SQL文で重複セルの横展開やソート、計算を実行させてネットワーク負荷を軽減させてみた話
Zennが出始めてすぐに新規ユーザ登録はしてたけど、ようやくネタが出てきたので1本目の記事を書いてみる。自分が調べ、試してみたことが他の方にも役に立つかどうかはさておき、メモ程度に。
はじめに
最近自粛自粛ばかり言われていてずっと家に引きこもり続けていたけど、それではあまりに暇すぎるのでWeb上で動作するTwitter集計ページを作ってみることにした。
自分の本業はクラウド屋のインフラ担当で、日常でのコーディングと言えばちょっとした自動化などで小規模なシェルスクリプトやPerlをたまに書く時がある程度。Webで動作するアプリケーションの知識は基本中の基本を知ってるくらいで、知識のアップデートもしばらく止まっている。
そんな自分が最新のWeb周り技術の勉強も兼ねて今回作ろうとしたモノの機能の概要をざっくりまとめるとこんな感じ。
- Twitterアカウントいくつかに対し、Twitter APIを経由して一定時間ごとにフォロワー数やツイート数などのデータを取得する。
- 取得したデータはRDBMSに蓄積する。
- 最新情報や過去のデータ、増減数などを表やグラフ形式でWeb上に分かりやすく表示する。
全体的なシステムのことは別の機会に譲るとして、今回は 2.から3.へのデータ受け渡し に関する部分にフォーカスを当てた記事を書いてみる。
今回はログ蓄積用のデータベースとしてMariaDBを採用した。余談ではあるが、今回は最新技術の勉強も兼ねてのこともあり、AWSが提供する時系列ログ記録に特化したDBであるTimestreamはじめイケてるサービスを使ってみたかったけど、作ろうとするシステムの規模や予算に見合わず断念。
ということでいささか長い歴史のある技術ではあるけど、その分枯れていてインターネット上にもたくさんのナレッジが転がっているRDBMSを採用した(ので、この記事もこのタイトルで書くことができている)。
データベースの構造
この後の説明のため、MariaDB内でデータ蓄積に使用する主なテーブルの設計を簡単に紹介しておく。若干めんどくさい作りになってるのは、取得対象となるTwitterアカウントの追加や削除はもちろん、ログを取得する時間やその際に取得するデータの不完全/断片化の許容、取得データ種別が増えても対応できるなど柔軟性に主眼を置いた設計としているため。
データ蓄積テーブル
基本となるデータ蓄積用のテーブル。このうちログインデックスID、対象Twitterアカウント、ログ種別IDの組み合わせは重複しないので、この3カラムを複合主キーに設定し一意性を確保している。
| ログインデックスID | 対象ユーザID | ログ種別ID | データ | |
|---|---|---|---|---|
| 例 | 1 | 1 | 1 | 100 |
ログインデックステーブル
ログを取得した日時をログインデックスIDとして参照可能にするテーブル。登録される日時情報はMySQL標準形式。
| ID | ログ取得日時 | |
|---|---|---|
| 例 | 1 | 2021-06-13 00:00:00 |
ログ種別テーブル
ログの種別をログ種別IDとして参照可能にするテーブル。
| ID | ログ種別 | |
|---|---|---|
| 例 | 1 | フォロワー数 |
対象ユーザテーブル
ユーザ情報を登録するテーブル。Twitter ID[1]などが格納され、Twitter APIでの情報取得実施の際にもこのテーブルが参照される(実際には該当ユーザのいろいろな情報を入れるためのカラムが他多数ある)
| ID | 名前 | Twitter ID | スクリーンネーム | |
|---|---|---|---|---|
| 例 | 1 | 上原 歩夢 | 1111 | uehara-ayumu |
