はじめに
この記事で想定している読者の方:
- Difyの使い方にまだ馴染めていない方
- ワークフローで何か作ってみたい方
- 簡単にPythonが書ける方
LLMを用いたアプリケーションをノーコード・ローコードで作成できるサービスである「Dify」がその使いやすさと拡張性の高さから最近注目を集めています。しかし, 「Difyを知っているけどまだ使って何かのアプリケーションを作ったことはない...」という方も多いのではないでしょうか。特に, 自由度が高い様々な機能を持ったノードを組み合わせることでLLMを自在に組み込んだシステムを作成できる「ワークフロー」機能は公式でも「経験豊富なユーザ向け」と紹介されている通り少し難易度が高いですが是非使ってみたい機能です。
そこでこの記事では, Dify初心者の方向けに, Dify初心者だった自分が「ワークフロー」機能を用いてシステムを作ってみて詰まった部分とその解決法を大きく5つに分けて紹介していこうと思います。
TL;DR
今回特に紹介したいワークフロー作成時のTipsは以下の通りです!
- ナレッジは手動で区切ったTXTやMDファイルから作成しよう (1章へ)
- ナレッジはユースケースに合わせて検索手法を設定しよう (2章へ)
- ノード間のデータ型を意識しよう (3章へ)
- イテレーションとループの違いを意識しよう (4章へ)
- 困ったらコードブロックを使ってみよう (5章へ)
ローカルファイルからのナレッジの作り方
ナレッジはDifyで最も特徴的とも言える機能ですが, その分初心者の方は様々なオプションや選択肢に悩まれることも多いと思います。その際にオススメの選択についてこの章では紹介して行こうと思います。
ファイルの種別について
まず, ナレッジを作成する際はDify画面上部の「ナレッジ」タブから作成ページに移動します。今回は以下の作成画面にて「テキストファイルからインポート」を選択しナレッジの作成を行います。
