はじめに(挨拶)
こんにちは、
普段は業務でデータ分析や可視化をしていますが、今回は「初心者向けに Looker Studio(以下LS)をどう設定すると成果に直結するアウトプットが作れるのか」をまとめました。
この記事は、「まだLSを使ったことがない人」や「触ってみたけどよく分からなかった人」 を対象にしています。
できるだけ専門用語を減らし、「これなら私もできそう!」と思えるように書きました。
また、作成したLSのアウトプットをPDF化し、NotebookLMで読み込ませることで、グラフの傾向やデータの要点を自動で把握する方法についても触れています。短時間で全体像をつかみたい方には特におすすめです。
本記事で使用する用語について
- F1:会員が初めて本体商品(例:電動自転車、シティサイクル、キッズサイクル等)を購入したタイミング
-
F2:同じ会員が2回目に本体商品を購入したタイミング
※パーツ購入や消耗品購入は含めません。
Looker Studioとは?

Looker Studio(旧Google Data Portal)は、Googleが提供する無料のBI(ビジネスインテリジェンス)ツール です。
スプレッドシートやBigQueryなど様々なデータソースを接続し、グラフやテーブルを自由に組み合わせてインタラクティブなダッシュボードを作成できます。
強み
- 無料で使える
- Googleスプレッドシートとの連携が簡単
- ドリルダウン機能で購入回数や期間別の絞り込みが可能(指定すると一括で対象テーブルが変化)
- データ更新がほぼリアルタイム
- グラフや表のデザイン自由度が高い
制限・限界
LSはとても便利ですが、実務ではこんな限界もあります。
- 行間比較が苦手(例:F1購入日とF2購入日の比較)
- 同日除外などの条件付き集計が難しい
- データ加工(集計・条件分岐)は柔軟ではない
- Nullや日付型の不一致がそのまま表示されやすい
こうした制限があるため、私は事前にGoogleスプレッドシートで前処理を行っています。
「ピボットテーブルでできるのでは?」という質問もありますが、今回のようにF1↔F2の比較や除外条件、LTV帯の自動分類などは、シート関数とLSの組み合わせの方が効率的です。
本記事の目次
最小構成で再現できるハンズオン
ここでは、できるだけシンプルな構成で再現できる手順を紹介します。
本番データではなく、自分で用意したサンプルスプレッドシートで試すのがおすすめです。
必要な準備
- Googleアカウント
- Googleスプレッドシート(サンプルデータ)
- Looker Studio アカウント(GoogleアカウントでOK)
サンプルデータの構造
| 会員ID | F1カテゴリ | F1購入日 | F2カテゴリ | F2購入日 | LTV | 購入回数 |
|---|---|---|---|---|---|---|
| A001 | 電動自転車 | 2024/01/05 | シティサイクル | 2024/07/10 | 150000 | 2 |
| A002 | シティサイクル | 2024/02/10 | スポーツバイク | 2024/06/20 | 70000 | 2 |
(※構造イメージです)
Looker Studio設定の流れ
-
データソースにスプレッドシートを接続

-
テーブルを作成し、指標(数値)とディメンション(項目)を設定
-
グラフを追加(棒グラフ、円グラフ、表など)
-
フィルタでF1カテゴリ・F2カテゴリ別に切替
-
ドリルダウンで購入回数や期間別に絞り込み
ここまで設定すると、カテゴリ別の購入傾向やLTV分布が一目で分かるようになります。
前処理をシートでやる理由(限界と設計意図)
LS単体でもグラフやテーブルは作れますが、実務では「事前にスプレッドシートで加工してからLSに渡す」方が効率的なケースが多いです。
なぜ前処理が必要か?
