
2025年、AI技術の中間レビュー:RAGとAgentの進化の行方
前回の年末総括から半年が経過し、年初に起きた大きな技術革新の波が次第に落ち着くにつれて、AIは再び発展の踊り場に入ったように見えます。これは**RAG(Retrieval-Augmented Generation)**にとっても同様で、学術界では依然として人気のトピックでありながら、ここ半年の研究では目を見張るような斬新なものは少なくなっています。これは、次なる大きな飛躍への準備期間なのでしょうか、それとも安定成長期への移行なのでしょうか。今、一度立ち止まり、中間レビューを行う意義は大きいでしょう。
RAGは、その誕生以来、常に様々な技術的論争の中にありました。2023年のファインチューニング論争、2024年のロングコンテキスト論争などがその例です。2025年に入ると、RAGそのものよりもAgentが技術的な主役となり、それに伴い「AgentにRAGは不要」という意見も散見されるようになりました。こうした言説は市場の注目を集めるための戦略的側面が強いものの、ユーザーや非専門家にとっては混乱を招きかねません。例えば、RAGに「Agentic」という衣を着せてAgentic RAGという新たな概念が生まれ、一部の市場調査機関【参考1】は、その市場規模が従来のRAGを大きく上回ると予測しています。
本稿では、このRAGとAgentの関係性から、現在の技術動向を紐解いていきます。ここで言うAgentとは、予め定義されたWorkflow(ワークフロー)と、自律的に判断・行動する知的エージェントの両方を含む概念とします。現在の多くのRAGシステムでは、Agent機能はまだWorkflowのレベルに留まっていますが、将来的には両者が分かちがたく統合される設計が主流になると考えられます。
「反省」が鍵を握る:AgentによるRAG推論能力の拡張
——Agentは、人間またはモデルが主導する「反省」のループを通じてRAGの推論における難題を解決し、知能の飛躍を促す。両者は密接不可分である。
2025年のRAGにおける重要なキーワードは、「推論」「記憶」「マルチモーダル」です。特に最初の2つはAgentと深く関わっています。近年のサーベイ論文【参考3】では、RAGにおける「推論」が包括的に整理されています。

これによると、昨今のRAG関連技術は、より高度な推論フレームワークの一部として位置づけられます。Self-RAG、RAPTOR、Adaptive-RAGといった手法は、ループやルーティングといった決定論的な処理(Workflow Based)を組み込み、人間が事前に定義した方法でRAGとAgentが連携します。これにより、対話の意図が不明確な場合や、長い文脈を扱う必要がある場合に、一種の「反省(Reflection)」プロセスを通じて、より精度の高い回答を導き出します。
一方、Agentic Basedのアプローチでは、モデル自身がどのように反省するかを決定します。これには、プロンプトによってLLM自身の能力を引き出して思考を巡らせるタイプと、強化学習などを用いて特定のタスクに特化した思考プロセス(Chain-of-Thought)を生成するタイプがあります。後者は、汎用LLMが特定のデータセットに対して、より最適化された推論を行えるようにするアプローチですが、その基盤には依然としてプロンプトベースのAgentフレームワークが存在します。
「記憶」の基盤を築く:Agentの記憶システムを支えるRAG
——RAGはAgentの長期記憶庫を構築し、インデックス作成・忘却・統合を通じてタスク状態の追跡とコンテキストの高速化を実現する。短期記憶と協調し、完全なアーキテクチャを形成する。
どのような推論アプローチを取るにせよ、Agentが真に知的であるためには、LLMを単発で利用するのではなく、観察と経験を通じて繰り返し思考する仕組みが必要です。この観点から、RAGとAgentの関係は非常に密接であり、RAGフレームワークにAgent機能が統合されるのは自然な流れと言えます。
2025年はAgent元年とも呼ばれますが、その核心技術はLLMの文脈内学習(In-Context Learning)能力の向上や、外部ツール連携(Tools)エコシステムの充実に支えられています。その中で、Agent技術の数少ない独自要素の一つが「記憶(Memory)」です。

