大規模言語モデル(LLM)の進化と主要技術
はじめに
近年、人工知能分野において大規模言語モデル(LLM)は目覚ましい発展を遂げています。その性能は日々向上し、自然言語処理の様々なタスクで人間と同等、あるいはそれ以上の成果を出すようになりました。本記事では、LLMの技術的な発展の軌跡、主要な訓練手法、性能向上を支える基盤技術、そしてマルチモーダルモデルへの広がりについて、ソースに基づき解説します。
1. 大規模言語モデルの発展の歴史
LLMの進化は、Transformerアーキテクチャの登場から本格的に加速しました。
1.1 Transformerの登場とBERTの双方向性
- Transformerは、2017年1月にGoogleが発表したモデルで、LSTMが抱えていた長距離の記憶喪失問題を解決しました。モデル全体がAttentionメカニズムに基づいており、入力された各単語間の関連性(距離に関わらず)を計算し、単語間の依存関係を理解して現在の単語の情報を表現し、全ての単語の情報を総合して出力を予測します。構造的にはエンコーダーとデコーダーの2つの部分から構成されます。
- **BERT (Bidirectional Encoder Representations from Transformers)は、2018年10月にGoogle AI研究院が提案したプレトレーニングモデルです。「プレトレーニング+ファインチューニング(Fine-tuning)」**がモデル訓練の主流方式となるきっかけを作りました。
- RoBERTaは、BERTをプレトレーニングすることで他のプレトレーニングモデルを超える性能を示しました。
- BARTは、新しいマスクプレトレーニング方式を提案し、双方向エンコーダーのテキスト生成能力を向上させました。
1.2 GPTシリーズと生成モデルの台頭
- GPTは、2018年6月にOpenAIが発表し、Generative Pre-Trainingという概念を提唱しました。アノテーション付きデータが少ない状況でも、**「教師なし訓練+ファインチューニング」**が有効な訓練方式であることを証明しました。構造的にはデコーダーのみで構成され、1.17億のパラメータと5GBの訓練データを使用しました。
- GPT-2は、2019年2月に発表され、パラメータ規模の大きなモデルと大量の教師なしデータによる訓練が、高性能な言語モデルを生み出し、多様なタスクをこなせることを証明しました。15億のパラメータと40GBの訓練データを使用しています。
-
GPT-3は、2020年5月に発表され、**「プレトレーニング+プロンプト(Prompting)」が大モデルの主流訓練方式となりました。このモデルは、多くの場合、複数の下流タスクでRLHF(Reinforcement Learning from Human Feedback)訓練が行われるため、「プレトレーニング+プレファインチューニング+プロンプト」**とも呼ばれます。1750億のパラメータと45TBの訓練データを使用しました。
