はじめに
この記事は、 Aidemy Advent Calendar 2022 の19日目と、 Kaggle Advent Calendar 2022 の21日目にクロスエントリーさせていただいた投稿です。
(本当は別々の記事を書く予定でしたが、時間の都合上叶いませんでした...。反省。😢)
みなさま、いかがお過ごしでしょうか。 Kaggle Contributer のざっしーと申します。

先日11/29に閉幕したKaggleコンペティション Feedback Prize - English Language Learning (通称Feedback3)の Winning Solution を寄せ集めて、目立ったものを試してみました。
この記事では、精度向上に一般的に効きやすいであろう手法を発見して、いい感じに共有できればと思います。
コンペ全体の解説や、戦い方の反省だったり懺悔だったりは、既にこちらに書いていますので、暇なときにポエム感覚でお読みいただくと面白いかもしれません。
本記事作成に使用したコード全体はこちらに置いています。 Readme など全然書いておらずですみません。参考まで。
対象読者の方々
こんな方に向けて書いています。
- Feedback3コンペに参加しており、振り返りをしたい方
- 最近のNLP手法に興味がある方
- Winning Solution 読んだけど、コードベースでも知りたい!という方
- 強くなりたい方

強くなりたい方 画像ソース
やったこと
Discussion の Winning Solution たちを読み漁って、以下4つの手法を試してみました。
詳細な実験結果は後述しますが、効果があったもの、無かったもの、どちらもありました。
- 連続する改行
\n\nを特殊トークンに置換 - 文章の先頭に、各目的変数予測用のトークンを設置し、そのトークンの出力を用いて回帰
- 目的変数ごとに、損失関数を重み付け
- Pseudo Label (疑似ラベル) データで事前学習
結果
結局、どの手法がどれくらい効果があったのか、最初に見せちゃいます。こんな感じでした!
| index | 工夫点 | CV | Public LB | Private LB |
|---|---|---|---|---|
| 0 | Baseline | 0.458 | 0.441 | 0.443 |
| 1 | 特殊トークン [PARAGRAPH] 導入 | 0.456 | 0.440 | 0.442 |
| 2 | 各目的変数予測用のトークン設置 | 0.456 | 0.440 | 0.439 |
| 3 | 損失関数に重み付け | 0.459 | 0.443 | 0.444 |
| 4 | 疑似ラベル | 0.457 | TBC | TBC |
(疑似ラベルのLBスコアのみ、Submitが完了したら追記します!なぜかモデルがアップロードできず...。)
スコアとしては、番号 1 と 2 の手法が最も改善量が大きいと言えます。とくに、 2 の手法は Private LB でよく効いていますね。(これに関しては結果論でしか無いのですが。)
概ね、CVスコア、 Public LB 、 Private LB スコアの全てがよく相関しており、バリデーションを盤石に行うことができていれば、見通しの立てやすいコンペだったと言えます。
とはいえ、優勝チームの Private LB スコアは 0.433 程度です。上述の手法を高水準で組み合わせて、更にモデルも大規模なものを使用し、複数モデルのアンサンブルを行って、更に細かい改善も行って、やっと辿り着けるラインなのかなと...。頭が上がりません。
ちなみに、Baselineモデルの基本的な情報は以下のとおりです。
ほとんど、Y.Nakama氏の神ベースラインFB3 / Deberta-v3-base baseline [train]を踏襲しています。
- Backbone: DeBERTa V3 Base
- Pooling: MeanPooling
- Optimization: AdamW
