はじめに
こんにちは。株式会社アイデミーデータサイエンティストの中沢(@shnakazawa_ja)です。
本記事ではFacebook(現Meta)社が開発した時系列データ予測モデル Prophet を取り上げます[1]。
ProphetはAnalyst-in-the-Loopを謳っており、モデルの出力結果を人が見てモデルに介入、改善するプロセスの簡便さを売りの一つにしています。しかし、論文では概念の提案に留まっており、具体的なループの回し方までは触れられていませんでした[2]。そこで、本記事では一度モデルを作った後に、どのように改良プロセスを回すべきかの一例を紹介します。
データセット
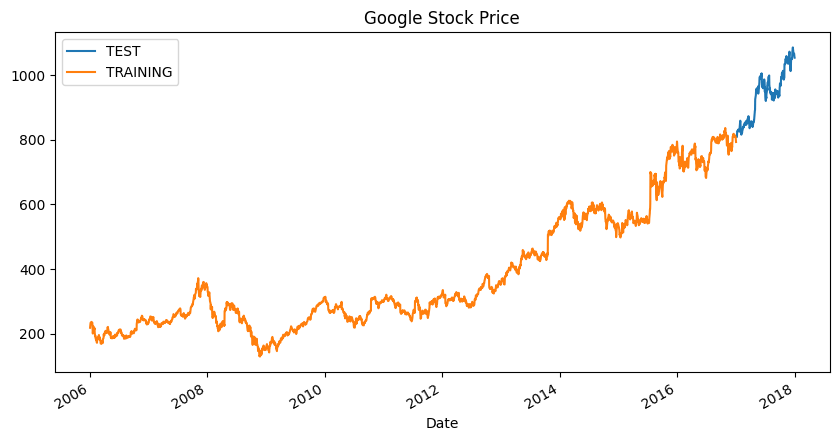
題材としてKaggle - DJIA 30 Stock Time SeriesのGoogleの株価を用います[3]。こちらには2006年1月3日から2017年12月29日までの株価が記録されています。
import pandas as pd
df = pd.read_csv('data/GOOGL_2006-01-01_to_2018-01-01.csv')
df['Date'] = pd.to_datetime(df['Date'])
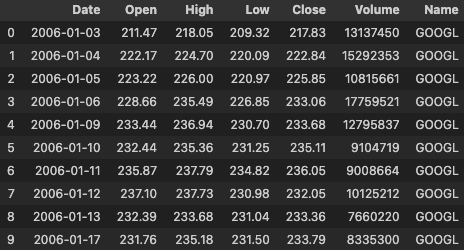
df.head(10)
分析に先立ち、訓練用と推論用のデータを分割しておきます。2006年から2017年のデータを訓練用、2018年のデータを推論用として用いましょう。
df_train = df[df['Date'] < '2017-01-01'][['Date', 'Close']]
df_test = df[df['Date'] >= '2017-01-01'][['Date', 'Close']]
merged_df = pd.merge(df_test.rename(columns={'Close': 'TEST'}),
df_train.rename(columns={'Close': 'TRAINING'}),
on='Date',
how='outer')
merged_df.set_index('Date').plot(figsize=(10, 5), title='Google Stock Price')
Prophetで最初のモデルを作る
データの変形
Prophetへの入力はds(datestamp)とyの2カラムを持ったデータフレームが指定されています。まずは、それに合わせデータの変形を行います。
