


記事の内容
この記事では、arize phoenixのspan queryの使い方を紹介します。
公式ドキュメントではわからない、以下の2つについて説明します
- SpanQueryで取得可能なデータの確認方法
- SpanQueryの指定パラメータの調べ方
対象読者
- span queryの使い方について、公式ドキュメントを既に読んでいる
- 読んだが、解決できなかった方
tl;dr
- SpanQueryで取得可能なデータは、phoenix上のjsonデータ
- jsonデータを見れば指定するパラメータもわかる
- jsonデータからSpanQueryを作成する方法を例示
SpanQueryで取得可能なデータの確認方法
phoenix上のchain確認画面を開き、Attributesのタブを表示します
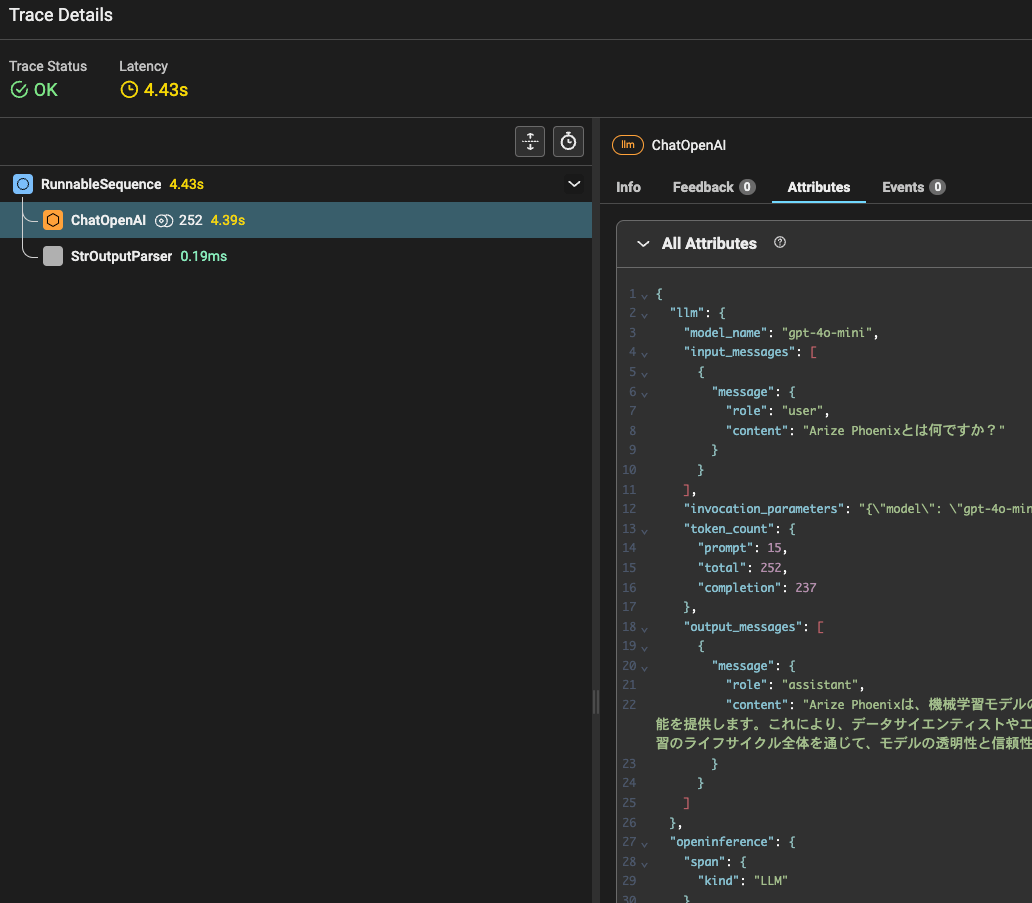
SpanQueryで取得可能なデータは、このjsonです。
SpanQueryで使用する値を調べる方法
以下はjsonの一部をコピペしたものです。
{
"llm": {
"model_name": "gpt-4o-mini",
"input_messages": [
{
"message": {
"role": "user",
"content": "Arize Phoenixとは何ですか?"
}
}
],
...
"output_messages": [
{
"message": {
"role": "assistant",
"content": "Arize Phoenixは、機械学習モデルのパフォーマンスを監視し、改善するためのプラットフォームやツールの一部として知られています。具体的には..."