- プロンプトとは、自然言語の指示(プロンプト)を構築することで、下流タスクをプレトレーニング段階の言語モデルタスクに変換する手法です。例えば、「私はこの映画が好きです。」の感情傾向を識別したい場合、その後に「それはとても 」というプロンプトを連結し、モデルが空欄に「素晴らしい」と予測すれば肯定的な感情と判断できます。これにより、プレトレーニングモデル全体をファインチューニングすることなく、モデル内部の知識を活用して「任意の」自然言語処理タスクを完了できる利点があります。
- instructGPTは、2022年3月に発表され、**RLHF(Reinforcement Learning from Human Feedback)**を導入しました。これは、生成モデルの評価が難しいという問題を解決し、RLによって生成モデルの生成戦略を向上させることを可能にしました。
- ChatGPTは、2022年11月にOpenAIによって発表された多言語モデルで、GPT-3.5を基盤としています。
- GPT-4は、2023年3月14日にOpenAIから発表されました。
1.3 その他の主要なモデル
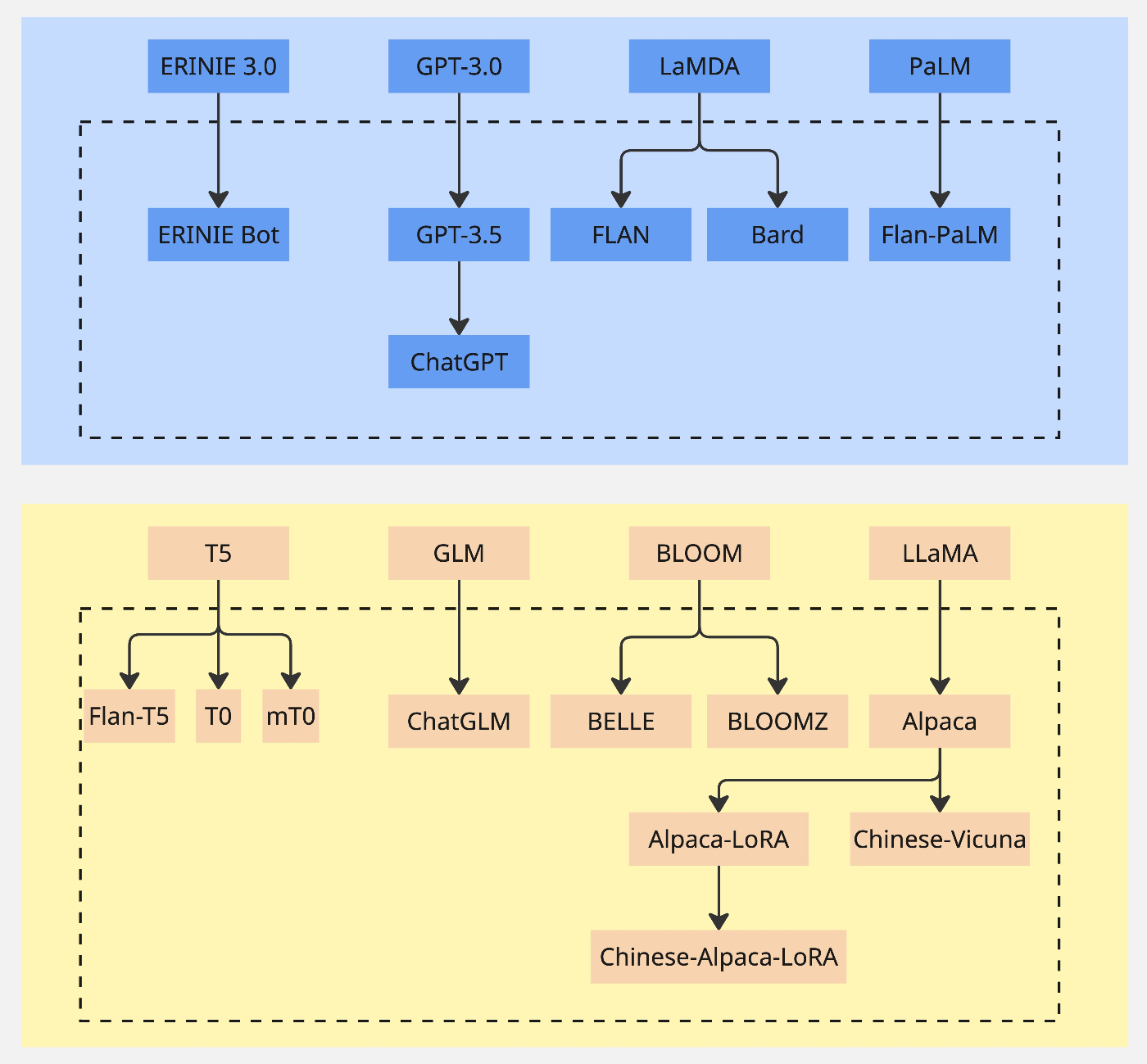
ソースには、他にも多くのLLMが記載されています。以下はその一部です。
- T5 (Google, 2019-10, 13Bパラメータ)
- LaMDA (Google, 2021-05, 137Bパラメータ)
- Jurassic (AI21, 2021-08, 178Bパラメータ)
- MT-NLG (Microsoft, NVIDIA, 2021-10, 530Bパラメータ)
- ERNIE 3.0 Titan (Baidu, 2021-12, 260Bパラメータ, Multi-task)
- Gopher (DeepMind, 2021-12, 280Bパラメータ)
- Chinchilla (DeepMind, 2022-04, 70Bパラメータ)
- PaLM (Google, 2022-04, 540Bパラメータ, 多言語)
- OPT (Meta, 2022-05, 125M-175Bパラメータ, オープンソース)
- BLOOM (BigScience, 2022-07, 176Bパラメータ, 多言語, オープンソース)
- GLM-130B (Tsinghua, 2022-08, 130Bパラメータ, 中国語・英語, オープンソース)
- LLaMA (Meta, 2023-02, 7B-65Bパラメータ, 多言語, オープンソース)
- Claudeは、Anthropicチームが開発したLLMで、Constitutional AI(憲法AI)訓練方法を提案した点が主な革新です。RLHFからRLAIF(Reinforcement Learning from AI Feedback)へと進化し、AIがAIの訓練を監督することで、AI自身が進化し、LLMの有用性を高めるとともに毒性を低下させ、AIが規制に適合するようにします。