df_p = df.rename({'Date': 'ds', 'Close': 'y'}, axis='columns') # 後で使うので、train/test全て含んだdataframeも変形しておく。
df_train_p = df_train.rename({'Date': 'ds', 'Close': 'y'}, axis='columns')
df_test_p = df_test.rename({'Date': 'ds', 'Close': 'y'}, axis='columns')
df_train_p.head()
モデルの訓練と予測
データの形式を整えたら、次にモデルに学習と予測を行わせます。
from prophet import Prophet
# モデルの訓練と学習
model = Prophet()
model.fit(df_train_p)
# 予測
forecast_all = model.predict(df_p)
forecast_test = model.predict(df_test_p)
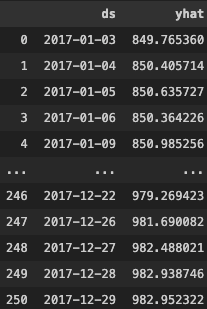
forecast_test

予測値に加え、トレンドや季節性の影響も計算されています。見づらいので予測値のみ抜粋↓
forecast_test[['ds', 'yhat']]
実測値/予測値の比較と定量評価
予測が終わったら、実測値と予測値の比較をしてみます。ここでは指標としてMAPEを用います。
import numpy as np
import matplotlib.pyplot as plt
def mean_absolute_percentage_error(y_true, y_pred):
y_true, y_pred = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
print('MAPE: ', mean_absolute_percentage_error(y_true=df_test_p['y'], y_pred=forecast_test['yhat']))
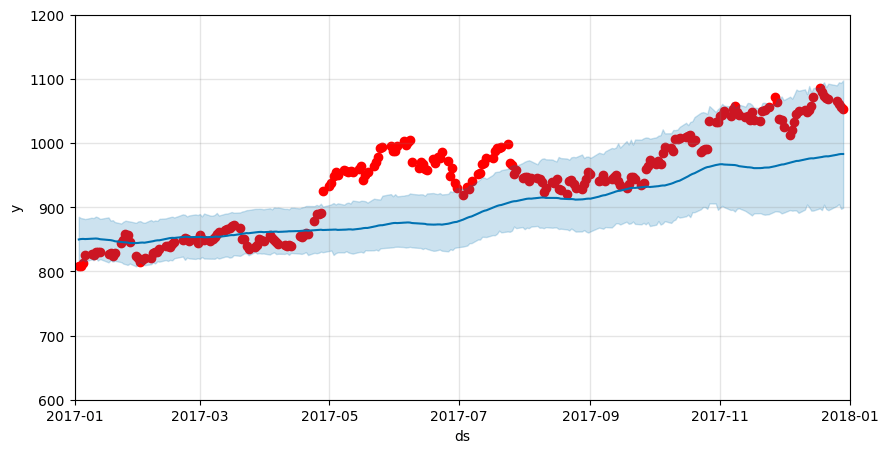
fig, ax = plt.subplots(figsize=(10, 5))
ax.scatter(df_test_p['ds'], df_test_p['y'], color='r')