どんどん増えるSQL問い合わせ結果
テーブル作成が完成しTwitter APIによるデータ取得を開始。しばらく経つとデータも蓄積され、いよいよSQLで情報を引っ張ってきてみることにする。しかし…。
基本的な問い合わせ
データ蓄積テーブルを基本とし、そこに他のテーブルを結合させて出力させる。ログ情報を出力させる擬似SQL文は以下のとおり。
SELECT
ログ取得日時, 名前, ログ種別名, データ
FROM
データ蓄積テーブル
JOIN
ログインデックステーブル ON データ蓄積テーブル.ログインデックスID = データ蓄積テーブル.ID
JOIN
対象ユーザテーブル ON データ蓄積テーブル.対象ユーザID = 対象ユーザテーブル.ID
JOIN
ログ種別テーブル ON データ蓄積テーブル.ログ種別ID = ログ種別テーブル.ID
この問い合わせを実行することで、情報取得対象者のフォロワー数が得られる。
| ログ取得日時 | 名前 | ログ種別名 | データ |
|---|---|---|---|
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロワー数 | 100 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロワー数 | 150 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロワー数 | 200 |
取得する項目が増えた
Twitter APIから取得する項目を、フォロワー数に加えてさらにフォロー数も追加。すると一気に出力行が倍増。
| ログ取得日時 | 名前 | ログ種別名 | データ |
|---|---|---|---|
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロワー数 | 100 |
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロー数 | 30 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロワー数 | 150 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロー数 | 40 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロワー数 | 200 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロー数 | 100 |
取得日時が増えた
Twitterからの情報取得を定期的に行っていればログ取得日時も当然のように増加。そして出力結果はさらに倍増…
| ログ取得日時 | 名前 | ログ種別名 | データ |
|---|---|---|---|
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロワー数 | 100 |
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロー数 | 30 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロワー数 | 150 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロー数 | 40 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロワー数 | 200 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロー数 | 100 |
| 2021-06-14 00:00:00 | 上原 歩夢 | フォロワー数 | 110 |
