まとめ
| フェーズ | 時期 | アルゴリズム/モデル名 |
|---|---|---|
| 初期の試み | - | LXMERT+ |
| - | VILBERT+ | |
| - | UNITER+ | |
| - | PIXEL-BERT+ | |
| 緩やかな始動 | 2021.01 | CLIP |
| 2021.10 | ALBEF+ | |
| 2021.11 | VLMO+ | |
| 2022.01 | BLIP+ | |
| 2022.04 | Flamingo+ | |
| 2022.05 | CoCa | |
| 2022.06 | VL-BEIT+ | |
| 2022.08 | BEiTv3 | |
| 発展の加速 | 2023.01 | BLIP-2 |
| 2023.04 | MiniGPT-4+ LLaVA |
|
| 2023.05 | InstructBLIP+ mPLUG-Owl+ |
|
| 2023.08 | Qwen-VL+ | |
| 2023.09 | GPT4V | |
| 2023.10 | LLaVA-1.5 | |
| 2023.11 | CogVLM Florence-2 |
|
| 2023.12 | Gemini | |
| 成熟化 | 2024.01 | Qwen-VL-Max |
| 2024.04 | Gemini 1.5 Pro Claude 3 MiniCPM-V |
|
| 2024.07 | InternVL 2.0+ | |
| 2024.08 | Qwen2-VL GLM-4V |
|
| 2024.09 | PHi-3-V 12B NVLM Llama-3.2 |
|
| 2024.11 | LLaVA-3D Step-1-V |
|
| 2024.12 | Gemini 2.0 DeepSeek-VL.2 |
|
| 2025.01 | InternVL 2.5 Janus-Pro(統一マルチモーダルモデル) Qwen-3-V Step-1o Vision |
|
| 推論能力の強化 | 2025.02 | Align-DS-V |
| 2025.03 | ERNIE 4.5 Manzano 3-27B-IT |
|
| 2025.04 | Step-R1-V-mini Kimi-VL A3B SemaNova v6 open-Al-s&o4-mini InternVL-3 |
|
| 2025.05 | BLIP3.0 (統一マルチモーダルモデル) BAGEL (統一マルチモーダルモデル) Storm1.0-VL |
|
| 2025.06 | Gemini 2.5 Pro(正式版) Kuai Keye-VL Ming-Omni(統一マルチモーダルモデル) SHOW-D2(統一マルチモーダルモデル) Skywork-V1(統一マルチモーダルモデル) |
|
| 2025.07 | GLM-4.1V-Thinking Skywork-R1V 3.0 Step-3 |
|
| 2025.08 | dots.vlm1 MiniCPM-V 4.5 |
|
| 2025.09 | Manzano Qwen3-vL |
第一段階:Oldモデル
Step1: 避けては通れないCLIP
Link: [2103.00020] Learning Transferable Visual Models From Natural Language Supervision

個人的に、CLIPは超大規模な検索システムのようなものだと感じています。非常にシンプルな構造と大量のデータを用いて、画像埋め込みとテキスト埋め込みの関連性を「記憶」するための対照行列を構築します。 推論時には、画像を与えて最も近い埋め込みを検索するだけです。 以下に、典型的な学習の擬似コードを示します。
# 各モダリティの特徴表現を抽出
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
# 結合マルチモーダル埋め込み [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# logits = [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 対称損失関数
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2
全体的な流れとしては、画像とテキストがそれぞれのエンコーダを経て埋め込みを取得し、正規化と温度係数付きの指数演算を行います。 なぜこれを行うかというと、(1) 0-1に正規化して後の損失計算を容易にするため(正解ラベルの相関行列は対角線がすべて1の行列であるため)、(2) 行列の分布を平滑化し、より良い収束を目指すためです。 もともと対照分布であり、クロスエントロピーに基づく多くの学習でも分布の平滑化は行われます。
CLIPはいわゆる「オープンセット」タスクの基盤モデルとして、膨大なカテゴリとそれに対応する画像を通じて検索行列を学習し、テキストカテゴリと画像を与えるだけでゼロショット分類を実現します。 しかし、この「オープンセット」自体は、単に非常に巨大なクローズドセットに過ぎません。 カテゴリが非常に多いため、ほとんどの自然画像のカテゴリをカバーでき、ゼロショットでの汎化が可能になっているだけです。 この点は、CLIPを小規模なドメインに転移させると明らかになり、結局はよく言われるOOD(Out-of-Distribution)問題に帰着し、新しいデータで転移学習するしかありません。
CLIPの細粒度の問題も明らかです。初期には、CLIPを直接使って物体検出やセグメンテーションのような低レベルのタスクを行おうとする研究が多くありましたが、結果は非常に悪かったです。 これは、CLIPがクロスエントロピーを用いて分布を学習するため、本質的には分類タスクであることに起因します(実際、分類タスクでの使用が大多数です)。 皆さんもバックボーンのヒートマップ可視化の経験があると思いますが、分類タスクで学習されたバックボーンを可視化すると、非常に乱雑で視覚的に意味不明な部分に集中していることがわかります。 実は、この部分が分類タスクを完了するための「プロキシトークン」として機能しており、clsトークンは後期に主にプロキシトークンから注意を「吸収」して最終的な分類タスクを完了します。 だからこそ、かなり早い時期からFPNやASPPのような、バックボーンから出力されたマルチスケールの特徴マップを融合してタスクヘッドに送る操作が存在するのです。 その本質は、分類のような非密集予測タスクと密集予測タスクの違いにあります。
対照的に、密集予測タスクはDINOやDINOV2のような自己教師あり学習で訓練されたバックボーンを好んで使用します。(最近DINOV3も出てきたらしいけど、まだ確認できてません)
DINOv2:[2304.07193] DINOv2: Learning Robust Visual Features without Supervision
これは、画像からの自己教師あり学習によって、様々なネットワークが詳細な情報を理解し、画像の顕著な表現を学習させるためです。抽象的な意味を持つラベルによる強い制約がないため、DINOが学習した特徴マップは、視覚的に人間の直感が注目したい領域に近くなります。 もちろん、これらはCLIPの特性と欠点を理解するためのものであり、より詳細な情報はネット上に無数のブログ記事がありますので、興味のある方はご自身で調べてみてください。
要するに、私の見解では、CLIPは我々が求めるVLMとは言えません。 それはVLMの補助として、画像やテキストの理解を提供するに過ぎません。 現在、CLIPの最も一般的な使用法は、そのエンコーダを使って特徴を抽出するなどの操作です。
Step2: SigLIP
Link: [2303.15343] Sigmoid Loss for Language Image Pre-Training
SigLIPの提案は、CLIPの学習コストを削減することを目的としています。 これはSigmoidとSoftmaxで処理された後の対照行列に関わるもので、ここでは詳細には触れませんが、CLIPの最適化版と捉えておけばよいでしょう。
Step3: BLIPとBLIP2
BLIPとBLIP2は基本的に考え方が似ているので、ここではBLIP2に沿って説明します。
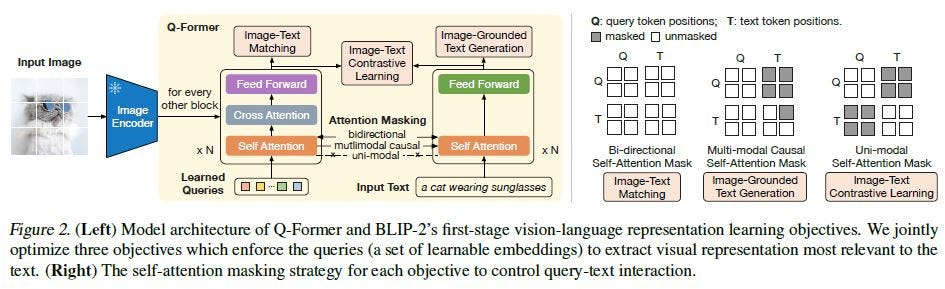
BLIP以降、VLMは現在のVLMの姿を現し始めました。 BLIPシリーズは、おそらく最も構造が複雑なVLMの一つでしょう。 提案されたQ-formerを学習するために、3つのタスクを構築しました。 それらは、画像テキストマッチング(ITM)、画像テキスト対照(ITC)、テキスト生成(ITG)です。 これら3つのタスクが何をしているのか?その中間のワークフローを話すよりも、各タスクの入力と出力が何であるかを理解する方が、かえって分かりやすいと思います。
まずQ-formerの入出力を説明します。入力は、ビジョンエンコーダを通した画像の埋め込み(img embedding)、一連の学習可能なクエリ(learnable query)、そしてテキストです。 画像埋め込みは、学習可能なクエリの学習を促すための追加の条件として機能し、学習可能なクエリは強化版のビジョントークンと理解できます。
-
ITC (Image-Text Contrastive): 画像とテキストの対照学習なので、自然とCLIPの対照学習が思い浮かびます。実際、BLIPも同様で、ITCは学習可能なクエリとテキストトークンの類似度を計算します。 ペアになったデータは類似度が高くなるべきで、最も高いものを類似度として選択します。 情報の相互漏洩を防ぐため、ユニモーダルなマスキング手法が用いられ、情報交換はゼロです。
-
ITM (Image-Text Matching): 対照学習に加えて、マッチングは何をするのか?これは二値分類タスクに相当し、各画像とテキストのペアは「一致」か「不一致」のどちらかです。 そのため、ITMの最後には二値分類のタスクヘッドがあり、入力されたテキストと一致するかどうかを判断します。 ここではマッチングが必要なので、お互いの情報が見えなければ、一致するかどうかを判断できません。 そのため、ここでは双方向(bi-directional)の可視性を持つマスクが使用され、画像とテキストの情報を相互作用させます。
-
ITG (Image-Text Generation): この生成タスクは何をするのか?ここではテキストと画像を入力し、テキストを生成します。 現在の自己回帰型LLMと同様に、画像のトークンをテキスト側の条件として与え、その条件と入力されたテキストに基づいて、Transformerデコーダが次に生成するテキストを予測します。 ここでの情報交換には単方向マスクのアテンションが使用され、画像トークンから情報を得るためです。 なぜテキストトークンが画像トークンから情報を得ることは許され、その逆は許されないのかというと、テキストの情報が画像トークンを偏らせ、後の結果に誤差を生じさせるのを防ぐためかもしれません。
では、このQ-Formerは一体何のためにあるのでしょうか?第2段階の学習がその答えを教えてくれます。 Q-formerの後ろにLLMを接続し、Q-formerが出力するのは学習可能なクエリ(つまり、テキストトークンと同じ意味空間に整列された画像トークン)です。 これを本来のテキストトークンと連結してLLMに送り、最終的に答えを生成します。 BLIP2がこれほど多くの複雑な設計をした大きな理由は、ペアになった画像テキストのマッチングデータを使ってVLMを構築したかったためです。 つまり、テキストトークンから意味空間の事前知識を画像トークンに与える手段がなく、この空間をより良く整列させるためでした。
Step4: Flamingo
Link: [2204.14198] Flamingo: a Visual Language Model for Few-Shot Learning