-
行間比較ができない
例:F1購入日とF2購入日の差(日数)を計算し、購入間隔分布を作る -
同日除外の集計ができない
例:F1とF2が同日に買われた場合を集計対象から外す -
条件付きのラベル付けが面倒
例:LTV帯を「0〜3万」「3〜5万」「5〜10万」などに分類 -
除外条件や例外処理を組み込みやすい
例:特定キャンペーンの注文を除外する
実際の設計意図
-
スプレッドシートで計算列を作る
- F1〜F2購入日差(日数)
- F1〜F2間のパーツ購入回数
- LTV帯(※00, 01, 02 を接頭辞にして並び順を制御)
-
条件付きフラグを作る
- 同日購入フラグ
- 除外対象フラグ
-
LSに渡す前に“完成形の分析テーブル”にする
- LSは表示に専念、計算はシート側で終わらせる
実務の判断ポイント
分析設計をする上で特に重要な判断ポイントは以下の通りです。
1. 粒度の決め方
- 例:会員単位か注文単位か
- 粒度を間違えると同じ人が複数カウントされることがある
2. 期間の切り方
- 購入日ベースか配信日ベースか
- キャンペーン期間と分析期間の一致が必要な場合は注意
3. 除外条件
- 特殊セール、返品、サンプル注文など
- 「なぜ除外したか」の理由を記録しておくと後で検証可能
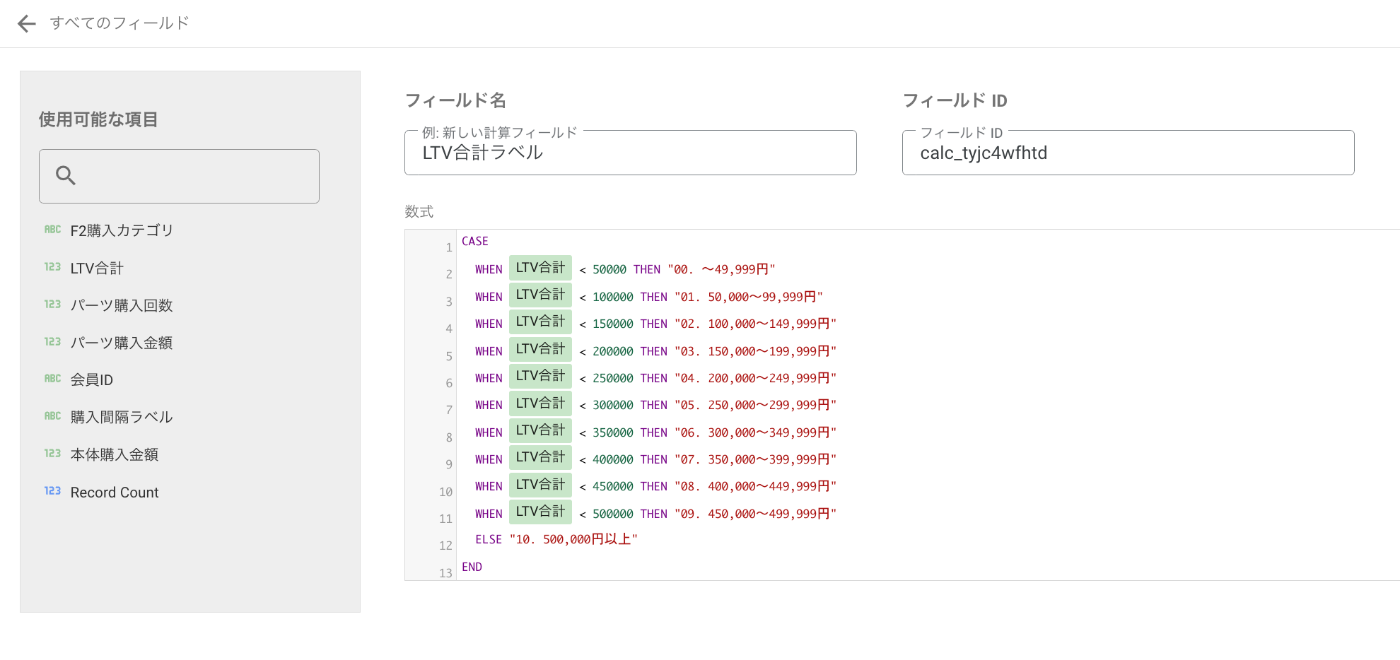
4. LTV帯の設計
- 商品や顧客層によって最適な区切りは変わる
- 高単価商品なら上限帯を広く、低単価なら細かく設定
-
順序を崩さないための工夫
→ LTV帯の前に00_,01_のような番号を付けると並び順が固定されます(付けないとLSでは金額順でなく件数順になることがある)
落とし穴と対処
LSやスプレッドシートでの分析では、以下のような落とし穴があります。
-
日付型の不一致
- シート上では日付に見えても実際は文字列になっている
- →
DATEVALUE()関数で揃える
-
数値/文字の混在
- 売上金額にハイフン(返品)や文字列が混ざっていると集計エラー
- →
VALUE()やIFERROR()で変換
-
重複カウント
- 同一会員・同日・同カテゴリで複数注文がある場合
