技術記事のキャッチアップをPodcastから行うための技術
はじめに
みなさんはテクノロジーのキャッチアップはどのように行っていますか?このたび、ラジオ形式で聴くことで日々の技術ニュースをキャッチアップできる機能をこのたび公開しました!

前日のZennやhackernewsなどの人気ニュースを、「Webフロントエンド」「データベース」のように特定の職種やテーマごとに、Podcast形式で視聴することができます!
現時点では下記のテーマごとにPodcastを生成しております。
- Webフロントエンド
- Webバックエンド
- モバイル開発
- セキュリティ
- インフラ
- データベース関連
- AI/機械学習
- TypeScript関連
- Python関連
- Deep Tech(高度な技術記事を取り扱う)
さらにPodcastを聞けるだけではなく、紹介した記事は、その場から記事に飛ぶことができ、直接記事として読むことも可能です。また従来のResearchlyの機能通り、その記事の中で気になったポイントをChat形式で質問することも可能になっています!
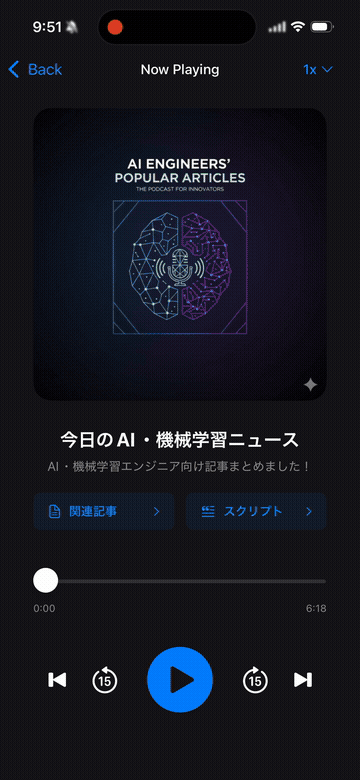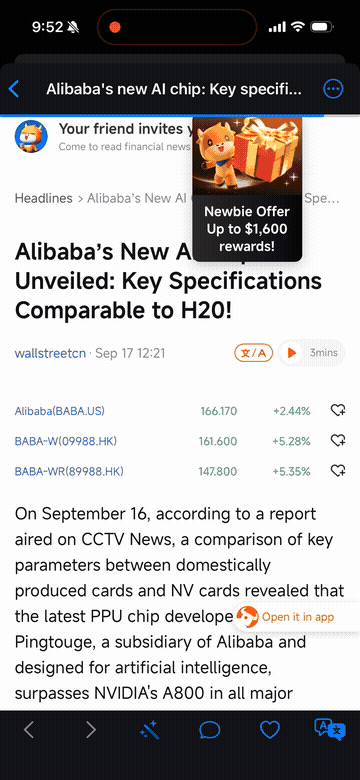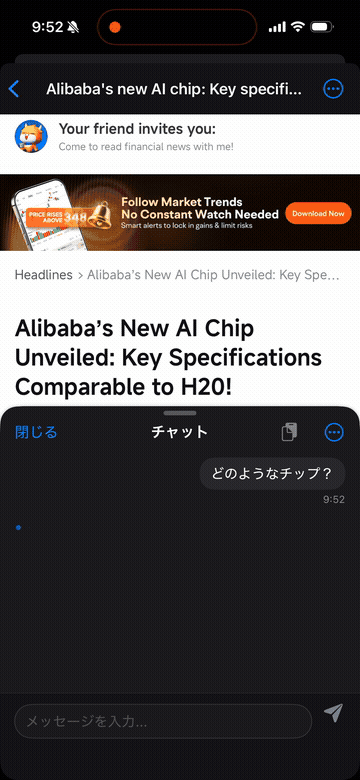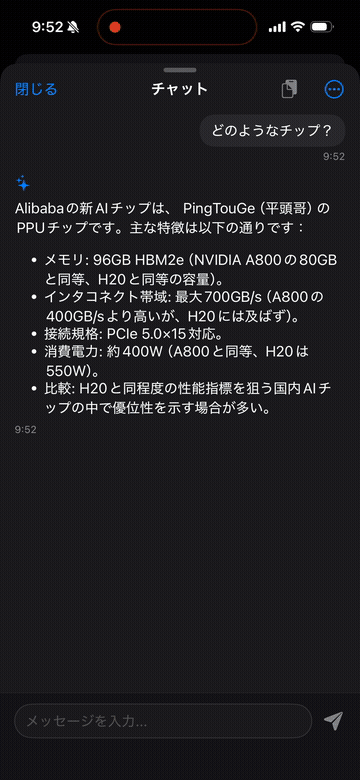
iOSアプリ限定にはなりますが、まずはトライアルから試すことができるので、他のテーマでも視聴してみてください!トライアル期間中にキャンセルすれば料金はかかりません!気に入っていただければサブスクしていただけると嬉しいです☺️
ダウンロードはこちらからどうぞ!
