はじめに
この記事で想定している読者の方:
- LangChainで簡単でもコードを書いたことがある人
- LLM chainについてざっくりと理解している人
公開されているLLMをapi経由で用いて様々な処理を記述できるライブラリ 「LangChain」にて, 主に外部から文書を与える際に用いられる以下の4つのchainをご存知の方も多いと思います。
- stuff chain
- map reduce chain
- map rerank chain
- refine chain
今回は, 実際にstreamlitを用いて4つのchainを使用したchatアプリのデモ作成し, それを用いてchainごとの性能比較を行いました!
比較では単純な応答能力の比較に加えて, 生成時間やAPI料金の観点からも比較を行なったので, ぜひ読んでみてください!
TL;DR
今回の実験は以下のgif画像のようなデモアプリを用いて行いました。簡単な結論は以下の通りです!
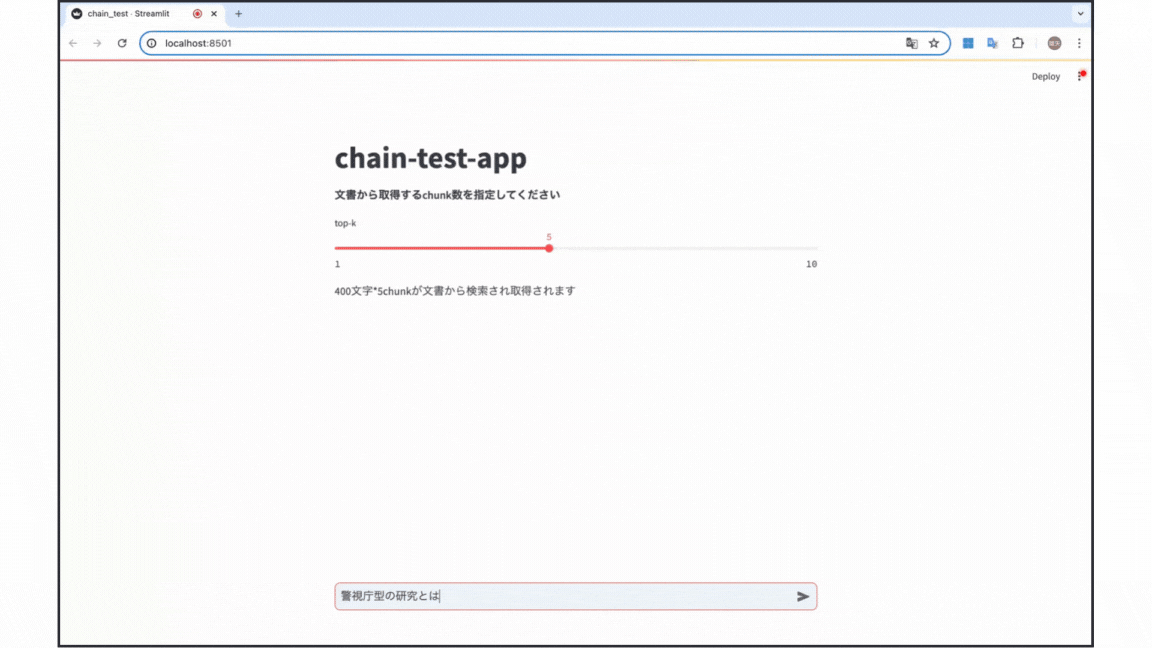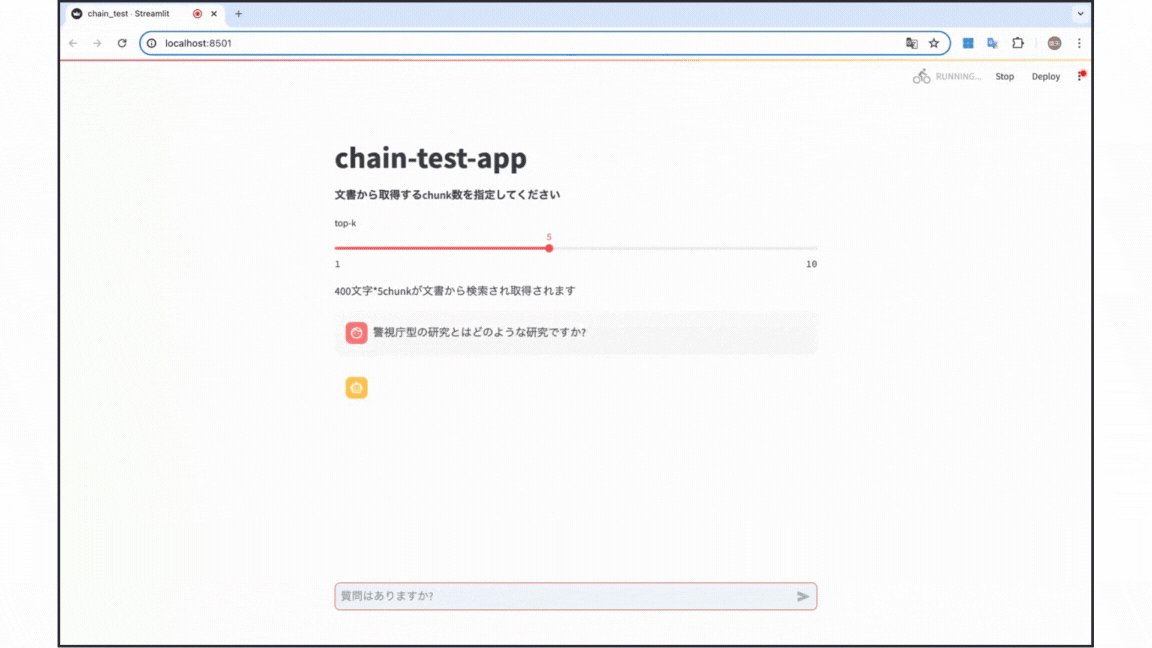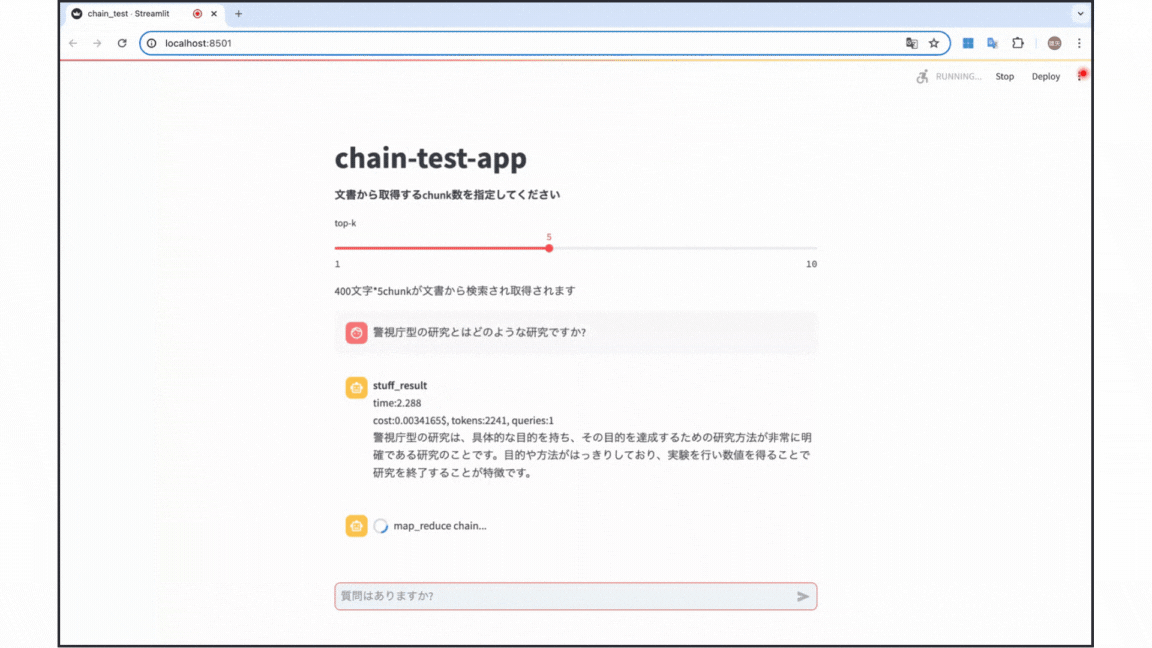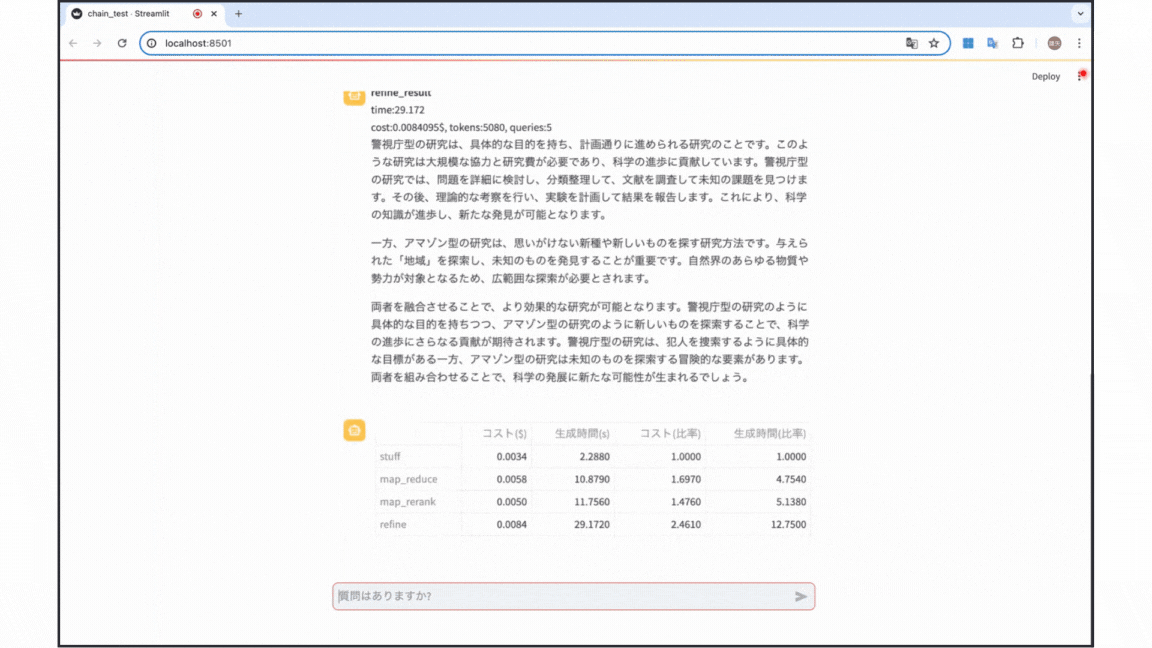
- バランスを優先する場合 : stuff
- 精度を優先する場合 : refine
- 文章と質問の形式が特定の形に固定される場合 : map reduce/map rerank
※ 今回の比較実験を踏まえた個人的な見解です。当たり前ですが, 実際にはユースケースごとに最適なものを選ぶことになります。
4種類のchainについて
初めに今回実装して性能を比較する4種類のchainについて, その仕組みを説明した後に一般的な比較についてまとめていきます。もしすでにご存知の方は読み飛ばしていただいて問題ありません!