- → 集計前に重複削除
-
Nullの扱い
- LSではNullがフィルタで無視されることがある
- → 前処理で「未設定」などに置き換え
おまけ:LTV帯の設定Tips
LTV帯(顧客生涯価値の金額区分)を上手く設定すると、グラフの見やすさや比較のしやすさが大きく変わります。
設定のコツ
-
商品価格帯に合わせて区切る
- 高単価商品:3万刻みや5万刻み
- 低単価商品:1万刻みや5000円刻み
-
順序を維持するための番号付け
- 「00_0〜3万」「01_3〜5万」「02_5〜10万」…
→ Looker Studioの並び順が安定します
(番号なしだと件数順や文字コード順になり、グラフが乱れる)
- 「00_0〜3万」「01_3〜5万」「02_5〜10万」…
-
帯ごとの色分け
- カラーを固定することで、他のグラフと見比べやすくなる
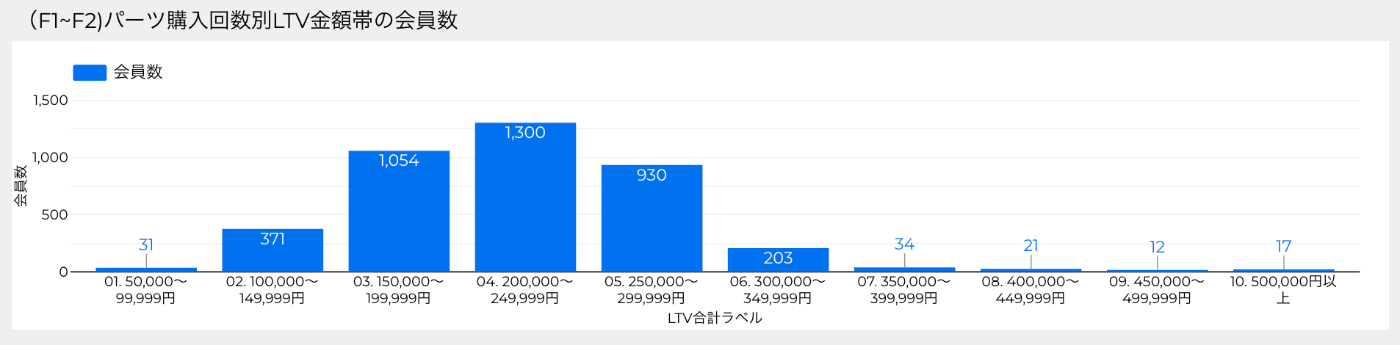
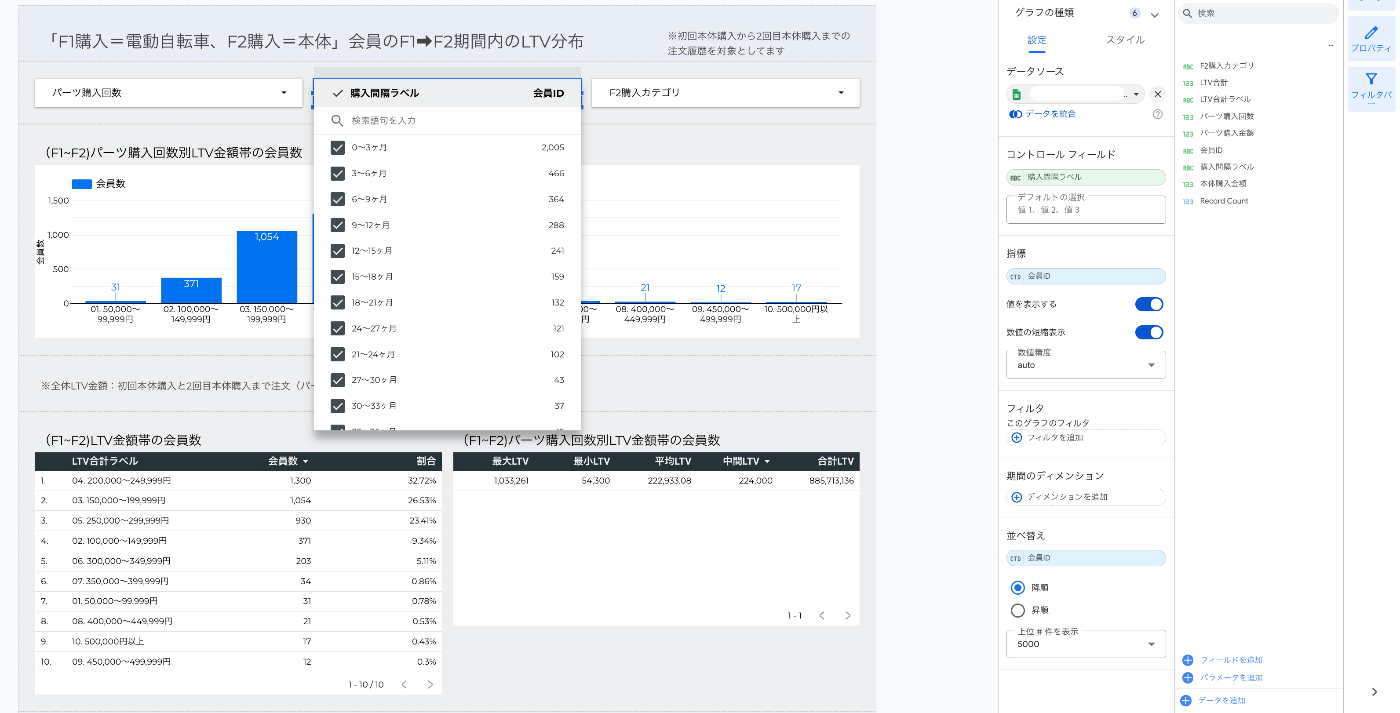
ドリルダウン機能での分析効率化
Looker Studioには「ドリルダウン」という便利な機能があります。
- 例:本体購入回数の分布 → クリックすると、その回数の内訳テーブルに変わる
- これにより、対象を一括で切り替えて詳細を確認可能
使い方
- グラフのデータ設定で「ドリルダウンを有効化」
- 上位指標(カテゴリや購入回数)と下位指標(商品名や期間)を設定
- 表示画面で項目をクリックすると下位データが展開
まとめ
- Looker Studioは「見せる」部分が得意
- 「計算」や「条件分岐」はスプレッドシートで前処理した方が効率的
- 除外条件やLTV帯などの設計をしっかりすると、グラフの意味が深まる
- ドリルダウンや色固定など、見やすさの工夫で使い勝手が向上する
次の章では、実際にこの設定を再現できる最小構成のハンズオン手順を紹介します。
最小構成で再現できるハンズオン
以下の手順を踏めば、この記事の内容をダミーデータなしで再現できます。
-
スプレッドシートを用意
- 必要な列:会員ID、注文日、カテゴリ、金額
- 前処理列:
-
F1日付(初回本体購入日) -