画面上にも記載されている通り, サポートされているファイルの形式は非常に多岐に渡ります。自分自身も初めて使用する際はどの形式のファイルを用いるかを迷いましたが, 結論としては初心者の方にオススメはTXTやMARKDOWNです。この理由としては以下の2点が挙げられます。
- Difyによるチャンク自動分割の精度が安定する
- 手動チャンク設定がやりやすい
後者については以下で別途説明するため, まずは前者について具体的に検証してみます。まず手元で同じ内容を記したスライドのpdf(以下の形式)とテキストファイルを用意します。(今回は両方ともにWikipediaのアメリカ合衆国のページの概要部分を用いました)

両ファイル共に10段落の文章によって構成され, pdfは上記の形式で3ページとなっています。これらを用いてチャンク設定を「自動」にしてナレッジを作成しようとすると以下の結果が得られます。

pdfから作成したナレッジの作成画面
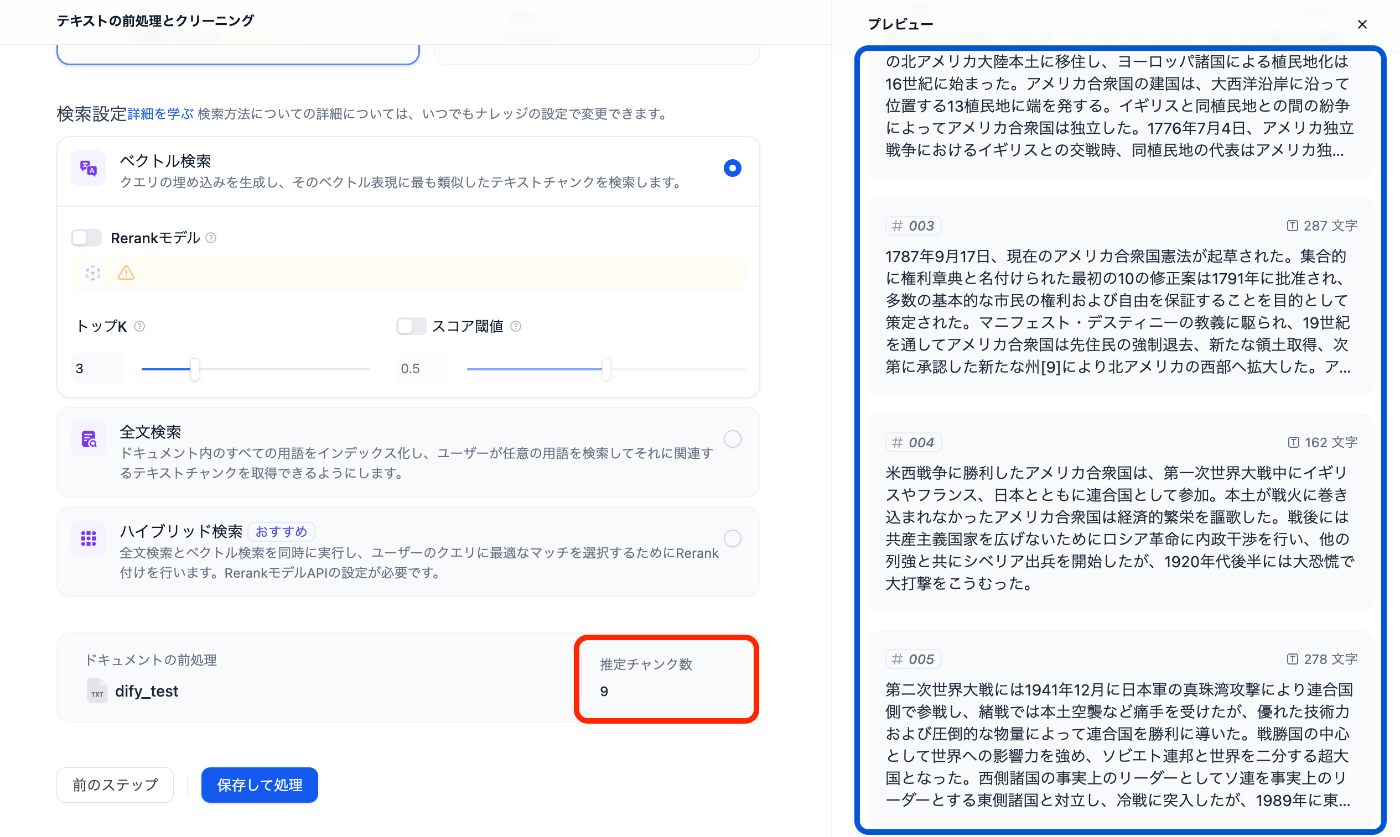
txtファイルから作成したナレッジの作成画面
ここで, 上記の2枚の結果について比較してみます。まず, 赤い四角で囲ったチャンク数を見てみると, pdfが7チャンク, txtが9チャンクと元の段落数の10に近い数になっているのはtxtファイルであることが見て取れます。
その上, 青い四角で囲ったプレビューの部分をよく見てみるとpdfの方は一部文字化けしてしまっていることが分かります。これはおそらくDifyの開発元が中国企業であるため, pdfをパースした際に得られる文字コードが中国語の漢字に変換されてしまっていることが原因ではないかと考えられます。
ナレッジで取得されるチャンクの設定について
