ご挨拶
こんにちは!Acompanyのイナミです。
この記事は Acompany5周年アドベントカレンダー 3日目 の記事です。
今回は普段から実務で利用しているCountについて、Countとは何か、使い方についてまとめてみました。
Countをアドベントカレンダーのテーマとして書こうとしていた矢先に出たリリースでますます使いやすくなったので最後までご覧ください。
Countとは
ふつふつと話題になり始めている、FigmaのUIによく似たデータ分析ツールです。
おしゃれなUIに加え、要件の整理、プロトタイプ作成、クエリ作成、データモデリング、可視化、レポート作成、文書化をすべて1つのホワイトボードで行えるイメージです。
BigQueryなどに直接繋いだ上でSQLも直接書くことができますし、SQLのデータフローを表現することも容易だと思います。
まだベータ版ではありますが、弊社Acompanyでは複雑なパイプラインの整理や意思決定、ビジネスサイドのダッシュボード、デモなどに利用しています。
個人的にはretoolといったノーコードツールとBIツールを混ぜたものにも近いように感じています。
Countは他のツールと比べて、CSVアップロードからSQLを書けてチャートやダッシュボードまで作れる手軽さは他ツールにはないCountの強みだと思います。
2023/5/31リリースでPythonも使えるようになった
ここまでご説明した内容でも魅力的なツールですが、なんと5/31に衝撃的なリリースが飛んできました。
