こんにちは!Acompanyのマッケイです!
今回は、2023年8月にプレビュー版リリースされたBigQueryのデータクリーンルームについて、その概要を調べ、実際に触ってみたのでまとめてみました。
データクリーンルームとは
データクリーンルームとは、プライバシーを保護しながら複数事業者のデータを連携できる環境のことです。
データの中でも特に個人情報といったセンシティブデータを連携するための環境として利用されることが多く、データクリーンルーム内ではデータは完全に保護されており、データを公開することなく共有、統合、分析などに行われます。
Analytics Hubとは?
Analytics Hubは、組織間での大規模なデータ共有を可能とするデータ交換プラットフォームです。
Analytics Hubを利用することで、組織は煩雑なIAM管理やプロジェクト管理から解放され、「誰に」「どのようなデータ」を提供したのか、そのデータがどのように利用されているのかを簡単にダッシュボードから管理することができるようになります。
データを提供する側(パブリッシャー)とデータを利用する側(サブスクライバー)をつなげる、文字通り「Hub」となるサービスです。

Analytics Hub のサブスクライバー ワークフロー
BigQuery DataCleanRoom
BigQuery DataCleanRoomはAnalytics Hubプラットフォーム上に構築されています。
Analytics Hubは組織間での大規模なデータ共有を可能にするサービスですが、データクリーンルームでは、複数の組織でデータを移動または公開することなく共有、統合、分析ができる環境を提供しています。
BigQuery DataCleanRoomにはAnalytics Hubの機能に加えて、「データの保護」「プライバシーポリシーの適用」といった追加の機能が拡充されています。
BigQuery DataCleanRoomの登場人物
BigQuery DataCleanRoomには、データを提供する「データ コントリビューター」とデータの分析を行う「サブスクライバー」という二つの役割があります。
データコントリビューターは、自身のBigQuery上で構成されたデータセットから、クリーンルームにデータを共有する権限を持っており、クリーンルーム内で利用するデータを投稿することができます。