Flamingoの提案は、主にBLIPシリーズが画像とテキストのペアデータで学習しており、これにより文脈理解が著しく欠如し、一貫性が非常に悪く、ほぼ単一ターンの対話理解しかできないという致命的な問題に気づいたことに起因します。
この点に基づき、Flamingoは上図に示すように、画像とテキストが織り交ぜられたデータを収集しました。 画像の数に制限はなく、織り交ぜられたデータはテキスト+画像の形式に分割されます。 テキストは<image>というプレースホルダーで画像の位置を埋め、このテキストは一貫性があるものの何か(画像)が欠けている文章であり、その欠けた部分がモデル全体で予測すべき対象となります。
画像のエンコーディングも非常にシンプルで、Q-Formerに少し似ており、学習可能なクエリ(learnable query)を使って画像トークンの表現能力を強化します。 具体的には次の通りです。

すべての画像(動画の各フレームであれ、異なる画像であれ)は、まずVision Encoderを通過してX_fという画像トークンを取得します。 動画フレームの場合は、絶対的な時間エンコーディングが追加されます。 次に、学習可能なクエリX(図中のlearned latent queriesに対応)がQとして、X_fとXが長さ方向に連結されたものがKとVとして使用されます。 そして、Self-Attentionを通じて特徴を統合し、FFNに送られます。特別な設計はありません。 出力されたクエリは、LM内のGATED-XATTN-DENSEに送られます。

これも非常にシンプルな構造で、Self-Attentionブロックの前にTanhを持つゲート付きCross-Attentionがあるだけです。 論文にコードも記載されており、ほんの数行のものです。
一連の画像を与え、次に生成すべき言葉を理解させるという、テキストの続きを生成するような学習プロセスを採用しています。 この方法は、後のキャプション+インストラクションを用いた指示追従データの構築の基礎を築き、この時点で既に現在のVLMの雰囲気が漂っています。
Step5: LLaVa
Link: arxiv.org/pdf/2304.08485
LLaVaの登場は、ある意味でBLIPシリーズの顔に泥を塗ったと言えます。 BLIPは意味空間を整列させるために非常に複雑な構造を設計しましたが、LLaVaはたった一つの線形層(Linear)と大量のデータで、直接的に整列を達成してしまいました。

LLaVaのアーキテクチャは、言葉で言い表せないほどシンプルです。 画像トークンは、線形層を一つ通すだけで、テキストトークンの隠れ層の次元と直接整列されます。 凝った仕掛けは一切ありません。
データ面では、指示追従データ(instruction-following data)に進化しました。 モデルは、指示(instruction)と画像トークン(img token)に基づいて質問に答えます。 これが指示追従です。 最も簡単な例は、「Describe this image」という指示と一枚の画像を入力すると、モデルが「There is a cat in the grass」などと答え始めるものです。 彼らのデータ作成方法は、小規模なドメインでマルチモーダルモデルを構築する際の参考になります。 後続の多くのモデルのデータパイプラインも、この方法を様々に洗練させたものです。

方法は非常にシンプルです。収集したデータにはキャプションとバウンディングボックスが含まれており、いくつかの指示のテンプレートを決めます。 LLaVaでは、図にあるように「会話」「詳細な説明」「複雑な推論」という3つの大まかな指示タイプを定めました。 これらのタイプに基づいて質疑応答の形式を生成し、残りはGPTに任せます。 GPTは質問とキャプションに基づいて、一連の質疑応答形式の指示追従データを自動的に関連付けて生成します。 当時は使いやすいVLMが少なかったため、キャプションとボックスの取得が比較的困難でしたが、現在ではVLMが百花繚乱の時代となり、キャプションの取得方法も多様化しました。 自動ラベリング方式でも、プロンプトが十分に優れており、制約が多ければ、質の良いキャプションが得られます。 通常は、いくつかの例を用いてVLMにfew-shot方式で目的のキャプションを生成させます。
個人的には、LLaVaから、私たちが現在よく使用するVLMの時代が本格的に始まったと考えています。 VLMの役割は、画像や動画の様々な理解を助け、簡単な視覚タスクを行うアシスタントのようになっています。
第二段階:BaseModelの争い
この段階から、各社は主に大量のデータといくつかの前処理を用いて、以下の課題を解決し始めました:
- OOD問題: 学習セットが適合できる分布を拡大し、OOD問題を減少させます。実際には、ひたすらデータを追加し、大規模モデルに巨大な適合状態を形成させます(適合するシナリオが多く、範囲が広ければ、それは超強力な汎化性能に等しい)。
- 高解像度画像、複数画像、フレーム数の多い動画の処理方法: ほとんどの場合、トークンを圧縮するか、画像をリサイズして連結する処理を行います。
- 性能が低いタスクでの最適化方法: (これは企業の事業展開に関連します)
- Post-Trainingでベースモデルの上限をいかに引き上げるか。
実際、どの企業のVLMであっても、その発展の道のりは非常によく似ており、基本的には以下のアーキテクチャに従っています。
- 初代: BLIP2アーキテクチャ > LLaVa類似アーキテクチャ
- 修正: 様々な他のタスクに適応させ、弱点を強化し、データに多くの工夫を凝らす。
- 現在: Post-Trainingによるモデルの応答能力向上。CoT(Chain-of-Thought)最適化、各種RL(強化学習)手法の小さな最適化と組み合わせ、推論時間と学習コストの削減...
LLaVaシリーズ (Microsoft)
LLaVaの発表後、同年にLLaVa-1.5もリリースされました 。
LLaVa-1.5の構造も非常にシンプルで、LLaVaの線形層を2層のMLPに変更し 、高解像度の画像に対して以下の処理を行いました。

高解像度の画像をパッチに分割し、各パッチをビジョンエンコーダでトークンにエンコードします。同時に、元の画像をパッチと同じサイズにリサイズし、それもビジョンエンコーダでエンコードします。最後に、これらのトークンをすべて長さ方向に連結してLLMに送ります 。このような設計になっているのは、事前学習済みのViTが固定の解像度で調整されているため、このように分割して構成するしかないからです。リサイズしてからエンコードするのは、パッチ分割後に全体的な空間情報が失われるのを防ぐためであり、全体的な空間情報を保持するためにリサイズが行われました 。
データ処理
データ量は665Kに増加しました 。現在の基準ではこれは多くありませんが、LLaVaは当初、少量のデータで学習する路線を取っていました。しかし、後に超大量のデータで学習されたモデルには敵わないことが分かり、後期にはデータを追加しました。指示追従データの種類も多様化し、GPTの登場により生成されるデータの多様性も向上しました 。
それに加え、LLaVa-1.5のデータは、BLIPとLLaVaが短い質問への回答が苦手であるという現象に対して調整が加えられました 。BLIPがうまく答えられないのは、視覚トークンの長さが実際には学習可能なクエリの長さに大きく影響されるためです。この長さは学習時に固定されてしまいます。直感的に言えば、どのような画像が出力されても、LLMが受け取る視覚トークンは常に長さが固定されたクエリのセットであり、それが接頭辞として送られます。さらにBLIPはLLMの微調整を行わず、常に凍結していました。これにより、LLMは長さのパターンが比較的固定された回答を生成する傾向があり、長い回答と短い回答のバランスを取るのが困難でした。一方、LLaVaは質疑応答データが出力形式に制限を設けていなかったため、非常に短い回答をする傾向があり、命令の一部を無視することがありました 。LLaVa-1.5は、指示の後に(基本的には一文を追加するだけで)出力形式の制限を加えました 。