では、AgentのMemoryとRAGの違いは何でしょうか。ある研究【参考4】によれば、Agentの記憶は主に、対話の文脈情報を扱うContextual Memoryと、モデルのパラメータ内に情報を保持するParametric Memoryに大別されます。一般にAgent Memoryと言われるのは前者であり、以下の価値をもたらします。
- タスク管理メタデータの保存:人間のフィードバックを反映したプランニング情報や、タスクの進捗状況などを保存し、Agentをステートフルなアプリケーションに変えます。
- コンテキスト管理:過去の対話履歴を保持するだけでなく、LLMの応答をキャッシュして高速化したり、ユーザーに合わせたパーソナライズデータを提供したりします。

このMemoryは、Indexing(検索可能な索引付け)、Forgetting(不要な情報の忘却)、Consolidation(情報の要約・統合) といったインターフェースを必要とします。そして、この記憶システムのアーキテクチャを見ると、RAGはMemoryの長期記憶を担う中核部分であることがわかります。短期記憶(セッションデータなど)に保存された情報のうち、価値の高いものがConsolidationプロセスを経て、RAGが管理する長期記憶へと格納されるのです。

したがって、優れたRAGシステムなくして、高機能なMemoryは実現できません。RAGは、Agentが利用する数あるツールの一つというだけでなく、その記憶システムの根幹を成す、最も重要な基盤の一つなのです。
技術的踊り場におけるRAGの挑戦と突破口
——長文テキストの推論は階層的インデックスに依存し、マルチモーダルデータはストレージ膨張のボトルネックに直面し、インフラの遅れがイノベーションの実現を制約している。
RAG技術自体は、現在どのような課題に直面しているのでしょうか。核心である情報検索技術は成熟していますが、質問の多様化とマルチモーダルデータという新たな要求が、技術的な挑戦を生んでいます。
1. 長文テキストの推論
複雑な質問に答えるためには、複数の文書や長い文脈の中から関連情報を見つけ出す高度な能力が求められます。GraphRAGやRAPTORのような手法は、情報の関連性を捉えるためのアプローチですが、まだ決定的な解決策には至っていません。
この課題に対し、検索と推論を一体化させた「Attention Engine」と呼ばれる新しいアプローチ【参考5, 6, 7, 8】が登場しています。これは、文書情報をLLMの推論プロセス(KV Cache)に直接組み込むことで、より高速で効率的な推論を目指すものです。LLMの推論エンジンとの強い結合が必要となるため、オープンソースモデルのカスタマイズやプライベート環境での利用が前提となり、導入のハードルは高いですが、今後の動向が注目されます。
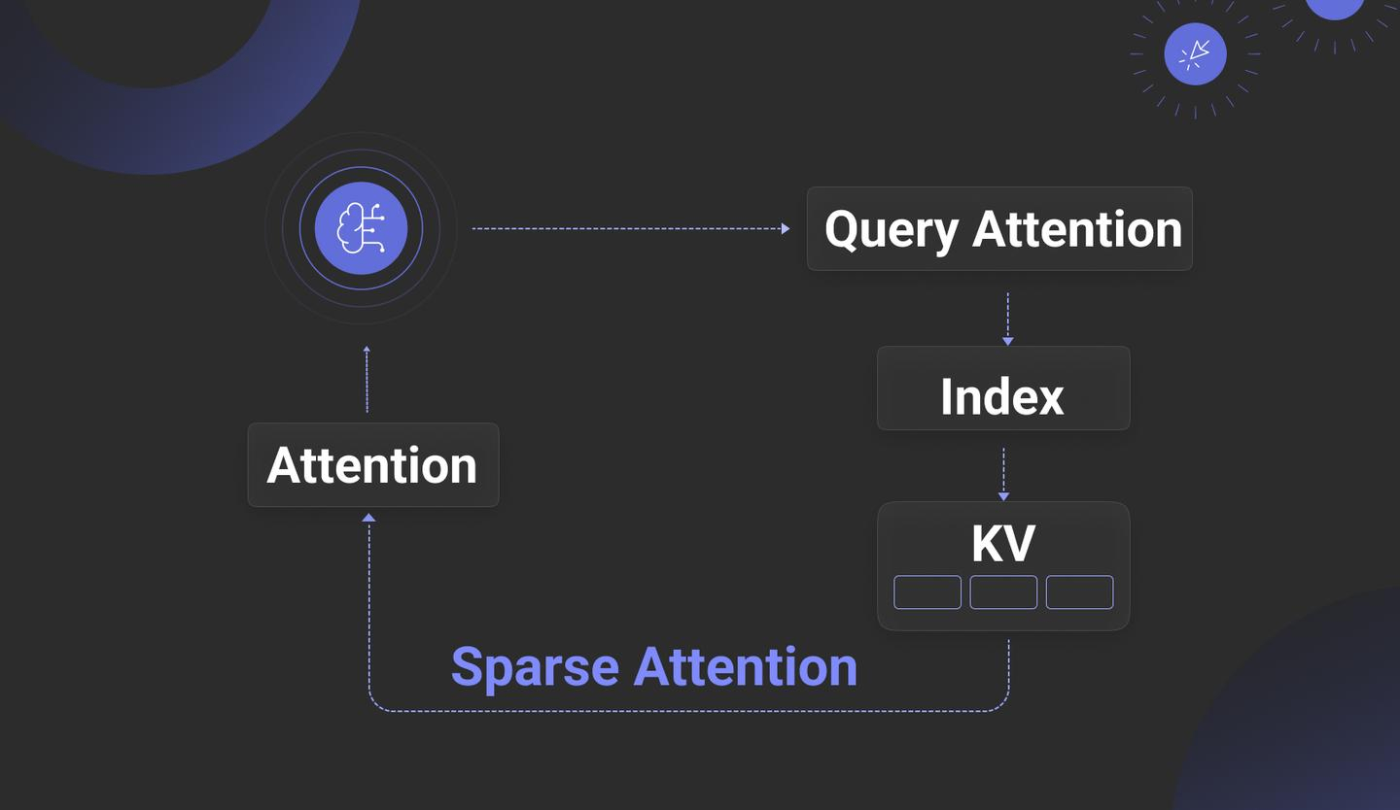
一方で、既存のRAGアーキテクチャの枠組みの中でも、以下のような戦略が模索されています。
- ドキュメントレベルでのリコール:チャンキングせず、まず関連文書を特定し、全文をコンテキストとしてLLMに渡す。
- 階層的インデックス:文書の目次構造などを利用してインデックスをツリー化し、文書全体と内部の詳細な部分を効率的に探索する。
- 粗粒度・細粒度の組み合わせ:文書全体を対象とするリコールと、詳細なチャンクを対象とするリコールを組み合わせる。
これらのアプローチは一長一短あり、最適な解決策はまだ確立されていません。
2. マルチモーダルデータ(MM-RAG)
2025年にはMM-RAG(マルチモーダルRAG)が主流になると予測されていましたが、その普及は遅れています。主な原因は、関連するインフラが未成熟であることです。

