こんにちは。
株式会社アイデミーでデータサイエンティストをやっている米倉と申します。
今回はデータ分析を高速化するために、従来のPandasによる実装に加えてDuckDBも併用して高速化を図ってみたのでご紹介します。
BI(ダッシュボード)作った → データ重すぎて動かない問題
データサイエンティストや機械学習エンジニアの代表的な日常業務として、データ分析があります。
データ分析作業を楽にしたり、より良い意思決定に繋げるための考察を得る手段として、BIツール(ダッシュボード)を作ることがあります。
Pythonでダッシュボード的なものを作ろうとした場合、WEBアプリ系のフレームワークがいくつか存在します。
代表的なものとして、私も日々の業務で使っているStreamlitがあります。
Streamlit:
とにかく簡単に作れて、速攻で可視化できるのが、現場のデータサイエンティストには大助かりなツールです。
機械学習との親和性も高く、他のPythonライブラリにも幅広く対応しています。
そんな便利なStreamlitゆえの課題かもしれませんが、ダッシュボード画面がやや重くなりやすいという特徴もあります。
さらに分析対象のデータが容量の大きなものだと、読み込むのに時間がかかったり、起動中にフリーズしてしまうこともよくあります。
またPyGWalkerという、従来のグラフ可視化ライブラリとは少し特徴の異なるものを知ったので、こちらも今後はStreamlitへの導入を検討しようと思っています。
PyGWalkerとは?
ユーザー操作でグラフを作成できるUIを用意してくれるPythonのライブラリです。
公式ドキュメントでも書かれていますが、いわゆるTableu風なツールです。
MatplotlibやPlotlyのように、あらかじめX軸とY軸を決めて表示するようなタイプとは異なり、ユーザーがDataframeからドラッグ&ドロップでX軸とY軸にする列を選択してグラフを作成できます。
このUIはNotebookやStreamlitに埋め込むことが可能です。
コードもとても短く簡単に書けるので、Streamlitに似た特徴があります。
実際使ってみると、Streamlitとの親和性も高そうだと感じました。
見た目もオシャレなので、ダッシュボードにするとカッコいいですよね。
しかし多機能ゆえに、使ってみると処理がやや重い印象でした。
このようにStreamlitと合わせて使ってみたいものの、やはり処理速度の課題は深まります。
DuckDBをPandasと一緒に使ってみよう!
そんな中、私が目をつけたのが「DuckDB」です。
DuckDBがどのぐらい速いのかをベンチマークしたのが以下です。
groupbyやjoinのタスクでの比較になりますが、近年Pandasより速いと評判のPolarsを抜いてトップの速さです。
DuckDBの使い方を調べると、Pandasとも連携良く使えそうなこともわかりました。
というわけで、早速お試しで大容量データに対してStreamlit+PyGWalkerがDuckDBで軽快な動作を獲得できるか検証してみようと思います。
いきなりDuckDBで全て置き換えようとするのではなく、使い慣れたPandasと一緒に無理なく使う方針でやってみます。
開発環境・ライブラリ
以下の開発環境とライブラリで動作を確認しております。
PC:
MacBook Pro(M2Pro 32GB)
ライブラリ:
pandas==2.1.0
scikit-learn==1.3.1
tqdm==4.65.0
streamlit==1.29.0
pygwalker==0.3.17
大容量なダミーデータセットの準備
まずはscikit-learnからToy datasetを使って、とにかく重たいダミーデータセットを準備します。
年末ということもあって(?)、糖尿病の進行状況のデータセットを使います。
(年末年始の食べ過ぎ・飲み過ぎには注意しましょう…)
ダミーデータセットの作成コードは以下です。
import pandas as pd
from sklearn.datasets import load_diabetes
from tqdm import tqdm
diabetes = load_diabetes()
diabetes_data = pd.DataFrame(data=diabetes.data, columns=diabetes.feature_names)
diabetes_data["target"] = diabetes.target
# 約104万行、11列
for i in tqdm(range(13)):
diabetes_data = pd.concat([diabetes_data, diabetes_data], axis=0)
diabetes_data = diabetes_data.reset_index(drop=True)
# 保存
diabetes_data.to_csv("csv/diabetes_data.csv", index=False)
出来上がったデータセットの行数は、エクセルの限界ギリギリの約104万行のデータになります。

