はじめに
少し前に「プログラマー脳 ~優れたプログラマーになるための認知科学に基づくアプローチ」という本が話題になっていました。
個人的にとても興味深い内容であり、
かつ日頃のタスクに活かせそう!と感じるポイントが多かったため
自分の整理も兼ねて記事にしたいと思います。
この記事で取り扱う範囲
本書では認知科学の側面から見て、プログラムがなぜ難しいか?といった説明や、
プログラムを効率的に理解するためのtips、
より効率的にコーディングをするためのアクションや具体例が豊富に示されています。
この記事では、「脳の負荷を減らす」というポイントに絞って
執筆していきたいと思います。
脳内の3つのプロセス
まずはじめに、プログラミングをするときに脳内ではどのような処理が行われているかを整理したいと思います。
私たちがプログラミングを行うとき、脳内では「短期記憶」「長期記憶」「ワーキングメモリ」の
3つのプロセスが動いています。
それぞれの役割としては
- 短期記憶: 入ってきた情報を一時的に保持する
- 長期記憶: 長期間の記憶の保持
- ワーキングメモリ: 情報の処理
のようになっており、それぞれ関連しながら処理を行っています。
図で表現すると下記のようなイメージになります。
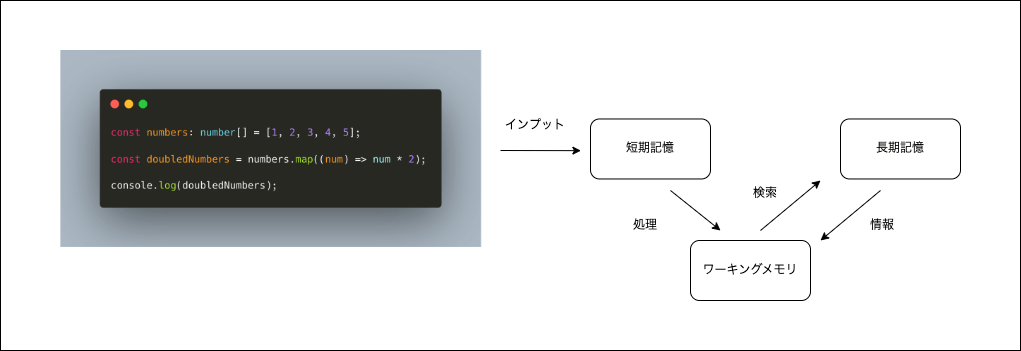
例えば、配列の各要素を2倍にする
const numbers: number[] = [1, 2, 3, 4, 5];
const doubledNumbers = numbers.map((num) => num * 2);
console.log(doubledNumbers);
というプログラムがあった場合、
まず変数名や型、処理の流れなどを短期記憶に取り込みます。
次に、ワーキングメモリでは短期記憶にインプットされた情報を元に、
コードの内容を脳内で処理していきます。
その際、長期記憶から「mapとは〜xxx」や「for文とは〜xxx」という記憶を検索し、
検索結果を元にコードの挙動を再現します。
このように、脳内では「短期記憶」「長期記憶」「ワーキングメモリ」を組み合わせることで、
プログラミングを行っています。
なぜ脳の負荷を下げる必要があるのか?
