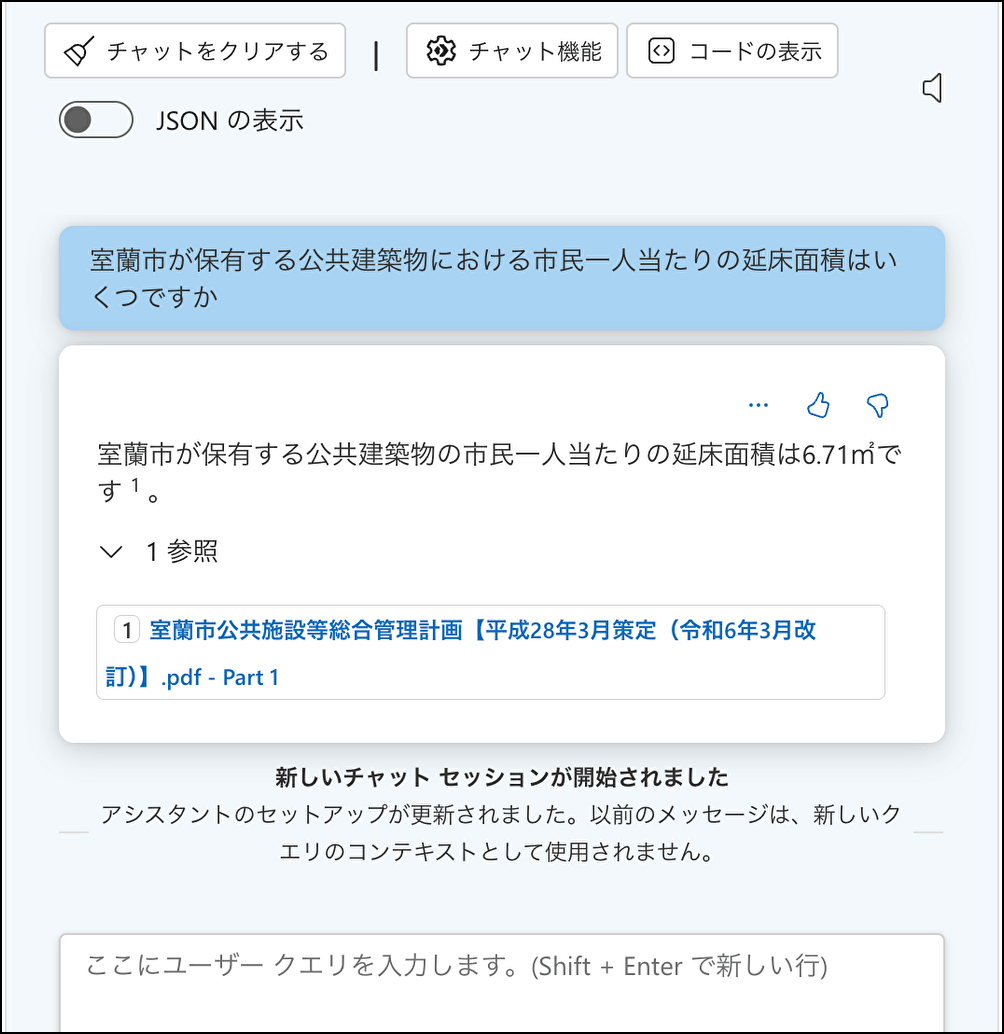
正常に回答できるようになりました!!🎉🎉
こんな感じでStorage Accountに文書をアップするだけでインデックスを自動更新することが可能です。
今回はこれで以上になります。
おわりに
今回は、なぜこのパラメータがあるのか、この機能を利用するにはどうすればいいのか等、あやふやになっていた部分を自分なりにできる範囲で整理してみました。
公式ドキュメントでは明記されておらず、Microsoftコミュニティの掲示板で直接質問しないとわからなかったことが多々あったのでそこも含めて皆様の助けになれば幸いです。

Discussion