はじめに
人工知能(AI)分野において、環境を観察・理解・予測し、適切に行動するシステムの開発は長年の課題でした。この課題に対し、Meta AIの研究チームは自己教師あり学習を活用した革新的なビデオモデル「V-JEPA 2」を提案しています。このモデルは、インターネット上の大規模なビデオデータと少量のロボットインタラクションデータを組み合わせ、物理世界の理解、状態予測、計画立案が可能な世界モデルを構築します。本記事では、V-JEPA 2の特徴と独自性について、特に大規模言語モデル(LLM)との違いに焦点を当てて解説します。
V-JEPA 2の概要
V-JEPA 2は、Joint-Embedding Predictive Architecture(JEPA)を基盤とした自己教師あり学習モデルです。このモデルは、100万時間以上のインターネットビデオデータと約62時間のロボット操作データでトレーニングされ、以下の3つの主要な能力を備えています:
- 理解(Understanding):ビデオデータの動きと外観を高精度に認識し、ビデオ質問応答タスクで優れた性能を発揮します。
- 予測(Prediction):人間の行動予測タスクにおいて、従来モデルを大幅に上回る精度を達成します。
- 計画(Planning):アクション条件付きモデル(V-JEPA 2-AC)は、新しい環境での物体把持やピックアンドプレースなどのタスクをゼロショットで実行できます。これにより、V-JEPA 2は物理世界の動的モデルとして機能し、観察から行動までを一貫して制御できる世界モデルを実現します。

これらの能力により、V-JEPA 2は単なるデータ分類器を超え、物理世界の動的モデルを学習し、行動を計画できる「世界モデル」として機能します。
V-JEPA 2のトレーニングプロセス
V-JEPA 2のトレーニングは、2段階のアプローチで行われます:
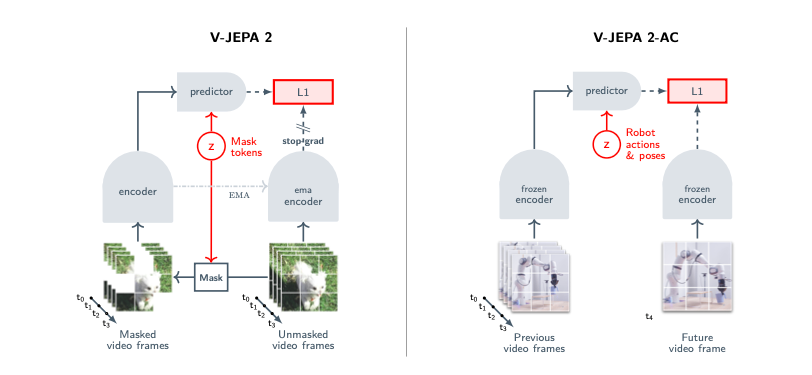
- アクションなし事前トレーニング:インターネット上の大規模ビデオデータ(VideoMix22M、2200万サンプル)を使用し、マスクデノイジングという自己教師あり学習手法でビデオエンコーダをトレーニングします。この手法では、ビデオの一部をマスクし、その欠損部分の表現を予測することで、ビデオの時間的・空間的パターンを学習します。10億パラメータ規模のViT-gエンコーダを使用し、データスケーリング、モデルスケーリング、長期トレーニング、高解像度トレーニングを組み合わせて性能を向上させています。
- アクション条件付きポストトレーニング:事前トレーニング済みのエンコーダを固定し、Droidデータセット(62時間未満の未ラベルロボットビデオ)を用いてアクション条件付き予測器(V-JEPA 2-AC)をトレーニングします。このモデルは、過去のビデオフレームとアクションから次のフレームの表現を予測し、ロボット制御のための計画立案を可能にします。
この2段階のアプローチにより、V-JEPA 2は膨大な観察データから一般的な世界知識を抽出し、少量のインタラクションデータで具体的な行動予測に適応できる能力を獲得します。
V-JEPA 2の独自性
V-JEPA 2の最大の特徴は、自己教師あり学習を用いて世界モデルを構築する点です。このアプローチは、従来のLLM技術とは以下の点で大きく異なります:
1. データの利用:観察中心 vs 言語中心
LLMは主にテキストデータ(ウェブページ、書籍、SNS投稿など)でトレーニングされ、言語理解や生成に特化しています。一方、V-JEPA 2はインターネット上のビデオデータ(100万時間以上)を主な学習リソースとし、視覚的・時間的な動的情報を中心に学習します。このビデオデータは、物理世界の動き、物体の相互作用、シーンの変化を捉え、言語データでは得られない直感的な物理知識をモデルに組み込みます。さらに、V-JEPA 2は少量のロボットインタラクションデータを活用し、アクションとその結果を結びつける能力を獲得します。この観察中心のアプローチにより、LLMが依存する言語的知識とは異なる、物理世界の直接的な理解が可能になります。
2. 学習目標:表現予測 vs ピクセル生成
従来のLLMや多くの生成モデルはピクセルレベルの再構築や高品質なコンテンツ生成を目指すのに対し、V-JEPA 2は異なるアプローチを採用しています。V-JEPA 2は、シーン内の予測可能な要素(例:物体の軌跡)の表現を学習することに焦点を当て、予測不可能な詳細(例:野原の草の葉の正確な位置や木の葉の細部)は意図的に無視します。このアプローチにより、計算コストを抑えながら計画立案に必要な本質的な情報を効率的に抽出できます。論文では、ビデオ生成モデルと比較して、V-JEPA 2がより少ないデータで優れた計画能力を発揮することが実証されています。例えば、Cosmosが2000万時間のビデオを必要とするのに対し、V-JEPA 2は100万時間で同等以上の結果を達成しています。
3. 応用範囲:計画立案 vs 言語応答