各chainの構造詳細
stuff chain
stuff chainは以下のイメージのように, 与えられた複数の文書をchain内部で1つのプロンプトの中にまとめて埋め込んでLLMに与える最も簡単な形式のchainです。その形式ゆえに他のchainと比較した際に, 実装が簡単であったりapi利用回数が少なくなることが特徴と言えます。
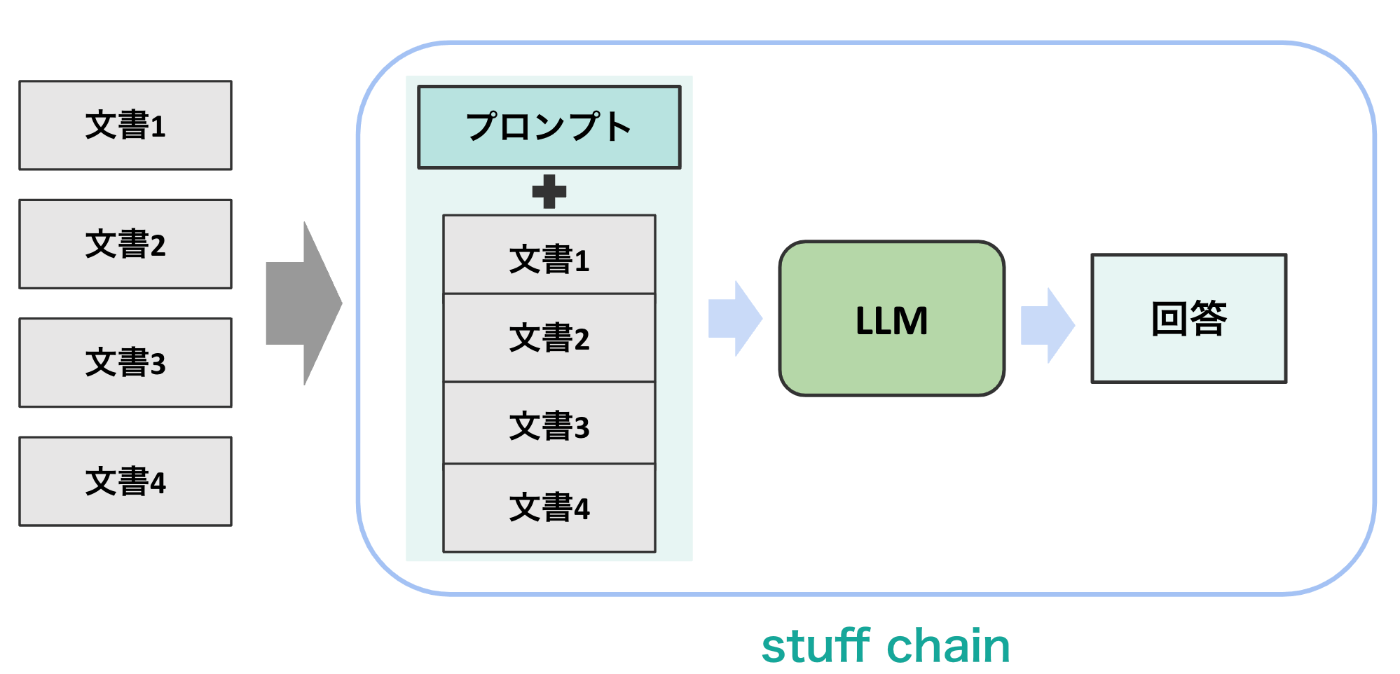
map reduce chain
次に, map reduce chainは以下のイメージの通りの構造となっています。具体的には, 与えられた文書1つずつに対して回答を作成し, それらを最終的に1つの最終回答にまとめるという動作が特徴的になっています。また, 形式上プロンプトに1回目の回答作成用と最終回答作成用の2種類が必要になります。
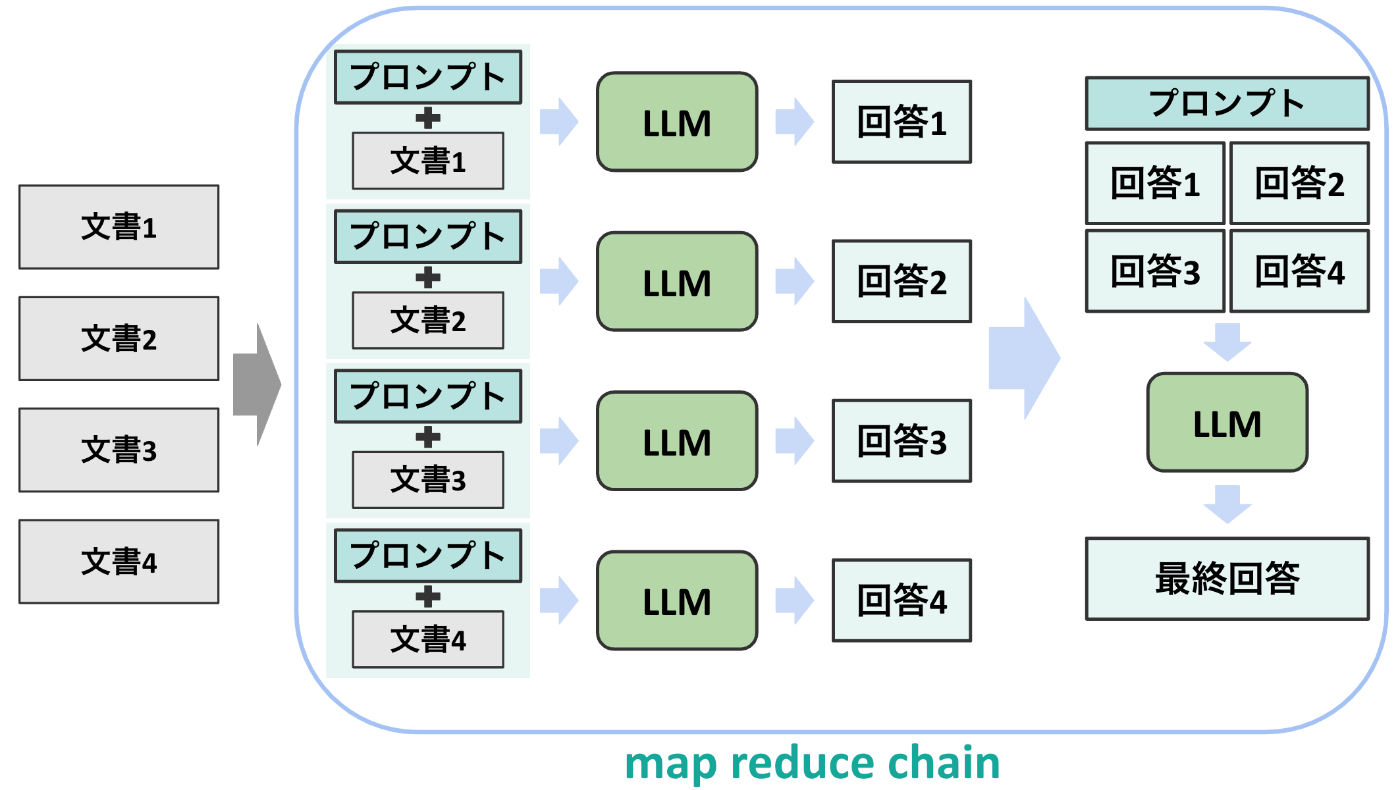
map rerank chain
3つ目のmap rerank chainは以下の構造の通りです。このchainでは, 上のmap reduce chainと似て文書を1つずつLLMに通して回答を作成するところまでは同一ですが, 回答時にLLMの自身度合いを順位として出力させる箇所が異なります。これによって, 最後にもう一度回答を作成するのではなく最も順位が高い回答を最終回答として出力することができます。
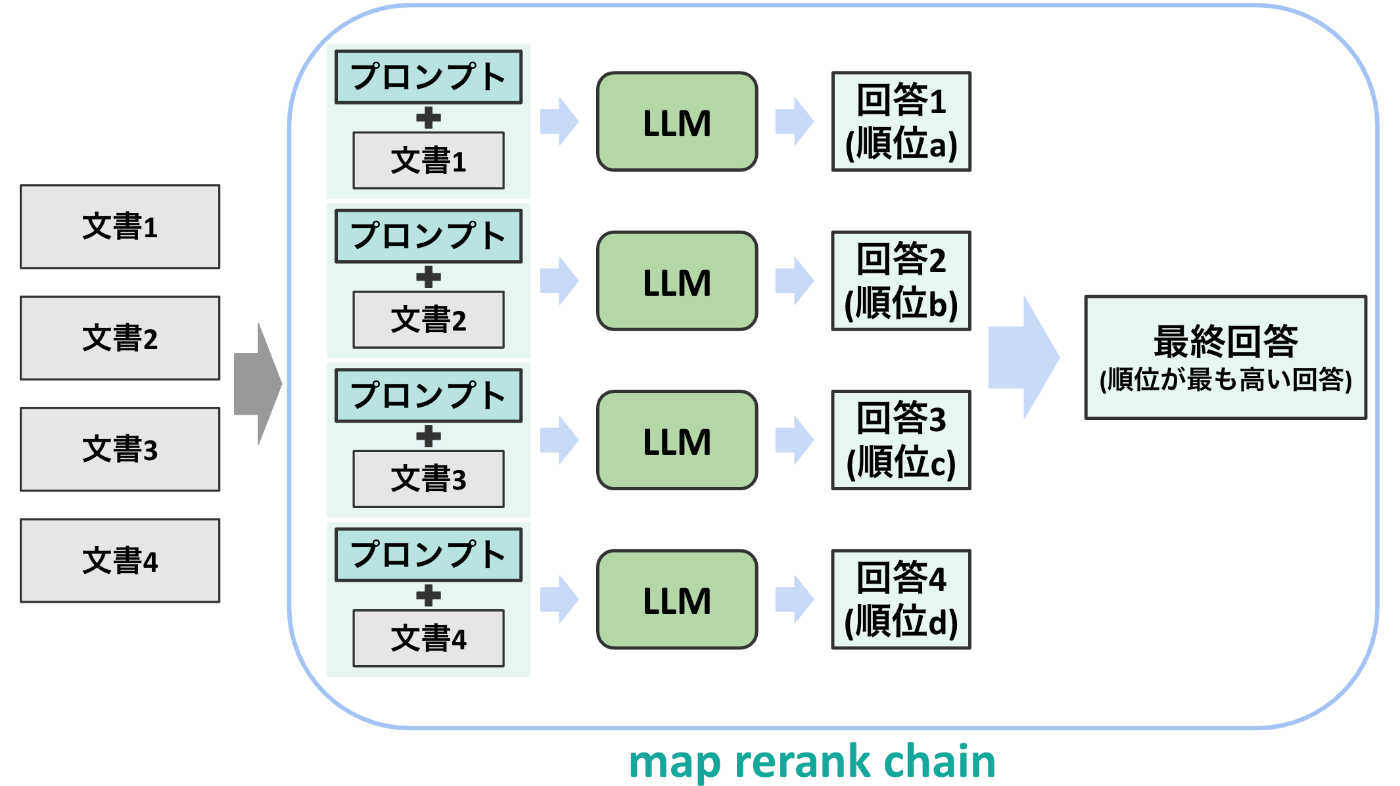
refine chain
4つ目のチェインは以下の図で表されるrefine chainです。このチェインでは文書を分けてLLMに入力する点は以前のチェインと同様ですが, 毎回の出力を次の文書に加えてLLMに入力する点が異なります。これによって, 文章全体を精度高く入力することができる点が特徴となります。
各chainの構造上の比較
以上の構造の違いから, 各chainの構造上の比較は以下の表の通りにまとめられます。
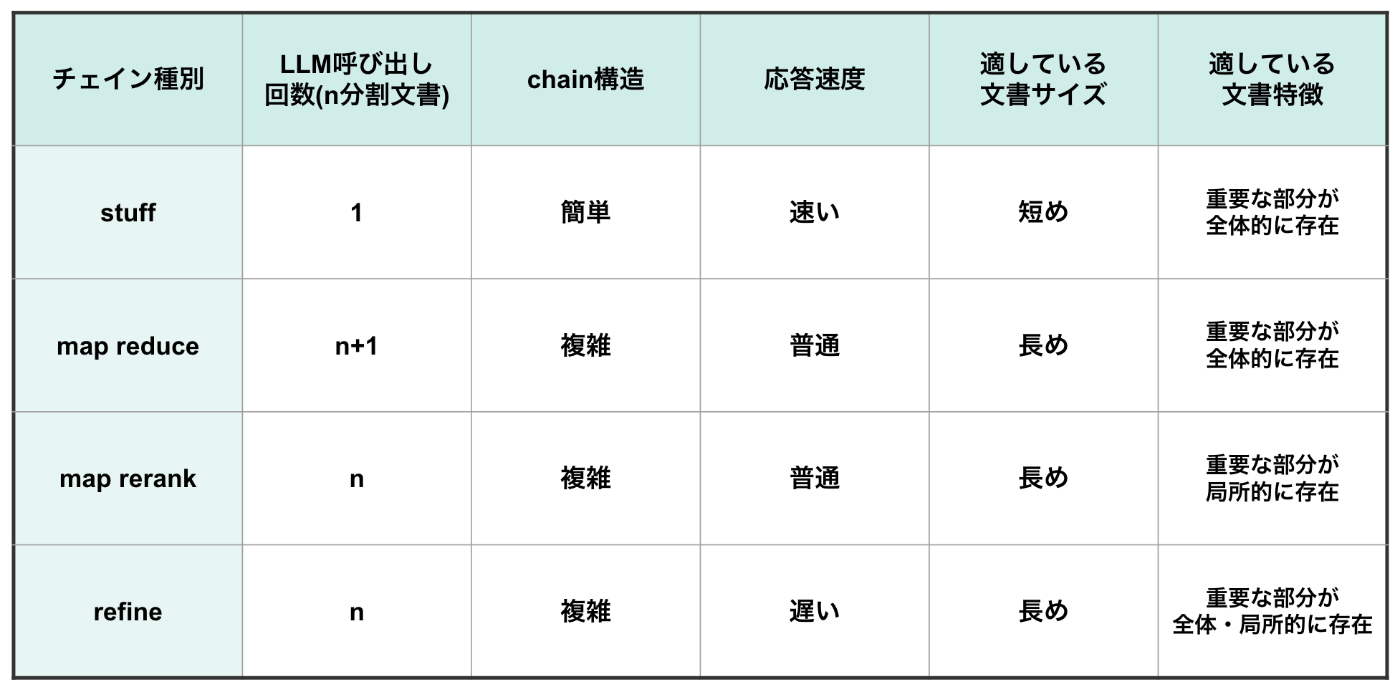
また, 各chainの特徴に関しての補足説明は以下の通りです。