サブスクライバーは、構成されたクリーンルームに対して、クエリーを実行する権限が付与されており、クリーンルーム内で利用可能なデータに対して操作を行うことができます。
これらの役割はデータ クリーンルームのオーナーにて管理されており、オーナーは権限の管理の他に、データコントリビューターと同じようにデータの投稿を行うことができます。
BigQuery DataCleanRoomの構成
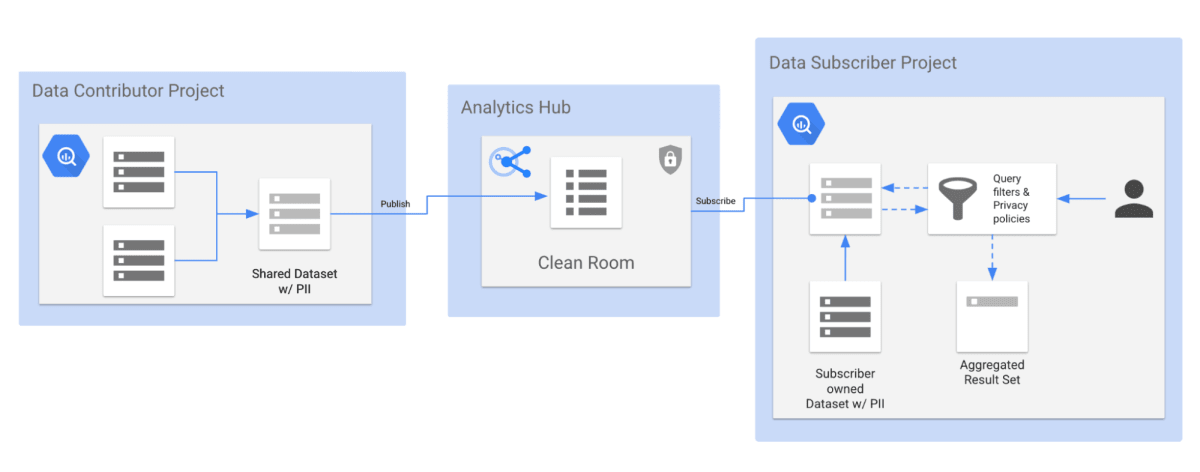
BigQuery DataCleanRoomは、データの構成とクエリーの構成を行う「BigQuery」と、データ共有・連携を行う「Analytics Hub」に分かれています。
データコントリビューターは、自身のBigQueryプロジェクト上で共有するデータセット(共有データセット)を構成し、所定のクリーンルームにデータをPublishします。
Publishされたデータは、リスティングとしてサブスクライバーに共有されます。
リスティングには、データセットの説明やサンプルクエリー、ドキュメントへのリンクといったメタ情報が設定され、サブスクライバーは生データを確認する代わりに、データの構成や状態を把握することができます。
サブスクライバーは、リスティングをSubscribeすることで、リンク済みデータセットを作成します。
リンク済みデータセットに対してクエリーを実行することで、共有データセットに対して分析を行うことができます。
実行できるクエリーは、集計しきい値のプライバシーポリシーによって制限されており、以下のような特徴があります。
- クエリー結果は統計情報のみ出力され、レコード抽出は不可
- privacy_unit_column(個人を特定する識別子)で指定したカラムには集計関数のみ適用可能で、GROUP BYはできない(個人特定は不可)
- thresholdで指定した値以下の集計値は、集計結果に表示しない(ex.3レコード以下で構成される集計値は除外する)
BigQuery DataCleanRoomを使ってみる
BigQuery DataCleanRoomで出た分析を開始するためには以下のフローが必要です。
- クリーンルームオーナーのフロー