F2日付(2回目本体購入日) -
F1→F2間隔(月)(DATEDIFで計算) -
LTV帯(金額区切り+番号付け)
-
-
Looker Studioに接続
- Google スプレッドシートをデータソースとして選択
- ディメンション:会員ID、カテゴリ、購入間隔、LTV帯など
- 指標:購入回数、合計金額
-
グラフ作成
- 本体購入分布:棒グラフ
- F1→F2間のパーツ購入カテゴリランキング:円グラフ
- LTV分布:棒グラフ(LTV帯をX軸)
-
デザイン調整
- LTV帯を「番号_金額帯」にして並び順を固定
- ドリルダウンを設定し、クリックで詳細表示できるようにする
- 色を固定し、カテゴリごとに統一感を出す

Looker Studioの強みと限界(おさらい)
強み
- データが更新されると自動でグラフに反映
- グラフやフィルターの自由度が高い
- 共有リンクでリアルタイム共有が可能
限界
- 行同士の比較や複雑な条件分岐が苦手
- 並び順の制御がしづらい(工夫が必要)
- 大量データだと表示が遅くなる
実務における判断ポイント
- 粒度:日次・月次のどちらで集計するか
- 期間:何年分を対象にするか
- 除外条件:同日複数注文やキャンセルをどう扱うか
- LTV帯:対象商品の価格帯に合わせて切る
これらの設計次第で、同じデータでも全く違うアウトプットになります。
NotebookLMでPDF分析
NotebookLMとは

NotebookLM はGoogleが提供するAIノートブックサービスです。文章やPDF、スライド資料などをアップロードすると、その内容をもとに要約・分析・質問応答が可能になります。特にLooker StudioのレポートPDFとの相性がよく、グラフや表を見ながら短時間で傾向を把握できます。
Looker StudioのPDFを読み込む手順
- Looker Studioで対象レポートをPDFとしてエクスポート
- NotebookLMにアクセスして新規ノートを作成
- PDFをアップロード
- 「このグラフから読み取れる傾向は?」など、自然言語で質問
この流れだけで、売上推移やカテゴリ別の伸び、LTV帯の偏りなどを自動でまとめてくれます。