2. LLMの訓練と最適化技術
LLMの訓練は、単にモデルを大きくするだけでなく、効率的かつ効果的に性能を引き出すための様々な技術の進歩によって支えられています。
2.1 主流の訓練方式
- プレトレーニング + ファインチューニング:BERTの登場以降、この方式が主流となりました。
- プレトレーニング + プロンプト:GPT-3以降、この方式が大規模モデルの主流となりました。
- プレトレーニング + プレファインチューニング + プロンプト:さらに多くのタスクに対応するため、下流タスクでの継続的なプレトレーニング(プレファインチューニング)が行われ、これが自然言語処理の新しいパラダイムとなりつつあります。
2.2 強化学習と人間のフィードバック (RLHF)
- **RLHF (Reinforcement Learning from Human Feedback)**は、生成モデルの結果評価の難しさを解決するためにinstructGPTで導入されました。このプロセスは、以下のステップで進められます。
- 実演データの収集と教師ありポリシーの訓練: プロンプトをサンプリングし、人間が望ましい出力行動を示して教師ありデータを作成し、GPT-3.5などをファインチューニングします。
- 比較データの収集と報酬モデルの訓練: プロンプトをサンプリングし、モデルから複数の出力を得て、人間がそれらの出力の品質をランク付けし、報酬モデルを訓練するための強化学習データを作成します。
- PPO強化学習アルゴリズムを用いたポリシーの最適化: 訓練済みの報酬モデルを使用して、教師ありファインチューニングされたモデルからの出力に報酬を評価し、そのフィードバックをモデルの訓練に利用します。
- Bloomzは、RLHFに基づいて訓練されたBloomモデルです。
2.3 AIによる強化学習 (RLAIF) と Constitutional AI
- Claudeで提案されたConstitutional AIは、RLHFにおける「人間が与える知識に毒性(有害な情報)が含まれる可能性がある」という問題に対処します。RLAIFでは、無毒なルール制限、いわゆる「憲法」のようなものが導入され、有害な知識を排除することができます。これは、AIが自己改善のために憲法AIのフィードバックを用いることで実現されます。
2.4 パラメーター効率的なファインチューニング (PEFT)
計算資源が限られた状況でも、深層学習モデルのファインチューニングを可能にする技術が**PEFT (Parameter Efficient Fine-tuning)**です。主な方法には以下のものがあります。
-
Prompt Tuning:モデル入力のプロンプトを調整することで、モデルの生成結果を改善するファインチューニング技術です。プロンプトの長さや形式を調整し、指示情報と誘導性情報を設計することで、モデルの生成結果をより良く導くことができます。