1.1 クリーンルームの作成
1.2 権限の設定 - データコントリビューターのフロー
2.1 データの準備
2.2 リスティングの作成 - サブスクライバーのフロー
3.1 リンク済みデータセットの作成
3.2 クエリーの実行
詳細は、BigQueryのドキュメントに全て書かれているため、ここではポイントだけ押さえながら解説します。
1. クリーンルームオーナーのフロー
1.1 クリーンルームの作成
Analytics Hubのダッシュボードからクリンルームを新しく作成します。
プロジェクト名やリージョンなどプロジェクトに必要な情報を入力して作成を実行します。
日本リージョンが選択可能なのも嬉しいですね。
1.2 権限の設定(任意)
他のユーザーとクリーンルームを共有する場合は、ユーザーの権限を設定できます。
「1.1クリーンルームを作成する」で初めに設定するか、クリーンルーム詳細から権限を設定で設定できます。
データコントリビュータを設定する場合は「Analytics Hub パブリッシャー」、サブスクライバーを設定する場合は「Analytics Hub サブスクライバー」を設定します。
「Analytics Hub サブスクリプションのオーナー」を設定すると、サブスクライバーに登録できるユーザーを管理することができる権限を付与できます。
2. データコントリビューターのフロー
2.1 データの準備
BigQueryにデータセットを作成します。
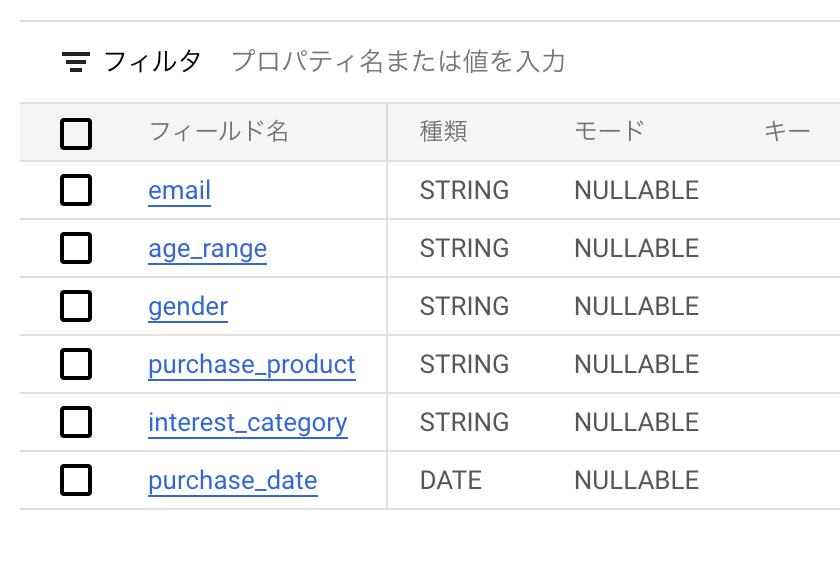
今回は以下のようなデータを準備して、BigQueryにデータセットを作成しました。
消費者の購買データをイメージしたデータになっています。
データクリーンルームで、集計しきい値のプライバシーポリシーが設定されたビューを利用できるように、「プライバシーポリシーの作成」と「ビューの承認」を行います。
プライバシーポリシーの作成
集計しきい値のプライバシーポリシーが設定されたビューを作成するために下記のクエリーをBigQueryで実行します。
CREATE OR REPLACE VIEW `dcr-zenn-demo.shared_pub_data.shared_pub`
OPTIONS (