fig = model.plot(forecast_test, ax=ax)
plt.xlim([pd.Timestamp('2017-01-01'), pd.Timestamp('2018-01-01')])
plt.ylim([600, 1200])
MAPE: 4.971864866382667
トレンドと季節性の可視化
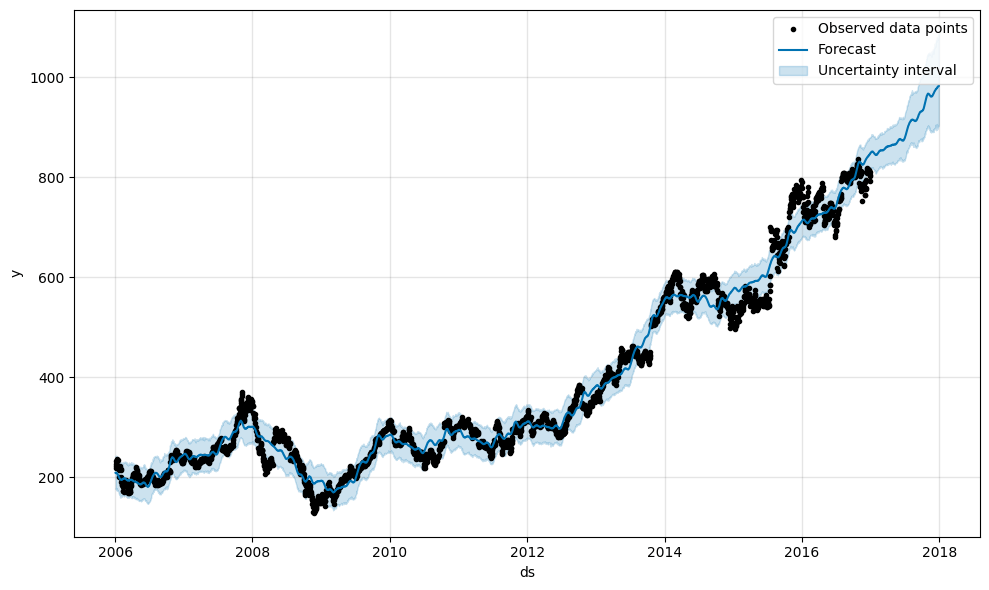
Prophetの強みの一つとして、トレンド (trend) と季節性 (weekly/yearly) の影響の可視化の簡便さがあります。以下の2行で可視化が完了します。
model.plot(forecast_all, include_legend=True)
# uncertainty intervalsはデフォルト80%
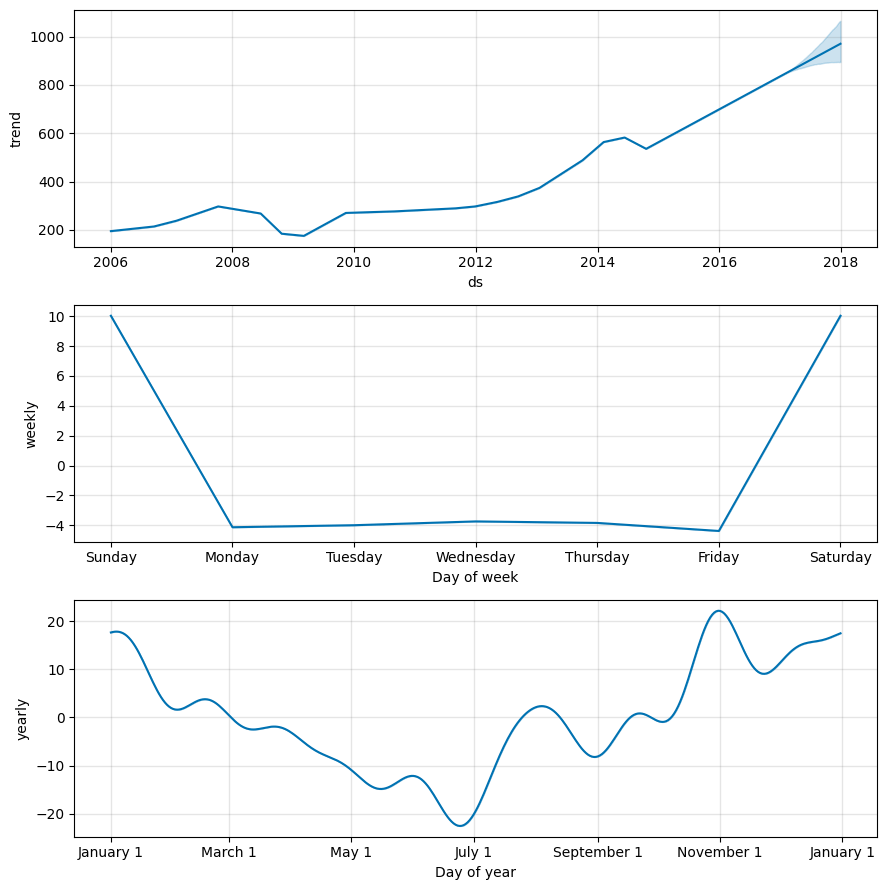
model.plot_components(forecast_all)
ここまでがProphetを用いた分析のワンサイクルとなります。
ここまでの分析だけでも有意義な示唆は多く得られ、それがわずか数行で実現できるProphetは時系列データ分析の第一手として選択肢に上がりうるものだと思います[4]。
本記事ではここからさらに分析を深めて行きます。モデルの出力から精度不足の箇所を探し出し、人の知識を用いた改良を目指します。
Analyst-in-the-Loop
Cross Validationで予測できていない時期を探る
まず、モデルが上手く予測できていない時期を探索します。Prophetではcross_validationを簡単に行える仕組みが整えられていますので、こちらを活用します。MAPEを基準に、大きく外している日付を取り出してみましょう。
from prophet.diagnostics import cross_validation
df_cv = cross_validation(model, initial='365 days', period='30 days', horizon='30 days', parallel="processes")
# initial: 学習に使う最短期間, period: cvごとにどれだけデータを追加していくか, horizon: 予測期間
df_cv['mape'] = (abs(df_cv['y'] - df_cv['yhat']) / df_cv['y']) * 100
df_cv.sort_values('mape', ascending=False).head(10)