}
}
]
},
"openinference": {
"span": {
"kind": "LLM"
}
},
...
}
SpanQueryで使用する値は、このjsonを見ればわかります。
以下に実例で説明していきます。
jsonの任意の値を取得するクエリを作成する
試しに、このjsonに記載されている"model_name"をSpan Queryで取得してみます。
...
"openinference": {
"span": {
"kind": "LLM"
}
},
...
jsonを見るとこのspanの種類は"LLM"だということがわかります。
import phoenix as px
from phoenix.trace.dsl import SpanQuery
query = (
SpanQuery()
.where(
"span_kind == 'LLM'",
)
...
そのためwhereの部分には↑のように記載します。
{
"llm": {
"model_name": "gpt-4o-mini",
...
}
}
取得したい"model_name"は"llm"の中に存在します。
これを取得するには、llm.model_nameのように'.'でつなぎselectで指定します。
import phoenix as px
from phoenix.trace.dsl import SpanQuery
query = (
SpanQuery()
.where(
"span_kind == 'LLM'",
)
.select(
model_name="llm.model_name",
)
)
result = px.Client().query_spans(query)
# resultの中身はpandasのDataFrame↓
#
# model_name
# context.span_id
# 3301548027c552e7 gpt-4o-mini
↑のようになります。
ちなみにmodel_name=の部分は帰って来るDataFrameの列名になるだけなので、何でも良いです(modelNameとか)。
jsonの中身がリスト(配列)の場合はどうするか?
ものによっては、jsonの中身がリスト(配列)となっているものがありますがこれも同様です。
リストに遭遇する代表例として、RAGでLLMに与えたcontextを取得する例を説明します。
※concatメソッドかexplodeメソッドを使うことになりますがこれについては公式ドキュメントを確認して下さい。
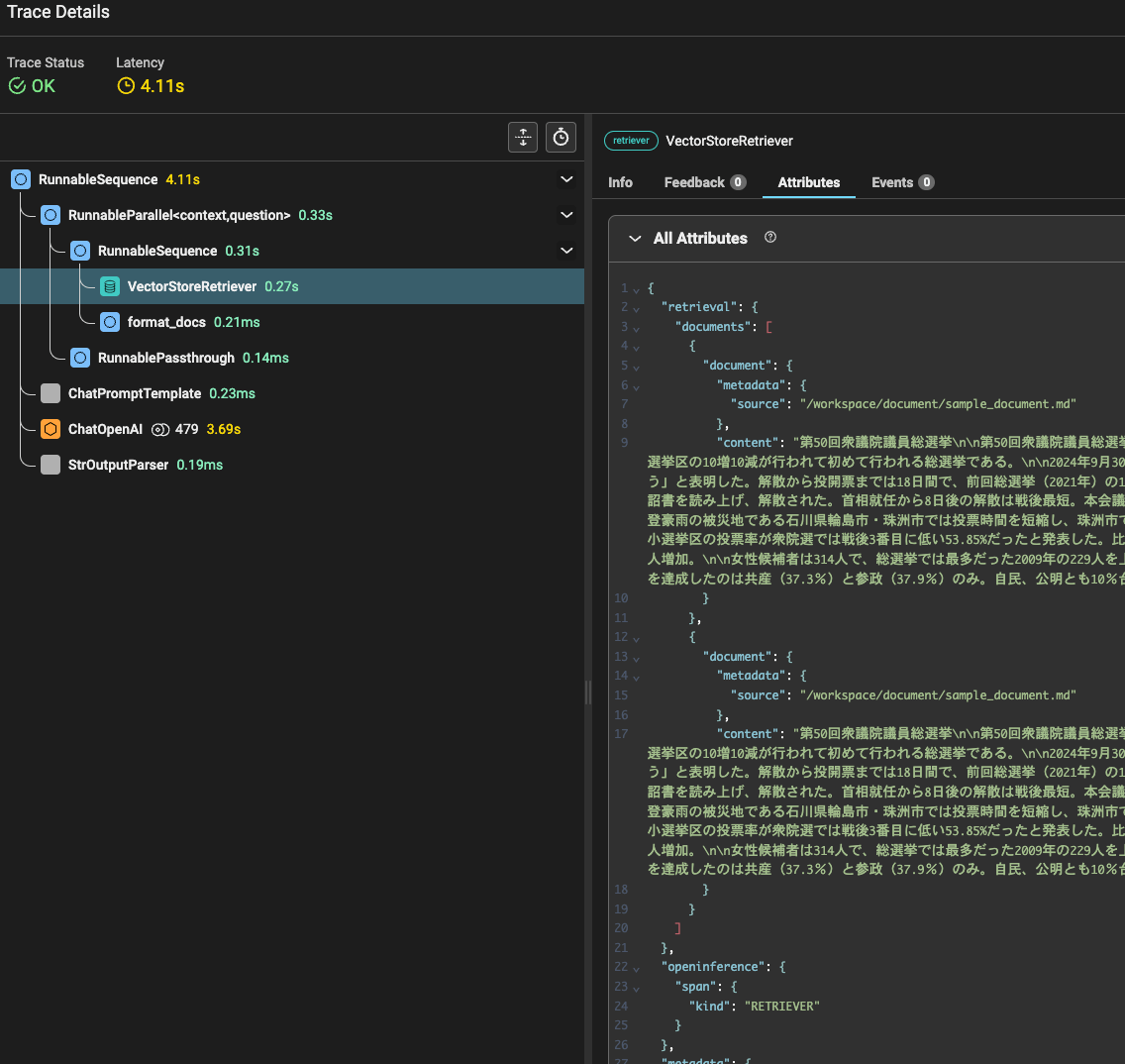
{
"retrieval": {
"documents": [
{
"document": {
"metadata": {
"source": "/workspace/document/sample_document.md"
},
"content": "第50回衆議院議員総選挙\n\n第50回衆議院議員総選挙(だい50かいしゅうぎいんぎいんそうせんきょ)は、..."
}
},
{
"document": {
"metadata": {
"source": "/workspace/document/sample_document.md"