privacy_policy= '{ "aggregation_threshold_policy": { "threshold" : 10, "privacy_unit_columns": "email" } }'
)
AS (SELECT * FROM `dcr-zenn-demo.pub_data.pub`);
VIEW:ビューを作成するパス
threshold:クエリ結果の各行に必要なプライバシー ユニットの最小数
privacy_unit_columns: プライバシー ユニットの一意の識別子を構成する列
AS: ビューの元となるデータセット
上記によって、プラバシーポリシーが構成されたビューが作成され、データセットを直接参照することなく、許可されたクエリーの実行と結果を取得できるようになります。
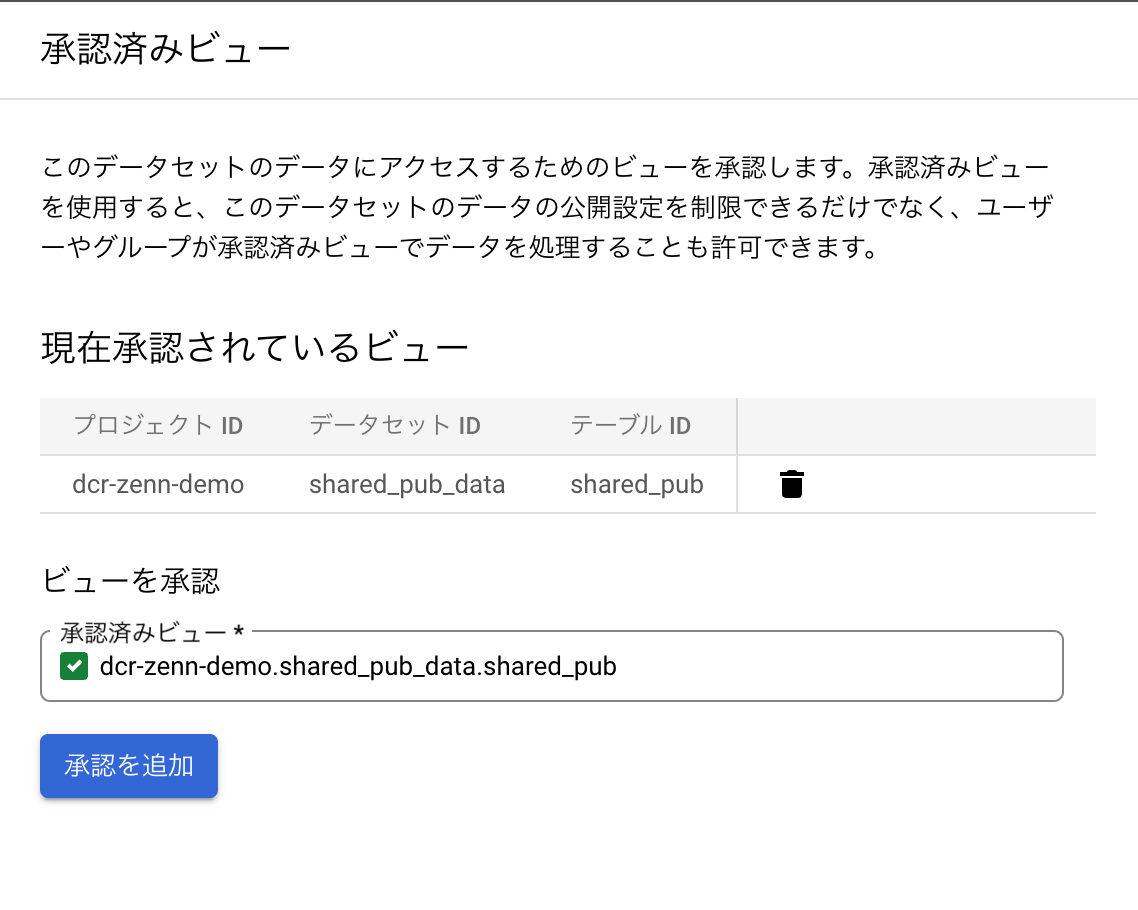
ビューの承認
上記で作成したビューを承認することで、ビューがデータソースにアクセスすることが可能になります。
ビューの承認は、BigQuery > データセットの選択 > +共有 > ビューを承認 から上記のビューを承認します。
作成したビューに対してではなく、ビューの元となったデータセット(pub_data)にするのがポイントです。

2.2 リスティングの作成
BigQueryのデータをデータクリーンルームに共有します。
Analytics Hubからデータクリーンルームを選択し、[データを追加]から先ほど作成したデータセットを追加します。
必要な情報を入力すると、下記のように確認画面が出てきます。
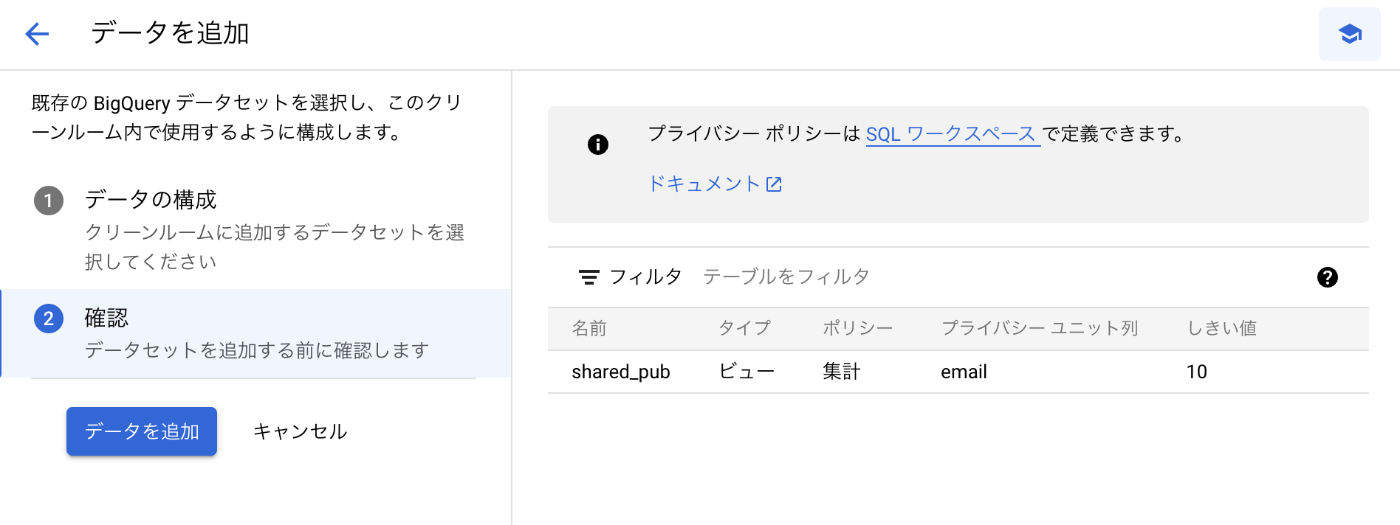
リスティングは、データセット単位で作成されるため、元となるテーブルとビューのデータセットを分けることで、クリーンルームにはビューのみを共有することができます。
3. サブスクライバーのフロー
3.1 リンク済みデータセットの作成
クリーンルームに追加されたリスティングにサブスクライバーからクエリーを投げれるようにします。
サブスクライバーとして利用するプロジェクトからAnalytics Hub > リスティング検索から先ほど作成したデータセットを探すことができます
データのサブスクライブが完了すると、BigQueryのエクスプローラー上にビューが生成されます。