実験ではtxtファイルの方が元の段落数に近いチャンク数に自動で分割されていることが確認できましたが, それでも元の10段落から1段落減った9チャンクになってしまっていました。また, 実際に使用する際に「意味的にここで区切って1チャンクとして取得してほしい」といった場合も多くあると思います。このような状況を解決するためにナレッジ作成時は手動で区切りマークを入れておくことがオススメです。(このためにも手動で編集しやすいTXTファイルやMARKDOWNファイルの使用をオススメします。)
実際にテキストファイルに対して段落間に手動で区切り文字を「====」として書き込み, 以下の画像の通りにチャンク設定を「カスタム」かつ赤い囲みの「セグメント識別子」に「====」を設定することで10チャンクに分割することができます。(この際にもし1チャンクとして維持したい長さがデフォルトの500文字を超える場合は最大チャンク長を調整する必要があります。)
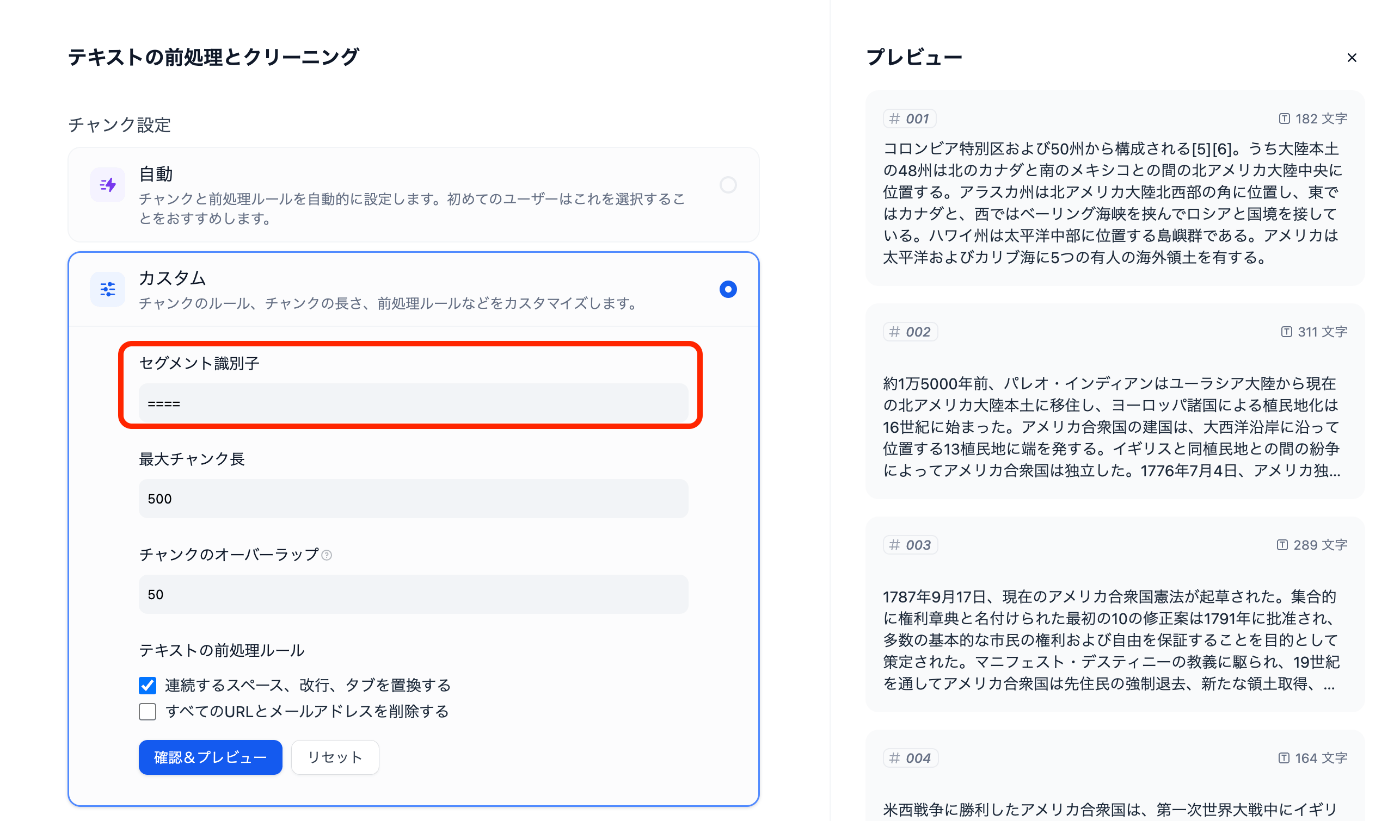
ナレッジの用途別の設定の仕方
次に, ナレッジを作成した後に設定できるオプションについて紹介します。この際には先ほどのナレッジの作成時とは異なりユースケースごとにオススメが異なります。
インデックス方法とその挙動について
そもそも 「インデックス方法」とは作成したナレッジに対してクエリが届いた際にどのような手法で検索を行うかを定義する設定 であり「高品質」と「経済的」の2種類のオプションが存在します。
具体的な挙動としては前者がクエリに対して毎回外部のembeddingモデルを用いてべクトル検索するのに対して, 後者はDifyオリジナルのembeddingモデルを用いたベクトル検索やキーワード検索などを併用し検索を行います。これによる最大の違いは「高品質」は外部モデルの使用料が発生し「経済的」は発生しないことです。実際にどの程度検索の精度が異なるのか見てみましょう。
先ほど作成したアメリカに関する概要を登録したナレッジに, 以下の2つの抽象的な質問と具体的な質問をしてみました。
- 「アメリカがいつできたか教えてください。」