前述の通り、脳内では「短期記憶」「長期記憶」「ワーキングメモリ」の3つのプロセスを組み合わせながら、プログラミングを行っています。
この3つのプロセスはPCで例えると、
- 短期記憶: メモリ
- 長期記憶: ストレージ
- ワーキングメモリ: プロセッサ
となり、それぞれのスペックが高ければ、より高性能なPCと表現することができそうです。
つまり、プログラミングの熟達者はこの3つのプロセスのスペックが高い、もしくはそれぞれを効率的に活用しているため、初学者より早く読み書きを行える。一方で、初学者はこれらのプロセスの能力が不足しているため、適切に情報が処理できずに時間がかかってしまうと言えます。
それぞれのプロセスの能力不足としては、
- 短期記憶
- 情報不足
- 変数の中身や、依存関係がわからなくなる
- 長期記憶
- 知識不足
- その処理が何をやっているのか知らない
- ワーキングメモリ
- 処理能力不足
- 実行される処理が脳内で追いきれない
のような影響が考えられます。
また、ワーキングメモリには処理結果を長期記憶に戻す役割もあり、
このときにかかる負荷を「 学習関連負荷」 と呼びます。
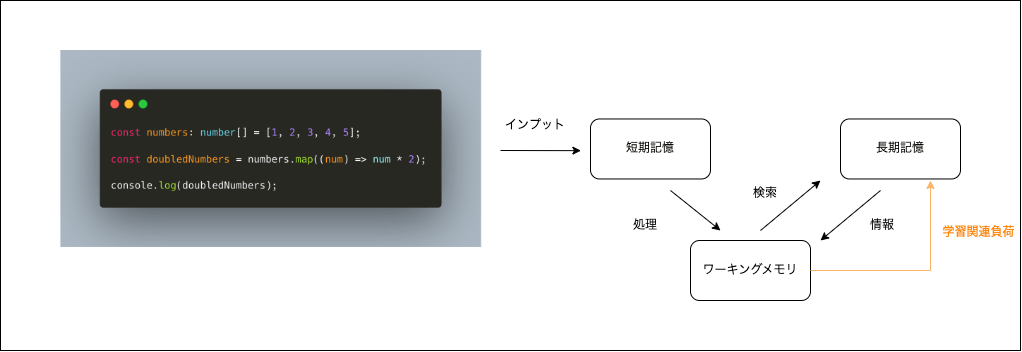
「負荷」と付く通り、処理結果を長期記憶に戻すにはワーキングメモリのリソースを消費します。
言い換えると、負荷が高い状態では学習関連負荷にかかる余裕はないため、
「何をやっていたのかわからなかった」「やったことはあるけどすぐ忘れちゃった」という状態に陥ります。
脳の負荷を下げる理由をまとめると、
- より深く早くコードを読み/書きするため
- 学習関連負荷の余裕を作り、新たな知識を効率的に覚えるため
になります。
2つ目の言語はなぜ簡単に習得できるのか?
プログラミングをしているとよく
「1つの言語を覚えると、2つ目以降の言語が覚えやすくなる」ということを耳にしますが、
これは1つ目の言語の内容が長期記憶に保存されているためです。
新しい言語のコードを読んだときに長期記憶を検索し
「あの言語でいうこういう機能か」と関連付けることができるため、
結果的にワーキングメモリの負荷を減らすことができます。
このように、ある知識が別の領域の知識と結びつくことを 転移 と呼びます。
コードを読む時の負荷を減らそう!
ここからが本題になります。
コードを読む時に脳内の負荷を減らすためのtipsとして紹介されていたものの中で、
いいなと思った部分をいくつかご紹介します。
まずは全体をスキャンする
コードを読み始める際に、まずは全体になんとなく目を通しながら長期記憶のウォーミングアップをします。
こうすることで、
- 長期記憶にある情報と関連付けながらコードを読むことができる
- 長期記憶の情報と照らし合わし、「重要な部分はどこか?」が理解しやすくなる
といったメリットがあります。
フォーカルポイントを見つける
フォーカルポイント とは、コードの起点となる場所のことで、
main関数や、イベントハンドラ、ライフサイクル系のメソッドなどが挙げられます。
コードのフォーカルポイントから少しずつ読み進めていくことで、
短期記憶の負荷を下げつつ、コードの理解を進めることができます。
ビーコンを残す
コードを読み進めながら、コメントやメモを残していくことで、
「あぁ、なるほど」というポイントを作ることができます。
また、ビーコンを残すことで、ある程度の処理を一つの塊として チャンク化 することができるので、短期記憶やワーキングメモリの負荷を下げることができます。
依存関係を図に書き起こす
依存関係を図にすることで、処理の流れを視覚的に理解しながら読み進めることができます。
本書の中では、「ソースコードを紙やPDFとして印刷して、直接メモしながら読み進める」という方法がおすすめされていました。
具体的には、どの変数がどこで参照されているかや、この関数はどこから呼ばれているかを
線で繋げるなどの方法が書かれていました。
メンタルモデルを意識する
依存関係を図にすることと似ていますが、
メンタルモデル を意識することも重要です。
メンタルモデルとは、「頭の中で利用するモデル」のことであり、
物事の予測、推論、説明をするのに非常に役立ちます。
メンタルモデルの具体例については下記の通りです。
例)ファイル
- 実際:0と1で表現されたデータ
- メンタルモデル:FinderやExplorerで確認できる構造的なデータ
例)HTMLの木構造
- 実際:ある要素を参照している要素の集合
- メンタルモデル:あるノードの子ノード
リファクタリングしながら読む
コードを読み進めていくうえで、「ここは理解しづらいな、、」という部分は、
リファクタリングしながら読むことで、負荷を減らすことができます。
例えば、Pythonのlambda関数を使った
numbers = [1, 2, 3, 4, 5]
doubled_numbers = list(map(lambda x: x * 2, numbers))
print(doubled_numbers) # [2, 4, 6, 8, 10]
というコードが読みづらければ、
その部分を
numbers = [1, 2, 3, 4, 5]
doubled_numbers = []
for num in numbers:
doubled_numbers.append(num * 2)
print(doubled_numbers)
のように置き換えながら読み進めることができます。
コードを書く時の負荷を減らそう!