ファイルサイズは742MB。
開くのに10秒ぐらい(体感)かかった上に以下のような警告も。
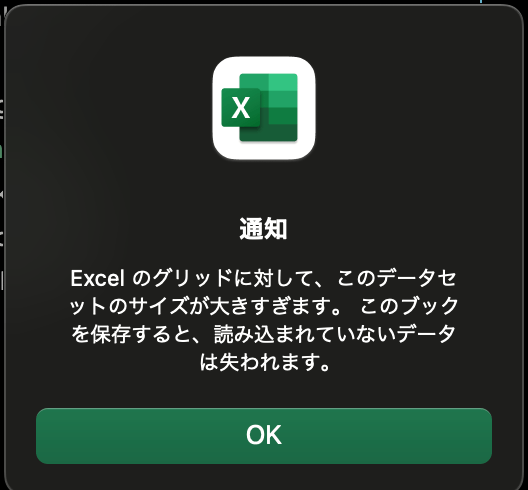
こういうデータを分析することになると憂鬱になります。。
検証ツールの概要
ではこのCSVファイルを分析するツールを作りましょう。
ツールの処理内容は以下です。
- Pandas(またはDuckDB)でCSVファイルを読み込む
- 読み込んだデータをPyGWalkerで分析できるグラフUIを表示する
- 1、2をStreamlit上で表示する
この3ステップを完了するまでの時間を計測します。
パターンとして、1のCSV読み込みをPandasでやるか、DuckDBでやるかで計測します。
この2パターンのコードを記載しますので、計測時間だけでなく、コードの差分にもご注目ください。
Pandasバージョン
Pandasバージョンのコードは以下です。
import os
import pandas as pd
from pygwalker.api.streamlit import init_streamlit_comm, get_streamlit_html
import streamlit as st
import streamlit.components.v1 as components
import duckdb
# 時間計測開始
import time
@st.cache_resource
def get_pyg_html(df: pd.DataFrame) -> str:
html = get_streamlit_html(df, use_kernel_calc=True, debug=False)
return html
# Streamlitページの幅を調整する
st.set_page_config(page_title="AdventCalender2023_Aidemy_yonekura", layout="wide")
# PyGWalkerとStreamlitの通信を確立する
init_streamlit_comm()
st.title("DuckDB+pygwalkerで、データ分析基盤作ってみた")
# 計測開始(pandas)
start = time.time()
read_df = pd.read_csv("csv/diabetes_data.csv")
# BI機能の作成(pandas -> pygwalker)
components.html(get_pyg_html(read_df), width=1300, height=1000, scrolling=True)
# 時間計測終了
elapsed_time = time.time() - start
# 時間を小数点以下3桁まで表示する
elapsed_time = round(elapsed_time, 3)
st.write(f"elapsed_time: {elapsed_time} [sec]")
これを実行すると、以下のような画面が立ち上がります。

PyGWalkerのコードの行数の短さに驚くかもしれませんが、わずか数行でグラフUIが作成できます。
さらにPyGWalker自身にも高速でデータを処理する機能があります。
html = get_streamlit_html(df, use_kernel_calc=True, debug=False)
これは公式通りなのですが、use_kernel_cal=Trueがポイントです。

PyGWalkerにもDuckDBをベースとした内部エンジンがあり、それを有効化できるとのことです。
1GB以上にも対応してるなんて、PyGWalkerすごい!(フラグ)
そしてCSVを読み込んで画面が起動するまでの時間は以下のように表示されます。