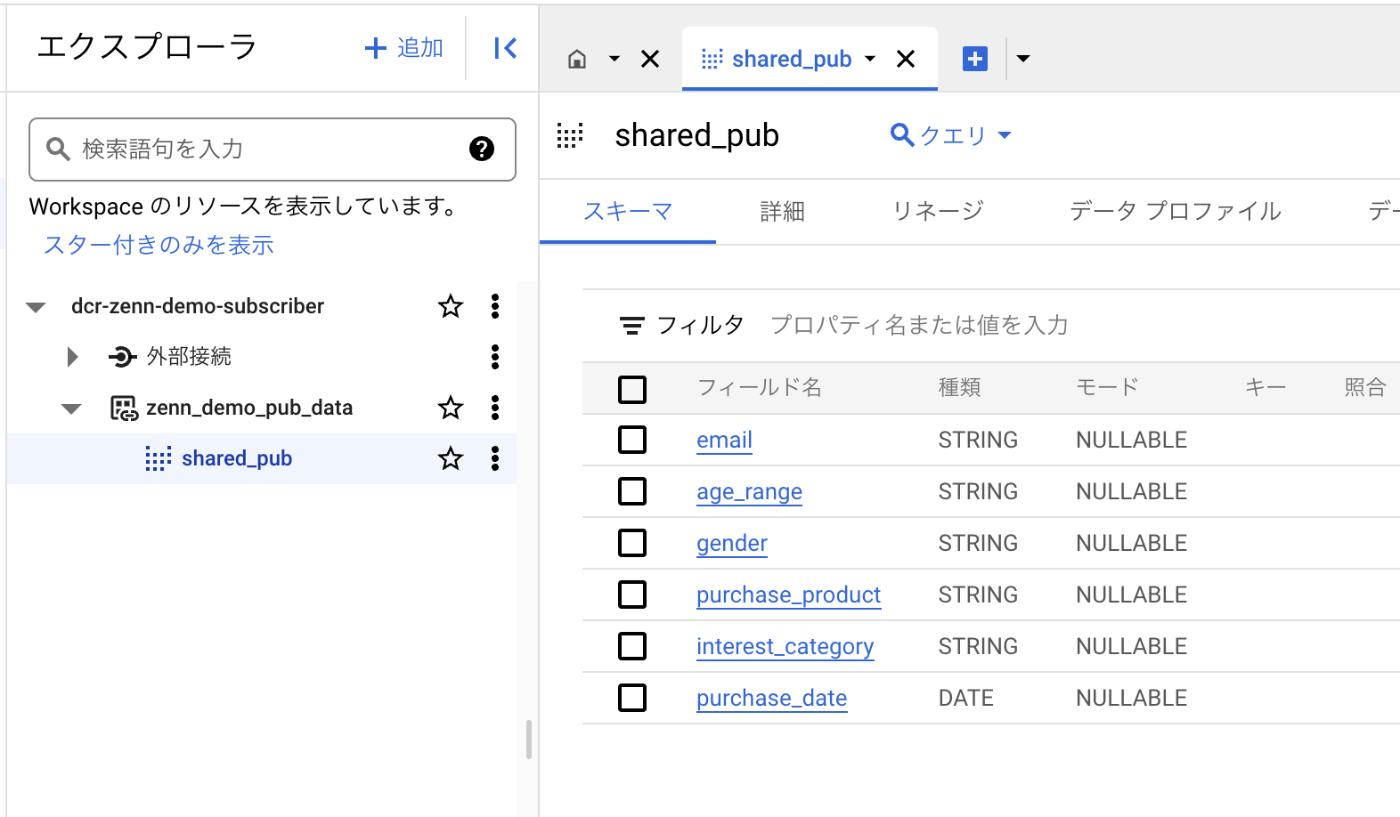
3.2 クエリーの実行
実際に共有されたデータセットのビューに対してクエリーを投げてみます。
クエリーにはいくつか制約があります。
- GROUP BYを指定する必要がある
- 集計関数を含ませる必要がある
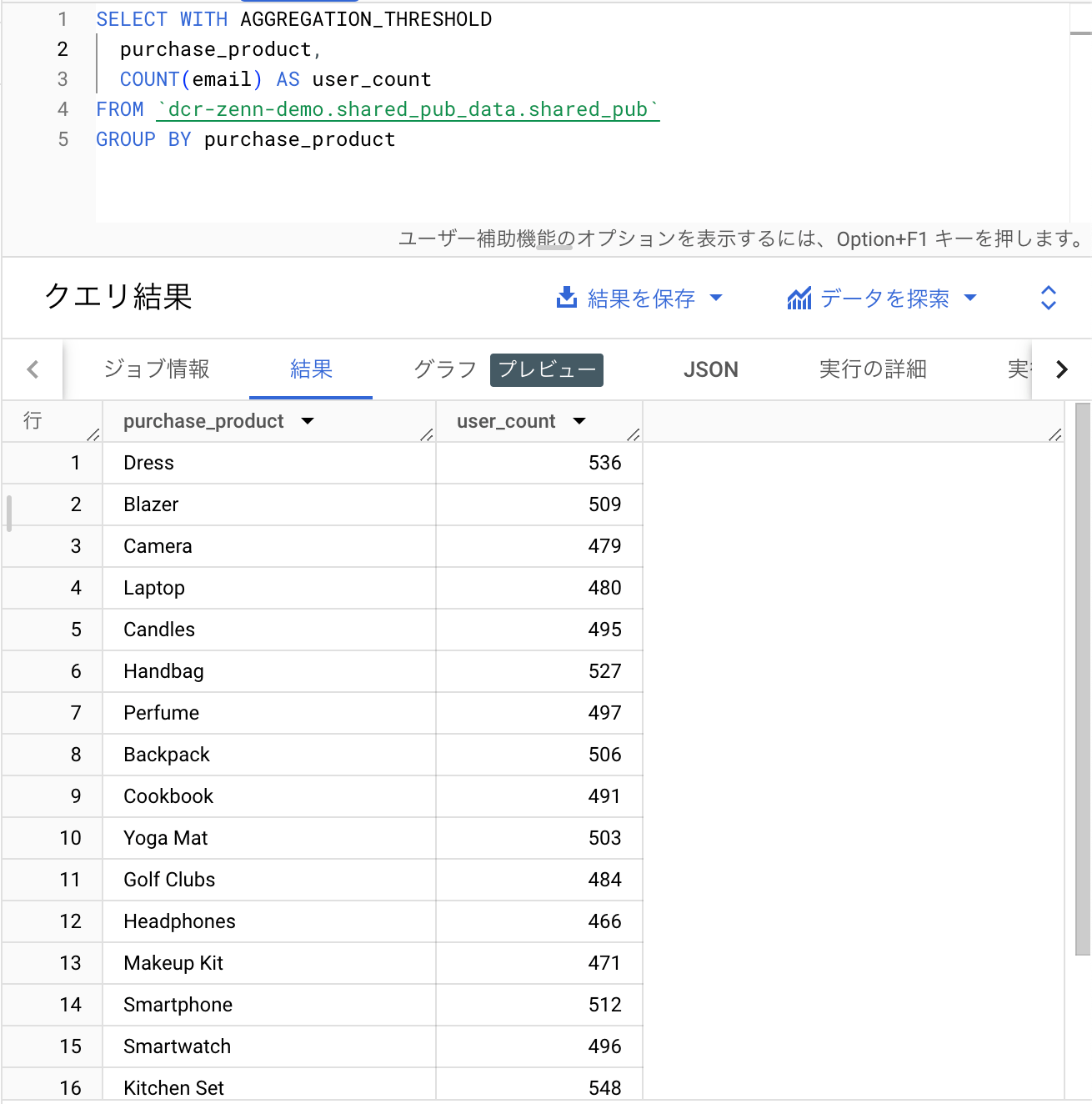
公式のクエリーを参考に以下のようなクエリーを生成しました。
SELECT WITH AGGREGATION_THRESHOLD
purchase_product,
COUNT(email) AS user_count
FROM `dcr-zenn-demo.shared_pub_data.shared_pub`
GROUP BY purchase_product
購入商品ごとのユーザー数をカウントする単純なクエリーです。
うまく取得できていそうですね。
おまけ:データの統合
データコントリビューと側のデータをサブスクライバー側で集計処理を行うことができました。
しかし、せっかくのデータクリーンルームですから、コントリビュータ側のデータとサブスクライバー側のデータを結合して集計を行えてこそのデータクリーンルームです。
JOIN句を用いた公式サンプルが無かったので、いくつか試してみました。
サブスクライバーの内部データセットとジョイン
サブスクライバー側でデータを用意し、BigQueryのデータセットを作成したものと、データクリーンルームのコントリビュータのデータのビューとで、メールアドレスを突合キーとした突合を行ってみます。
SELECT WITH AGGREGATION_THRESHOLD
purchase_product,
COUNT(email) AS user_count
FROM `dcr-zenn-demo.shared_pub_data.shared_pub`
GROUP BY purchase_product
INNER JOIN `dcr-zenn-demo-subscriber.sub_data.sub`
ON dcr-zenn-demo.shared_pub_data.shared_pub.email = dcr-zenn-demo-subscriber.sub_data.sub.email