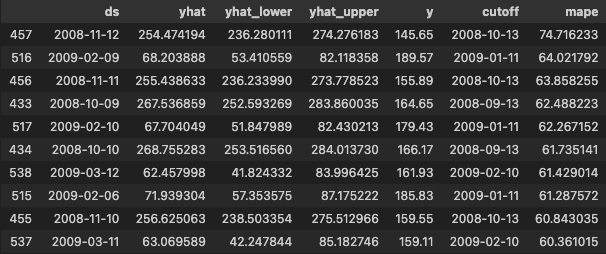
以上より、2008年の10月から翌3月にかけて大きく外しているものが多いことが分かります。何があったかなぁと考えると、
- 2008年9月15日にリーマン・ブラザーズが破綻(リーマン・ショック)
- 2008年11月4日にアメリカ大統領選挙
- 2009年2月にアメリカ復興・再投資法が制定
なんてことがありました。いかにも株価に影響を与えそうですね。これらの情報を人為的にモデルに与えてみましょう。
ある時期に起こったイベントをデータフレーム化する
Prophetでは「休日 (holidays)」としてイベントの影響をモデルに組み込むことができます。
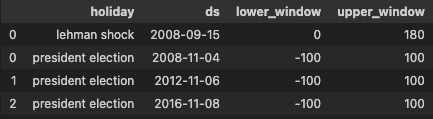
まずはリーマン・ショックから。以下のようなデータフレームを作ります。
lehman_shock = pd.DataFrame({
'holiday': 'lehman shock',
'ds': pd.to_datetime(['2008-09-15']), # イベントが起こった日
'lower_window': 0, # 何日後から影響が出うるか。負の数だと"何日前から"
'upper_window': 180, # 何日後まで影響が出うるか
})
リーマン・ショックの影響はアメリカ復興・再投資法の制定後少し立つまで続いたと仮定し、180日後まで影響が出うるとします。
次いで、大統領選挙について。影響が前後に何日続きうるかは全く知識が無いので、適当に前後100日ずつと設定します。
president_election = pd.DataFrame({
'holiday': 'president election',
'ds': pd.to_datetime(['2008-11-04', '2012-11-06', '2016-11-08']), # イベントが起こった日
'lower_window': -100, # 何日後から影響が出うるか。負の数だと"何日前から"
'upper_window': 100, # 何日後まで影響が出うるか
})
これらを一つのデータフレームにまとめます。
holidays = pd.concat([lehman_shock, president_election])
holidays
そしてモデルに「特別な日」として渡し、再度ループを回します。
イベントの影響をモデルに組み込む