- 「太平洋およびカリブ海に5つの有人の海外領土を持つ国はどこですか?」
まず前者についての検索結果は以下の2枚の画像の通りです
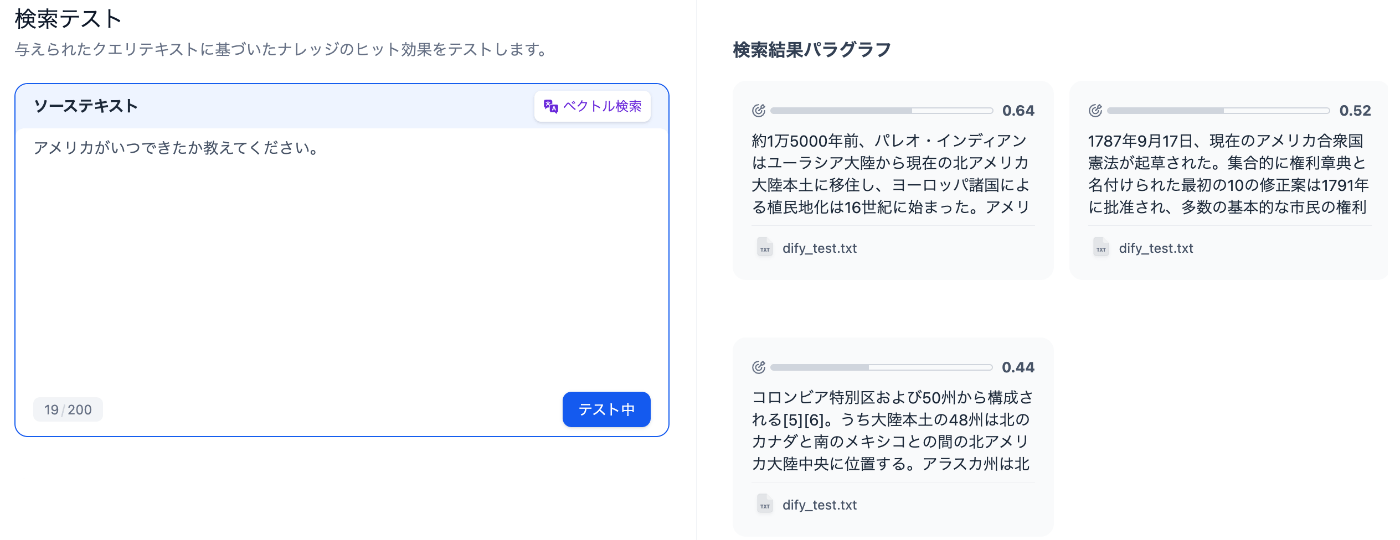
「高品質」の検索結果

「経済的」の検索結果
両者を比べてみると「高品質」は複数の結果が変えせている上に最もスコアが高いチャンクに「約1万5000年前」という回答の一つが表示されています。一方で, 「経済的」の結果ではチャンクがそもそも取得できていないことが見て取れます。
次に, 後者の質問に対する検索結果は以下の2枚の通りです。
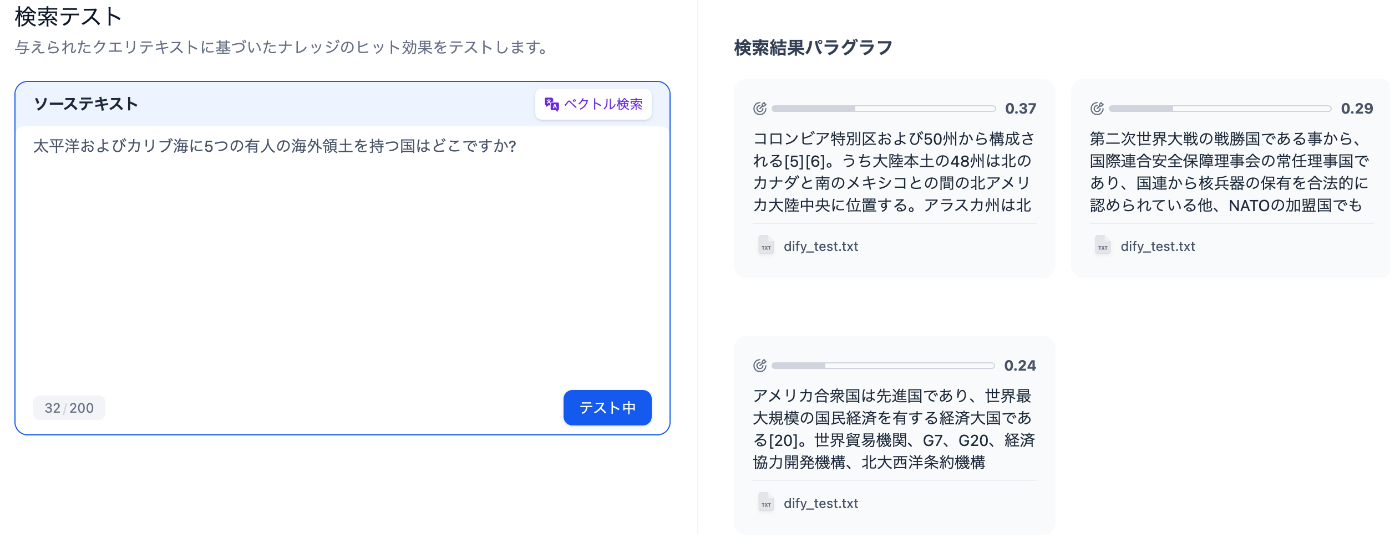
「高品質」の検索結果
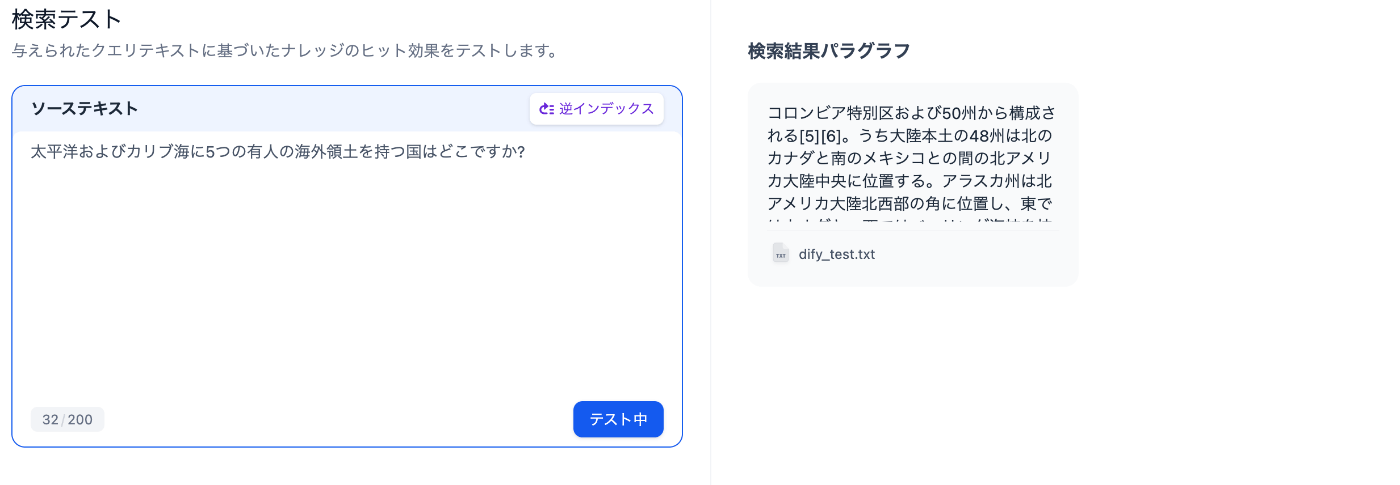
「経済的」の検索結果
両者を比べてみると, 今度はどちらも正解チャンクである「コロンビア特別区~~~」と言うチャンクを取得できていることが分かります。総じて具体的なクエリ(チャンク内に同じ単語が複数出てくるクエリ)に対する性能は同等であったものの, 抽象的なクエリ(意味的な検索を求めるクエリ)への性能は「高品質」の方が圧倒的に優れていることが判明しました。この性能差とクエリのembeddingにかかるモデル使用料は非常に長いクエリや大量のクエリ処理を行わない限り非常に微量であることを考えると, インデックス方法は余程の場合をのぞいて「高品質」がオススメです。
検索手法とその挙動について
以上の内容を受けて「高品質」のインデックス方法を用いる場合, さらに「検索手法」を3種類から設定することができます。この「検索手法」では先ほどとは異なり価格ではなくユースケースごとの検索手法を選択することができます。それぞれの検索手法とその具体的な内容は以下の通りです。
- ベクトル検索 : 入力されたクエリをベクトル化してベクトル検索を行う手法
- 全文検索 : 入力されたクエリに関連する単語で検索を行う手法