エラーが出ました
Syntax error: Expected end of input but got keyword INNER at [6:1]
クリーンルームのビュー同士でジョイン
サブスクライバー側のデータセットをクリーンルームのデータセットとして追加を行い、ビュー同士でジョインできるか試してみました。
SELECT WITH AGGREGATION_THRESHOLD
purchase_product,
COUNT(email) AS user_count
FROM `dcr-zenn-demo.shared_pub_data.shared_pub`
GROUP BY purchase_product
INNER JOIN `dcr-zenn-demo-subscriber.zenn_demo_sub_data.shared_sub`
ON dcr-zenn-demo.shared_pub_data.shared_pub.email = dcr-zenn-demo-subscriber.zenn_demo_sub_data.shared_sub.email
やはりこちらもエラーでした。
Syntax error: Expected end of input but got keyword INNER at [6:1]
LiveRamp によるエンティティ解決
公式ドキュメントにエンティティ解決のための解説がありました。
以下抜粋です。
データ クリーンルームのユースケースでは、共通の識別子を含まないデータ投稿者とサブスクライバーのデータセット間でエンティティをリンクする必要があることがよくあります。 ... データの準備の一環として、BigQuery のエンティティ解決では次の処理が行われます。
- データ コントリビューターの場合、選択した共通プロバイダの識別子を使用して、共有データセット内のレコードの重複を除去して解決します。このプロセスにより、クロスコントリビューター結合が有効になります。
- サブスクライバーの場合は、自社データセット内のレコードとデータ コントリビューター データセット内のエンティティへのリンクを複製して解決します。このプロセスにより、サブスクライバーとコントリビューターのデータセットを結合できます。