Podcast生成を支える技術
さて、ここからは、より掘り下げた技術面にフォーカスした実装方法を紹介します!Researchlyの技術自体の紹介はZennの記事に挙げているため、そちらを参考にしてください。
Podcastの生成の全体像は大きく5つのステップに分かれています。これらを個別に紹介していきます。
Step1. PodCastで選ぶ記事を選定する

Researchlyは毎日フィード形式で、Zenn、はてブ、hackernewsなどのRSSを取り込んでいます。このタイミングで記事を分類対象となる記事を選定します。ただし、すべての記事を分類すると膨大な数の記事を分類する必要があるため、現時点では対象(例えばいいねの数が30以上など)を(Supabaseの)DBに保存するだけです。
Step2. 選定した記事をテーマごとに分類する

前日までの分類対象となった記事について深夜のタイミングでバッチ処理を行います。 分類作業自体は、gpt-5-nanoでおこないます。また可能な限り人気の記事が取得できるように、はてブ数やいいね数などを参考に並び替えて紹介できるようにしています。
Step3. Podcast形式の読み上げスクリプトに変換する
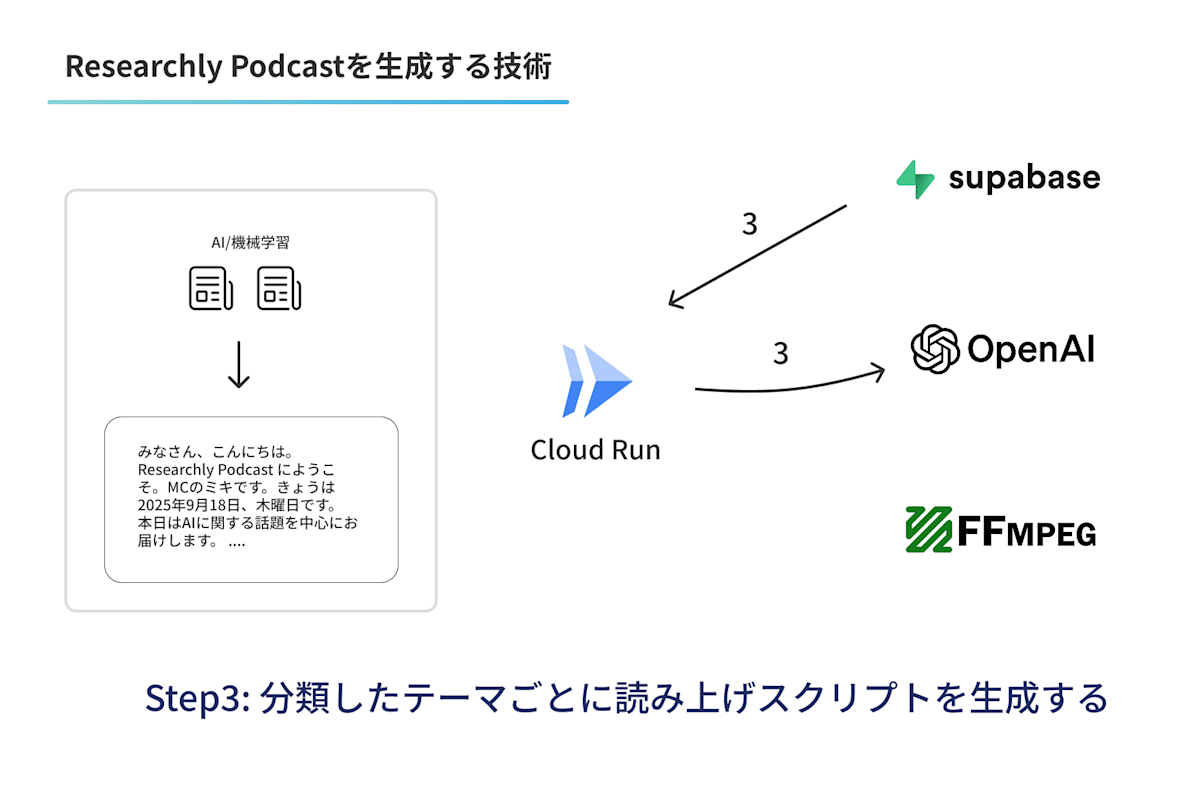
そのあとに選定した技術にかんする記事を、テーマごとにPodcast形式のスクリプトにgpt-5-miniを利用して変換します。読み上げスクリプトに関しては、下記のZenn Castさんのプロンプトを参考に、行間の読み上げ余白を広げるなど小さなチューニングをしたもので生成しています。
生成されたスクリプトの例
みなさん、こんにちは。Researchly Podcast にようこそ。MCのミキです。
きょうは2025年9月18日、木曜日です。
本日はAIやモビリティに関する話題を中心にお届けします。
今日は5本の記事をお届けしますよ。
それでは、最初の記事からいきます。まず一つ目の記事は「Alibaba's new AI chip: Key specifications comparable to H20」です。
この記事のがいようは、アリババが新しいAIチップを発表したという話です。
報道では、その主要な仕様がH20とくらべても匹敵するレベルだと紹介されていますよね。
クラウドでの推論やデータセンターでの用途を念頭に置いた設計のようです。
技術的なポイントとしては、テンソル演算の加速やメモリ帯域の強化、消費電力の最適化が注目されています。
それから、ハードとソフトをセットで最適化するアプローチを強めている点も特徴です。