| 2021-06-14 00:00:00 | 上原 歩夢 | フォロー数 | 35 |
| 2021-06-14 00:00:00 | 優木 せつ菜 | フォロワー数 | 170 |
| 2021-06-14 00:00:00 | 優木 せつ菜 | フォロー数 | 60 |
| 2021-06-14 00:00:00 | 宮下 愛 | フォロワー数 | 300 |
| 2021-06-14 00:00:00 | 宮下 愛 | フォロー数 | 150 |
現実には分割して取得するも、しかし…
MariaDBとWeb表示用サーバとはローカルネットワークを介してネットワークで接続されている。SQL内に格納されるデータが増えていくたびにSQLの問い合わせで返答される結果データも増大し、それに比例してネットワーク帯域も圧迫されることに。
さらに、Webの表示側では前日と比較した増減数も表示させたかったため、2つの日時の結果を取得することに。ひとまずはWHERE句を使用して各日時ごとの結果を取得していたが、対象者やログの種別が増えれば出力行も増大し、なにより2度の問い合わせを行っているため無駄が多いと感じてきた。
そこで、なるべく 必要な結果だけを無駄なデータを発生させることなく1度の問い合わせで出力する ようにSQL文を工夫できないかと調べることにした。
出力結果をできる限りSQLで整形する!
今回利用したテクニックは主に3点。順番に説明していこう。
1. ソート
これはORDER BY句の追加で比較的簡単に行える。通信量の減少には貢献しないが、フロントエンド側の計算量は減る(ただしRDBMS側の計算量は増える)。もちろん、ソート処理を行うポイントをRDBMS側か、それともフロントエンド側かのどちらでやる方が最適かは状況に依るだろう。
2. GROUP BY句/MAX関数/CASE関数による縦の連続項目の横展開
例えば先の例では、
| ログ取得日時 | 名前 | ログ種別名 | データ |
|---|---|---|---|
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロワー数 | 100 |
| 2021-06-13 00:00:00 | 上原 歩夢 | フォロー数 | 30 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロワー数 | 150 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | フォロー数 | 40 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロワー数 | 200 |
| 2021-06-13 00:00:00 | 宮下 愛 | フォロー数 | 100 |
を
| ログ取得日時 | 名前 | フォロワー数 | フォロー数 |
|---|---|---|---|
| 2021-06-13 00:00:00 | 上原 歩夢 | 100 | 30 |
| 2021-06-13 00:00:00 | 優木 せつ菜 | 150 | 40 |
| 2021-06-13 00:00:00 | 宮下 愛 | 200 | 100 |
のようにすること。これにより重複する文字列が無くなり、結果を受け取るフロントエンド側で捨てられるだけのデータをより少なくすることができる。これには GROUP BY句 、 MAX関数 、 CASE関数 の組み合わせにより実現が可能。擬似SQL文は以下のとおり。
SELECT
ログインデックステーブル.ログ取得日時,
対象ユーザテーブル.名前,
MAX(CASE WHEN ログ種別テーブル.ログ種別 = 'フォロワー数' THEN データ END),