- Loss Function: SmoothL1
- LR Scheduler: Cosine (num_cycles=0.5)
- epochs: 4
- LR: 2e-5
- batchsize: 4 (accumulate_grad_batches=4)
実験の詳細解説
以下、今回試した手法を1つずつ、詳細に解説します。
1. 連続する改行 \n\n を特殊トークンに置換
この置き換えは、 HAKUBISHIN3氏の 4th place solutioin をはじめ、上位勢の多くが採用していたテクニックです。ほぼ確実に効果が出ている前処理と言えるでしょう。
というのも、今回データセットとして与えられていた文章では、文章内にいくつかの段落が存在し、その前後で話題やメッセージの切り分けが行われていました。段落の分割は、2連続の改行 \n\n で行われているサンプルが非常に多いです。そのため、2連続の改行 \n\n を [PARAGRAPH] みたいな特殊トークンに置き換えると、モデルとしては文章が読みやすくなるのでは?という算段ですね。6つの目的変数の中でも、 grammer, conventions のスコアの予測で、精度の改善幅が大きかったです。
2連続の改行による話題の分割は、↓こんな感じで空白行ができるので、視覚的に話題の変化を読み取れます。直感的なソリューションですね。
実装方法は様々かと思いますが、CHRIS氏の 3rd Place Solutionで紹介されているとおり、 \n\n を特殊トークンではなくパイプ記号 | に置き換えてしまう方法が、最もシンプルかと思います。訓練データには、 | が使用されている文章は存在しなかったので、「段落の切り替え時に現れる特有の文字」として解釈できるわけですね。 [PARAGRAPH] みたいな特殊トークンを導入する場合、 Tokenizer に特殊トークンの情報を渡さなくてはならないため、ほんの少しだけ実装の手間がかかったりします。
もちろん、テスト用データに | が使用されていない保証はないので、 [PARAGRAPH] みたいな特殊トークンを導入するのが最善だと思います。時間がないときにはこういう方法もあるのだなぁと勉強になりました。

本心ワイ「実際、小論文でパイプ | 書く奴にゃロクな点数は付かんやろ」 画像ソース
2. 文章の先頭に、各目的変数予測用のトークンを設置し、そのトークンの出力を用いて回帰
この手法も、GEZI氏の 2nd solution (back-translation & rank-loss) をはじめ、多くの上位勢が使用していました。
これもシンプルながらに、ほぼ確実に効果があったと言える手法です。説明は、GEZI氏の以下の説明が端的でわかりやすいでしょう。
1. Let bert deal with the target relation
"[CLS] cohesion syntax vocabulary phraseology grammar conventions text [SEP]“
Each target output emb with 1 unique fc added to predict target value.
(日訳・解説)
1. BERT に、目的変数同士の関係を扱わせる。
"[CLS] cohesion syntax vocabulary phraseology grammar conventions text [SEP]“
文の冒頭にこれを挿入し、これら6つのトークンの出力をそれぞれ独立した全結合層に入力し、目的変数を予測する。
ポイントはやはり、目的変数同士の関係性を、BERTに扱わせるという点です。
ベースラインモデルでは、BERTモデルに行ってもらうのは特徴抽出のみでした。得られた特徴から、6つの目的変数全てを予測するのは、独自で追加する全結合層の役割です。(無論、内部ではそうなっていないかもしれませんが。)
