99%のAIエージェント開発企業は、完全に道を間違えかも知らない。
では、エージェントはどのようにして成功できるのか?
ある海外の自動車運転免許管理局(DMV)が、最新のAIアシスタントを導入し、運転免許証の更新といった新しいタスクを処理できると約束したとします。
しかし、あるユーザーが「運転免許証を更新したい」と尋ねたところ、システムは無限ループに陥り、同じ質問を繰り返し、最終的にはメモリが溢れてクラッシュしてしまいました。
なぜこのAI Agentプロジェクトは失敗したのか?
原因:
- トークン予算: 500に制限されており、複数回の対話を完了できない。
- 記憶の設計: 会話の状態管理がない。
- 評価の欠如: 本番環境でのパフォーマンスを知るすべがない。
- アーキテクチャの選択: チャットボットのアーキテクチャでエージェントのタスクを処理しようとしている。
これらはすべて、避けることのできる間違いです。
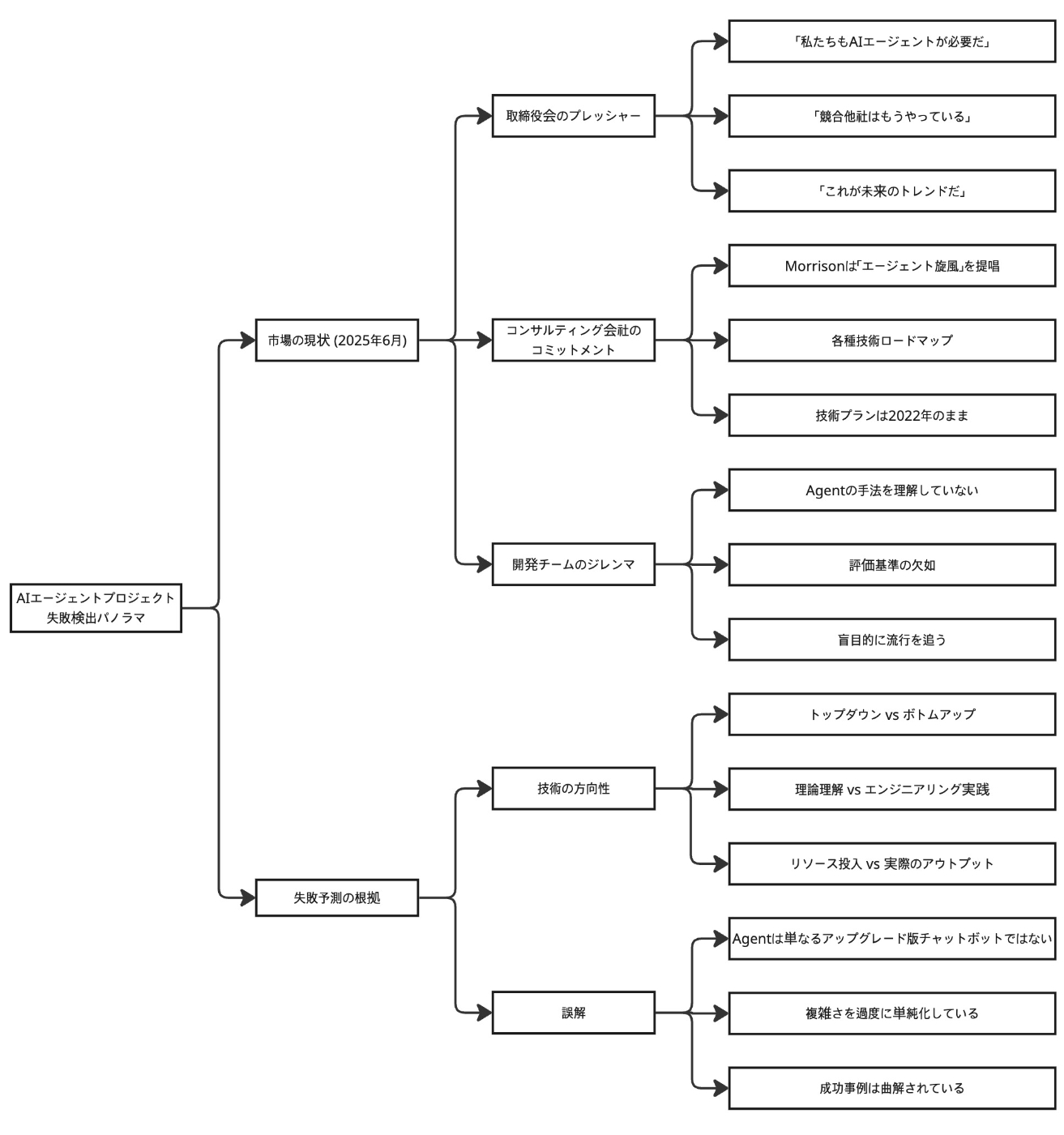
2025年初頭、Anthropic社とCognition社(Devinの開発元)の間で、AIエージェントのアーキテクチャに関する大きな論争が巻き起こりました。
この論争は、残酷な事実を明らかにしました。トップレベルのチームがまだ基盤となるアーキテクチャについて議論を戦わせている一方で、99%の企業は自分たちが全く理解していないシステムを盲目的に導入し、追随しているのです。
AI Agentの本質を理解する
以下の等式を真に理解すれば、あなたはすでに80%の人々を超えています。
AI Agent = LLM(大脳)+ Tools(両手)+ Policy/Memory*(神経系)**
AnthropicのDeep Researchシステム + マルチエージェントアーキテクチャは、数時間に及ぶ長期的な詳細研究を可能にします。一方、Cognitionは自社のAgentソリューションにおいて、システムのシンプルさがより重要であると主張しています。これは単なる技術的な路線の違いだけでなく、AI Agentの本質に対する根本的な理解の違いを反映しています。
- マルチエージェント派: より多くの計算リソースと協調作業を通じて、さらに強力な推論能力を実現できると考える。
- シングルエージェント派: 現段階では、エンジニアリングの安定性とデプロイ効率を優先すべきだと考える。
この論争を理解することは、AI Agentの技術的な上限(天井)がどこにあるのかを理解することに繋がります。
# 最小実行可能AI Agentの例
class MinimalAgent:
def __init__(self):
self.llm = LLM(model="gpt-4") # 脳
self.tools = { # 両手
"search": web_search,
"calculate": calculator,
"remember": vector_store
}
self.memory = ShortTermMemory() # 神経系
def think_and_act(self, user_query):
# 1. 意図を理解する
context = self.memory.get_recent_context()
intent = self.llm.analyze(user_query, context)
# 2. 計画を立てる
plan = self.llm.create_plan(intent)