- ハイブリッド検索 : 上記2つを用いて検索を行い, その結果をLLMでランク付けしてより適切な結果を選択する手法
以上の検索手法についてそれぞれ適しているユースケースを考えてみると, 初めにベクトル検索については先程の比較でも特徴が出たように抽象的なクエリへの検索に適していることが考えられます。そのため, 一般的なユーザからの質問検索や類似文章の取得などが適切なユースケースになりそうです。
次に, 全文検索では単語の一致不一致に強く影響を受けるため, より具体的なクエリへの検索に適していると考えられます。具体的には, ある程度構造化されたデータへのキーワード検索などが適切なユースケースだと考えられます。これによってDifyのナレッジを一般のRDBっぽく使用することも可能になります。
最後にハイブリッド検索については, 上記2つの特性を併せ持ったデータ(ラベルづけされた非構造化テキスト)などへの使用が適切だと思われます。特にユーザ入力の文章+あらかじめ決められているキーワード等の複数クエリを用いた検索でもより良い精度が出ると考えられます。
基本的なノードの繋ぎ方
ノードの繋ぎ方の基本について
Difyではワークフローのノードを繋ぐ際には以下の簡単なルールがあります。
-
ノードのループはできない
あるノードからフローを辿ると元のノードに着くようなノードの繋ぎ方はできません。 -
開始点と終点が必要
開始ノードと終了ノードをフローにつける必要があります。開始ノードは1つですが, 終了ノードは分岐した先に応じて複数設定することもできます。 -
同じノードから同時に2つ以上のフローに分離できない
以前まではノードから「IF/ELSE」や「質問分類機」を用いずに2つのフローに分離することはできませんでした。ですがv0.8.0にて一般のノードからも通常の繋ぎ方で並列の実行が可能となりました! (詳しくはgithubのリリースノートをご覧ください!)