-
応答速度 : 呼び出し回数が1回のstuffは「速い」, n回ですが各文書に対するLLM呼び出しを並列化できるmap系2種は「普通」, n回かつ並列化ができないrefineは「遅い」としています。
-
適している文書特徴
-
stuff・map reduce : 文書全体を1段階または2段階でLLMに入力するため, 文書全体に重要な情報が含まれる場合に特に有効です。
-
map rerank : 文書の一部のみの回答から最良の回答を選ぶため, 一部のみに重要な情報が含まれる場合に特に有効です。
-
refine : 一部のみの回答を複数回再起的に呼び出すため, 重要な情報が文書の全体でも一部でも対応することが可能です。
-
実験と性能比較
GitHubリポジトリ上のコードを用いて実験と性能比較を行います。
実験概要
環境
今回はLLMとしてgpt-3.5-turboを指定します。また, RAG対象文章として以下のような形式の青空文庫のテキストファイルを用意し, ルビや本文に関係ない部分を整形してベクトルDB(FAISS)に登録し使用します。
[#6字下げ]一 研究における二つの型[#「一 研究における二つの型」は中見出し]
科学が今日のように発達して来ると、専門の分野が、非常に多岐に分れて、研究の方法も、千差万別の観を呈している。事実、使われている機械や、研究遂行のやり方を見ると、正《まさ》に千差万別である。しかしそれらの研究方法を概観すると、二つの型に分類することができる。
その一つは、今日精密科学といわれている科学のほとんど全分野にわたって、用いられている研究の型である。問題を詳細に検討して、それを分類整理し、文献をよく調べて、未知の課題を見つける。このいわゆる研究題目が決まると、それについて、まず理論的な考察をして、どういう実験をしたら、目的とする項目についての知識が得られるかを検討する。そして実験を、そのとおりにやって、結果を論文として報告する。
こういう種類の研究で、一番大切なことは、よい研究題目を見つけることである。それが見つかれば、あといろいろと工夫をして、その問題を解いて行けばよい。
実験に用いる質問