4.551sec!
確かに起動するまでに少し待ちました。
割といつものあるあるな遅さを感じるぐらいです。
この時間と体感はDuckDBバージョンと比較するので、覚えておきましょう。
では、PyGWalkerでグラフを作成してみましょう。
あ、、、
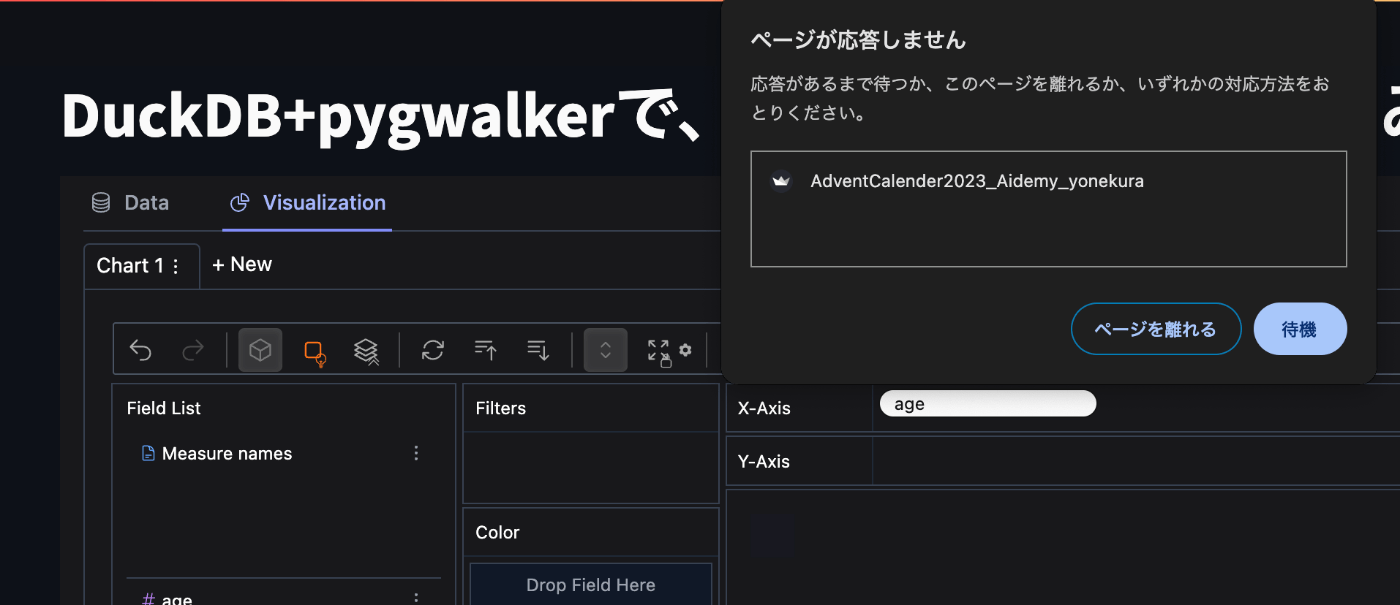
でたー!!これこれ!!これですよ!!現場を悩ませる例のあれ。
あれ、use_kernel_calcさん…?
X軸に「age」を入れただけで潰れてしまいましたよ…?
DuckDBバージョン
DuckDBバージョンのコードは以下です。
import os
import pandas as pd
from pygwalker.api.streamlit import init_streamlit_comm, get_streamlit_html
import streamlit as st
import streamlit.components.v1 as components
import duckdb
# 時間計測開始
import time
@st.cache_resource
def get_pyg_html(df: pd.DataFrame) -> str:
html = get_streamlit_html(df, use_kernel_calc=True, debug=False)
return html
# Streamlitページの幅を調整する
st.set_page_config(page_title="AdventCalender2023_Aidemy_yonekura", layout="wide")
# PyGWalkerとStreamlitの通信を確立する
init_streamlit_comm()
st.title("DuckDB+pygwalkerで、データ分析基盤作ってみた")
# 計測開始(duckdb)
start = time.time()
read_df = duckdb.read_csv("csv/diabetes_data.csv")
# BI機能の作成(duckdb -> pygwalker)
components.html(get_pyg_html(read_df), width=1300, height=1000, scrolling=True)
# 時間計測終了
elapsed_time = time.time() - start
# 時間を小数点以下3桁まで表示する
elapsed_time = round(elapsed_time, 3)
st.write(f"elapsed_time: {elapsed_time} [sec]")
画面の表示は先ほどと全く一緒です。
しかし速い!!起動するまでの速さはすぐに体感できました。
計測時間はどうでしょう。