ナレッジノードの繋ぎ方について
これまでで作成方法を紹介したナレッジもノードとして組み込むことができます。この際にはフローに接続した後に, LLMの入力の一部として使用することができます。この際には, LLMブロック(以下の画像)の赤い囲いの部分にて「コンテキスト」として設定し, オレンジの囲いの形式でプロンプトに含める必要があります。青い囲いにて示される通常の変数(result)とはプロンプトに含める形式が異なることに注意が必要です。
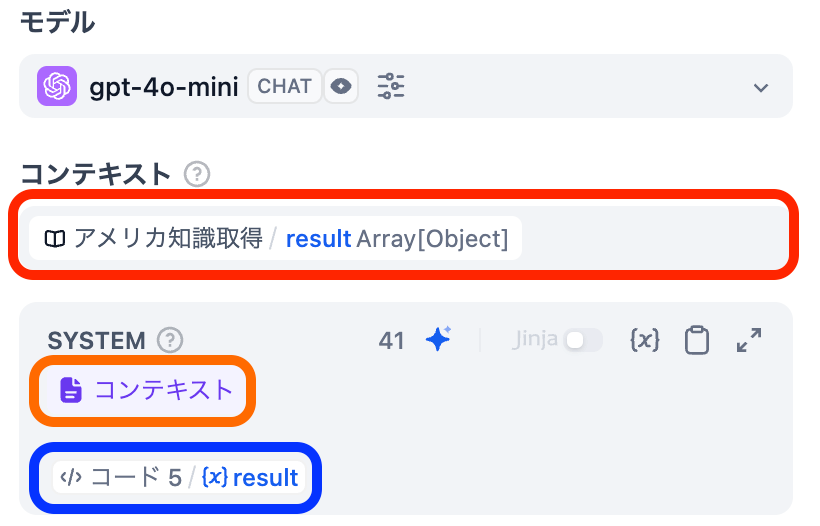
ノード間のデータ型について
上記の画像の中でもコンテキストがArray[Object]型と示されている通り, ワークフロー中で受け渡されるデータには型が定義されています。これらはプログラミングの型にも準拠しており, それに応じた処理をすることができます。(数値計算, 文字列操作, etc..) また, ナレッジから取得された知識はArray[Object]型ですが, これは取得された知識がチャンクの文字のみではなく取得元ナレッジの情報などの複数の情報によって構成されていることを表しています。
繰り返し処理の書き方
作れるループ処理と作れないループ処理について
Difyのワークフローでは作成できるループ処理と作成できないループ処理が存在します。具体的にはループ内で終了条件を判定するループは作成できません。 例えば無限ループにしておいてLLMの呼び出し結果に応じて終了する処理などは1つのワークフローを用いて作成することはできないため, 1つのワークフローをツール化して別のワークフローで呼び出すといった工夫が必要となります。
