Jetson NanoでK3sクラスター(構築編)
K3sは軽量なコンテナオーケストレーションツールでJetsonやRaspberry Piなどのエッジコンピューティングデバイスとも相性の良いツールです。シンプル故に導入も簡単で、Kubernetesの学習用にも向いています。
この記事ではK3sとJetson Nanoモジュールを搭載したSeeed製 reComputer J1020を使用してK3sクラスターを構築してみます。
構成
今回はreComputer J1020を3台使用して1台をマスターノード、残り2台をエージェント[1]として構成します。
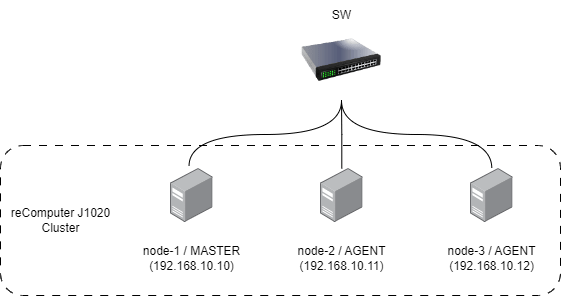
クラスターの構築
Jetsonの初期設定
まずはどのノードにも共通した設定としてJetsonの初期設定を行います。
JetPackのバージョンとしては4.6.4 (r32.7.4)がインストールされているデバイスを使用しました。
- 起動後、ライセンス設定やキーボードなどの設定を行います。
- 固定IPを設定します。
- GUIは使用しないので無効化しておきます。
sudo systemctl set-default multi-user.target - (reComputer J1020は記憶領域であるeMMCの容量が少ないためSSDをルートファイルシステムとして使用するための設定を行いました。開発者キット等を使用していて十分な領域が確保できる場合は必須の作業ではありません。K3sをインストールするだけであれば32GB程度あれば申し分ありません。)
- リソース使用状況の可視化ツールとして
jtopをインストールしておきます。sudo apt update -y && sudo apt install python3-pip -y sudo -H pip3 install --no-cache-dir --upgrade jetson-stats sudo rebootjtopが使用できるか確認しておきましょう。jtop - 以下のパッケージをインストールしてDockerコンテナからGPUデバイスを認識できることを確認します。
sudo apt install libnvidia-container-tools libnvidia-container0:arm64 nvidia-container-csv-cuda nvidia-container-csv-tensorrt nvidia-container-runtime nvidia-container-toolkit nvidia-docker2 sudo reboot docker run -it --rm --runtime nvidia jitteam/devicequery - デフォルトランタイムを変更します。
/etc/docker/daemon.jsonを以下のように変更します。"default-runtime": "nvidia"の一行を追加しましょう。変更後にDockerを再起動し、デフォルトランタイムが変更されていることを確認します。/etc/docker/daemon.json{ "default-runtime": "nvidia", "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } }sudo systemctl restart docker docker info | grep Runtime > Runtimes: runc io.containerd.runc.v2 io.containerd.runtime.v1.linux nvidia > Default Runtime: nvidia # この行が表示されていればOK
以上でJetsonの初期設定は完了です。次はいよいよK3sのインストールに進みます。
K3sのインストール
マスターノードとエージェントノードでインストール手順が異なります。また、今回導入したK3sのバージョンは以下の通りです。
Client Version: v1.28.7+k3s1
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.28.7+k3s1
マスターノードの設定
- 以下のコマンドでK3sをインストールします。Containerdではなく先ほど設定したDockerをコンテナランタイムとして使用します。
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="--docker" sh -s - - ノードの状態を確認してみましょう。たった今セットアップしたマスターノードが表示されるはずです。
sudo k3s kubectl get no - マスターノードにてエージェントの追加に使用するトークンを取得します。
sudo cat /var/lib/rancher/k3s/server/node-token
エージェントノードの設定
- 2台のワーカーノードにて以下のコマンドを実行してk3sをインストールします。
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="--docker" K3S_URL={マスターノードのIPアドレス}:6443 K3S_TOKEN={先ほど取得したトークン} sh - - 再度ノードの状態を確認してみましょう。マスターノードにて以下のコマンドを発行すると、マスターノードとワーカーノード2台、計3ノード分の情報が表示されるはずです。
sudo k3s kubectl get no
K3sクラスターの構築としては以上です。最後にGPUデバイスを利用するPodをデプロイしてみましょう。
GPUデバイスを利用するPodのデプロイ
KubernetesにおいてPodとは1つ以上のコンテナをグループ化する最小の配置単位のことでクラスター内に配置されるアプリケーションの基本的な構成要素です。
Podの概念的な詳細はここでは割愛しますが、主な特徴を私なりに整理してみました。
- 共有リソース: Pod内のコンテナは同じネットワーク名前空間、IPアドレス、ポート空間を共有します
- スケジューリング: PodはK3sクラスターのどれか1つのノードにバインドされ、また、スケジュールされます
- より高レベルのKubernetesオブジェクトによる管理: PodはDeploymentやStatefulSetなどのよりKubernetesオブジェクトにより管理されます。機会があれば別途記事にて扱いたいと思います
kube runによるPodのデプロイ
まずはGPUデバイスを利用するPodをデプロイしてみましょう。deviceQueryを実行するPodをデプロイします。
sudo k3s run -i -t nvidia --image=jitteam/devicequery --restart=Never
正常にデプロイできれば以下のようにGPUの情報が表示されるはずです。
> ./deviceQuery Starting...