指示形式の例:
通常のプロンプト:
質問: What is the color of the shirt that the man is wearing?
回答: The man is wearing a yellow shirt.
フォーマット指定プロンプト:
質問: What is the color of the shirt that the man is wearing? Answer the question using a single word or phrase.
回答: Yellow.
短い質問は、元の質疑応答データを分解することで作成でき、これはChatGPTで直接解決できます 。
その後、LLaVaはすぐにNEXTバージョンとOneVisionバージョンをリリースしました。これらは主に特定の専門的な質問に対する性能を最適化し、それらの分野のデータを追加し、高品質な指示追従データや多様なQAデータを最適化するなどしました 。また、超高解像度の画像や動画については、パッチをエンコードした後に補間を行って視覚トークンの数を減らしました 。なぜなら、以前のパッチ分割はViTの事前学習解像度に適応するためだけであり、トークン数の最適化は行われていなかったからです。解像度が上がるとトークン数が急増し、学習コストも増加します。
LLaVaの最適化は、他のベースモデルの学習にもアイデアを提供しました。その後の多くのモデルは、実際にはLLaVaに似たモデル設計に従い、主にデータのクリーニングと高品質なデータの選別に多くの作業を費やしました 。LLaVa-OneVisionの学習データ量は約9Mで、他のモデルに比べれば比較的少なく、シンプルさと少量データが特徴です(とはいえ、現在の性能は比較的見劣りしますが) 。
InternVLシリーズ (上海AI Lab)
Project Link: GitHub - OpenGVLab/InternVL
InternVL-1.0
InternVL-1.0はBLIP2とほぼ同時期の研究です 。Link: [2312.14238] InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
InternVL-1.0が目指していることは、タイトルに明確に示されています。「視覚基盤モデルのスケールアップ」です 。そのため、一つの特徴はビジョンエンコーダをテキストエンコーダとほぼ同じパラメータ数まで拡張したことです 。
論文を見ると、全体的なアーキテクチャは以下の通りです。

全体的にはBLIP2に非常に似ていますが、ビジョンエンコーダを6Bにスケールアップしています 。具体的な学習方針は以下の通りです。

学習プロセス:
- 第一段階: ビジョンエンコーダとLLaMA-7BをCLIPのアーキテクチャで対照損失を用いて学習させ、ビジョンエンコーダに初歩的な意味理解能力(粗粒度)を持たせます 。この段階で、ゼロショットの画像分類と画像テキスト検索が可能になります 。
- 第二段階: 学習済みのビジョンエンコーダを凍結し、画像のビジョントークンをQ-llama構造に入力します 。このQ-llamaもLLaMAを改良したもので、学習可能なクエリ層とクロスアテンション層が追加されています 。学習時にはQ-llamaを凍結し、クロスアテンションのみを学習させ、空間的なアライメントを研究します 。この部分はBLIP2と大差なく、Q-formerをQ-llamaに置き換えたことで、元々LLaMAが持っていたキャプション生成能力により、キャプションタスクを完了できます 。この段階で実現できる機能は、入力: 画像 → 出力: 画像のキャプション です 。
-
第三段階: ビジョンエンコーダ、Q-llama、クロスアテンションをすべて凍結します 。この時点で視覚空間をテキスト空間に整列させる能力が備わっています。その後、Q-llamaの後ろにMLPを接続し、Vicuna-13Bに繋ぎます 。同時に、ビジョンエンコーダの後ろにもMLPを接続してVicuna-13Bに繋ぎます 。これにより、最終的なLLMの前で再度意味空間の整列を行います。
- 入力: 画像 + テキスト (オプション)
- Q-llamaの中間出力: 画像のキャプション
- Vicunaが受け取る入力: 画像 + 画像のキャプション + テキスト (オプション)
- 出力: 回答/対話/...
InternVL-1.0の学習プロセスは段階的に進み、タスクは簡単なものから複雑なものへと移行します 。そして、学習プロセス全体が比較的「安全」であり、アライメントも2回行われますが、その分学習コストも大きくなります 。
InternVL-1.1
1.1バージョンは1.0に比べて、Q-llamaを廃止し、LLaVaと同じMLPに置き換えました(ここでの進化の道筋は基本的に同じです) 。

学習に使用するビジョンエンコーダは依然として1.0のInternViT-6Bですが、学習全体の解像度を448に引き上げています 。解像度が高くなると、パッチサイズが変わらない一方でトークン数が倍増するという問題が生じます。計算効率を向上させるため、1.1ではエンコード後にPixel Shuffleを行いました 。これは後のバージョンでも視覚トークンを削減するためによく使用される操作です。もう一つの変更点は、LLMをVicuna-13BからLLaMA2-13Bに置き換えたことです 。
Pixel Shuffleコード
def pixel_shuffle(self, x, scale_factor=0.5):
n, w, h, c = x.size()
# N, W, H, C --> N, W, H * scale, C // scale
x = x.view(n, w, int(h * scale_factor), int(c / scale_factor))
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
x = x.permute(0, 2, 1, 3).contiguous()
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
int(c / (scale_factor * scale_factor)))
if self.ps_version == 'v1':
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
'which results in a transposed image.')
else:
x = x.permute(0, 2, 1, 3).contiguous()
return x
Pixel Shuffleは、空間次元を4分の1に圧縮し、その圧縮分をチャネル次元に補填することで、チャネル数が以前の4倍になります 。これにより、より多くの情報がチャネルに圧縮され、後続のMLPが必要な次元に整列させます。チャネル数とトークン数のトレードオフにおいて、トークン数を減らす方が計算量が大幅に少なくなることは明らかです(主に推論コストを考慮して) 。
1.1の学習は2つの段階に簡略化されました 。
- 第一段階: ビジョンエンコーダとMLPのみを学習させます 。この段階では72Mのサンプルを使用してビジョンエンコーダを学習させ、解像度への適応と、意味空間を整列できるMLPの学習を行います 。
- 第二段階: モデル全体の言語理解力と命令追従力を向上させる段階でMLP+LLMだけを訓練します。
このあと1.2もあるけど、個人的に大きいな変化がないかと思って、スキープしましたが、興味ある人は公式blogを見てください。Link: InternVL 1.2: Scaling up LLM to 34B
InternVL-1.5
Link: [2404.16821] InternVL-1.5: Any-Resolution Visual Foundation Model

1.1以降、InternVLのアーキテクチャに大きな変化はなく、依然としてビジョンエンコーダ + MLP + LLMのアーキテクチャが中心です 。1.5バージョンでは、元のビジョンエンコーダに構造的な簡素化が加えられ、一部の層が削除されましたが、パラメータ数は6Bのままです 。エンコード後もPixel Shuffleが使用されます。

1.5の主な革新はDynamic High Resolutionです。解像度の大きい画像に対して、まず事前に定義された35個のアスペクト比の中から、入力画像に最も近いものをマッチングさせます 。そして、画像を448解像度のタイルに分割します。分割後、リサイズによって高解像度画像全体のサムネイル(thumbnail)を取得し、全体的な情報を補完します 。
学習は以前のバージョンと同様に2段階で行われます。第一段階でビジョンエンコーダとMLPを学習させ、第二段階で全パラメータSFT(教師ありファインチューニング)を行います 。
InternVL-2.0
Link: InternVL 2.0 Technical Report
InternVL-2.0では、モデルのスケール範囲が1Bから108Bまで拡大され、大小さまざまなサイズのモデルをカバーできるようになりました 。1.6Bから8Bのモデルでは、InternVL-2.0は巨大な6Bのビジョンエンコーダを廃止し、300Mに最適化しました 。これは、InternVL-1.0の「ビジョンエンコーダのスケールアップ」という方針を覆すものです。
その他の構造に新しいものはなく、Pixel ShuffleやDynamic High Resolutionは引き続き採用されています 。

学習は依然として2段階です。第一段階では、データをスケーリングした後、1.5バージョンをベースにMLPのみを学習させます 。第二段階では、さまざまな高品質なバイリンガルデータを収集し、第一段階をベースに全パラメータSFTを行います 。
InternVL-2.5
Link: [2407.05271] InternVL 2.5 Technical Report
論文形式で発表された2.5では、いくつかのトリックが導入されました 。
Trick 1: 構造の微調整
6Bのビジョンエンコーダでは、LayerNormをRMSNormに置き換え、平均値を引く操作を削除しました 。その理由は、計算効率の向上と、QK間の方向関係を維持することで、RoPEやAttentionの計算とより適合させるためです 。ベクトルから平均値を引くと方向が大きく変わってしまう可能性があり、アテンション計算時の
Trick 2: 統合された学習戦略
学習戦略は「single model training + Progressive Scaling Strategy」です 。