BigQuery のエンティティ解決は、LiveRamp との統合が組み込まれています。
サブスクライバーの場合は、自社データセット内のレコードとデータ コントリビューター データセット内のエンティティへのリンクを複製して解決します。このプロセスにより、サブスクライバーとコントリビューターのデータセットを結合できます。
とのことだったので、LiveRampを利用することでIDレベルでの統合ができるみたいです。
残念ながら、LiveRampは無料開放されておらず、サンプル実装も見当たらないため、どのような利用イメージになるかはわかりませんが、ドキュメントを読むところLiveRamp側の機能を用いることで実現が可能そうです。
LiveRampは、データ間で異なる識別子(商品ID、ユーザーIDなど)を統合し、サイロ化されたデータを結合できるようにするソリューションを提供しています。
ドメインからRampIDと呼ばれる識別子を生成し、別のドメインのRampIDに変換して、第三者がRampIDを利用できるようにします
データのマーケットプレイス
ここまでで、具体的なBigQuery DataCleanRoomについて見てきましたが、BigQuery DataCleanRoomはただ組織間でのデータ連携を行うだけではありません。
Analytics Hubには、一般公開されているデータセットが用意されており、自由に利用することが可能です。

GoogleのデータやGitHubのデータ、広告のデータなど様々なデータセットが用意されており、その総数は210個にまで上ります。
連携先組織がいないような組織でも、こういったデータセットを用いることでリッチなデータを簡単に分析することができます。
ユースケース
データクリーンルームは、事業者間でのデータ連携に特化した機能を有しています。
主なユースケースは以下の通りです。
キャンペーンの計画とオーディエンスの分析情報
2 つの当事者(販売者と購入者など)が自社データを統合して、プライバシーを重視した方法でデータ拡充を向上させる。
測定とアトリビューション
顧客とメディアのパフォーマンス データを一致させることで、マーケティング活動の効果をより深く理解し、より多くの情報に基づいたビジネス上の意思決定を行うことができます。
Activation