1.511sec!約3分の1の時間で読み込んでくれました。
ではこの3分の1を実現するために、コードはどのぐらい変化したのでしょう。
その差分はこちら。

DuckDBとPandasでほとんど似たような書きっぷりですね。
このぐらいならDuckDBを使ってみようって気になります。
そして問題はPyGWalkerですが、動くのでしょうか・・?
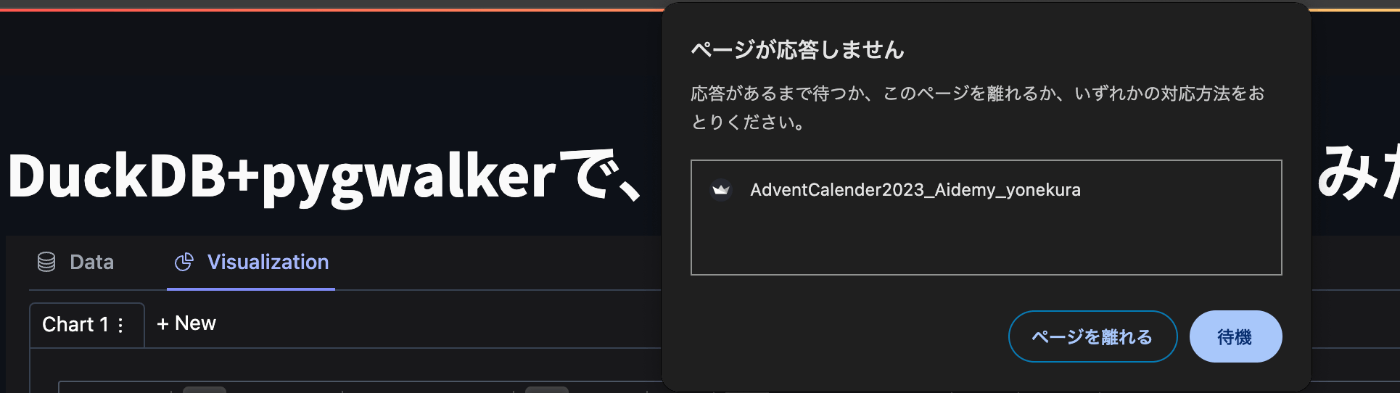
いや変わらんのかい!
こちらもX軸に「age」を入れただけで潰れてしまいました。。
・・・まぁ結局Dataframeに変換してるので、一緒なのはある意味当たり前ですよね。。
1GB以上にも対応できるって書いてたから、1GB以下ならサクサクだろうと期待しましたが、残念。。
あのQ&Aはなんだったんだろう。。
さてこの場合、私ならいつもどうしているかというと、CSVの読み込みには成功しているので、PyGWalkerにインプットするread_dfをPandasで必要な行数を指定してカットする対応します。
この辺もStreamlitのwidgetsで便利なものがあるので、組み合わせてユーザーが設定できるように調整すればOKです。
read_csvはPandasとほとんど同じような記述でかけて、Pandasよりも高速で読み込んでくれるので、今後はDuckDBを少しずつ導入していきたいと思いました。
まとめ
今回はDuckDBを使って、大容量のデータを分析できる分析ツールの作成について紹介しました。
ポイントとして、
- CSVの読み込み速度はPandasに比べて圧倒的に速い
- コードの書きっぷりもPandasに比べて難しくない(馴染みやすそう)
- Streamlit+PyGWalker動かす時でもDuckDBの方が快適さを体感できる
今後は生成AIの開発も盛んになる可能性があるので、分析するデータも膨大なものを取り扱う機会が増えるかもしれません。
BIツールやライブラリは今後も開発が進むと思うので、より良いものを使えるよう情報にキャッチアップしたいですね。
DuckDBのようなツールを上手く使って、快適なデータ分析業務を行なっていきましょう。
データ分析業務を行う人の参考になれば幸いです。
ここまでご覧いただきありがとうございました。

Discussion
この記事が非常に役立ちました。ありがとうございます。
記事内の「PyGWalkerでのグラフ作成」について、使用している
pygwalker==0.3.17を、現時点の最新verの
pygwalker==0.4.9.1に置き換えて試しても、同様の結果になりました。→ダミーデータセット(約740MB)を読み込み、グラフ生成でX軸に「age」入れたら即潰れました。
→現時点でも、PyGWalkerのStreamlit Walker APIsに、カット無しで
700MBぐらい~1GB以上の大容量データをそのままインプットするのは難しそうでした。
試した理由:PyGWalkerの
use_kernel_calcに変更があったためです。use_kernel_calcが非推奨になり、代わりにkernel_computationが登場。https://github.com/Kanaries/pygwalker?tab=readme-ov-file#better-practices
https://docs.kanaries.net/pygwalker#better-practices
https://docs.kanaries.net/pygwalker/api-reference/streamlit#example-of-kernel_computation-enabledrecommend