LLMは主にテキストベースの対話、質問応答、コード生成などのタスクに特化していますが、物理世界での行動計画には直接適用できません。V-JEPA 2はビデオ質問応答などの言語タスクにも対応できますが、その真価はロボット制御とゼロショット計画立案にあります。例えば、V-JEPA 2-ACはFrankaロボットアームを使用した実験において、追加のトレーニングや報酬なしで、新しい環境での物体把持やピックアンドプレースを実現しました。この能力は、LLMの言語処理の枠を超え、実世界での物理的インタラクションに直接応用できる点で特に優れています。
4. データ効率:少量のインタラクションデータ
LLMのトレーニングには数十億トークン規模のテキストデータが必要である一方、V-JEPA 2は比較的少量のインタラクションデータ(62時間のロボットビデオ)でアクション条件付きモデルを構築できます。このデータ効率の高さは、自己教師あり学習による事前トレーニングが一般的な世界知識を効果的にエンコードしているためです。LLMが特定のタスクへの適応に大規模なファインチューニングを必要とすることが多いのに対し、V-JEPA 2は新しい環境へゼロショットで適応する能力を示します。
実験結果
V-JEPA 2は複数のベンチマークテストにおいて、以下の新記録を達成しました。
| タスクタイプ | ベンチマーク | V-JEPA 2 | 従来の最高記録 |
|---|---|---|---|
| 計画とロボット制御 | Reach(到達) | 100% | 100%(Octo) |
| Grasp(把持) | 45% | 8%(Octo) | |
| Pick-and-place(ピックアンドプレース) | 73% | 13%(Octo) | |
| 予測 | EK100(動作予測) | 39.7% | 27.6%(PlausiVL) |
| 理解 | Something-Something v2 (動作認識) | 77.3% | 69.7%(InternVideo2-1B Attentive probe) |
| Diving48 Attentive probe(動作認識) | 90.2% | 86.4%(InternVideo2-1B Attentive probe) | |
| Perception Test(知覚テスト) | 84.0% | 82.7%(PerceptionLM) | |
| MVPBench(ビデオ質問応答) | 44.5% | 39.9%(InternVL-2.5) |
これらの成果は、V-JEPA 2が単なる認識モデルを超え、物理世界の動的モデルとして機能し、観察から行動までを一貫して制御できることを実証しています。
LLMとの比較における限界と今後の展望
V-JEPA 2は、LLMと比較して物理世界の理解と計画に優れていますが、いくつかの限界があります。例えば、カメラ位置の変化への感度が高く、長期予測の精度が低下する傾向があります。また、LLMが持つ広範な言語知識や論理的推論能力を完全に代替することはできません。研究チームはV-JEPA 2とLLMの統合により、視覚と言語の両方で優れた性能を発揮するモデルの構築を進めていますが、完全な統合には更なる研究が必要です。
将来的に、V-JEPA 2の技術は多様なロボットタスクや複雑な環境への適応、さらには人間とロボットの協働作業へと応用が広がるでしょう。また、自己教師あり学習のスケーリング戦略の進化により、データ効率が向上し、リアルタイムでの学習や適応が実現できると期待されています。
結論
V-JEPA 2は、自己教師あり学習を活用し、ビデオデータから物理世界のモデルを構築する革新的なアプローチです。その独自性は、観察中心の学習、表現空間での予測、計画立案への直接応用、そして高いデータ効率にあります。これらの特徴は、LLMの得意とする言語処理とは異なり、物理世界での理解と行動に特化した強みとなっています。V-JEPA 2の成功は、AIが情報処理の枠を超えて、実世界で自律的に行動する未来への重要な一歩を示しています。この技術は、ロボティクス、自動化、インタラクティブシステムの分野に大きな革新をもたらすことが期待されます。
参考文献
- Assran, M., et al. (2025). V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning. arXiv:2506.09985v1.
- Code: https://github.com/facebookresearch/vjepa2
- Blog: https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks

Acrosstudio株式会社は、コンサルティング×生成AIスタートアップです。 コンサルティング事業に加え、自社でのVLM, RAG, AI Agentのプロダクト開発、生成AI/AI Agent業務設計等を推進しています。上場企業元CTOや、GAFA出身の生成AIエンジニアを中心に技術発信も行っていきます。
Discussion