顧客データと第三者データを組み合わせることで、顧客をより深く理解し、セグメンテーション機能を改善してより効果的なメディア アクティベーションを行うことができます。
主なユースケース
また、マーケティングに留まらず、様々な領域で活用が期待されます。
小売、消費財(CPG)
小売業者の POS データと CPG 企業のマーケティング データを組み合わせて、マーケティングとプロモーション活動を最適化します。
金融サービス
他の金融機関や政府機関からの機密データを組み合わせて、不正行為の検出を改善します。複数の銀行の顧客データを集計して、クレジット リスク スコアリングを作成します。
医療
医師と製薬研究者との間でデータを共有し、患者が治療にどのように反応しているかを把握する。
サプライチェーン、物流、輸送
サプライヤーとマーケターからのデータを組み合わせて、ライフサイクル全体における商品のパフォーマンスの全体像を把握します。
その他のユースケース
料金
データコントリビュータには、データストレージ(BigQuery)にのみ課金されます。

サブスクライバーは、クエリを実行したときにのみコンピューティング(分析)に対して課金されます。

まとめ
BigQueryのデータクリーンルームについて、特長や使用感についてまとめてみました。
データクリーンルームは、組織間でのデータ連携を行うためのソリューションとして今後ますます注目を集めていくものになっていくと思います。
BigQuery DataCleanRoomは、BigQueryの基盤上に構築されたデータクリーンルームとして、BigQueryの資産を最大限に生かしながら、組織間でのデータ連携を行えるものとして非常に洗練されたものであると思います。
データのクエリー制限や権限管理、分析の柔軟性など、プレビュー版と言いつつ、データクリーンルームで必要とされる機能はある程度揃っている印象がありました。
一方で、データ結合ができると言いつつ、現状はINNER JOINが使えなかったり、LiveRampを併用しないといけなかったりと、本当のデータ連携を実現するためにはまだまだ欲しいと思う機能がなかったりするのも事実です。
今後、機能拡充が進み、データクリーンルームとしての完成度が上がることを期待しています。
それでは今日のこのあたりで。

Discussion