まず、比較的小さなLLM上で学習させたビジョンエンコーダでも強力な視覚能力を学習できることが分かったため、single model training を用いてビジョンエンコーダを訓練します 。これは3段階に分かれます:
- Stage 1: MLPのみを訓練(MLP Warmup)。
- Stage 1.5: ビジョンエンコーダとMLPを訓練。
- Stage 2: 全パラメータSFT。
この3段階を経ると、VLMの形が整います。その後、LLMをより大きなものにスケールアップする場合、このビジョンエンコーダを直接再利用できます。これが Progressive Scaling Strategy です 。大きなLLM上では、第一段階でMLPを訓練し、第二段階で直接全パラメータを訓練します 。
Trick3: 訓練中のデータ増強とloss設計
ランダムJPEG圧縮: 75から100の品質(満点は100)で画像をランダムにJPEG圧縮し、ノイズのある画像に適応させ、過学習のリスクを低減します。
loss設計: まず、現在主流の2つのNTP loss(実際にはクロスエントロピー)の形式を分析します。
token averaging loss と sample averaging
まず、本文で言及されている token averaging の劣っている点について説明します。これは、各tokenが平等に扱われるため、モデルが長い回答を生成する傾向を持ってしまうからです。仮に、1つのバッチに長い回答Aと短い回答Bの2つのサンプルしかないとします。
A:
token数100、各tokenのlossが0.5
B:
token数10、各tokenのlossが1.5
このバッチの総lossを計算すると、
では、sample averaging はどうでしょうか? 上記のAとBの回答を例にとると、sample averagingはまず各回答サンプル内の平均lossを計算します。したがって、Aのlossは0.5、Bのlossは1.5となります。この時、Bのlossが全体の75%を占めることになり、モデルはBの回答を最適化する傾向が強まります。しかし、我々はAが無視されることも望んでいません。そこで、InternVL-2.5で改善された Loss Reweighting が導入されました。
上記の問題に対し、Loss Reweightingの考え方は、上記の式の
これを計算すると、それぞれのlossの比率がより均等になります(少なくともtoken averagingとsample averagingよりはバランスが取れています)。
個人的には、データ収集とフィルタリングについては特に説明する必要はなく、最新のバージョンの手法に従うのが良いと考えています。
InternVL-3
Link: [2504.10479] InternVL 3
InternVL-3の構造は2.5とほぼ同じで、visionエンコーダは依然として300Mと6Bの2つのレベルを採用しています。LLMにはQwen2.5とInternLM3-8Bが採用されていますが、9BのモデルでのみInternLM3-8Bが使用され、その他はすべてQwenです。
また、位置エンコーディングにはV2PEが採用されており、V2PEはvisionトークンの外挿能力を拡張し、mllm(マルチモーダル大規模言語モデル)がより長いコンテキストを扱えるようにします。このV2PEについて説明します。仮にサンプルが
PE計算式
通常、textトークンであれvisionトークンであれ、位置は後方に順次増加していきます(つまり、このインデックスはtextとvisionを区別しません)。V2PEではこの操作を次のように変更します:
V2PEのindex計算
もしtextトークンであれば+1し、visionトークンであればより小さい
vision tokenのより小さいindex
訓練プロセスの最適化: InternVL-3は、インタリーブされたマルチモーダルデータと純粋なテキストデータを直接ファインチューニングに使用します(純粋なテキストデータの追加は、マルチモーダルデータによる短い応答の問題を緩和するためです)。理論的には、モデルが多様なマルチモーダルタスクに適応できるようにするためです。以前の事前学習段階のようにタスクを分離し、段階的に単純なタスクから複雑なタスクへと調整するのではなく、InternVL-3は2.5をベースに直接マルチモーダルデータでフルパラメータのファインチューニングを行い、性能が大幅に向上しました。
Post-Training: SFT+MPO。InternVL-3はRL(強化学習)を使用しました。第一段階はSFT(教師ありファインチューニング)で、これについては特に説明することはありません。元のテキストと比較して、より多様で精緻なデータを使用したという点です。
SFT段階をInternVL2.5と比較すると、InternVL3のSFT段階での主な進歩は、より高品質で多様なGUI操作、長文対話、タスクプランニング、科学図解、創造的な文章作成、抽象的な推論のデータを使用した点にあります。
MPO (Mixed Preference Optimization): このアイデアは、分布シフトという一般的な概念から来ています。その意味は、訓練時にモデルがt番目のトークンを予測する際、先行するt-1個の正解トークンに基づいて予測が行われるということです。したがって、訓練段階のシーケンスはすべて正解の情報ですが、推論時にはそうではありません。推論時には、先行するt-1個のトークンはモデル自身が生成したものであり、正解トークンではありません。この時、モデルは誤った予測や次善のトークンを予測する可能性があり、その誤差が蓄積され、生成される回答と正解との差がどんどん大きくなっていきます。特にCoT (Chain-of-Thought) のような状況では、この現象は非常に拡大されます。
この現象に対応するため、MPOは以下の3つのlossをそれぞれの重みで組み合わせています:
MPO loss
ここで、
選好損失にはDPOの損失が使用されます:
DPO loss
DPOについてはここでは詳しく述べませんが、要するにこのlossの意義は、モデルにどちらの回答が良いかを判断させ、悪い方の回答を棄却するように学習させることです。
品質損失にはBCOのlossが採用されています:
BCO loss
BCO lossの各項
InternVL-3.5
Link: [2508.18265] InternVL 3.5
InternVL-3.5はMoEモデルになりました(実際にはQwen3がMoEであるため)。以下のモデルがあります:

見たところ、LMをQwen3に置き換え、3.5の各種微調整を加えたようです。

以前のバージョンとの違いとして、MLPの名前がVision-Language Connectに変更され、2つのモジュールに分割されました。一つはMLPで、もう一つの新しいバージョンはVisual Resolution Routerです。このルーターは高解像度版で使用され、各トークン(元々は1024個)に対して256個のルーターの出力でpixel shuffleを行い、豊富な圧縮を実行し、最適な圧縮率を決定することで、豊富なセマンティック情報が失われないようにします。その後、この圧縮された特徴マップに対して再度pixel shuffleを行い、次元数を50%以上削減しつつ、性能をほぼ100%維持します。
Pretrain: データセットを拡張し、標準的なNTP lossで訓練。
Post-Training: 以下の3つの段階に分かれています。