-
P-Tuning (Projected Tuning):下流タスクを空欄補充タスクに変換し、自然言語で構成されたテンプレート(プロンプト)を活用して予測を誘導する技術です。これは、少量の注釈データでプレトレーニングモデルに特定の知識を学習させることを目的とし、下流タスクで優れた柔軟性と汎用性を示すことができます。

-
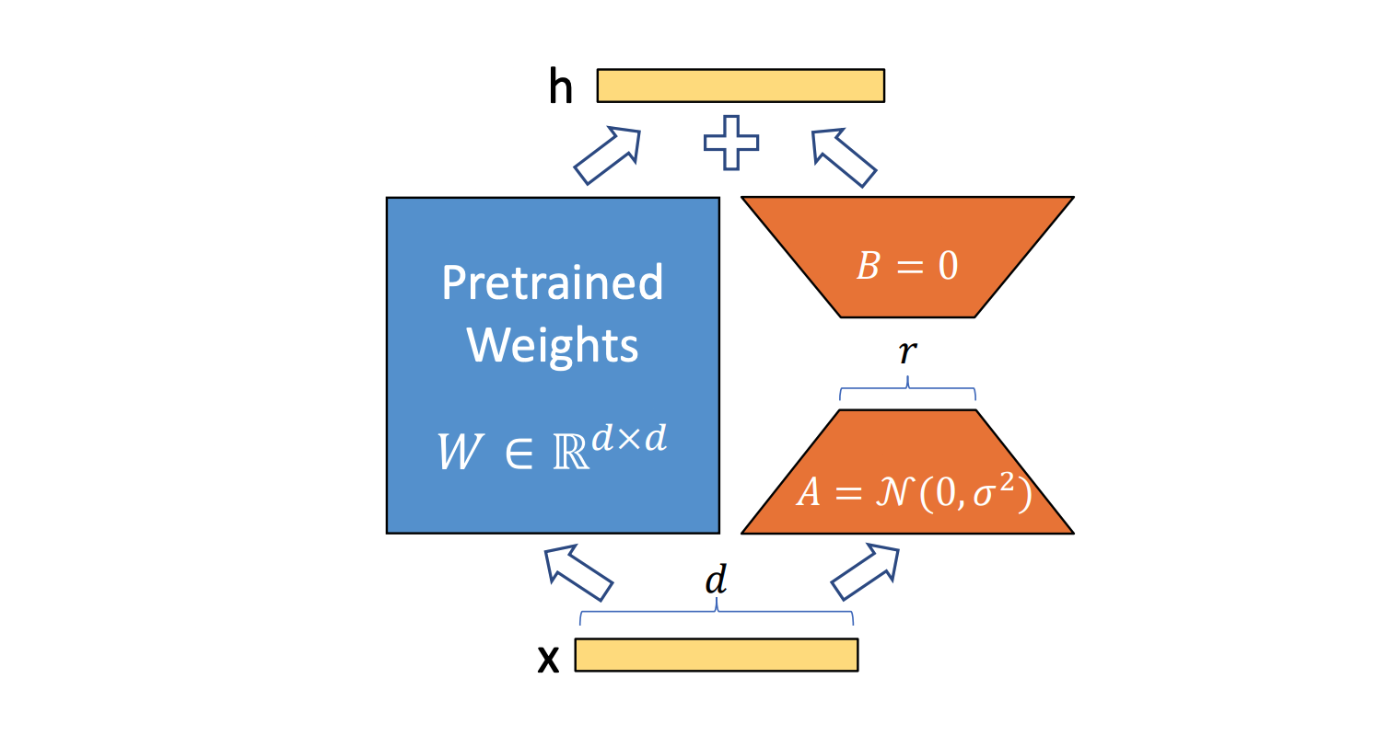
LoRA (Low-Rank Adaptation):モデル全体ではなく、ごく一部のパラメータのみを更新することでモデルのファインチューニングを実現し、新しいドメインでのLLMの性能を向上させます。特に、GPT-3のような巨大モデル(1750億パラメータ)の場合、ファインチューニングによる全パラメータ更新は計算コストが高いですが、LoRAでは更新するパラメータを大幅に削減できます。
2.5 訓練データの品質と多様性
GPT-3.5が他の再現方法よりも強力な理由の一つは、その訓練データの品質にあります。
- 低品質データのフィルタリング
- プレトレーニングデータの冗長性除去:冗長なデータは過学習を引き起こし、性能に影響を与える可能性があります。
- プレトレーニングデータの多様性:ドメイン、形式(テキスト、コード、テーブル)、言語の多様性が重要です。
2.6 訓練フレームワークと最適化戦略
- 訓練フレームワーク: ZeROデータ並列(PyTorch、DeepSpeedに実装)やモデル並列(Megatron-LMに実装、パイプライン並列、テンソル並列、シーケンス並列を含む)などが大モデル訓練を加速します。
- 訓練過程の調整: 訓練途中で最適化戦略を調整したり、fp16やbf16などの半精度浮動小数点数を使用したり、正規化層を調整したり、改良されたAdam最適化器を使用したりします。また、バッチサイズを小さいものから徐々に増大させることも行われます。
3. 大規模モデルの性能向上を支える基盤技術
LLMの能力を最大限に引き出すためには、内部のアーキテクチャや計算効率を向上させる技術が不可欠です。
3.1 位置エンコーディングの進化
-
RoPE (Rotary Position Embedding):相対位置エンコーディングと絶対位置エンコーディングの利点を組み合わせた改良されたエンコーディング方法です。LLMの外挿能力を向上させ、例えば512の入力長で訓練されたモデルが100万の入力長の内容をサポートできるようになります。

-
NTK (Neural Tangent Kernel):Qwen大モデルで使用されている**動的NTK補間法(dynamic NTK scaling)**は、NTK認識型のRoPE拡張により、LLaMAモデルのコンテキストウィンドウを大幅に拡張(8k以上)し、ファインチューニングなしで実現します。
3.2 計算高速化技術
-