# 3. アクションを実行する
results = []
for step in plan:
if step.requires_tool:
result = self.tools[step.tool_name](step.params)
else:
result = self.llm.generate(step.prompt)
results.append(result)
self.memory.add(result) # キー:記憶の連続性を保つ
# 4. 結果を統合する
return self.llm.synthesize(results)
トークンから記憶へのシステマティックな失敗
2025年初頭、AI(Claude Opus*)が執筆に関与したある論文が業界に衝撃を与えました。
Apple社がLLMの推論能力は低下していると主張したのに対し、Claude Opusは実際のデータを用いて、問題はモデルにあるのではなく、トークンの割り当てが不十分であることにあると証明しました。

各落とし穴の背後にある技術的な真相
落とし穴1:Token予算の数学的ジレンマ
Multi-Agent(マルチエージェント)システムが存在する核心的な理由:より多くのToken = より優れた推論。これは無駄遣いではなく、必要不可欠なものです。出力Tokenを1000に制限するのは、まるで数学者に3文でフェルマーの最終定理を証明するように要求するようなものです。
落とし穴2:記憶アーキテクチャのエンジニアリング的挑戦
# 間違った記憶設計
class BadMemory:
def __init__(self):
self.buffer = [] # 単純なリスト
def add(self, item):
self.buffer.append(item)
if len(self.buffer) > 10: # 任意の制限
self.buffer.pop(0)
# 正しい記憶設計
class GoodMemory:
def __init__(self):
self.short_term = deque(maxlen=100)
self.long_term = VectorStore()
self.working_memory = {}
def add(self, item, importance_score):
self.short_term.append(item)
if importance_score > 0.7:
self.long_term.add(item)
self.update_working_memory(item)
落とし穴3:時代遅れのソリューションがもたらす隠れたコスト
McKinseyは2025年になっても、技術的な意味合いが皆無な「Agentic Mesh」のような概念を推奨しています。これは、もはや使われなくなったClaude HaikuやGPT-2時代のLLaMA 3 8Bのようなものです。まるで1990年代の地図を使って2025年の都市をナビゲートするようなものでしょう。
落とし穴4:評価の死角がもたらす複合的影響
評価をしないのは、目を閉じて運転するようなものです。あなたは以下を監視する必要があります:
- モデルドリフト (Model Drift)
- 指示遵守度 (Instruction Adherence)
- 記憶の正確性 (Memory Retention)
- タスク完了率 (Task Success Rate)
Agentは自社開発か、それとも購入か?