今回は, 4種類のchainの性能を比較するために ①要約, ②質問応答, ③直接の記述がない曖昧な質問 の3つのタスクを想定した質問をそれぞれ行います。その後, 下の図の通りにchainからの出力を定性的に評価してかかった時間とAPI料金についても計測を行い比較します。具体的な質問は以下の通りです。
- 質問1 : 「研究における2つの型とそれらの特徴を教えてください。」
- 質問2 : 「警視庁型の研究の具体例を教えてください。」
- 質問3 : 「比較科学論についてそれが何かを説明してください」
質問1の結果と考察
質問1では「研究における2つの型とそれらの特徴を教えてください。」をchainに通して回答を得ました。この質問では, 文章全体のテーマである2つの研究の型について質問しているため, 全体の要約的なタスクとなっています。期待される回答としては "警視庁型"と"アマゾン型"の研究について触れられている回答 が挙げられます。
各chainの回答から以下の傾向が判明しました!
- map rerankのみ正しい回答を出力できなかった
- refineについてはかなり詳しく正しい解説をできていた
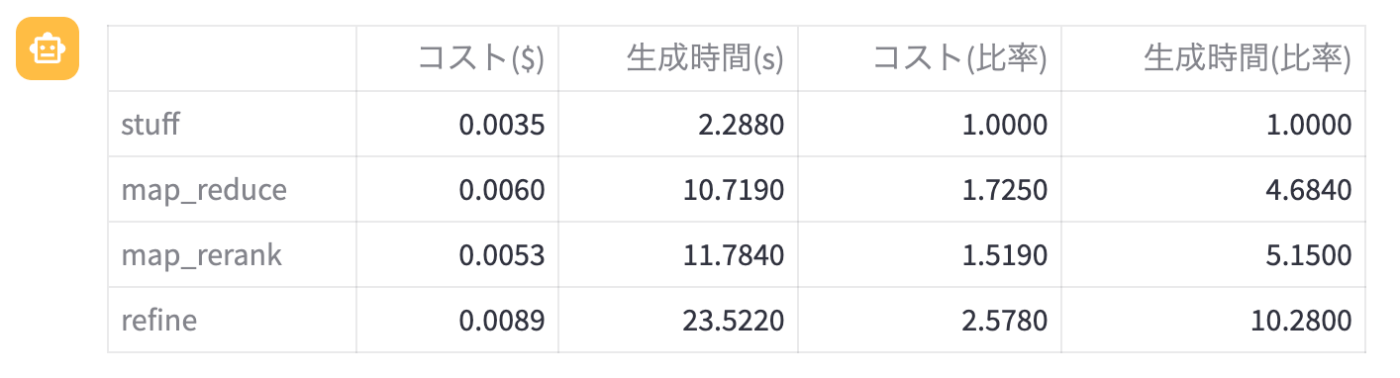
- 生成時間, コストともに stuff < map系列2種 < refine の関係であった
よって, 文章全体の要約のタスクに関しては文章の1部のみを用いた回答が出力されるmap rerankは不向きであることが考察されます。
この際の各chainの実際の回答は以下の通りでした。(長いので折りたたみ)
-
stuff chain

-
map reduce chain

-
map rerank chain

-
refine chain

また, 生成時間と使用API料金についての表は以下の通りとなりました。
質問2の結果と考察
質問2では「警視庁型の研究の具体例を教えてください。」を質問として与えています。この質問は本文中にていくつかの具体例が紹介されているため, 一部を抜き出す質問応答タスクとなっています。期待される回答としては正しく具体例を回答できている回答が挙げられます。
各chainの回答から以下の傾向が判明しました!