NotebookLMに投げる質問例
例えば、以下のような質問をするとより実務に直結した分析結果が得られます。
質問例
本体購入回数を増やすための施策を立案する上で、ソースから抽出された「事実」と、それらの事実から導かれる「インサイト」を整理してください。
回答例(一部抜粋)
-
事実 (Facts)
- 大半の会員は2回の本体購入(F1とF2)に留まっており、全体の**91.59%**が2回購入にとどまっています。
- 3回本体を購入している会員は**6.62%**に過ぎません。
- F2本体商品全体では、**電動自転車が68.81%**と最も高い割合を占めています。
-
インサイト (Insights)
- F2購入顧客をF3以降へ導くことが最重要課題:全体の9割以上が2回で止まっているため、3回目以降の購入促進がカギとなります。
- F1購入カテゴリに基づくパーソナライズ施策が有効:F1の購入カテゴリがF2にも影響しているため、顧客のライフステージ変化やニーズ変化を予測し、適切な提案を行うことで再購入を促進できます。
実務での利点
- 短時間で傾向把握:数分で分析メモが完成
- 定量から定性へスムーズに移行:数値の背景をその場で言語化
- 議事録や報告書の下書きとして流用可能
補足:NotebookLMはデータを加工・集計する機能はありません。あくまで既存のレポートを「解釈」するツールとして活用しましょう。
おわりに
この記事では、実務で成果につながるLooker Studioの設定方法を、初心者でも再現できる形で紹介しました。
ポイントは、「前処理はスプレッドシート」「見せ方はLooker Studio」 という役割分担です。
さらに、NotebookLMを組み合わせることで、PDF化したレポートの傾向をAIが即座に要約・解釈してくれるため、分析初期の時間短縮と仮説構築が非常にスムーズになります。
まずはここで紹介した基本形を試し、自分のデータや案件に合わせて調整してみてください。
一度仕組みを作ってしまえば、レポート更新や共有が驚くほど楽になります。
この記事が、あなたの分析スキルを一歩前進させるきっかけになれば幸いです。

Discussion