しかし、今回のデータセットは、全ての目的変数同士に強い相関があり、目的変数同士の関係性も含めて学習を行うのが1つのポイントでした。であれば、独自で追加した全結合層にここを任せるよりも、言語を扱う能力に長けているBERT部分にまとめて任せてしまったほうが良い結果が出やすいのは、妥当な結果かもしれません。
この手法は、言語のコンペであればかなり広く応用できるテクニックだと思います。言語以外のコンペでも、「学習済みモデルにこういう部分も扱わせることは可能か?」のような発想は、役に立つことがあるかもしれません。今後も積極的に使っていきたい知見ですね。

ああーもうそんなポンコツ(目的変数同士の関係)... DeBERTa V3 に任せろ。 画像ソース
3. 目的変数ごとに、損失関数を重み付け
この手法は、CHRIS DEOTTE氏の3rd Place Solutionで紹介されています。端的に言うと、予測する6つの目的変数1つひとつに対し、損失関数の重み付けをしています。
各目的変数につけられた重みは以下の通りで、合計で1になるように調整されています。ポイントとして、予測が困難な目的変数であるほど、大きな重みが付けられています。
{'cohesion':0.21, 'syntax':0.16, 'vocabulary':0.10, 'phraseology':0.16, 'grammar':0.21, 'conventions':0.16}
残念ながら、今回試した改善案の中では、この手法のみ精度の向上が見られませんでした。大きな重みがつけられた cohesion は、0.001程度のみRMSEが小さくはなっていましたが、そのぶん小さな重みが付けられた目的変数の予測精度が落ち、結果はむしろ少し悪いくらいです。
個々の重みを細かく調整することにより、精度の向上が狙える可能性もありますが、今回はやめておきます。
また、直感的には「そもそも予測誤差の大きい目的変数に対しては、損失関数の値自体が大きくなっているので、わざわざ損失関数に重み付けをする必要はないのかも?」とも思っています。もしご知見のある方いらっしゃれば、アドバイスいただけますと幸いです。
今回の損失関数の実装は以下のとおりです。イニシャライザに引数として、 target_weights を渡しています。
import torch
import torch.nn as nn
class WeightedSmoothL1Loss(nn.Module):
def __init__(self, beta: float, target_weights=[0.21, 0.16, 0.10, 0.16, 0.21, 0.16]):
"""
https://github.com/facebookresearch/fvcore/blob/main/fvcore/nn/smooth_l1_loss.py
"""
super().__init__()
self.beta = beta
self.target_weights = torch.Tensor(target_weights).cuda()
def forward(self, pred, target):
if self.beta < 1e-5:
loss = torch.abs(pred - target)
else:
n = torch.abs(pred - target)
cond = n < self.beta
loss = torch.where(cond, torch.pow(0.5 * n, 2) / self.beta, n - 0.5 * self.beta)
loss = torch.sum(loss * self.target_weights)
return loss
コードの大部分はfacebookresearchのコードから引用してきていますが、読みにくかったらすみません。
4. Pseudo Label データで事前学習
今回のコンペで最も多くの上位勢が採用していた手法というと、まさにここで紹介する Pseudo Label (疑似ラベル) による学習データの増量と言えるでしょう。