イテレーションブロックの使い方について
一方で作成できるループ処理の作成にはイテレーションブロックを用いる必要があります。このイテレーションブロックでは, 入力としてArray型のデータを受け取りその中のデータ1つずつに対して処理を行い同じくArray型として返すことができます。イメージとしてはPythonの簡易for文の処理に近いです。この際に入力がArray型である必要があるため, もし 「処理したい対象が配列ではない」or「規定回数同じ処理をしたい」といった場合はコードブロックを用いて入力配列を作成する必要があります。例えば以下のコードブロックでの解決方法などが挙げられます。
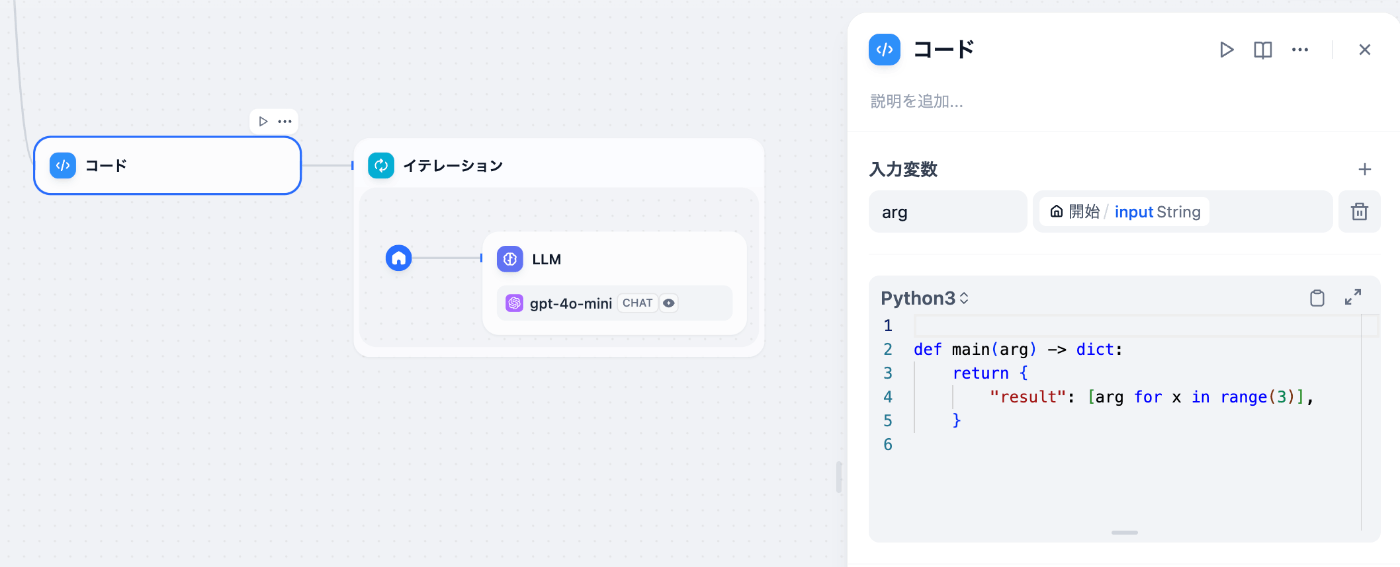
同じユーザ入力を3回LLMに渡したい場合

シンプルに3回イテレーションを回したい場合
コードブロックの使い方
コードブロックで何ができるかについて
上のイテレーションの使い方でも用いましたが, コードブロックを用いることで各ノードの繋げ方を柔軟にすることができます。特に, 前述したノード間でのデータ型を調整する際や, ユーザからの入力を整形したい時に使うと便利です。また, 上級者の方はワークフロー内で環境変数を設定することができるため, それを用いて外部との通信などのより複雑な処理を書くこともできます。ですが, とりあえず初めて使う場合はノードの繋ぎ方に困ったらコードブロックを挟んでみることがオススメです。
コードブロックのユースケース紹介
実際に自分が初めてワークフローを使う際に参考になったコードブロックのユースケースについて2つ紹介します。