なんとPythonをcellとして表現することができるようになりました!
特に最高なのはpandasデータフレームとDuckDB上のSQLを相互変換できる点です。
これによって様々なデータをシームレスに加工できると思います。
流行りのOpenAIとCountを一緒に使ってみよう
現段階でも非常に使いやすくとても今後に期待できるCountでちょっとしたチュートリアルを作ってみました。
人気のOpenAIに対してCountからAPIへリクエストをしてみましょう!
キャンバス公開してます
すでに一般公開したデモがあるのでサクッと完成品を見てみたい方はこちらをご覧ください!
OpenAI準備編
まずはOpenAI APIへリクエストを行うためにAPI Keyを入手しましょう。
OpenAIにサインアップ&ログインした後、下記リンクからAPI Key設定画面へ移動します。
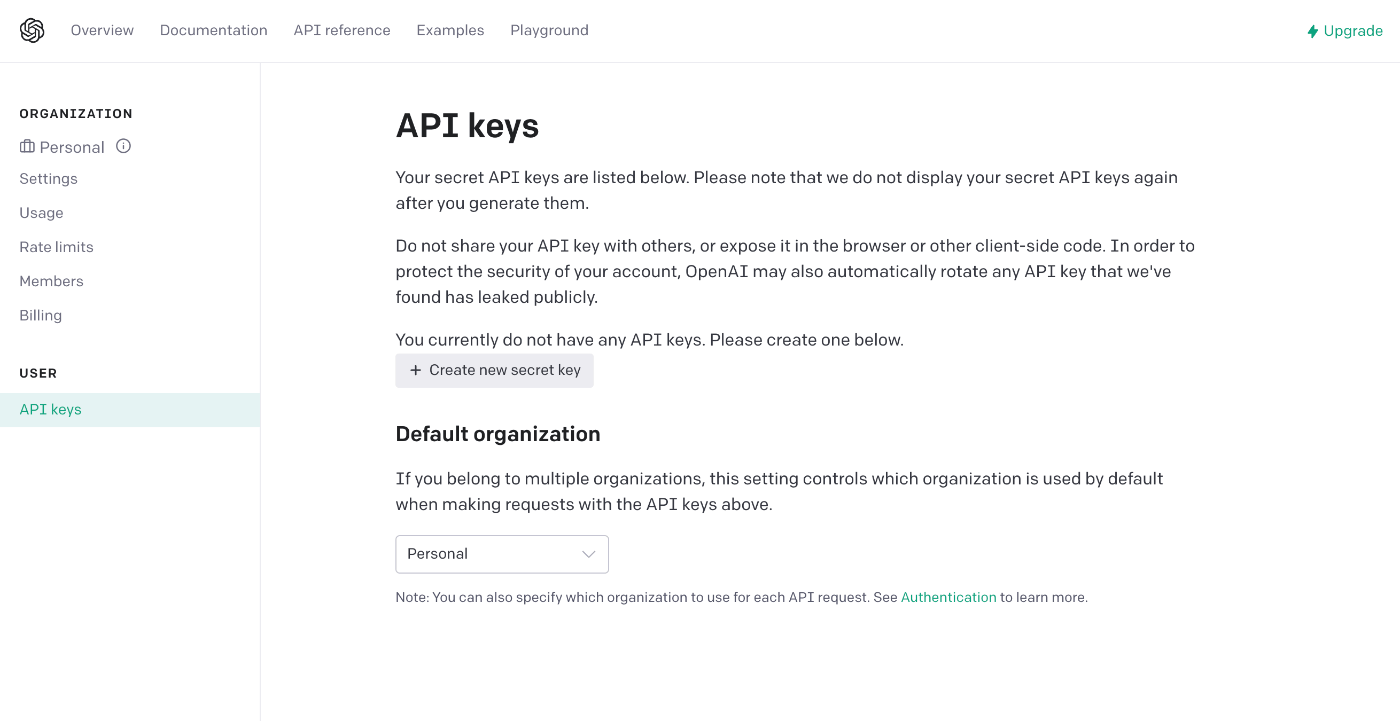
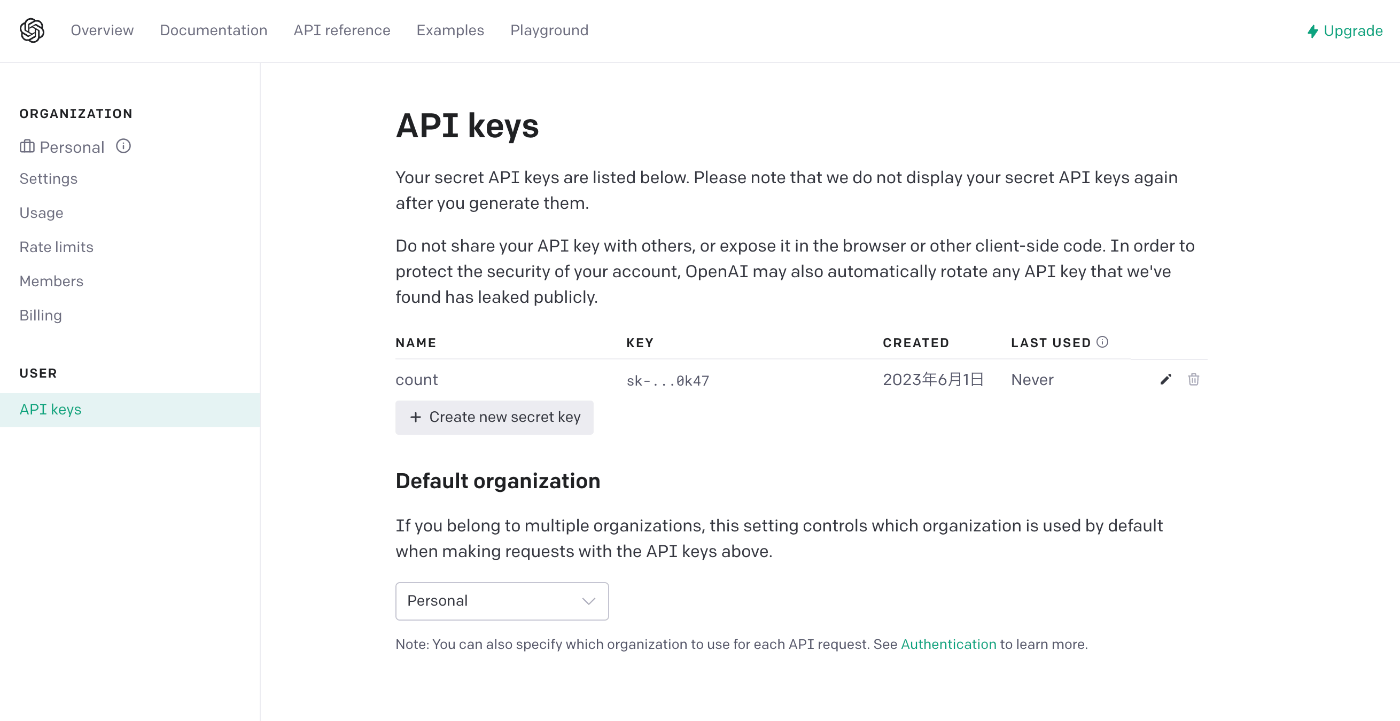
API Keyの設定画面が表示されます。
まっさらな状態であれば画像とほとんど同じような画面になっていると思います。
早速API Keyを入手しましょう。
画面中央の + Create new secret key ボタンをクリックします。
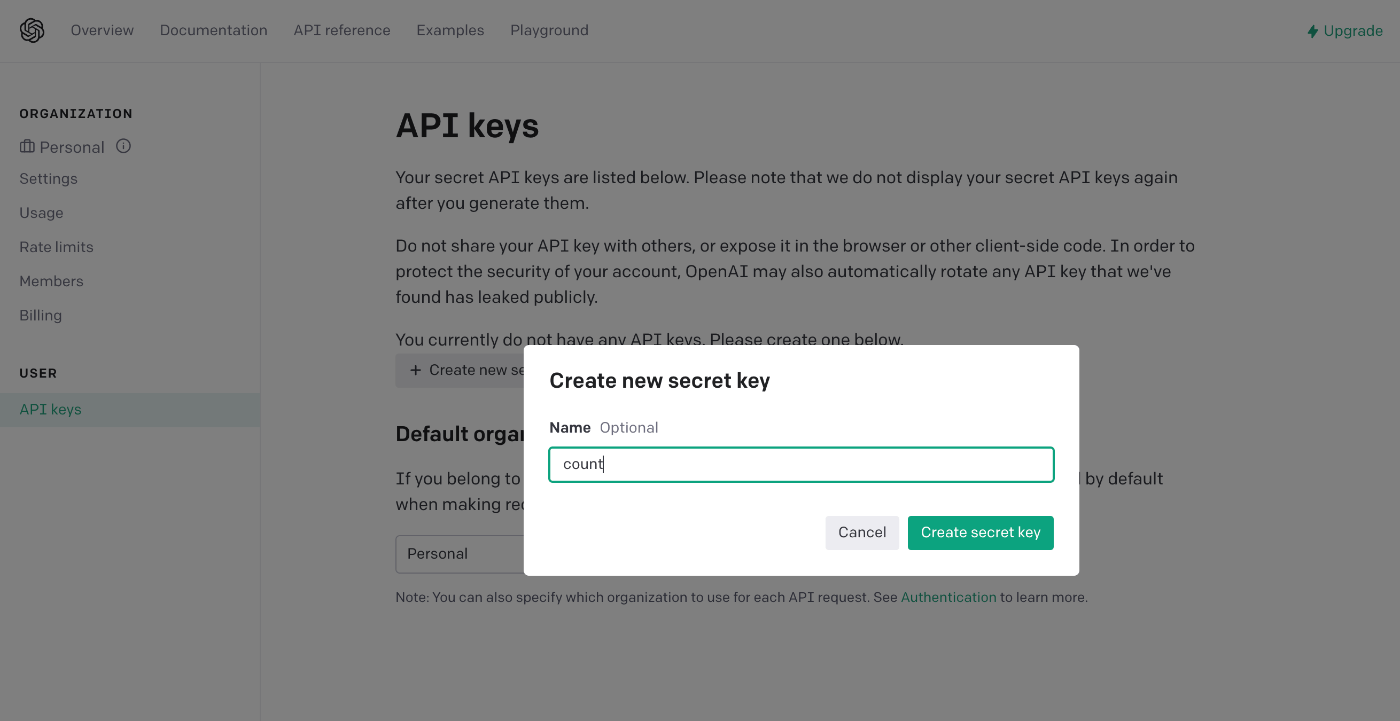
API Keyの識別名を入力します。
ここではわかりやすくcountと入力しましょう。