Flash Attention:TransformerのAttention計算を加速する技術です。高速キャッシュを利用して不要なI/Oを削減することで、訓練速度を最大7倍向上させます。
- QKV計算を分割することで、softmax計算がHBM(High Bandwidth Memory)の読み書きを多用し、メモリ占有量が多いという問題を回避します。これにより、最終的な計算効率は6倍向上し、メモリ占有量は9倍削減されます。シーケンス長が長いほど、その効果は顕著になります。
- PyTorch 2.0では
torch.nn.functional.scaled_dot_product_attention関数としてFlash Attentionアルゴリズムが実装されており、ChatGLM2のコードでも使用されています。

-
DeepSpeed:PyTorchやTensorFlowなどのフレームワーク上で動作するモデル訓練最適化ツールです。大モデル訓練を加速し、モデル並列化、勾配累積、動的精度スケーリング、混合精度、分散訓練管理、メモリ最適化、通信量節約、モデル圧縮などの機能を提供します。
- ZeRO (Zero Redundancy Optimizer):DeepSpeedの主要な機能の一つで、顕著なメモリ最適化技術により、100Bパラメータモデルの訓練速度を3〜5倍向上させることができます。
-
1ビットAdam:大モデル訓練で最も使用される最適化器であるAdamに対して、通信量を5倍圧縮し、Adamと同様の収束率を達成できる新しいアルゴリズムです。

3.3 量化 (Quantization)
-
量化は、モデルのサイズを削減し、推論の効率を高める技術です。ChatGLMは、fp16(非量化)、int8、int4の量化技術を提供しています。int8はメモリを半分に削減できますが、推論速度は半分になります。ソースによると、量化による推論速度の加速能力は提供されていません。

3.4 Decoder-onlyアーキテクチャの優位性
大規模言語モデルの構造がDecoder-onlyになっているのは、双方向Attentionのエンコーダーの行列が低ランク(秩が低い)であることに起因します。一方で、単方向Attentionのデコーダーは満ランクであり、理論的により強い表現能力を持つためです。
4. マルチモーダルLLMの展望
LLMはテキストだけでなく、画像などの異なるモダリティを理解する方向へと進化しています。
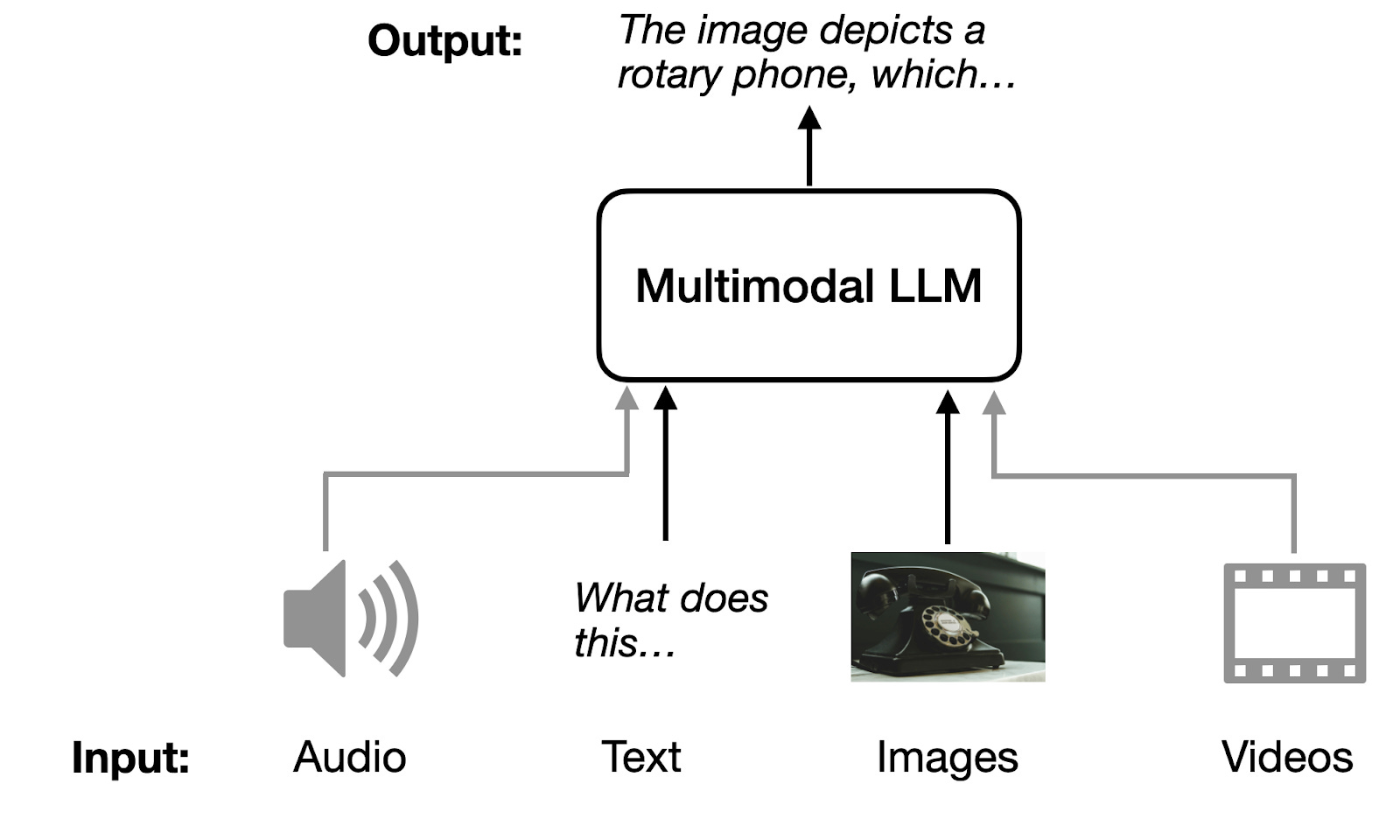
4.1 現状と課題
- 現在のマルチモーダル大モデルは、内容の全体的な理解に焦点を当てており、「画像中の物体の色」のような特定の主体に焦点を当てるAttention能力が不足しており、誤った回答をすることがあります。
- オープンデータにおいて「画像に基づくオープンなテキスト生成タスク」のアノテーションデータが不足していることが明確な課題です。
- 従来のマルチモーダルデータセットで構築されたinstruction dataは、NLP instruction dataと比較して豊富さが劣ります。