MAX(CASE WHEN ログ種別テーブル.ログ種別 = 'フォロー数' THEN データ END),
MAX(CASE WHEN ログ種別テーブル.ログ種別 = 'ツイート数' THEN データ END)
FROM
データ蓄積テーブル
JOIN
ログインデックステーブル ON データ蓄積テーブル.ログインデックスID = ログインデックステーブル.ID
JOIN
ログ種別テーブル ON データ蓄積テーブル.ログ種別ID = ログ種別テーブル.ID
JOIN
対象ユーザテーブル ON データ蓄積テーブル.対象ユーザID = 対象ユーザテーブル.ID
GROUP BY 対象ユーザテーブル.名前
GROUP BY句は重複する項目をまとめるもの。上記の例では「名前」カラムが対象となり、出力結果に名前の重複が無くなった状態となる。
SELECT句の中にあるCASE関数は、条件により処理を分岐させる関数。 WHEN に続き条件を記述し、その後 THEN や ELSE で条件式の評価結果により処理を分岐できる。上記で示した擬似SQL文の中では
CASE WHEN ログ種別テーブル.ログ種別 = 'フォロワー数' THEN データ END
のように書かれているが、これはログ種別が"フォロワー数"となっている行については「データ」の内容を返すというもの。WHERE句に記述することでこのカラムが追加で表示されるようになるが、条件に従って返される実際の値が行として出力されるわけではなく NULL となってしまう。そこでこのCASE関数をMAX関数で内包し、「データ」の内容を取得している。MAX関数は集合の中で最大の値を返す関数だが、この場合CASE関数で評価され返される数値は「データ」内のひとつのみなのでそのまま行に出力される(故にMIN関数を使用した場合でも同様に動作する)。
ちなみにこのまま問い合わせると MAX(CASE WHEN ログ種別テーブル.ログ種別 = 'フォロワー数' THEN データ END) のような長いカラム名になるのでAS句で別名を設定するのがおすすめ。
3. 四則演算処理
SELECT内で演算記号を用いて計算した結果を出力できる。今回は前日差のデータが欲しかったので、前日のログとの差を計算するカラムを設定した。
最終的にWeb上の表示と同じ出力にできた!
慣れないSQL文で試行錯誤を繰り返し、完全にフロントエンド(Web)側で表示させるテーブルと全く同一の出力結果を得ることができた。これによりWeb上ではSQLからの返答を順番に並べるだけの至極簡単処理。せっかくなので実例をば。
SQL問い合わせ
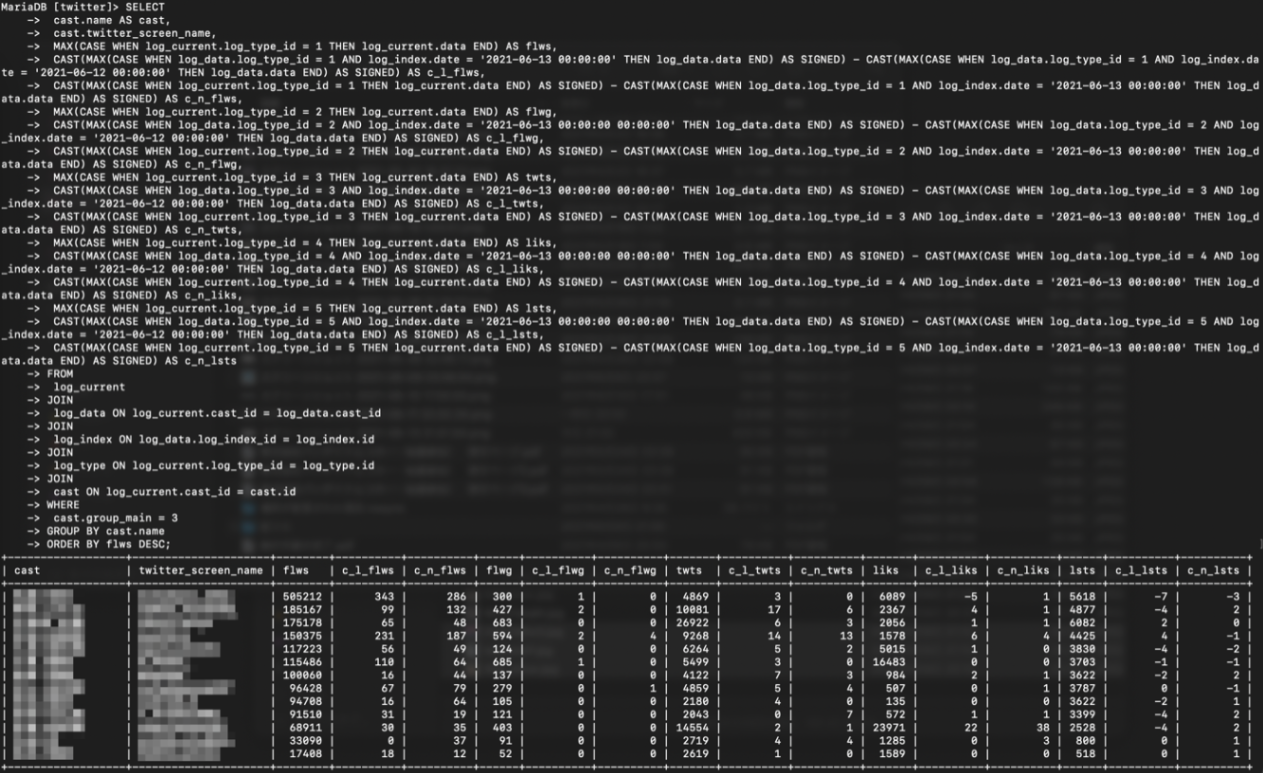
Webの表示
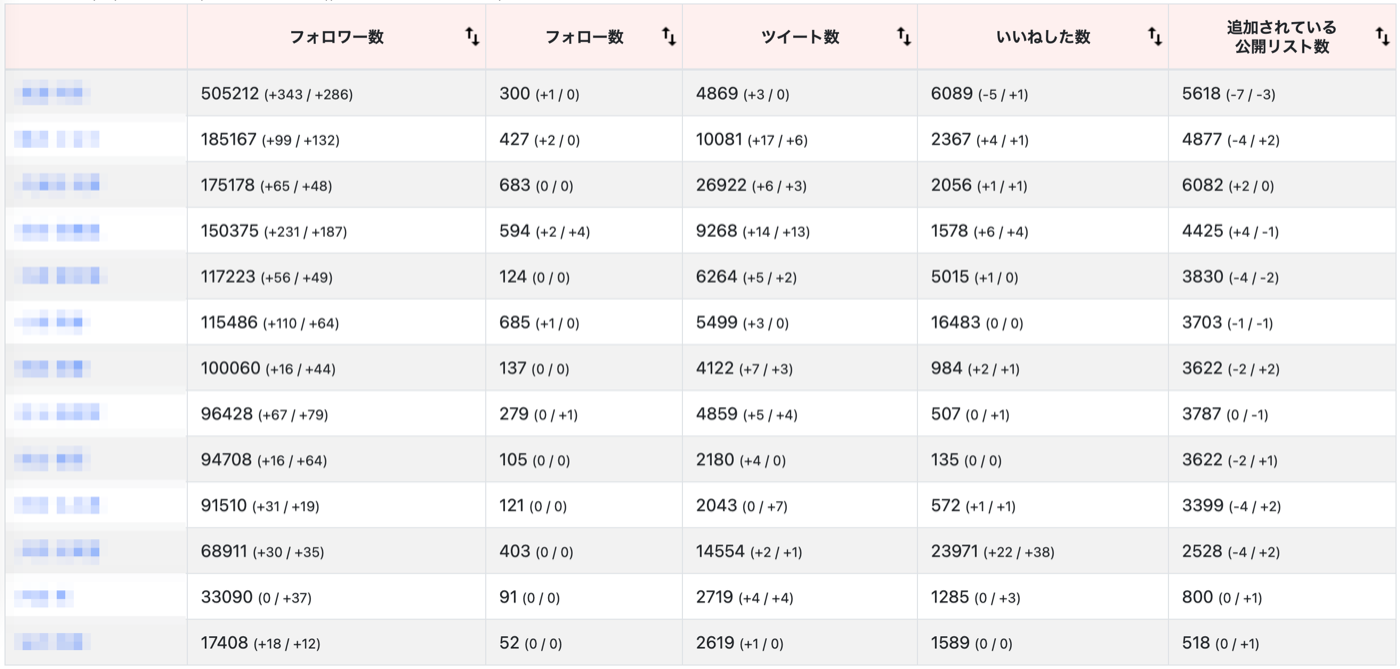
SQL文の問い合わせ結果より得られる値は合計195個。それらが行・列ともに全く等しくWeb上のテーブルに並べられるため、無駄になる項目が一切ない状態となっている。
まとめ
現時点では、このようなテクニックを使用することによる効率向上のメリットはほとんど見えてこない。ただしフロントエンド側で処理する設計の場合、レコード数が増えれば増えるほど無駄なネットワーク負荷が増大するのは明らかだろう。MariaDBでは他にも有用な関数が豊富に用意されている。これからも調査を続けてより効率的な設計を目指していきたい。
-
よく見る「@ほげほげ〜」で表記されるアレはスクリーンネームと言ってユーザがいつでも自由に変更できる(ユニークである必要があるので誰かが使用中のものは不可)。Twitter APIではスクリーンネームを指定してもユーザ情報を取得できるが、もしユーザが別のものに変更してしまうとそれ以降追跡できなくなってしまう。ので、情報取得にはTwitterアカウント作成時に発行され不変の値となる数字で構成されるTwitter IDを指定するのがよい。 ↩︎
Discussion