},
"content": "第50回衆議院議員総選挙\n\n第50回衆議院議員総選挙(だい50かい..."
}
}
]
},
"openinference": {
"span": {
"kind": "RETRIEVER"
}
},
...
}
↑はretrieverのspanのjsonです。
最初の例と同様にspanの種類を確認します。
{
...
"openinference": {
"span": {
"kind": "RETRIEVER"
}
},
...
}
spanの種類は"RETRIEVER"だということがわかります(ほしいデータがretrieverにあるので当然ですが)。
import phoenix as px
from phoenix.trace.dsl import SpanQuery
query = (
SpanQuery()
.where(
"span_kind == 'RETRIEVER'",
)
...
そのためwhereには↑のように記載します。
{
"retrieval": {
"documents": [
{
"document": {
...
"content": "第50回衆議院議員総選挙\n\n第50回衆議院議員総選挙(だい50かいしゅうぎいんぎいんそうせんきょ)は、..."
...
}
今回欲しいデータは、:"retrieval"の中の"documents"の中の"document"の中の"content"です。
なのでretrieval.documents.document.contentとしたくなるのですが、concatメソッドとexplodeメソッドは、リストに入る前後で分割して指定する必要があります。
- リストに入る前まで:
retrieval.documents - リストに入った後:
document.content
import phoenix as px
from phoenix.trace.dsl import SpanQuery
query = (
SpanQuery()
.where(
"span_kind == 'RETRIEVER'",
)
.concat(
"retrieval.documents",
reference="document.content",
)
)
result = px.Client().query_spans(query)
# resultの中身はpandasのDataFrame↓
#
# reference
# context.span_id
# 669d172c4167be43 第50回衆議院議員総選挙\n\n第50回衆議院議員総選挙(だい50かいしゅうぎいんぎいんそう...
↑のようになります。
おわりに
ちょっと複雑なchainを使っていたため公式ドキュメントのサンプルでは思うようにデータが取得できず、悲鳴を上げていました。
しかし、SpanQueryで取得できるデータはphoenix上に表示されているjson && 規則的に指定すればよいのだとわかると簡単にデータが取得できるようになりました。
(もしかしてすぐわかるものなのだろうか...)
この記事が誰かの悲鳴を防げたのなら幸いです。

Discussion