- map reduceのみ正しい回答を出力できなかった
- refineは他2つと比べて別のより具体的なテーマを選択していた
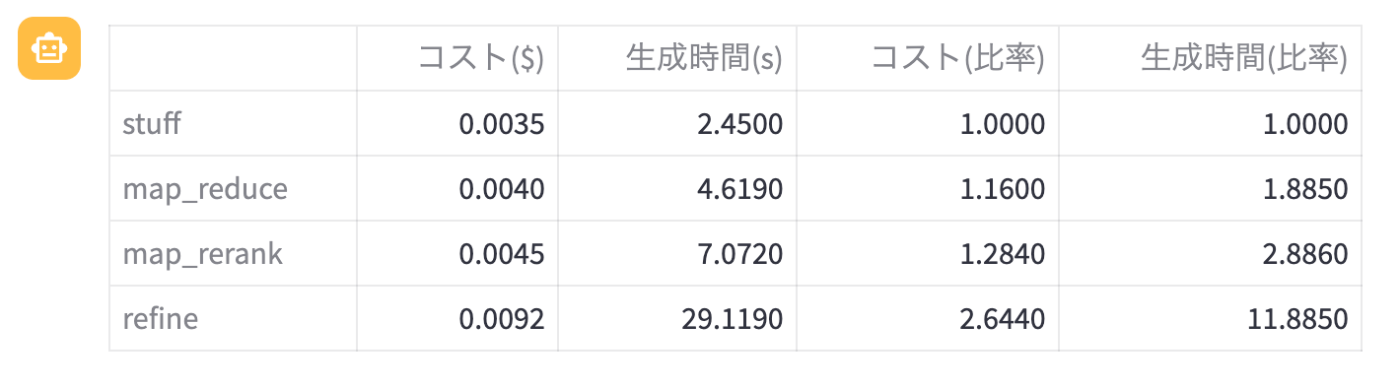
- 生成時間, コストともにstuffと同様の関係が成り立っていた
よって, 文章一部の抜き出しによる質問応答には全体の回答を作成した後にまとめて出力するmap reduceは不向きであることが考察されます。
この際の各chainの実際の回答は以下の通りでした。(長いので折りたたみ)
-
stuff chain

-
map reduce chain

-
map rerank chain

-
refine chain

また, 生成時間と使用API料金についての表は以下の通りとなりました。
質問3の結果と考察
質問3では「比較科学論についてそれが何かを説明してください」を質問として与えています。この質問は本文中には明確な回答がない概念的な質問であるため, 抽象的なテーマについての難易度の高い回答・要約タスクとなっています。期待される回答としては文章中の説明をある程度抜き出せていることに加えて独自で解釈をつけてまとめられていることが挙げられます。
各chainの回答から以下の傾向が判明しました!
- map reduceのみ正しい回答を出力できなかった
- refineは他2つと比べて抜き出しだけでなく正しい解釈を行えていた
- コストの関係はあまり変わらないが, 生成時間に関しては関係が強くなっていた。
よって, 難易度の高い抽象的な質問にはmap_reduceは不向きであり, さらに他2つと比べるとrefineは一歩進んだ出力をしてくれることが考察されます。
この際の各chainの実際の回答は以下の通りでした。(長いので折りたたみ)
-
stuff chain

-
map reduce chain

-
map rerank chain

-
refine chain
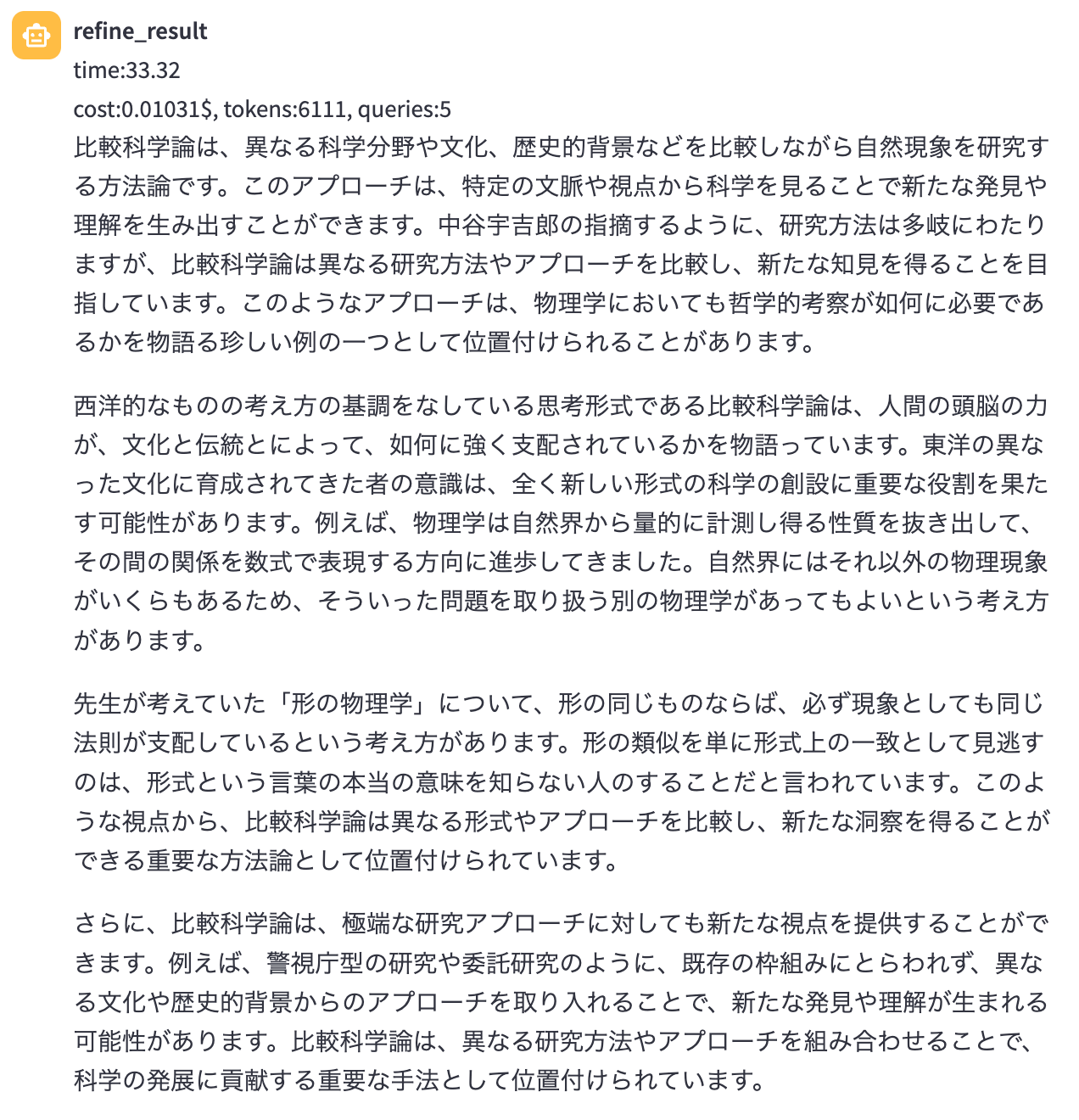
また, 生成時間と使用API料金についての表は以下の通りとなりました。
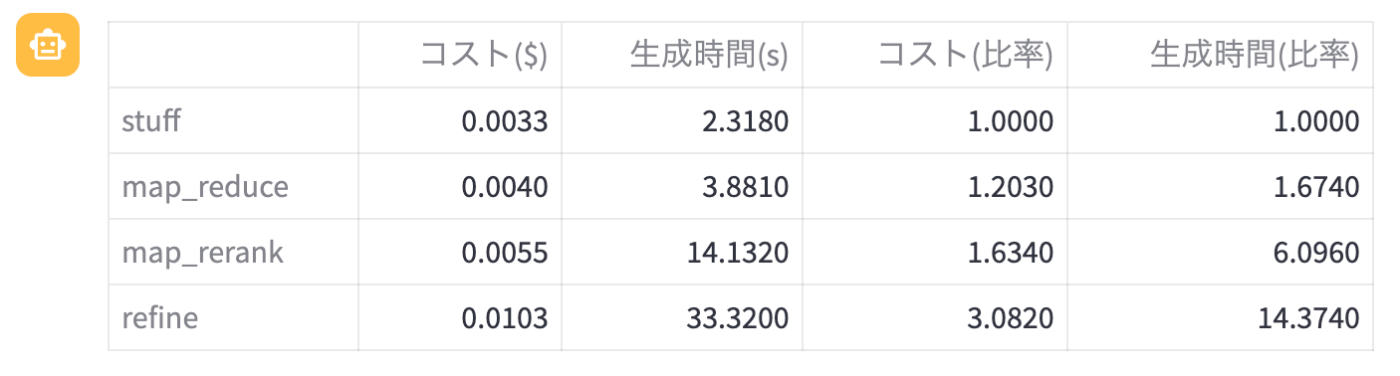
性能比較
まず, 以上の実験で得られた結果をパフォーマンスごとにまとめると以下の表の通りとなります!