ちなみに自分もコンペ期間中に試したものの、教科書どおりのリークをぶちかましてお陀仏になった話は前回記事でしています。あのときは、CVスコアは 0.006 くらい向上しました。今回の改善幅の6倍です。恐ろしいですね。
Pseudo Labeling については、数あるソリューションの中でも、 PSI氏の5th place solution で詳説されている「Pseudo Label データを事前学習に使う!」という手法がとても納得感が高いです。上述のスコアは、この方法を採用しています。
全体の流れはこのとおりです。
- 与えられた訓練データでのみ、モデルを訓練
- Feedback1のデータに対して、↑のモデルで推論して疑似ラベルを生成
- この際、今回のコンペの訓練データとの重複は除去する
- 疑似ラベルを用いてモデルを事前学習
- 与えられた訓練データでファインチューニング
- ↑の2〜4の流れを何度か繰り返し、疑似ラベルを与えられた訓練データに近づけていく
ちなみに、上述しているスコアは5.の「2〜4の流れを何度か繰り返す」の手順を踏めておらず、1回きりで生成した疑似ラベルを用いての訓練結果です。上記の手順で疑似ラベルの質を高めるほど、スコアにも良い影響が及ぶと考えられるため、もし時間が取れれば試してみたいところです。
疑似ラベルを付ける対象としては Feedback1 コンペのデータセットが選ばれています。今回の Feedback3 コンペのデータとよく似た小論文のデータで、今回のデータと重複したサンプルを除いても、15,000件ほどのラベルなし小論文のデータが使用できます。
ただ問題として、 Feedback1 コンペのデータセットは、今回の Feedback3 コンペのデータよりも、全ての目的変数に比較的高いスコアが付きがちでした。以下は、CHRIS DEOTTE氏の3rd Place Solutionの画像を拝借しました。顕著にデータセットの分布が異なっていることがわかります。
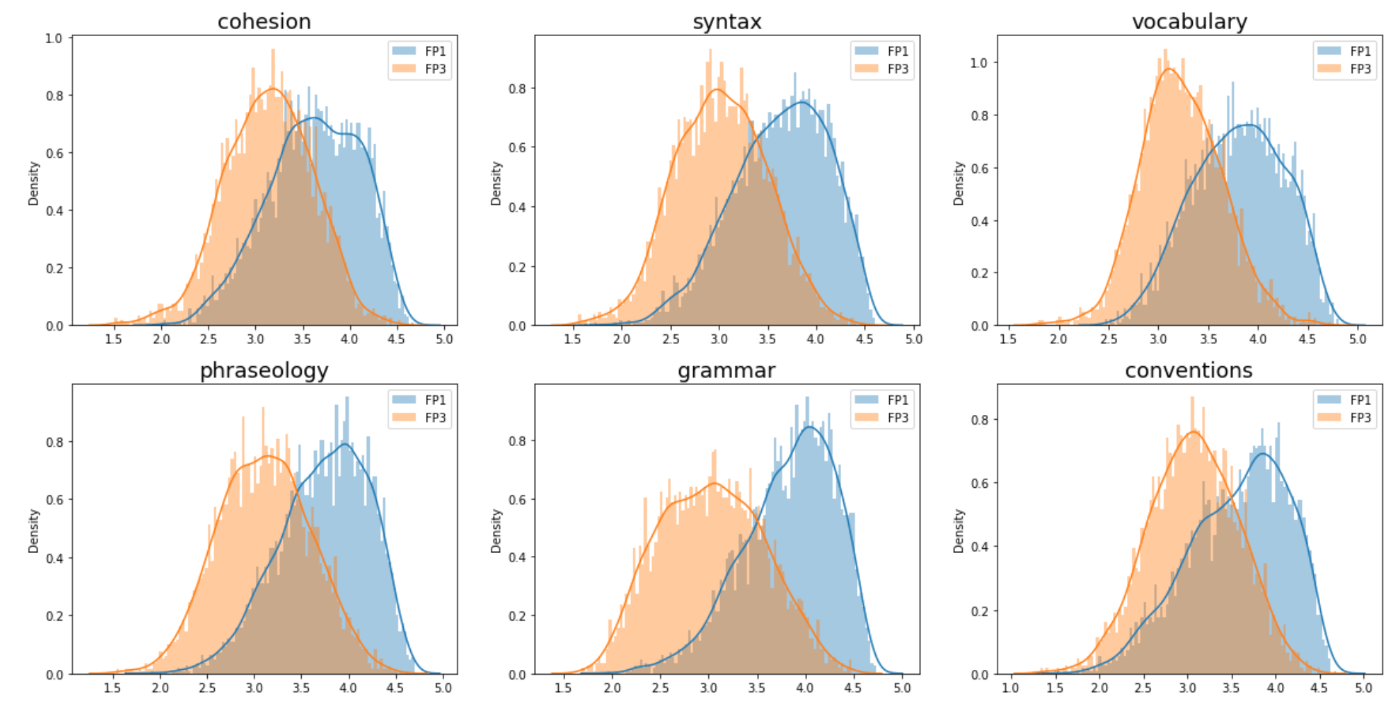
Feedback1、 Feedback3 のデータセットに対し、同一のモデルにより付けられたラベルの分布
そのため、よく疑似ラベルを使った訓練で採用される、「与えられた訓練データと作成した疑似ラベルデータを、完全にシャッフルしてモデルを訓練する」方法は、最終的なモデルの予測値を不必要に上振れさせてしまう危険性があります。
そこで今回の手法では、疑似ラベルはあくまでもモデルの事前学習に使用するのみで、与えられた訓練データによる最終調整はその後で行っています。これにより、モデルの予測する目的変数の分布は、与えられた訓練データのみにフィットするようになる、という算段です。
まさに、Kaggleやっててよかったなーと心から思えるくらい、スッキリとした納得感を覚えたソリューションですね。
とはいえ実際のところ、総データ量が5倍近くにまで増加したにも関わらず、精度に与える影響は僅かでした。上述の通り、疑似ラベルの生成回数を増やしたり、あるいは事前学習の学習率などのチューニングを丁寧に行ったりなど、色々考えられる改善策はあるものの、どこまで極めようとも Pseudo Labeling 一本で勝負が決まることはなさそうです。
また、本コンペのデータを用いての Pseudo Labeling については、 Kaggle Advent Calendar 2022 の23日目の解説も楽しみにできればと思います。(キラーパスすみません。笑)
その他、 Feedback3 コンペから持ち帰るべきもの
以下、ここまでに紹介したソリューションほどに差を生む要因ではなかったと言えるものの、今後の実務やコンペに活かしたいと思った知見をまとめています。
CV戦略
前提として、今回のコンペは公開されたNotebookの多くでCV戦略として MultilabelStratifiedKFold を使用していました。上位勢の多くも、大きく異なるバリデーション戦略は導入していなかったようです。