ある金融テクノロジー企業が、6ヶ月と200万ドルを費やして自社のAI Agentシステムを構築しましたが、最終的にLindy.aiの既存ソリューションが、コストをわずか20分の1に抑えながら要求の90%を満たせることが判明しました。
| 比較項目 | 既存ソリューションの購入 | 自社開発システム | 意思決定における比重 |
|---|---|---|---|
| ビジネスの独自性 | 標準化されたプロセス | 独自のプロセス | 40% |
| コストの考慮 | 月額$1,000〜$10,000 | 立ち上げに$100,000〜$1,000,000 | 25% |
| サービス開始までの時間 | 1〜2週間 | 3〜6ヶ月 | 20% |
| 技術チーム | 1〜2人の運用担当者 | 5〜10人の開発者 | 15% |
| 成功事例 | Lindy.aiによるカスタマーサービス処理 / Zapier AIの自動化フロー | Anthropic Deep Research / Cognition Devin | - |
以下のすべての条件を満たす場合にのみ、自社開発を検討すべきです:
- あなたのビジネスプロセスが、真に独特で複雑である。
- 既存のソリューションでは、中核的なニーズを満たすことができない。
- あなたには、専門のAIエンジニアリングチームがある。
- あなたは、長期的な投資を行う準備ができている。

アーキテクチャ選択の知恵:シングルエージェント vs マルチエージェント
あなたがレストランを経営していると想像してみてください。シングルエージェントは一人の万能なウェイターのようなもので、マルチエージェントは完全なチーム(シェフ、ウェイター、レジ係)のようなものです。どちらが良いか?それは、あなたがファストフード店を開くのか、それともミシュランレストランを開くのかによって決まります。
マルチエージェントシステムの核心的な価値は、「より多くの計算資源を燃やす」ことにあります。これは無駄に聞こえるかもしれませんが、以下の比較を考えてみてください。
- シングルエージェントが複雑な研究タスクを処理:成功率30%、平均Token消費量10K
- マルチエージェントが同じタスクを処理:成功率85%、平均Token消費量100K
タスクの価値が十分に高い場合、10倍の計算コストをかけて約3倍の成功率を得ることは価値があります。
# シングルエージェントの実装:シンプルだが能力に限界がある
class SimpleResearchAgent:
def research(self, topic):
# 直線的な処理フロー
search_results = self.search(topic)
analysis = self.analyze(search_results)
report = self.generate_report(analysis)
return report
# マルチエージェントの実装:複雑だが機能は強力
class AdvancedResearchSystem:
def __init__(self):
self.coordinator = CoordinatorAgent()
self.researchers = [WebResearcher(), AcademicResearcher()]
self.analysts = [DataAnalyst(), TrendAnalyst()]
self.writer = ReportWriter()
def research(self, topic):
# 並列での研究フェーズ
research_tasks = self.coordinator.plan_research(topic)
research_results = parallel_execute(
self.researchers, research_tasks
)
# 詳細な分析フェーズ
analysis_tasks = self.coordinator.plan_analysis(research_results)
analysis_results = parallel_execute(
self.analysts, analysis_tasks
)
# レポート生成フェーズ
final_report = self.writer.create_report(
research_results, analysis_results
)
return self.coordinator.quality_check(final_report)
あるAIエージェントが、テスト環境では完璧に動作したものの、本番環境にデプロイされるとエラーが頻発しました。調査の結果、本番環境の入力長がテスト環境の3倍であったのに対し、システムはTokenの使用状況を一度も監視していなかったことが判明しました。
優れた設計とは、事後対応的な修正ではなく、システム設計の一部であるべきです。以下が重要な原則です。
- 設計段階で可観測性を考慮する: すべての意思決定のポイントを記録すべきです。
- ベースラインを確立する: 「正常」がどのような状態かを知ること。
- アラートを自動化する: ユーザーからの苦情を待ってから問題を発見するのではなく。
-
継続的な最適化サイクル:
評価 → 洞察 → 改善 → 再評価
class AgentEvaluationSystem:
def __init__(self):
self.metrics = {
'task_success_rate': RollingAverage(window=1000),
'avg_token_usage': RollingAverage(window=1000),
'error_rate': RollingAverage(window=1000),
'user_satisfaction': RollingAverage(window=100)
}
self.alerts = AlertSystem()
def evaluate_response(self, request, response, ground_truth=None):
# 基本指標を記録
self.metrics['avg_token_usage'].add(response.token_count)
# 品質を評価
if ground_truth:
accuracy = self.calculate_accuracy(response, ground_truth)
self.metrics['task_success_rate'].add(accuracy)
# 異常をチェック
if response.error:
self.metrics['error_rate'].add(1)
self.alerts.check_threshold('error_rate',
self.metrics['error_rate'].average)
# 評価レポートを返す
return EvaluationReport(
success=response.success,
quality_score=self.calculate_quality_score(response),
recommendations=self.generate_recommendations()
)
結論
成功の鍵は、AnthropicやCognitionになることではなく、以下の点にあります。
- AIエージェントの本質を理解すること(LLM + Tools + Memory)
- 計算リソースの必要性を認識すること(Tokenは高価だが不可欠)
- 適切なアーキテクチャを選択すること(すべてのタスクにマルチエージェントが必要なわけではない)
- 完全な評価体系を確立すること(見えないものは改善できない)
- 技術的に冷静であること(「Agentic Mesh」のような空虚な言葉に惑わされないこと)

Acrosstudio株式会社は、コンサルティング×生成AIスタートアップです。 コンサルティング事業に加え、自社でのVLM, RAG, AI Agentのプロダクト開発、生成AI/AI Agent業務設計等を推進しています。上場企業元CTOや、GAFA出身の生成AIエンジニアを中心に技術発信も行っていきます。
Discussion