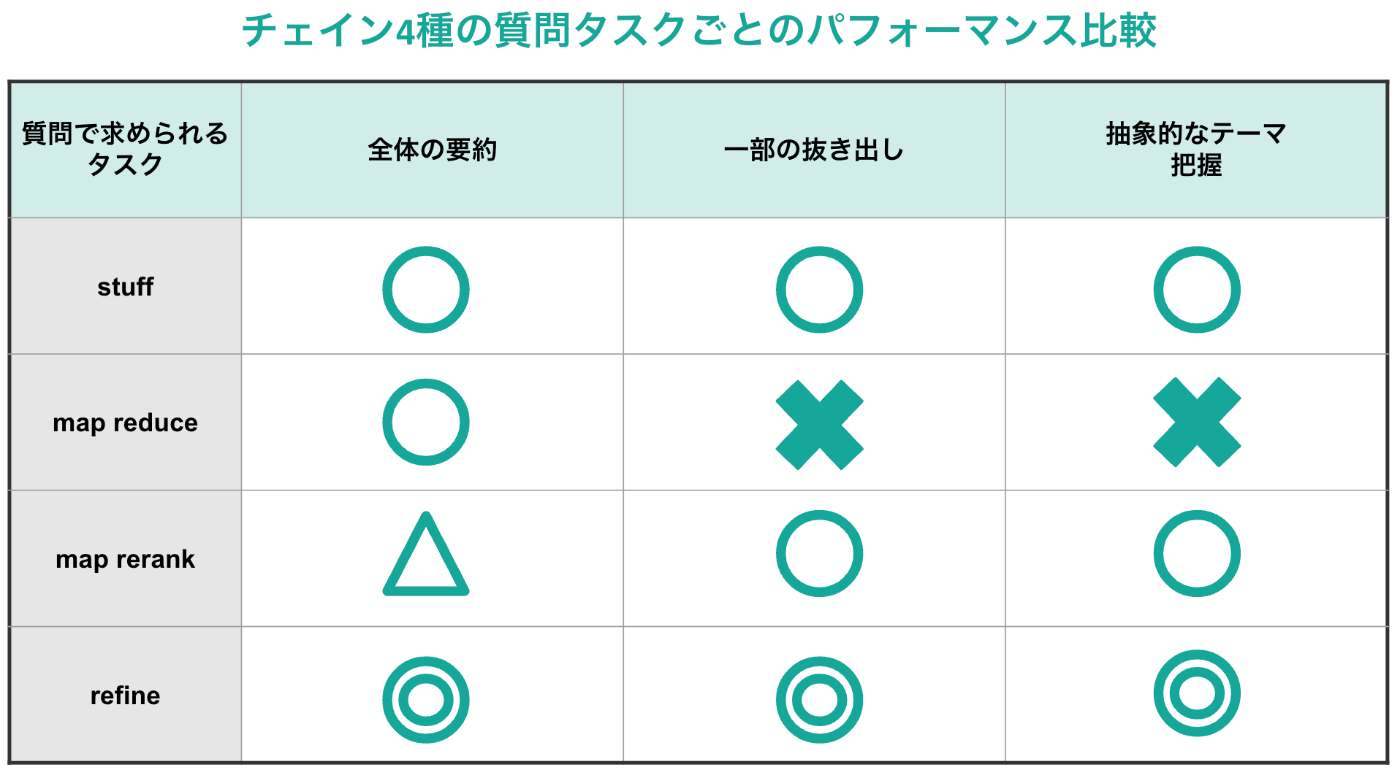

次に, 実験で得られたAPI料金によるコスト生成時間をまとめると以下の2つの表の通りとなります! (どちらもstuff chainを基準にした際の比率です)
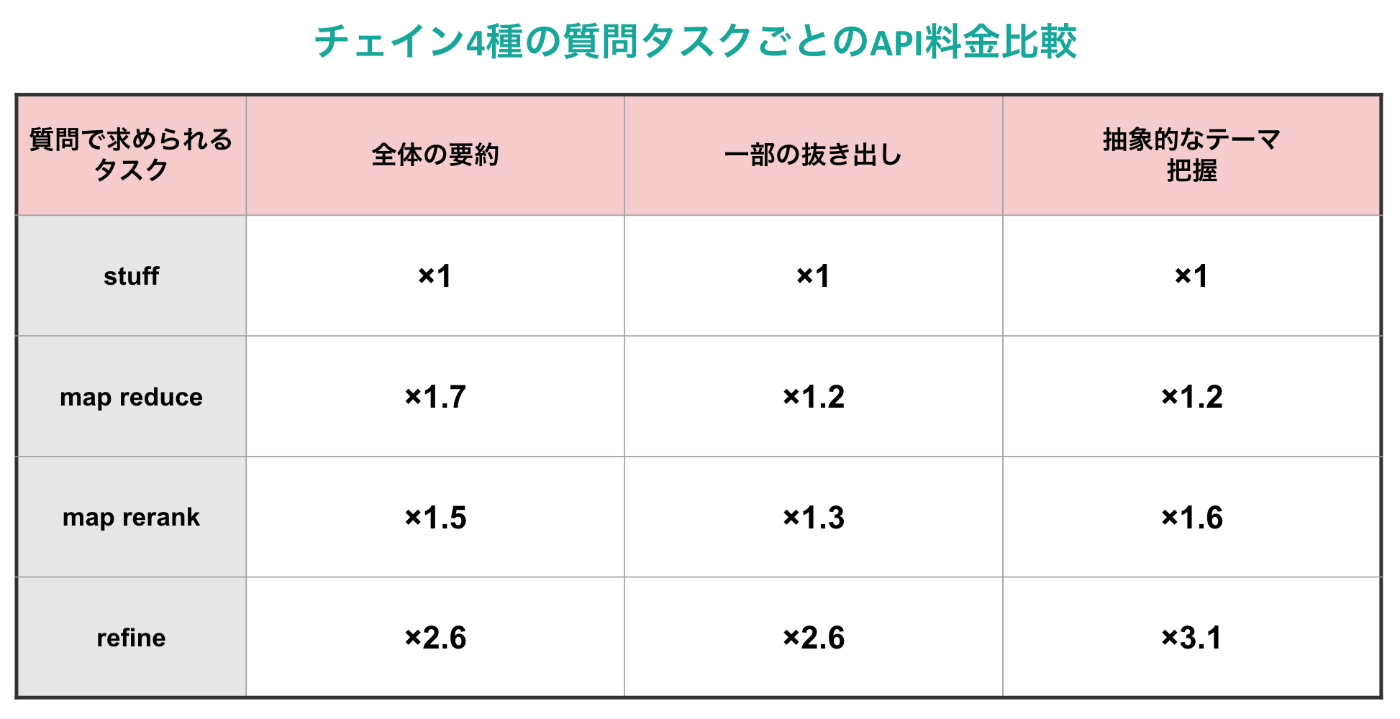
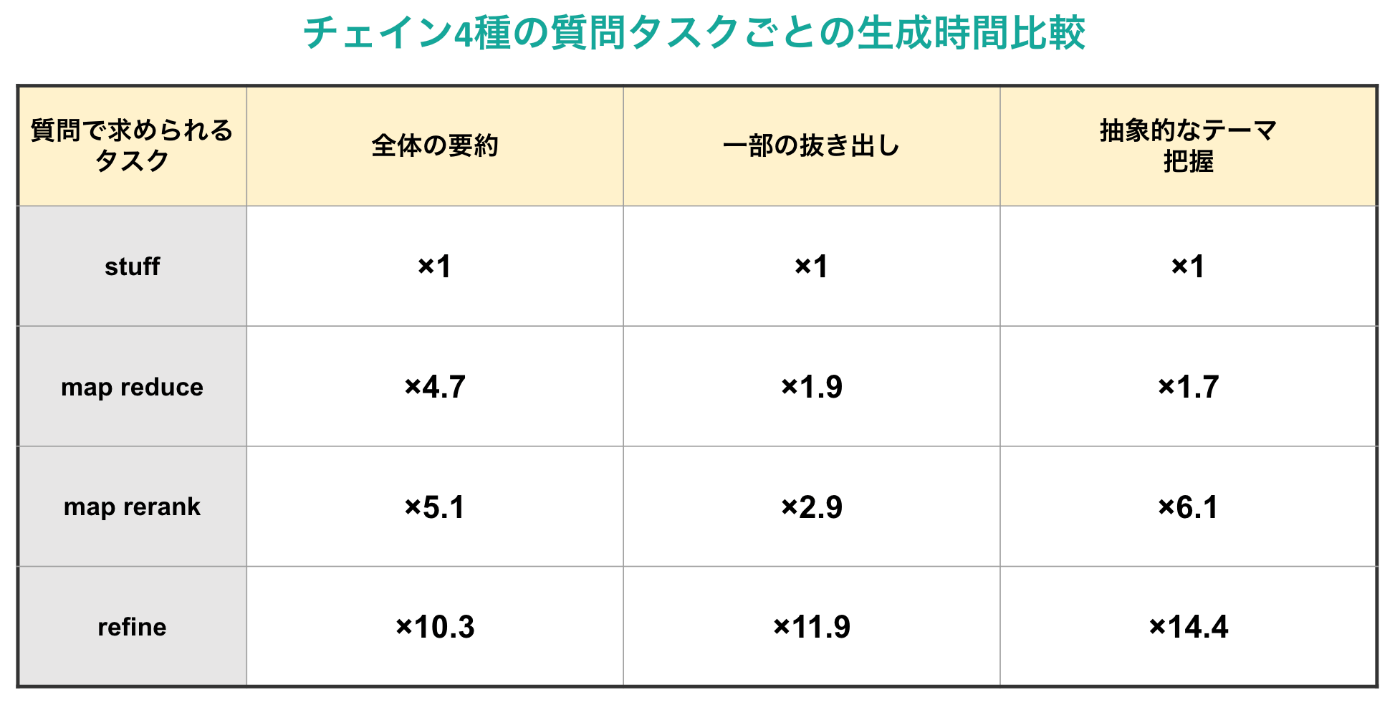
以上の表を見比べると, パフォーマンス観点では圧倒的にrefineが優れているということがわかると思います。一方で, API料金・生成時間の点ではrefineは劣っているため, この部分のトレードオフをユースケースごとに考えることになりそうです。また, map系2種に関してはパフォーマンスにて得手不得手がはっきりと分かれる部分も実際に使用する際には参考になりそうです。
おわりに
今回は, LangChainを用いた4種類のchainについて外部からの文書をもとに入力された質問に応答する形式で実装を行い, 複数の質問の種類について実験を行いました! 結果としては各chainごとにかなり大きな違いがあることがわかっていただけたと思います。
また, 実装面ではLangChainのライブラリが更新の大きな節目にあるということもあり今後動かなくなってしまうことがあるかもしれませんが, GitHubリポジトリは適宜アップデートしていく予定です。
少し長くなってしまいましたが, 最後までお読みいただきありがとうございました!

Discussion
とても参考になります。機械学習のboostingの概念を応用した感じでしょうか。早速、仕事でも活かしてみようと思います。
評価の部分、わかりやすくていいですね!