InternVL-3.5の3段階post-training
SFTは、より多様で質の良いデータでオフライン訓練を行っただけで、特に言うことはありません。RL部分はCascade RLに変更され、主にMPOとGSPOを使用します。MPOはオフラインRLであり、3.0の内容で述べたものから変更はなく、そちらを参照してください。オフラインRLは収束が速いですが、初期性能に劣ります。次にオンラインRLのGSPOですが、GSPOはQwenが7月に提案したRLアルゴリズムです。ここでは詳細には触れず、大まかな内容のみを話します。post-trainingを専門とする方は、Group Sequence Policy Optimizationを参照してください。
where
is the i-th response generated for the query y_i , G is the total number of generated responses to the query, and x denotes the reward for this response. The training objective of GSPO is given by: r(x, y_i) \mathcal{L}_{GSPO}(\theta) = \mathbb{E}_{x \sim \mathcal{D}, \{y_i\}_{i=1}^G \sim \pi_{\theta_{old}}(.|x)} \left[ \frac{1}{G} \sum_{i=1}^{G} \min(s_i(\theta)\hat{A}_i, \text{clip}(s_i(\theta), 1-\epsilon, 1+\epsilon)\hat{A}_i) \right] \quad (5) where the importance sampling ratio is defined as the geometric mean of the per-token ratios:
s_i(\theta) = \frac{\pi_\theta(y_i|x)}{\pi_{\theta_{old}}(y_i|x)} = \exp \left( \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \log \frac{\pi_\theta(y_{i,t}|x, y_{i,<t})}{\pi_{\theta_{old}}(y_{i,t}|x, y_{i,<t})} \right) \quad (6) where
and \pi_\theta(y_i|x, y_{i,<t}) denote the generation probability of response \pi_{\theta_{old}}(y_i|x, y_{i,<t}) under the policy model with parameters y_{i,t} , respectively. \theta
GSPO
GSPOの核心は、異なる長さの系列に対して重要度サンプリングを行った点です。PPOやGRPOは系列長に比較的鈍感ですが、分散が大きいため訓練が不安定になりがちです。GSPOは系列空間の平均で重要度サンプリングを行い、各トークンのlog ratioを平均化し、シーケンスを正規化することで、シーケンス長による偏りを減らし、各長さの系列の性能がほぼ同じレベルに近づくようにします。その後、InternVL-3.5では、MPOの報酬収集は比較的遅いものの安定しており、解釈もしやすいことが分かりました。MPOには選好データがあり、さらにBCO lossが存在するため、回答の良し悪しを絶対値で判断でき、reward hackingを非常によく抑制できます。
ps: reward hackingとは、モデルがプロセス上は正しいように見えて報酬モデルから高い報酬を得るものの、実際には質の低い回答を出力するように学習してしまうことです。
そして、MPOの基礎の上にGSPOを訓練することで、モデルが一定レベルの高品質な応答を保証し、集団で質の低い回答に陥る状況を避けます。個人的にはMPOが核心であり、GSPOはここではおまけのようなものだと考えています(やはりトレンドを追う必要があるからでしょう)。
Visual Consistency Learning: この段階はFlash版のInternVL-3.5を訓練するためのものです。追加で参照モデル(reference model)を導入し、全体の訓練目標は以下のようになります:
where KL denotes the KL divergence and
denotes the compression rate, which is uniformly sampled from \xi . The image \{\frac{1}{16}, \frac{1}{4}\} is represented as 256 tokens when I_c and 64 tokens when \xi=\frac{1}{16} . The reference model always performs inference with \xi=\frac{1}{4} . \xi=\frac{1}{4}
Visual Consistency Learning loss
ここで、参照モデルは凍結され、圧縮率は常に1/4に保たれます。一方、ポリシーモデル(policy model)は更新されるモデルで、圧縮率は
Router Training: この部分はルーターを訓練するためのもので、このルーターは二値分類器です。その出力は、各パッチを高解像度で圧縮するか低解像度で圧縮するかを決定します。
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
where
and y_i^{router}=0 indicate that the compression rate y_i^{router}=1 is set to \xi and \frac{1}{4} , respectively. \frac{1}{16}
Router training
まず比率
Test-Time Scaling: これまでの基礎の上に、Deep Thinkingモードを有効にすることができます。まずCoTの回答を一つ生成し、その後、Deep Thinkingが同時にBest-of-Nの回答を取得し、最後にVisualPRM-v1.1を用いて最適な回答を選択します。この部分と3.0との区別はそれほど大きくありません。
残りの内容は推論と訓練の最適化に関するものですが、この部分は私もよく理解していないため、ひとまず誤解を含む可能性のある解釈として読んでいただければと思います。
Qwen-VLシリーズ
初代Qwen-VL
Link: [2308.12966] Qwen VL
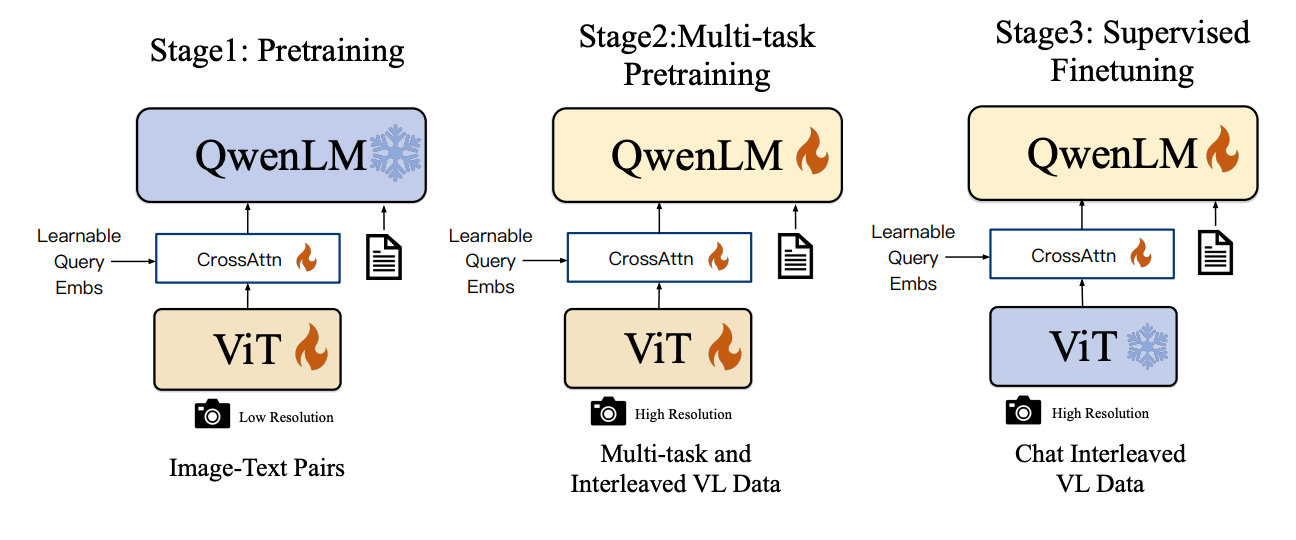
初代Qwen-VLは、CrossAttentionを用いて視覚と言語のモダリティを連携させます。VisionエンコーダはViT-bigG、LMは7BのQwen-LMで、学習可能なクエリ(Learnable query)を用いてViTと対話します。訓練は3つの段階に分かれています。Pretrainingでは視覚と言語の連携のみを行い、初期の知覚能力を構築します。迅速な収束のために、まず低解像度の画像を用います。Multi-task pretrainingでは前の段階を直接ファインチューニングし、この時点で入力画像は高解像度になります。visionエンコーダ、LM、crossattentionをファインチューニングします。最後のSFTでは、visionエンコーダとcrossattentionをファインチューニングします。
初代のQwen-VLは多くの内容を含んでいましたが、主に最初の試みでした。その後更新されたQwen-VL-MaxとPlus版は、このアプローチをスケールアップさせたものです。
Qwen2-VL
Link: [2409.12191] Qwen2 VL
他のモデルの迅速な更新とは異なり、Qwen2-VLは初代から一年経って発表され、今回のベンチマーク対象はGPT-4oです。構造上はCrossattention + Learnable queryのQ-former方式を廃止しています。構造は以下の通りです:

Qwen2-VLの構造
LMにはQwen2、Visionエンコーダには600M程度のViTが採用されており、このViTは任意のアスペクト比の画像と動画をサポートしています。さらに、Qwen2-VLのVisionエンコーダはネイティブ解像度入力をサポートしており、ユーザーは画像をリサイズしたりクロップしたりする必要がありません。画像は自動的に小さなパッチに分割され、ViTに入力されます。
これはtokenシーケンスにtoken数を追加することに等しく、パッチ数の位置変化に対してLLMがより敏感になります。以前のアーキテクチャは、画像token数の変化に適応し、パッチ間の相対位置関係をより良くモデル化するために2D-RoPEに変更されました。しかし、token数は制限されています。Qwen2-VLは、インタリーブされた視覚言語データからのvision tokenをパッキングし、最大token数を制限した後、2x2のtokenに隣接するMLPで1次元に平坦化し、冗長な情報を削減します。
M-RoPE: この多モーダル入力に適応するため、Qwen2-VLはRoPEを拡張しました。すべてのモダリティのすべてのtokenがこのM-RoPE方式を使用します。違いは、LMが視覚tokenを処理する際には2D-RoPEが使用される点です。Visionエンコーダに2D-RoPEが再導入された理由については、論文で説明されています。

簡単です。M-RoPEは3つの次元のデータを持ちます。単一の画像では、THW(Time、Height、Width)は不変です。フレームごとにHとWは固定されていますが、動画では各フレームのTインデックスが異なります。T、H、Wのインデックスは連結され、例えば(4, 4, 1)のようになります。同じ動画の次のフレームでは、Tが変わり、(5, 5, 5)のようになります。すべてのトークンを1次元のインデックスに統一することで、PEでエンコードできるようになります。
画像と動画の処理のまとめ: 要するに、Qwen2-VLは画像と動画を両方とも動画として扱います。連続性を可能な限り維持するため、すべての動画は毎秒2フレームでサンプリングされます。30秒の動画は60フレームになり、FPSの影響を排除します。長い動画はフレームにサンプリングされて平坦化されます。高解像度をサポートするため、Qwen2-VLは動画のパッチ解像度を16384に設定し、すべてのフレームtokenをこの上限内に収め、時間情報を保持するために連結します。使用されるViTは3D-Convで、時間的には体積(volume)に相当し、時空間関係をより良く捉えることができます。
動画処理を行ったことがないため、上記は資料をまとめただけです。実際のQwen2-VLは動画を直接マッピングし、1秒の動画を1秒のフレームとして扱います。これも3D-convに適応でき、画像と動画をViTに対して統一的に訓練することができます。
訓練フォーマット(SFTとPretrainは同じ)
データ形式: 指示データはChatMLの形式に従います(Openaiと同じ)。
<|im_start|>user
<|vision_start|>Picture1.jpg<|vision_end|><|vision_start|>Picture2.jpg<|vision_end|>What do the two pictures have in common?<|im_end|>
<|im_start|>assistant
Both pictures are of Spongebob Squarepants.<|im_end|>
<|im_start|>user
What is happening in the video?<|vision_start|>video.mp4<|vision_end|><|im_end|>
<|im_start|>assistant
The protagonist in the video is frying an egg.<|im_end|>
ChatML形式のデータ
<|im_start|>と<|im_end|>で文の開始と終了を示し、<|vision_start|>と<|vision_end|>でメディア入力の位置を示します。
Groundingタスクでは、すべての座標は元の解像度に基づいて0-1000の範囲内に正規化されます。
Qwen2.5-VL
Link: [2502.13923] Qwen2.5 VL Technical Report
Qwen2.5-VLは、実際には特に大きな変更はなく、構造は以下の通りです:

LM部分はQwen2.5に更新され、Visionエンコーダは引き続きネイティブ解像度を維持しています(実際にはネイティブではなく、ViTに送るために14と28の倍数に縮小されます)。2D-RoPEも引き続き使用され、内部のほとんどのBlockはウィンドウアテンション(Window Attention)に変更されました(ViTが大半Swin Transformerに圧縮されたようなものです)。そしてMLPがtokenの圧縮に使われ、元の画像位置の2x2の位置にあるtokenが1つのtokenに圧縮されますが、実際にはチャネル数は増加しています(情報損失を防ぐため)。以下の図の通りです。
Vision-Language Merger
| In Channel | 1280 | 1280 | 1280 |
|---|---|---|---|
| Out Channel | 2048 | 3584 | 8192 |
MLPのチャネル変化
動的FPS+絶対時間エンコーディングのM-RoPEへの追加: Qwen2の説明では、動画を毎秒2フレームで処理すると述べましたが、すべての動画がそうであるとは限りません。もし元の動画のfpsが非常に高い場合、失われる情報が非常に多くなります。2.5ではこの基礎の上で、動的FPSと絶対時間の次元を結合してPEを最適化するという問題を解決しました。2.5はPEを最適化する方法を捨て、代わりに絶対時間のテキストタイムスタンプを用いてインデックスを決定する方法を採用しました。つまり、1秒目のインデックスは1、2秒目のインデックスは2という概念です。これにより、FPSの選択が動的になり得ます。人間の直感では、ある動作は何秒目から始まると認識されるためです。この方法の良い点は、fpsがいくつであれ、フレームと絶対時間を対応させさえすれば、モデルは何秒目に何の内容があるかを把握できることです。
Seed1.5-VLシリーズ
Link: [2505.07062] Seed1.5 VL

Qwen2-VLとInternVL-3.5のVisionエンコーダであり、Vision Encoder+MLP+LLMの構造に基づいています。初代Qwen2-VLも同様に、エンコーダに2D-RoPEを使用し、visionエンコーダの出力を2x2でプーリングした後、2層のMLPを経て言語空間との連携を行います。
Seed-ViT: 先にQwen2-VLとInternVL-2.5を少し話しましたが、それらのViTは事前学習の重みでファインチューニングされており、きめ細かな特徴に対する知覚能力が失われていると感じました。これは試してみて分かったことです。Seed-ViTは、固定されたCLIPに直接接続し、各パッチが1つのトークンに対応し、ファインチューニングに大規模モデルを介さないことで、この問題を解決しようとします。つまり、視覚部分をしっかりと行い、大規模モデル側のユーザー体験のフィードバックが悪いという状況を避ける、というのが基本的なロジックです。
Seed-ViTの訓練は3つの段階に分かれています。

Seed-ViTの訓練プロセス
第一段階 PW-MIM (Part-wise Masked Image Modeling): 2D-RoPEのViTを用い、自己教師あり学習のMAE+蒸留方式に似たプロセスで訓練します。新たにSigLip lossを導入し、studentとteacherを比較するというアイデアです。EVA02-CLIP-Eがteacherとなり、studentの画像パッチ埋め込みの75%をマスクします。そして、studentにマスクされた位置の特徴とteacherの対応位置の出力を近づけるようにさせ、タスク全体を回帰タスクにします。
第二段階 PW-NCR (Part-wise Native-resolution Contrastive Learning): EVA02-CLIP-Eをteacherとして、SigLip loss + Superclass lossの2つの損失で訓練します。なぜSuperclass lossが使いやすいかというと、CLIPの訓練がきめ細かくないため、損失比較もbeに基づいて最適化されており(その方が簡単)、このSuperclass lossが生まれました。例えば、catとdogはどちらもdogですが、より細かく対比するとcatとdogはanimalになります。Superclass lossは多層的な意味ラベルを構築するためのものです。CLIPは画像だけでなくテキストも扱うため、animalの後にさらに他の分類が可能です。具体的な実装は元の論文2411.03313を参照してください。最終的にSuperclass lossに統合されます。
第三段階 O-M Pre-training (Omni-modal Pre-training): この部分はフルモーダル訓練で、audioを追加します。MiCoの訓練フレームワークとaudioエンコーダを使用し、textエンコーダの出力をアライメントさせ、2つのユニモーダルエンコーダの出力もアライメントさせます。
訓練段階で最も重要なのは第二段階で、この段階では91.2%のtokenを訓練し、ViTに強力な基礎能力を持たせます。
次に動画エンコードについてですが、Dynamic Frame-Resolution Samplingを用いてデータを処理します。これはQwen2.5-VLの処理方式と同じです。タスクに応じて、例えば動画キャプションではfps=1でサンプリングし、時間的情報を必要とする行動認識のようなタスクではfps=2、動きの激しい動画ではfps=5でサンプリングします。

フレームの前にテキストのタイムスタンプを追加
上の例では、fps=1の時は各フレーム間の時間間隔が1.0秒、fps=2の時は0.5秒、fps=5の時は0.2秒です。このようにして、モデルにとって時間が概念化され、例えば行動認識タスクで、何秒目にどの動作が起きているかを把握できるようになります。もしフレームの差分だけを用いると、時間は完全に不確定になってしまいます。
次に、事前学習の段階です。

3つの段階があり、第一段階ではMLPを訓練し、第二段階では高品質なマルチモーダルコーパス(Grounding、OCRなどを含む)で全パラメータを訓練します。第三段階も似ていますが、シーケンス長を増やし、文脈理解、データバランスを強化し、動画理解と3D理解を追加します。
Post-Training段階: Seed1.5-VLはpost-trainingで多くの試みを行っています。