4.2 取り組みと応用
- 多くのマルチモーダルタスクは、詳細な画像記述テキスト生成 + 純粋なNLPタスクに変換できる可能性があります。
- オープンソースの取り組みでは、image-text pair、VQAなどの限られたマルチモーダル下流タスクデータセット、純粋なテキストのinstruction data(shareGPT/蒸留ChatGPTデータ)を利用してinstruction dataを構築しています。
- LLaVAは、Vision EncoderとProjection層を介して画像情報を言語モデルに統合するマルチモーダルモデルの一例です。ViTとBaichuan2を組み合わせたLLaVA訓練モデルは、合計7.65Bのパラメータを持ちます。
-
応用範囲は、図文検索、画像に基づく質問応答(例:教育問題)、画像に基づく文書分類(例:EC商品、ビデオコンテンツ審査分類)、画像記述生成など多岐にわたります。従来のモデルは記述の精度が高いものの、短い記述しか生成できず、「画像に基づくオープンなテキスト生成タスク」は基本的には完了できませんでした。
4.3 幻覚 (Hallucination) への対策
LLMが事実と異なる情報を生成する「幻覚」の問題に対して、以下の3つの方法でモデル能力を向上させることができます。
- 多様で高品質な訓練データの提供
- **RLHF (Reinforcement Learning from Human Feedback)**の活用
- 人工的な訂正フィードバックをモデルに与える
5. その他の重要な概念とツール
LLMの利用や開発を促進するためのエコシステムも拡大しています。
- RAG (Retrieval Augmented Generation):言語モデルを他のデータソースに接続することで、データ認識能力を高める技術です。
- Agent:言語モデルがその環境と対話できるようにする代理的性質を持つ技術です。
- LangChain:LLMアプリケーションの開発を支援するフレームワークです。
- vLLMによるRolling batch:LLMの推論性能を加速する技術です。
5.1 オープンソースプロジェクト
LLMの開発と利用を加速するために、多くのオープンソースプロジェクトが公開されています。
- LLaMAFactory:LLM向けのツール。
- swift:MLLM(Multi-modal Large Language Models)とLLMの両方に対応。
- Chinese-LLaMA-Alpaca
- THUDM/GLM

Acrosstudio株式会社は、コンサルティング×生成AIスタートアップです。 コンサルティング事業に加え、自社でのVLM, RAG, AI Agentのプロダクト開発、生成AI/AI Agent業務設計等を推進しています。上場企業元CTOや、GAFA出身の生成AIエンジニアを中心に技術発信も行っていきます。
Discussion