つまり、単体のチップ性能だけでなく、コンパイラやランタイムとの連携で実運用の効率を上げようとしているんです。
この発表は、AIチップ市場での選択肢が増える意味でも重要ですね。
......
次に、二つ目の記事です。タイトルは「AIの安全性を評価するツール、IPAなどが無料公開 『有害情報の出力制御』など10観点でAIの出力採点」です。
概要は、情報処理推進機構、IPAが中心となるAIセーフティ・インスティテュート、AISIが評価ツールをGitHubで公開したという話です。
ツールはライセンスがApache 2.0で、商用利用も想定されていますよ。
技術的ポイントは、大きく二つあります。
一つは、評価観点を10項目に整理していて、「有害情報のしゅつりょくせいぎょ」や「プライバシー保護」などを定量化する仕組みです。
定量評価と、利用者に聞く定性評価を組み合わせて総合スコアを出す点が特徴なんです。
もう一つは、レッドチーミング、つまり攻撃者の視点からの検証項目を自動生成する機能を備えていることです。
業界や業務に合った評価項目をAIがドキュメントから抽出してくれるので、評価の立ち上げコストが下がります。
オープンでカスタマイズ可能という点も、実務で使いやすいですね。
......
次、三つ目の記事にいきます。タイトルは「I got the highest score on ARC-AGI again swapping Python for English」です。
この記事のがいようは、ARC-AGIという抽象パターン認識のベンチマークで、著者がPythonコードではなく英語の指示を使う手法で高得点を出したというものです。
具体的には、ARC v1で79.6パーセントを達成し、ARC v2でも29.4パーセントという新しい最先端スコアを出しました。
さらに、コスト面でも1タスクあたり約8.42ドルに抑えられ、以前の手法の約25分の1の効率だと書かれています。
技術的には、Grok-4を使って自然言語の「手順」を生成し、サブエージェントがそれらを訓練例で検証してスコアを付けます。
そのうえで、進化的な世代交代を行い、個別の修正とプールした修正を繰り返すというアーキテクチャです。
ポイントは、コードよりも「英語の指示」がパターンを柔軟に表現できる点と、評価→改良のループを設計的にまわしている点ですね。
トークン制限や情報の過多による注意散漫など、実運用上のトレードオフも丁寧に説明されています。
こうした手法は、モデルの一般化能力を高める新しい方向性として興味深いですね。
......