SFT段階: データは主に2つの部分から来ます。一つは、指示に従ってベースモデルで回答を生成すること。もう一つは、データ量は多くありませんが、各タスクのデータ分布を均衡させるために慎重にクリーニングされていることです。LongCoT (Thinking) データを使用し、プロンプトエンジニアリングと棄却サンプリングを通じてこの種のデータを収集します。このデータパイプラインについては、もう少し詳しく説明したいと思います。
- 第一歩: 「指示+シード+人手ラベル」による13000件以上の高品質データを用い、多様なタスクをカバーする13000パラメータ版のベースモデルをファインチューニングし、基本的なタスク遂行能力を持たせます。
- 第二歩: 160万の画像テキストペアから、image-text embeddingを用いて全データをクリーニングします。どのように行うかは、基本的にはタスク関連のデータを収集することです。その後、クリーニングされたデータに対してマルチラウンドの対話を行い、モデルに同じプロンプトで複数回の回答(ロールアウト)を生成させ、後の工程で扱いやすい形式で表現します。
- 第三歩: 生成されたものをLLM-as-a-Judgeで評価し、概念的な回答が正しいかを判断します。その後、選好選択を持つ報酬モデルを用いて最も良い回答を出力し、スコアリングすることで、高品質なデータの選択を促進します。最後のステップは、3万件のデータに対して最も良い回答を選択することです。実験により、これは報酬モデルによる自動的なデータ選択よりも優れていることが証明されています。
第二歩で述べた報酬モデルもVLMであり、最初のSFT段階のモデルで初期化されます。ほとんどのVLMの報酬モデルは、出力トークンに新しいヘッドを追加してスコアリングを行いますが、この方法は不自然で文脈情報が欠けています。そのため、Seed1.5-VLの報酬モデルは直接回答をモデル化し、モデルに特殊なトークンの中からより良い選択肢を選ばせるようにします。これは「回答AとBのどちらが良いか」と尋ね、モデルが「回答Aが良い」と答えるのに似ており、より自然でLLM自身の応答スタイルに合致しています。報酬モデルのデータ収集も同様の方法で行われます。
人手によるラベリング
- 回答の質に注力し、モデル内部で複数の回答を生成し、その中から最適なものを選択する。
- 各回答を多角的に評価する:正しさ、言語スタイル、長さの適切さなど。
- 修正版の回答を生成する。提供された回答が良くても、言語をより簡潔に、ロジックをより明確に、内容をより完全にすることで改善できる。
- 非言語的なフィードバックを提供する。これは報酬モデルのためで、詳細な説明が望ましい。
- ソートとフィルタリング。他のモデルで処理を高速化し、人手のアノテーターがその結果を参考に直接ラベリングする。
データ合成
- 正解(ground-truth)のあるデータを選択する。各プロンプトに対し、モデルにK個の回答を生成させ、LLM-as-a-Judgeで各回答の良し悪しを判断する。
- リストワイズのプロンプト判断:正解(+)と不正解(-)の回答。
- オプションワイズの判断(中難易度):正解+誤った選択肢のある回答(誤り)。キャプションタスクでは、洗練された回答とモデル生成の回答を用い、Preference Strengthでスコアを調整する。
Seed1.5-VLには良い視点がある:なぜ正解を修正したり、不正解のサンプルを捨てたりしないのか?それは、このようなサンプルでは「何が良い回答か」ではなく、「どちらの回答がより良いか」を学習しているためだ。これは理解しやすい。モデルに常に質の悪いものばかり与えていると、その一部に同化してしまい、抑制が難しくなる。いくつかの簡単な例を与え、核心的な内容を掴ませる方が良い。
RLHF段階
Seed1.5-VLはPPOを使用しています(財力に物を言わせていますね)。RLHF段階では、前のSFT段階で収集したデータセットを用いて訓練し、データのあらゆる側面を完全に活用・カバーします。まず、データに対して選好分類を行うタギングモデルを訓練します。その後、複数の候補回答を生成し、この分類器でフィルタリングしてベースラインの品質を保証します。初期段階の報酬とKLレベルをバランスさせ、高品質な回答の探索を効果的に促進し、報酬ハッキングを防ぎ、簡単なタスクへの過学習を減らします。
Reinforcement Learning with Verifiable Rewards (RLVR)
この段階は、モデルのドメイン知識とプロンプトの要求を正確に理解し、一時的に戦略を無視することに焦点を当てています。詳細は後ほど。
Hybrid RL
Seed1.5-VLのRLはPPOに基づき、RLHFとRLVRを組み合わせています。ここでは4つの部分に分けられます。
-
Reward:
<think>{thought}</think><solution>{solution}を含む通常の報酬フレームワークを使用し、フォーマットチェックで報酬を与えるかペナルティを与えるかを判断します。 - Verifiable reward: 思考プロセスについては、最終結果が正しいかどうかにのみ注目し、推論過程は無視します。ステップが多様であるかどうかも気にしません(これは以前の厳格なデータフィルタリングとは異なります)。
- Shared critic: 報酬モデルと検証器は共通のvalueを共有します。PPOはKL側にあり、2つの報酬モデルがvalueを共有できます。
- Reward hacking: 検証可能な問題が少ない場合、いくつかのRLロールアウト(生成回答数が多い)を追加して、検証可能なデータが不足する問題を解決できます。
- No roll-outs: 発散度の高いプロンプトに対しては、ロールアウトを少なくする方が良いです。
まとめると、「高品質な回答を収集 → SFTモデルを更新 → RLプロセス」となります。LongCoTを用いてコールドスタートモデルを生成し、マルチラウンド対話のPPOループで選好モデル用のデータを収集します。このデータで訓練された報酬モデルを、新しいRLループで用いて第二世代のRLモデルを訓練しますが、その際は正しいデータのみを使用します。これは**自己改善(self-improvement)**モデルです。このプロセスは非常に特別です。
InternVLとSeed1.5-VLのエンジニアリングについては、まだよく理解できていません。データクリーニングとラベリングには膨大な労力がかかっています。Seed1.5-VLが成功したのも、ベンチマークが非常によく整合しているからでしょう。
GLMおよびCogVLMシリーズ
CogVLM
Link: [2308.12966] CogVLM: Visual Expert for Pretrained Language Models
CogVLMは23年の研究で、モデル全体の構造もLLaVAに類似したViT-MLP-LLMの形式です。以下に示します。
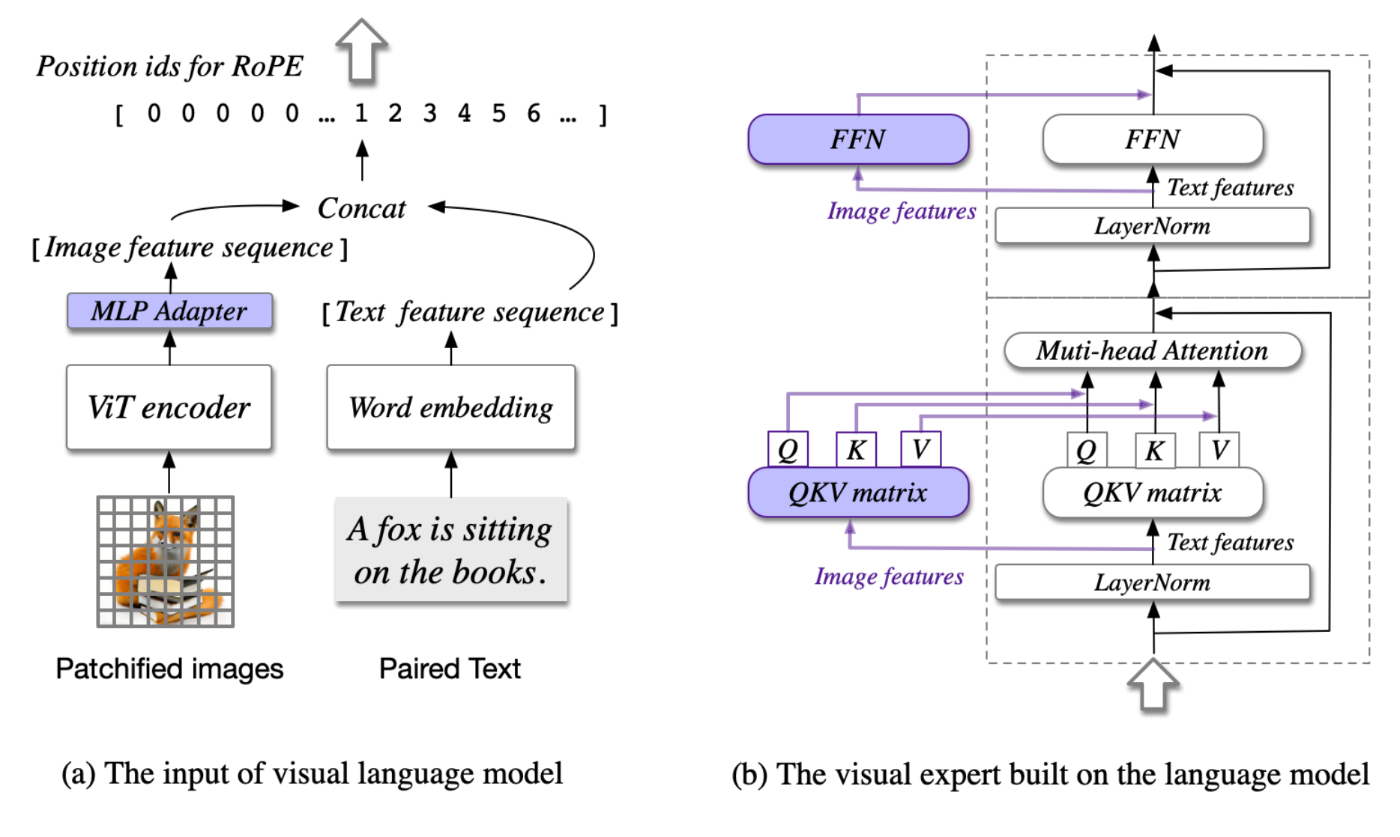
CogVLMの構造
全体の構造は前のシリーズのモデルと大差ありません。ここで強調すべきは、CogVLMが純粋なテキストデータで十分に訓練されたLLMをVLM訓練に用いると、スイッチを全開(フルパラメータファインチューニング)にすると壊滅的忘却を引き起こすと考えている点です。そして、この点を検証する実験を行いました。以下に示します。

壊滅的忘却の検証実験
LAIONデータセットを用いてVLMを訓練した際、訓練損失(training loss)は減少していますが、純粋なテキストのMMLUスコアも低下しています。この現象を用いて壊滅的忘却を説明するのは、やや偏った概念だと個人的には思います。まず、LAIONのデータ自体がそれほどクリーンではありません。さらに、LLM自体の事前学習データセットと数量には大きなシフトがあるため、VLM訓練時のデータ量がScaling則とLLM事前学習データ量の差と大きく関連しているはずです。インタリーブされた(interleaved)画像テキストデータを追加することがより説得力を持つでしょう。実際、Qwen2-VLやInternVL-2.5もこのような方式で訓練しており、少なくともこの問題が解決不可能な致命的問題ではないことを示しています。
この実験は私たちのプロジェクトの考え方とも一致しており、データ量が少ない状況で凍結パラメータのファインチューニングを行う、LoRAやP-Tuningのような方法は比較的うまくいきますが、当然ながらSOTA(最先端)には及ばない可能性があります。
CogVLMは、構造的な壊滅的忘却耐性設計を用いています。元のLLMの基礎ブロックの上に、視覚専門のモジュール(b)としてブロックを分岐させ、それをファインチューニングします。

追加のvisionブロック、テキスト処理はしない
これは直接、q, k, vのLinearとFFN、Attentionを追加していますが、実際には元のLLMのブロックを一つコピーして、ここのLinearとFFNの初期化を直接LLMの元の重みで行っています。これは、元のモデルがvision tokenを処理する能力の由来を説明しています。Attentionのcausal maskもvision tokenに適用されます(作者も実験を行い、元のLLMの構造を維持する方が効果が良いことを証明しています)。とは言え、個人的にはMMDITに類似したこの種の構造が好きです...
訓練段階:
- 事前学習: 2つの段階があります。第一段階は1.5Bの画像テキストデータを用いてモデルのcaption能力を訓練し、主にNTP lossを使用します。第二段階は簡単なgroundingデータ(問題+直接の回答座標)を用いて訓練し、これもNTP lossです。事前学習全体は比較的粗く、初期のベースモデルと同様に、画像テキスト検索と簡単なgroundingの能力を得るだけです。
- アライメント(ファインチューニング): CogVLMは2つの独自データで訓練しました。一つはVQAタスク用のCogVLM-Chat、もう一つはgroundingタスク用のCogVLM-Groundingです。CogVLM-ChatはLLaVA-Instructの対話VQAデータの大部分を使用し、中のいくつかの論理的誤りを修正しました。CogVLM-Groundingは4種類のgroundingデータを使用しています:(1) caption内の各名詞に対応するbbox、(2) bbox内の内容に対応するtext内容とbbox、(3) VQA形式のgrounding、(4) いくつかのCoTを含むVQA形式のgrounding。
添付資料で開示された詳細から見ると、pretrainingとfinetuneは基本的に2023年頃の標準的な訓練プロセスに従っており、データが成功の鍵であることがわかります。
GLM-4.1V-Thinking及GLM-4.5V
ようやくまとめが終わりました。当初は最初のバージョンを書き始めたところでInternVL-3.5がリリースされ、GLM-4.5Vのレポートを待っていました。8つの論文を26ページにまとめるのは大変な作業でした。GLM-4.5VがVLM分野でどれほどの人気を博しているのかは疑問です。