画像などのマルチモーダルデータをベクトル化すると、データ量がテキストの数百倍にも膨れ上がる「データ膨張」が深刻な問題となります。この問題を解決するには、データベース層でのバイナリ量子化(ベクトルを1ビットで表現しストレージを大幅に削減する技術)や、モデル層でのベクトル次元削減(MRLなど)、パッチ数の削減といった、ストレージと計算コストを総合的に削減するソリューションが必要です。これらの基盤技術が成熟するまで、MM-RAGが本格的に普及するにはまだ時間がかかると考えられます。
結論
2025年、RAG単体での技術的進歩は緩やかになったように見えますが、その一方で、Agentとの関係はますます深まっています。RAGは、Agentの「記憶」を司る基盤として、また高度なリサーチ能力を提供するツールとして、これまで以上に重要な役割を担うようになりました。もはや**「RAGなくして、企業におけるAgentの本格的な応用はない」**と言っても過言ではないでしょう。
RAGは単なるアーキテクチャの名称ではなく、その内実(=できること)は、LLM、データベース、そして周辺インフラ全体の進化とともに、これからも絶えず変化し、拡大していく技術領域なのです。
参考文献
- https://market.us/report/agentic-retrieval-augmented-generation-market/
- https://www.anthropic.com/engineering/building-effective-agents
- Reasoning RAG via System 1 or System 2: A Survey on Reasoning Agentic Retrieval-Augmented Generation for Industry Challenges
- Rethinking Memory in AI: Taxonomy, Operations, Topics and Future Directions
- Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
- RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
- RetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
- AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference

Acrosstudio株式会社は、コンサルティング×生成AIスタートアップです。 コンサルティング事業に加え、自社でのVLM, RAG, AI Agentのプロダクト開発、生成AI/AI Agent業務設計等を推進しています。上場企業元CTOや、GAFA出身の生成AIエンジニアを中心に技術発信も行っていきます。
Discussion