四つ目の記事です。タイトルは「Bringing fully autonomous rides to Nashville, in partnership with Lyft」です。
内容は、WaymoがLyftと協力してナッシュビルで完全自動運転のライドヘイリングサービスを展開するという発表です。
WaymoのDriverは都市間での一般化を目指しており、既に週に何十万件もの自動運転ライドを提供している地域があるそうです。
技術的ポイントは、車両側の自動運転ソフトと、Lyftのフリート管理能力を組み合わせる点です。
運行規模を拡大するうえでの安全データや運行管理のノウハウが重要になってきますよね。
また、100万マイル級ではなく1億マイルを超える実走行データを根拠に安全性を主張している点も注目です。
これは都市交通や規制、雇用にも影響を与える話題ですね。
......
最後、五つ目の記事です。タイトルは「Teen safety, freedom, and privacy」です。
これはOpenAIのサム・アルトマン氏による声明で、ティーンの安全、自由、プライバシーの間の緊張にどう対処するかを説明しています。
要点は三つです。ひとつ目は、会話のプライバシーを重視するということ。
ふたつ目は、大人の利用者にはできるだけ自由を与えたいということ。
そして三つ目が、未成年者に対しては安全を優先するという立場です。
技術的な施策としては、年齢を推定するシステムを作り、あいまいな場合は未成年向けの扱いに寄せるという方針です。
また、保護者コントロールや、差し迫った危険が疑われる場合の自動検知とエスカレーションも示されています。
この話は、プライバシーと安全のバランスをどう取るかという、社会的にも難しいテーマですよね。
実装面では、年齢推定の精度や誤判定時の対応が大きな課題になりそうです。
本日は以上になります。
どの記事も現場や社会への影響が大きいものばかりでしたね。
詳しい内容は各社の発表や記事をご覧ください。
それではまた次回、Researchly Podcastでお会いするのを楽しみにしています。ミキでした。
Step4. 読み上げ音声を生成する
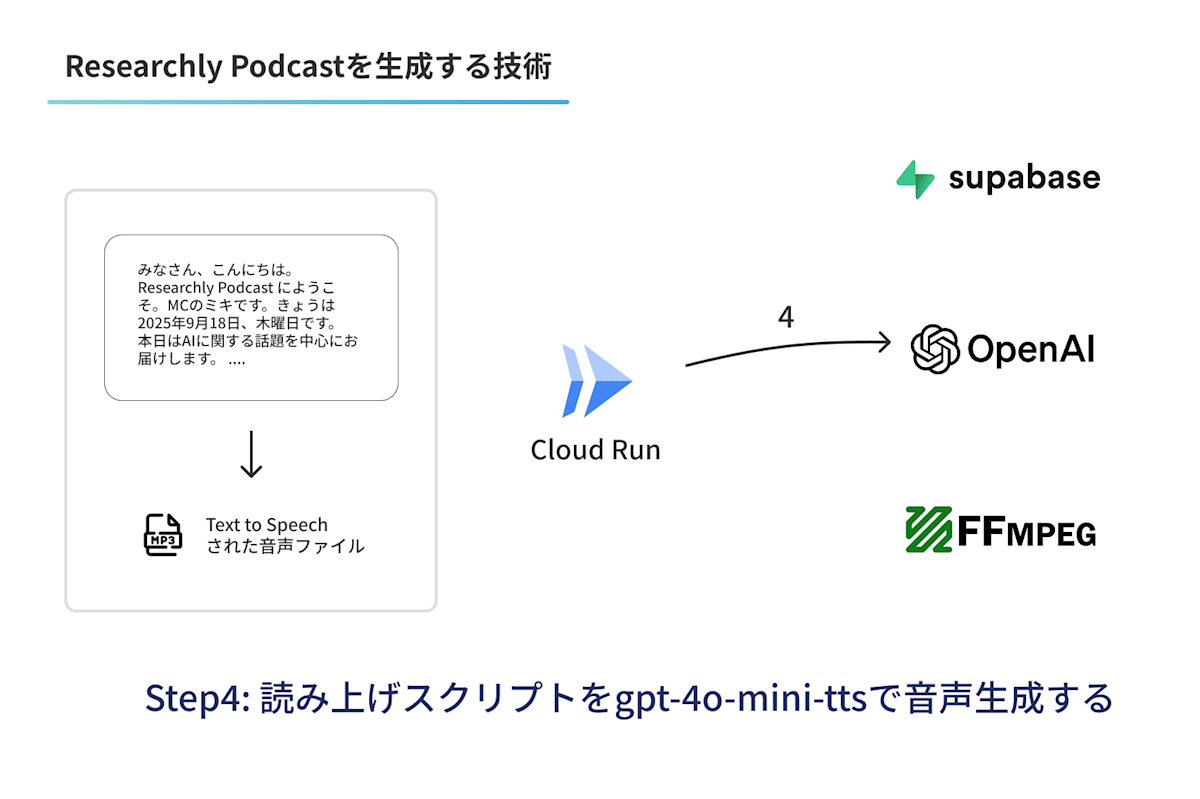
生成したスクリプトをもとに、音声合成を行います。Researchlyでは、OpenAIの Text to Speechを利用しています。理由としては、いくつか検討をしたなかでも自然な音声が生成できるためです。しかし個人的には好みもあると思うため、将来的には複数の音声をユーザが選択できるようにしたいと考えています。
OpenAIの提供するText to Speech機能は、OpenAI Playgroundで試すことも可能で非常に気軽に利用できます。
Step5. よりPodcastらしくBGMをつける