GLM-4.1V-ThinkingとGLM-4.5Vの構造
まだそのパラダイムではないが、使いやすく、本当に役に立つ。さらに、vision encoderはQwen2-VLと同様に2D-RoPEを導入し、2D-convを3D-convに置き換えてビデオを処理し、この3D-convによって時間軸(temporal)上で2倍のダウンサンプリングを実現している。単一の画像は2フレームのビデオとしてリピート処理され、まさにQwen2.5-VLのコピー版だ。2D-RoPEの追加に加えて、ViTの事前学習済みである学習可能なabsolute PEも維持しており、トレーニング中にはbicubic interpolationを通じて可変解像度に適応させ、元の位置表現から適応後の位置エンベディングを取得する。そのプロセスは以下の通りである:
これらの正規化された座標は、元の位置エンベディングテーブル
learnable absolute PEによる解像度拡張
これは実際には、座標をパッチの位置を無視できる範囲に正規化し、元のパッチグリッドを解像度の変化に応じてマッピングし、新しいグリッドの座標にマッピングすることで、解像度をスケーリングできるようにするものである。なぜこれを追加するのか? GLMのViTはQwen2-VLと同じだが、Qwen2.5-VLは大規模な再学習を行っている。GLMは事前学習済みの224解像度のViTを基に変更を加えることで、元の構造パラメータを可能な限り維持し、これにより学習の収束が速く、より安定し、智谱(Zhipu)の安定性を求めるスタイルに合致している。
LLM部分もQwenと同様にM-RoPEを使用しているが、GLMでは3D-RoPEと名付け、名前を変えただけだ。
ビデオ入力については、図を見ればわかるが、Seed1.5-VLと同様に、タイムスタンプをインデックスとしてマークする。
次に、学習段階について:
-
Pretraining: このデータパイプラインはCogVLM2と比較して大幅なアップグレードと言える。ここではその内容を簡単にリストアップする。
- 画像-キャプションデータ: 解像度、clip-score、ウォーターマーク除去の分布(metaClipの考え方を参照)、キャプションの書き直しによる情報密度の向上に基づいて選別。
- 画像-テキストインターリーブデータ: ウェブページ、電子書籍から。主に広告を除外し、clip-scoreを用いて無関係な画像とテキストを除外し、情報密度の高い画像・テキスト情報を優先的に保持。
- OCRデータ
- Groundingデータ: CogVLM2の考え方を踏襲しつつ、多くの生成データを追加。
- ビデオデータ: 学術、内部、ウェブから。
-
インストラクション・チューニングデータ: 任意の多層ラベルとして機能させ、そこからサンプリングしたもの。複雑なシーンの合成データ(長文理解・解答など)、データ汚染チェック(多少の汚染はあり、人手+自動化でチェック)。
事前学習は2つの段階に分かれる。第1段階はマルチモーダル事前学習で、ビデオデータを除くすべてをシャッフルし、8kのコンテキストで学習する。第2段階は長文コンテキスト学習で、32kのコンテキストを使用し、その後ビデオ、高解像度画像、長いインターリーブデータを追加してコンテキストを拡大する。ただし、このコンテキスト長は他のメーカーに比べると少し短い。
-
SFT: この段階は非常に重要である。なぜなら、コールドスタートSFTの効果はThinkingモードの効果に大きく影響し、コールドスタートのデータが悪いと、学習がクラッシュしたり、RL(強化学習)が学習を進めるほど悪化したりするからだ。この段階では、まず独自の長いCoT(Chain-of-Thought)コーパスを構築した。これには、検証が必要なタスクや比較的簡単な指示追従タスクが含まれる。主な目的は、モデルが持つ既存の視覚言語理解能力を、効果的な思考モデルと厳格な回答スタイルに整合させ、後のRLのためにより良いベースモデルを提供することである。具体的な回答スタイルは以下の通り:
<think> {think_content} </think> <answer> {answer_content} </answer>
Thinkingモードの回答スタイル
この中で、<think> タグ内には思考内容を、<answer> タグ内には簡潔な回答を記述する。
一度のコールドスタートを経てRL用のベースモデルを提供し、そのRLで学習されたチェックポイント(ckpt)がrejection samplingの素材を提供する。この素材を用いてbest-of-Nのデータスクリーニングを行い、さらに人手でスクリーニングする。こうして得られた高品質なデータは、再びコールドスタートのデータとしてSFTに使用できる。したがって、SFTとRLは一種の反復的な更新戦略である。
GLM-4.1-ThinkingはThinkingモードのみをサポートするが、GLM-4.5Vは両方をサポートする。そのため、SFT(Supervised Fine-Tuning)の際には、CoTデータと非CoTデータの両方を混合して学習させる。非思考モードのデータには<nothink>トークンを一つ追加するだけでよく、モデルの回答のthink部分は空になる。
-
RL: Seed1.5-VLと似たようなプロセスで、いずれもRLVR+RLHFであるが、詳細には大きな違いがある。全体的なRLアルゴリズムはGRPOを使用しているが、具体的な詳細はここでは述べない。データ、reward設計、trainingの観点から、大まかに何を行っているかを以下に記す:
データ: まず、すべてのタスクを検証(verify)可能なサブ問題に分解し、選択問題を穴埋め問題に変更する(自己回帰のロジックにより適合させるため)。オフラインのpass@kと人手によるラベリングを用いて、各問題に1~5段階の難易度を付ける。トレーニング中は、各サブ領域におけるモデルの正答率をリアルタイムで統計し、難易度分布をオンラインの監視指標とする。50ステップごとに「簡単すぎる、適度、難しすぎる」に基づいてサンプリングの重みを再配分し、モデルに常に最も勾配を生み出しやすいサンプルが供給されるようにする。
reward: 2層のverifierを構築する。下層では共有関数を用いてフォーマットチェック、答えの抽出(
<|begin_of_box|>...<|end_of_box|>の間から抽出)、完全一致のマッチングを統一的に行う。もしマッチングしない場合は、上層で領域ごとにカスタムモジュールを挿入する——数学ではSympyの数値許容誤差、物理/化学では単位を再判定、グラフでは数値を優先し次にセマンティクス、OCRでは編集距離、GroundingではIoU、GUIではアクション+IoUのダブル指標を用いる。リワードハッキングを防ぐため、言語の混用、繰り返し、空のbox、または万能な答え(例:「0~10の間の整数を指摘せよ」という問いに「光の速さに近い」と答えるなど)が検出された回答には直接0点を与える。verifyタスクではないのにboxマークが出現した場合もペナルティを与える。Training: GRPOをベースにRLCS(Reinforcement Learning with Curriculum Sampling)を追加。まず4~8倍のoversampleでrolloutを行い、EMAを用いてoversample係数を動的に ≈ 1/(1−無効率) に調整する。無効サンプルとは、バッチ全体が全正解または全不正解の場合を指す。長い思考連鎖が途切れた際には挿入を行い、強制的に答えを出力させることで、ゼロリワードの無駄を避ける。KL正則化とエントロピー正則化を削除し、top-pを1に設定して稀なトークンの学習を減らし、per-token lossの代わりにper-sample lossを採用する。実験によれば、RLCSは3000ステップ以内にマルチモーダル全体のベースラインをさらに2~4ポイント向上させ、領域間の汎化性能も良好であることが示されている。
ps: pass@kとは、トレーニング前にオフラインで完了させるサンプルの難易度評価である。一つのモデルまたは複数のモデルに問題を解かせ、少なくとも一度正解する確率を統計する。つまり、pass@kが0であれば非常に難しく、pass@kが1であれば非常に簡単だということだ。その後、人手で値を調整し、難易度レベルを分けることができる。GLM-4.5Vの各RLの際には、問題の難易度に基づいてデータをスクリーニングし、超簡単または超難解なサンプルを除外することで、このRL段階の学習をより効果的にする。
残りのインフラについては、いつものように省略する。総じて言えば、GLM-4.5VとGLM-4.1-Thinkingは、主にデータ面で大きな改善を行い、クリーニングプロセスを多様化し、RLとコールドスタートを連携させている。これは現在のVLMにおけるRLの一般的なアプローチでもある。RLの詳細設計においては、独自の考え方があり、多くの小さなトリックを加えてRLのトレーニングプロセスを最適化し、トレーニングプロセスを安定させている。
MIMO-VL
- まだ書いてません
ERINE
- まだ書いてません
Skywork-R1V
- まだ書いてません
Keye-VL
- まだ書いてません
MiniCPM-V 4.5
- まだ書いてません

Acrosstudio株式会社は、コンサルティング×生成AIスタートアップです。 コンサルティング事業に加え、自社でのVLM, RAG, AI Agentのプロダクト開発、生成AI/AI Agent業務設計等を推進しています。上場企業元CTOや、GAFA出身の生成AIエンジニアを中心に技術発信も行っていきます。
Discussion