とは言えその中でも、より盤石にモデルの評価を行うために、「3種類の random_seed により、データの分割パターンを3つにし、3パターン全てのモデルのパフォーマンスの平均値で評価を行う」方法が紹介されていました。
詳細は、PSI氏の5th place solutionで説明されています。(実際は時短のため、もう少し凝って検証しているようですが)
平たく言うと、 seed averaging と呼ばれる手法ですね。
この手法は、精度向上にももちろん少しは寄与しますが、「1つひとつの打ち手をより堅実に評価する」ための工夫として捉えたほうが良いかと思います。
とりわけ、今回のコンペは
- 精度がRMSEで評価される
- データセットのサンプル数が非常に少ない(4000件程度)
のように、バリデーションが不安定になる要素が複数あるので、バリデーションを堅実にするメリットは大きかったと推測できます。
今後、同様にバリデーション結果の信頼性が疑わしいコンペに参加する際には、押さえておきたいテクニックです。
実装は非常に単純で、 Cross Validation の各 Fold のループのさらに1階層上に、 random seed によるループを加えています。
擬似コードで書くと、以下のとおりです。クロスバリデーションを行った結果の oof_score の、Seed毎の平均をとった mean_oof_score を計算し、モデル評価の基準として活用します。
mean_oof_score = 0
for seed in [42, 43, 44]:
for fold in [0, 1, 2, 3, 4]:
# 訓練
# 検証
# seed, fold ごとにモデルを保存
oof_score = evaluation(seed=seed)
mean_oof_score += oof_score / 3
print(mean_oof_score)
言わずもがな、 random_seed を変更してCVの値が良くなったからといって、モデルの性能が上がっているわけではありません。見かけ上は良くなったように見えたとしても、あくまでもデータの分割方法が変わっただけで、モデルに本質的な変化はありません。この記事をここまで読んでくださった方には、釈迦に説法、孔子に論語、河童に水練でしょうが。

とはいえ、それで本当に順位が少し上がっちゃうようなこともあるんでしょうけどね...。 画像ソース
Backbone : DeBERTa V3
基となる学習済みモデルは、多くの公開 Notebook と同様、 deberta-v3-base を用いました。上位勢の解法もほぼ全て、 deberta-v3-base か、より大規模な deberta-v3-large モデルを採用していました。
他の学習済みモデルも試してはみたものの、文章からの特徴抽出においては現状では DeBERTa V3 が第一択と捉えて間違いなさそうです。
精度面でのパフォーマンスは、 large モデルの方が優れているものの、本記事ではひとまず短期間でいろいろな検証を行いたかったため、 base モデルを使用しています。
コンペ期間中でも、
- 細かい検証は訓練に時間のかからない base モデルで回してみる!
- サブミット用など力を入れたいモデルは large で作る!
のように、使い分けていた方も多いと思います。
今後も、言語からの特徴抽出を行う場合、まずはじめに試してみるモデルとして、しばらくは君臨し続けるのではないでしょうか。タスクによっては、「Just use GPT-3」戦略を上回る可能性も、十分にありますからね。
おわりに
以上です。いかがだったでしょうか。
やはりコンペの振り返りって大事ですね。上位勢の Winning Solution も、私のレベルでは、文面で読むだけでは次回のコンペに活かせるか不安なので、ちゃんと実装込みで振り返る時間を取れてよかったと思います。
ではまた、コンペのリーダーボードでお会いしましょう。
あと、弊社はデータサイエンティストを絶賛採用中なので、ご興味あればお気軽にご連絡ください!(データサイエンティスト以外も)
おわり。ちょっと早いですが、


Discussion