model_with_events = Prophet(holidays=holidays) # holidaysを指定
model_with_events.fit(df_train_p)
forecast_all = model_with_events.predict(df_p)
model_with_events.plot_components(forecast_all)
holidaysの影響だけ抜粋↓
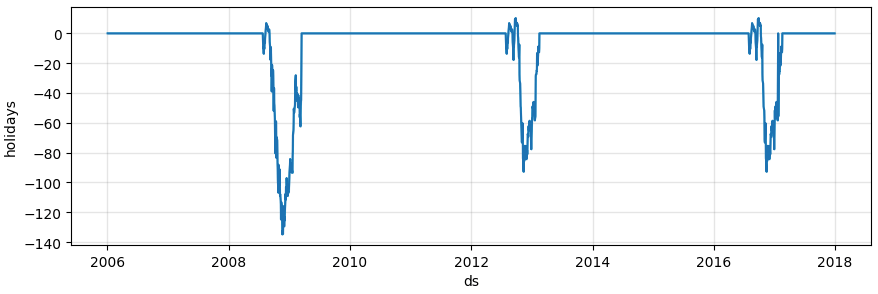
上図より、大統領選挙はGoogleの株価を下げる影響を持っていることが示唆されます[5]。また、2009年はリーマン・ショックも重なり大きな負の影響が出ています。
続いて、これらのイベントの導入が予測結果に与えた影響を見てみましょう。
forecast_test = model_with_events.predict(df_test_p)
print('MAPE: ', mean_absolute_percentage_error(y_true=df_test_p['y'], y_pred=forecast_test['yhat']))
fig, ax = plt.subplots(figsize=(10, 5))
ax.scatter(df_test_p['ds'], df_test_p['y'], color='r')
fig = model.plot(forecast_test, ax=ax)
plt.xlim([pd.Timestamp('2017-01-01'), pd.Timestamp('2018-01-01')])
plt.ylim([600, 1200])
MAPE: 3.30799061249904
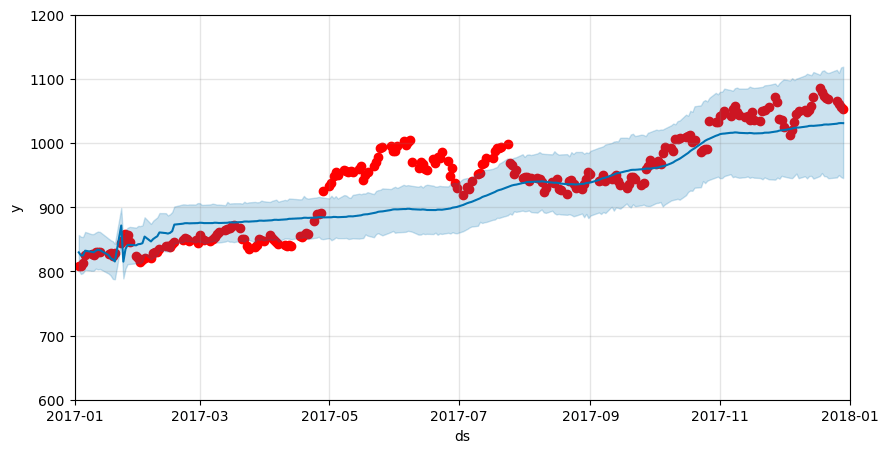
MAPEが4.97から3.31へと大幅に改善しました。すなわち、人の知識の積極的な活用 (Analyst-in-the-Loop) によりモデルの性能が良くなったことを意味します。
未来の予測
最後に未来の予測を行います。せっかくなので(意味があるかは置いておいて)2024年末まで予測してみましょう。
model = Prophet(holidays=holidays).fit(df_p)
future_dates = model.make_future_dataframe(periods=2559) # データの最後の日から2559日分未来の行を追加する。
forecast = model.predict(future_dates)