よりラジオらしい形式にするために読み上げ音声の裏側には、BGMを鳴らす必要があります。Step4で生成した読み上げに追加で、BGMをミクシングしなければなりません。
このミクシングのために、ffmpegを利用しています。 しかしながら、ResearchlyのバックエンドはTypeScriptで実装しており、このためのTypeScriptライブラリに特筆するほど良いライブラリを見つけられませんでした😔
そのため、Researchlyでは、ffmpeg のスタティックなバイナリを直接コンテナに取り込んでいます(Cloud Runで動作)。下記サイトで配布されているものになります。
最終的なDockerfileは下記のようになっています。
# alpineイメージをベースにffmpegをインストール
FROM node:22-alpine AS runtime
RUN apk add --no-cache wget xz && \
wget https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz && \
tar -xf ffmpeg-release-amd64-static.tar.xz && \
mv ffmpeg-*-amd64-static/ffmpeg /usr/local/bin/ && \
mv ffmpeg-*-amd64-static/ffprobe /usr/local/bin/ && \
rm -rf ffmpeg-* && \
apk del wget xz && \
chmod +x /usr/local/bin/ffmpeg /usr/local/bin/ffprobe
ffmpegはソースコードからビルドしようとすると依存関係が複雑になりすぎるので、適切なバイナリを直接インストールしてしまえば、CLI経由で利用できるので非常に楽です。 しかし、お世辞にも行儀の良い方法とは言えないですが、このためにサーバレス化したりするほどでもなく、またffmpegの強固な機能群を利用できるため、なんだかんだ非常に重宝しています。インフラを不要に増やす必要もないですしね。
そして、ミクシングされた音声ファイルを、Supabase Storageに保存して配布準備が完了になります!🎉
コスト面について
毎朝種類のニュースを配信していますが、日次でも$1程度に収まる程度になっています。下記がそのコストのダッシュボードのスクリーンショットになりますが、Researchlyの他のコスト(チャット機能や要約機能など)も含まれていても、この程度になっています。

おわりに
以上のようにPodcast形式にすることで、通勤時間や散歩の時間でも技術のキャッチアップが簡単にできるようになりました。自分も以前までは耳でキャッチアップをすることは少なかったのですが、この機能は非常に気に入っています☺️
ぜひ一度Researchlyで試してみてください!ダウンロードはこちらからどうぞ!
Discussion