続いて、コードを書く際の負荷についてです。
コードを書く際のtipsとしては、下記のようなものが紹介されていました。
チャンク化を意識する
「ビーコンを残す」にも登場しましたが、ある程度のまとまりとして
チャンク化されたコードを書くことで、読み返す際の負荷を下げることができます。
一般的に、短期記憶で覚えられる数は±7(マジックナンバーセブン)までとされており、
これを超える場合は短期記憶の負荷を高めることにつながります。
チャンク化の具体例としては、
- 処理を関数に分割する
- 変数名を長くしすぎない
- デザインパターンを活用する
などが挙げられます。
先にやることを書き出す
コードを書きながら考えるという場面はよくあるかと思いますが、
これからやることをコメントとして書き出した上でコードを書き始めることで、
「今やろうとしていること」に集中することができます。
その結果、「次は何をするんだっけ」という中断がなくなるため、
実装スピードを早くすることにもつながります。
中断時にすぐに戻れる準備をしておく
本書の中で紹介されていた研究によると、
一度作業を中断してから、再び集中してコーディングをするのに約25分ほどかかるそうです。
自分が何をやろうとしてたか思い出す時間をなるべく減らすために、
「中断時にあえてコンパイルエラーが出るようにしておく」というテクニックが紹介されていました。
また、何を考えていたかをメモやコメントに残しておくことも有効です。
長期記憶を強化しよう!
長期記憶を強化することは、新たな分野の学習時の転移に繋がったり、
ワーキングメモリの負荷を下げることにつながります。
長期記憶の強さ
長期記憶の強さとしては、
- 貯蔵強度:どれだけきちんと長期記憶に保持されているか
- 検索強度:思い出す手掛かりがどれくらいあるか
の2つの強度で測ることができます。
貯蔵強度は一般的に増加する一方ですが、
検索強度は年月がたつにつれ低下していくと考えられています。
学校のテストなどで、「ここ勉強したはずなのに、、!」や 「解説読んだら思い出したぁ!」となるのは、
検索強度が弱いため、「覚えてはいるけど、思い出せなかった」状態であると言えます。
検索強度は、「繰り返し意識して取り出す」ことで強化することができます。
繰り返し意識して取り出すことで、記憶が海馬から大脳新皮質と呼ばれる場所に移り、
脳に取って「これは重要な記憶だ」と認識させることができます。
繰り返す頻度についてですが、僕の好きなアウトプット大全によると、
2週間に3回以上という目安がいいようです。
精緻化
また、上記の2つの強度に加えて、精緻化 も重要になります。
精緻化とは、「学んだばかりの情報について考え、振り返る」プロセスのことで、
- 新しく学んだことについて考え
- 既存の記憶と関連付けをし
- 既に保存されている脳内のスキーマに適合させる
ことで、関連する記憶のネットワークが強化され、検索強度を高めることにもつながります。
おまけ
本書の中では、依存関係を図にするにあたり、
ソースコードを紙に印刷する、もしくはPDFとして出力し、
直接メモを書き込む方法が紹介されていました。
ただ、個人的にはソースコードを紙で印刷するわけにはいかないよな、、
という思いがあり、いい感じに依存関係を表現できるツールを探してみたところ
「Obsidian」というツールを見つけました。
マークダウンや、手書きでメモしたものに対してリンクを貼れたり、
グラフビューで表示できたりするので、
コードを整理するのに役立ちそうです。
おわりに
今回はプログラマー脳 ~優れたプログラマーになるための認知科学に基づくアプローチを読んで、実践に活かせそうな部分をまとめてみました。
今回紹介した部分以外にも、「なるほどなぁ!」と学びを得られる箇所がたくさんあったため
機会があれば別の記事で整理したいと思います。

Discussion