forecast[['ds','yhat']]
model.plot(forecast, include_legend=True)
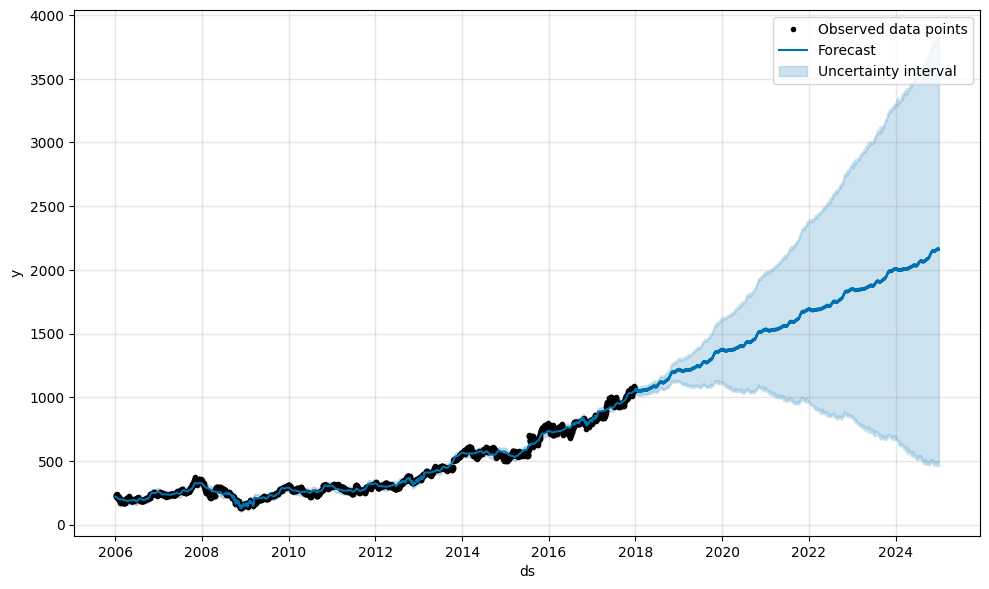
確かに2024年12月31日までの予測値が追加されています。さて、現実の株価はどうなるでしょうね[6]。
さいごに
本稿を通じて、Prophetを使用した時系列予測におけるAnalyst-in-the-Loopアプローチの実践的な応用を紹介しました。
本稿では特別な時期(holidays)として2つのイベントを取り上げましたが。実践では 「この時期は天気が悪かったから不作だった」「競合他社が新製品を出した」「新技術が登場した」「夏休みや年末年始、ゴールデンウィークだった」「covid-19によるロックダウンがあった」 といった要因も予測に影響を与えうるイベントとして考慮すべき対象となってくるでしょう。
また、本稿で取り上げた方法以外にも、トレンドの変化点の抽出や、変化点の人為的設定、Cross validationを用いたハイパラチューニングなどでのさらなる介入も可能です。
社会情勢や市場動向といった分析者の知識を積極的にモデルに組み込んでいくことで、予測精度の改善に繋がることはもちろん、分析の過程で様々な知見が得られることもAnalyst-in-the-Loopの大きなメリットです。分析を通し、よりよいモデルとして&よりよい分析者として成長していくことが期待できるのではないでしょうか。
2024年、不安なことが続く幕開けとなっていますが、みなさまどうぞご安全に。今年もどうぞよろしくお願いいたします。
-
論文・モデルの概要については論文日本語サマリーをご参照ください https://github.com/TeamAidemy/ds-paper-summaries/issues/37 ↩︎
-
株価はランダムに動くとされているので、時系列データのみから予測できるものではありません。あくまで題材としてご覧ください。 ↩︎
-
測定間隔が一定でなくてもOK、欠損値があってもOKと、前処理の少なさも大きな利点。 ↩︎
-
「大統領選挙の年は、次の大統領が誰になるかという政治的なリスクがあるため、株価の上昇幅はやや抑えられる傾向がある」らしい。https://shikiho.toyokeizai.net/news/0/723028 ↩︎
-
繰り返しますが、過去の値動きのみからの予測の効果は限定的で多くの不確実性とリスクを伴います。 ↩︎

Discussion