-
イテレーションの出力整形
イテレーションは出力形式もArray型に限定され, 終了ノードはArray型のデータを綺麗に表示することができません。そのため, イテレーションの後に終了する場合に, それらの間に以下のコードブロックを挟むことで文字列にデータを変換し綺麗に表示することができます。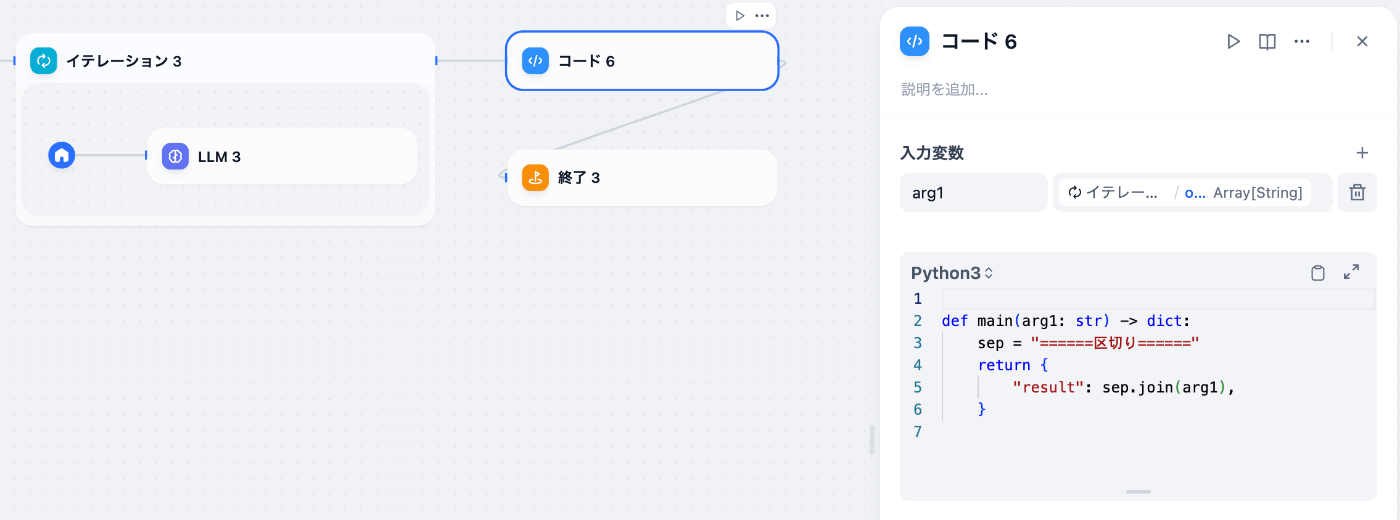
イテレーションの出力を整形したい場合のコードブロック例 -
取得したナレッジの1つずつを取得し処理
ナレッジから取得された知識はArray型であるためイテレーションブロックで1つずつ処理することができます。ですが, 配列の1つずつをそのまま変数としてプロンプト内に埋め込むとナレッジの様々な補助情報も埋め込まれてしまいます。そのため, 内容の文章のみを取得するコードを挟むことで解決することができます。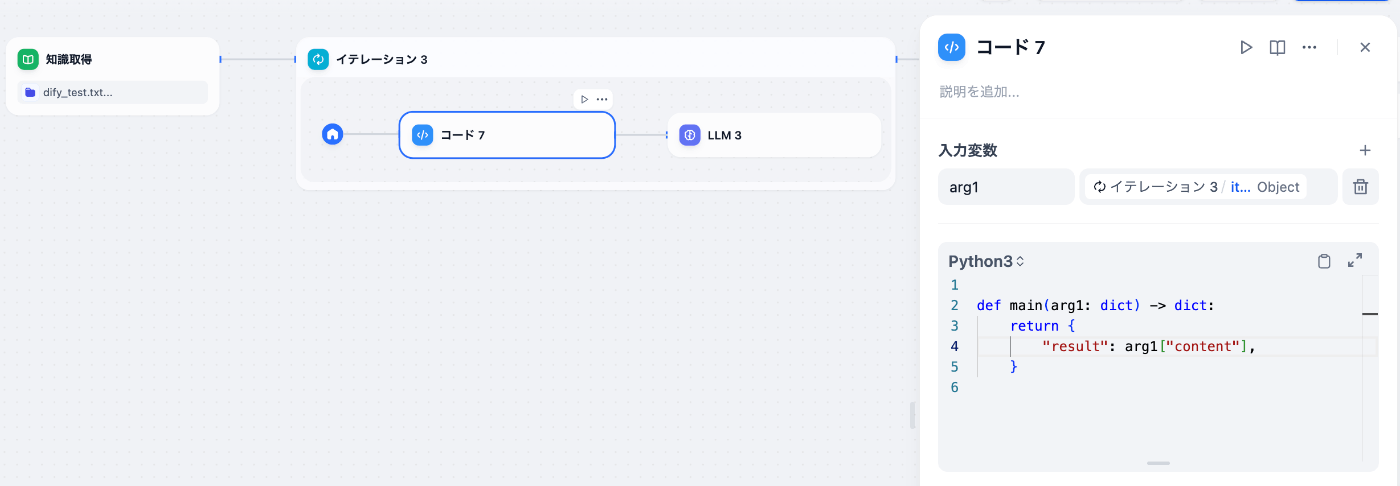
取得された知識を1つずつイテレーションで処理する場合のコードブロック
おわりに
今回は, 初心者の方向けにDifyを用いてワークフローを作成する際に詰まりがちな点についてその解決法と共に5つ紹介させていただきました! 自分自身まだDifyについては初学者に近いためもっと効率的な解決方法等があったかもしれませんが, 自分でより良い方法を見つけたら適宜内容をアップデートしていこうと思います。
少し長くなってしまいましたが, 最後までお読みいただきありがとうございました!

Discussion
参考になります!