>
> CUDA Device Query (Runtime API) version (CUDART static linking)
>
> Detected 1 CUDA Capable device(s)
>
> Device 0: "NVIDIA Tegra X1"
> CUDA Driver Version / Runtime Version 10.2 / 10.0
> CUDA Capability Major/Minor version number: 5.3
> Total amount of global memory: 3956 MBytes (4148047872 bytes)
> ( 1) Multiprocessors, (128) CUDA Cores/MP: 128 CUDA Cores
> GPU Max Clock rate: 922 MHz (0.92 GHz)
> Memory Clock rate: 13 Mhz
> Memory Bus Width: 64-bit
> L2 Cache Size: 262144 bytes
> Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
> Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
> Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
> Total amount of constant memory: 65536 bytes
> Total amount of shared memory per block: 49152 bytes
> Total number of registers available per block: 32768
> Warp size: 32
> Maximum number of threads per multiprocessor: 2048
> Maximum number of threads per block: 1024
> Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
> Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
> Maximum memory pitch: 2147483647 bytes
> Texture alignment: 512 bytes
> Concurrent copy and kernel execution: Yes with 1 copy engine(s)
> Run time limit on kernels: Yes
> Integrated GPU sharing Host Memory: Yes
> Support host page-locked memory mapping: Yes
> Alignment requirement for Surfaces: Yes
> Device has ECC support: Disabled
> Device supports Unified Addressing (UVA): Yes
> Device supports Compute Preemption: No
> Supports Cooperative Kernel Launch: No
> Supports MultiDevice Co-op Kernel Launch: No
> Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 0
> Compute Mode:
> < Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
>
> deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.0, NumDevs = 1
> Result = PASS
Podの一覧と詳細情報の表示、削除はそれぞれ以下のコマンドです。
sudo k3s kubectl get pod
sudo k3s kubectl describe pod {Pod名}
sudo k3s kubectl delete pod {Pod名}
マニフェストファイルによるPodのデプロイ
kube runコマンドを使用するとPodのデプロイが簡単に行えますが、より複雑な設定を行う場合はマニフェストファイルを使用することが一般的です。マニフェストファイルはYAML形式で記述され、Podの設定やリソースの割当てなどを宣言的に記述できます。
以下はdeviceQueryを実行するPodをデプロイするマニフェストファイルの例です。
apiVersion: v1
kind: Pod
metadata:
name: nvidia
spec:
restartPolicy: Never
containers:
- name: devicequery
image: jitteam/devicequery
imagePullPolicy: Always
さて、このマニフェストファイルを使用してPodをデプロイしてみましょう。
sudo k3s kubectl apply -f devicequery.yaml
ログを確認してdeviceQueryが正常に実行されているかを確認するには以下のコマンドを実行します。
sudo k3s kubectl logs {Pod名}
まとめ
今回はJetson Nanoモジュールを搭載したデバイスでK3sクラスタの構築を行い、Podのデプロイを通してGPUデバイスが利用可能であることを確認しました。導入からクラスター構築までのコストが低いのはK3sのシンプルな操作性ゆえの魅力です[2]。次回はより複雑な設定を行うためにDeploymentなどのKubernetesオブジェクトについて取扱いたいと思います。
Discussion