入力したら Create secret key ボタンをクリックします。

API Keyが発行されます。
これの文字列をメモしておきます。
メモし終えたら Done ボタンをクリックして準備完了です。
シークレット登録方法編
次にCountへAPI Keyをシークレットとして登録します。
Countではキャンバス上に秘密情報を表示しないためにシークレットを利用することができます。
これによってアクセスキーを特に意識せずともキャンバスでデータを操作することができます。
シークレットについての説明は下記をご覧ください。
操作するプロジェクトを用意しましょう。
ここでは新しく空のプロジェクトを用意しました。
赤枠の Manage project ボタンをクリックします。
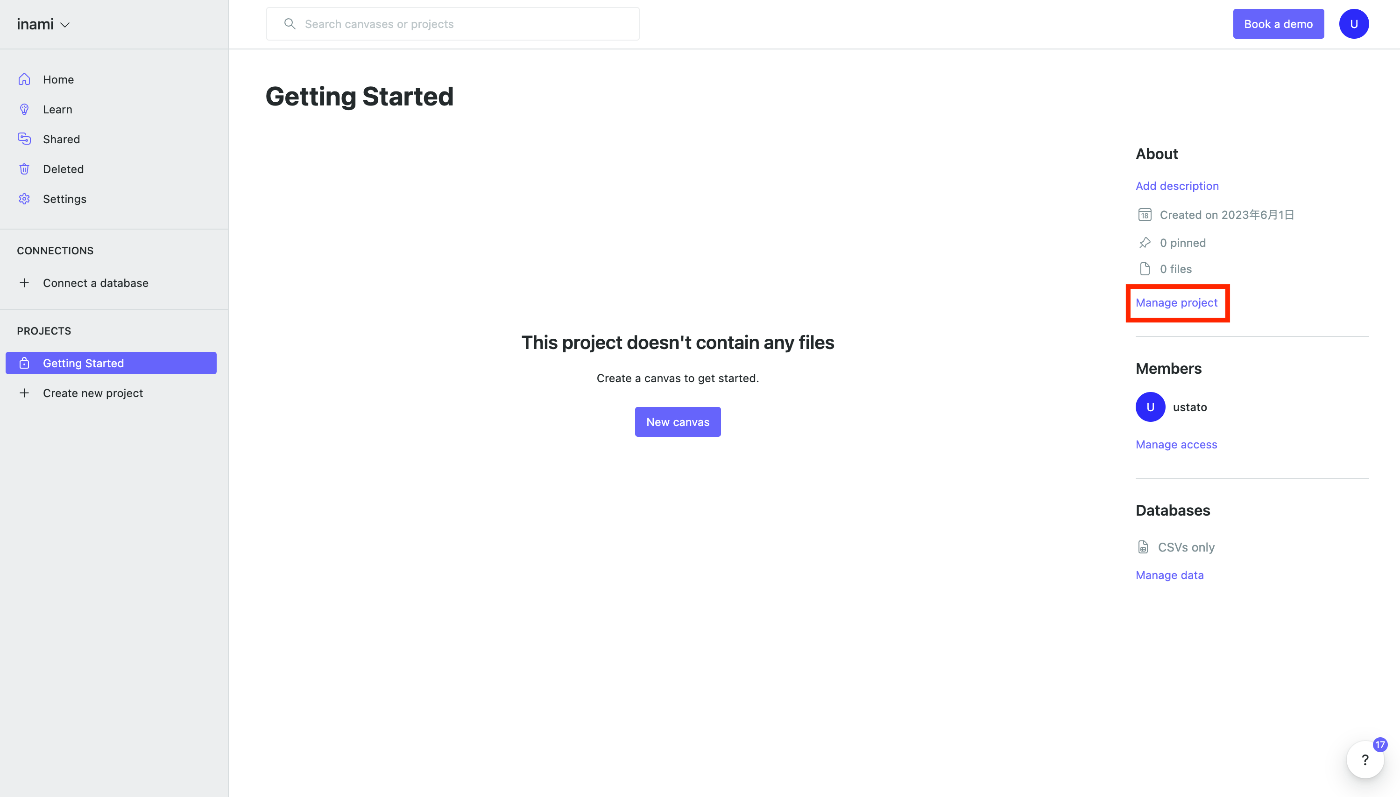
プロジェクトの管理画面が表示されます。
次に赤枠の Edit secrets をクリックします。
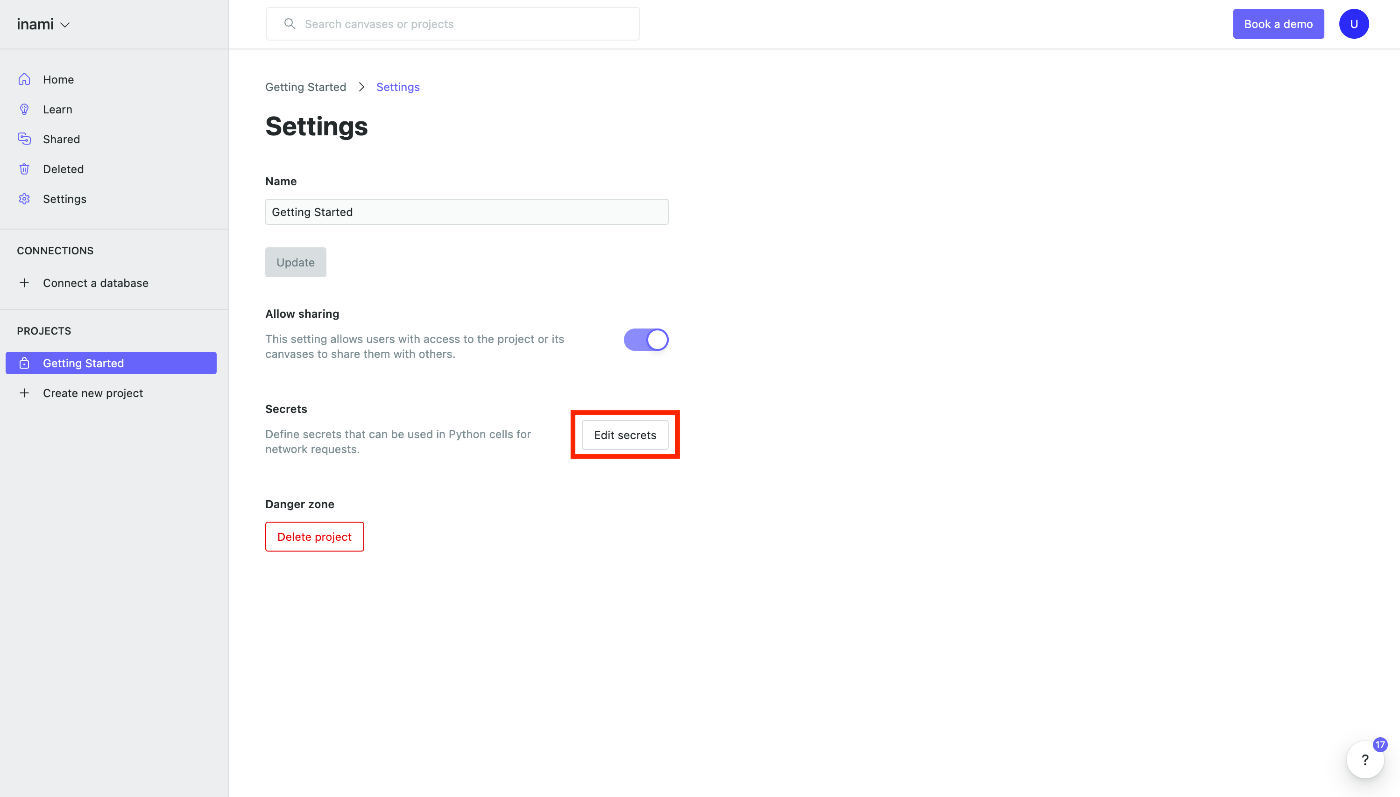
シークレットの登録画面が表示されます。
ここで先ほどメモしておいたOpenAI API Keyを入力します。
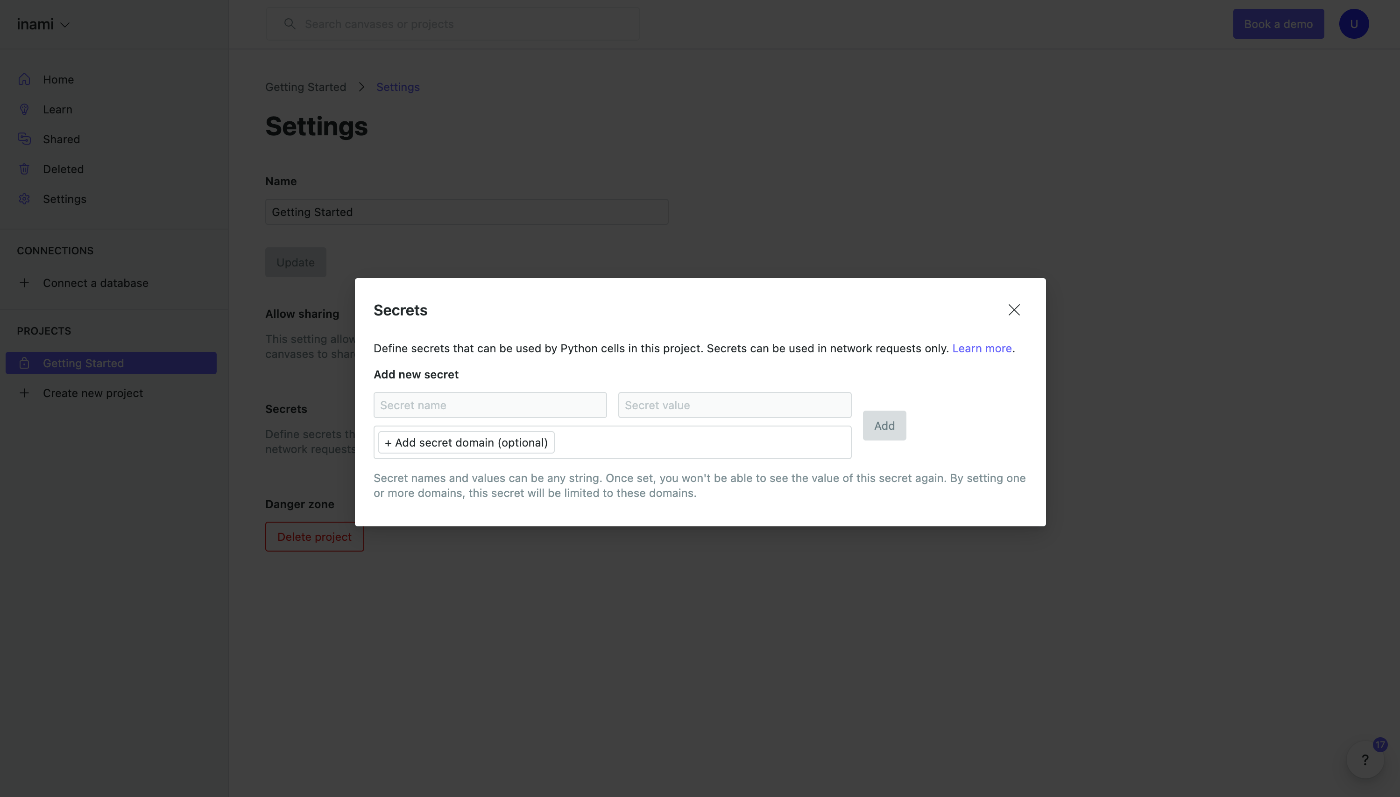
シークレットの識別名とAPI Keyを入力しました。
ここでもわかりやすく openai-api-key と入力しましょう。
入力したら Add ボタンをクリックします。
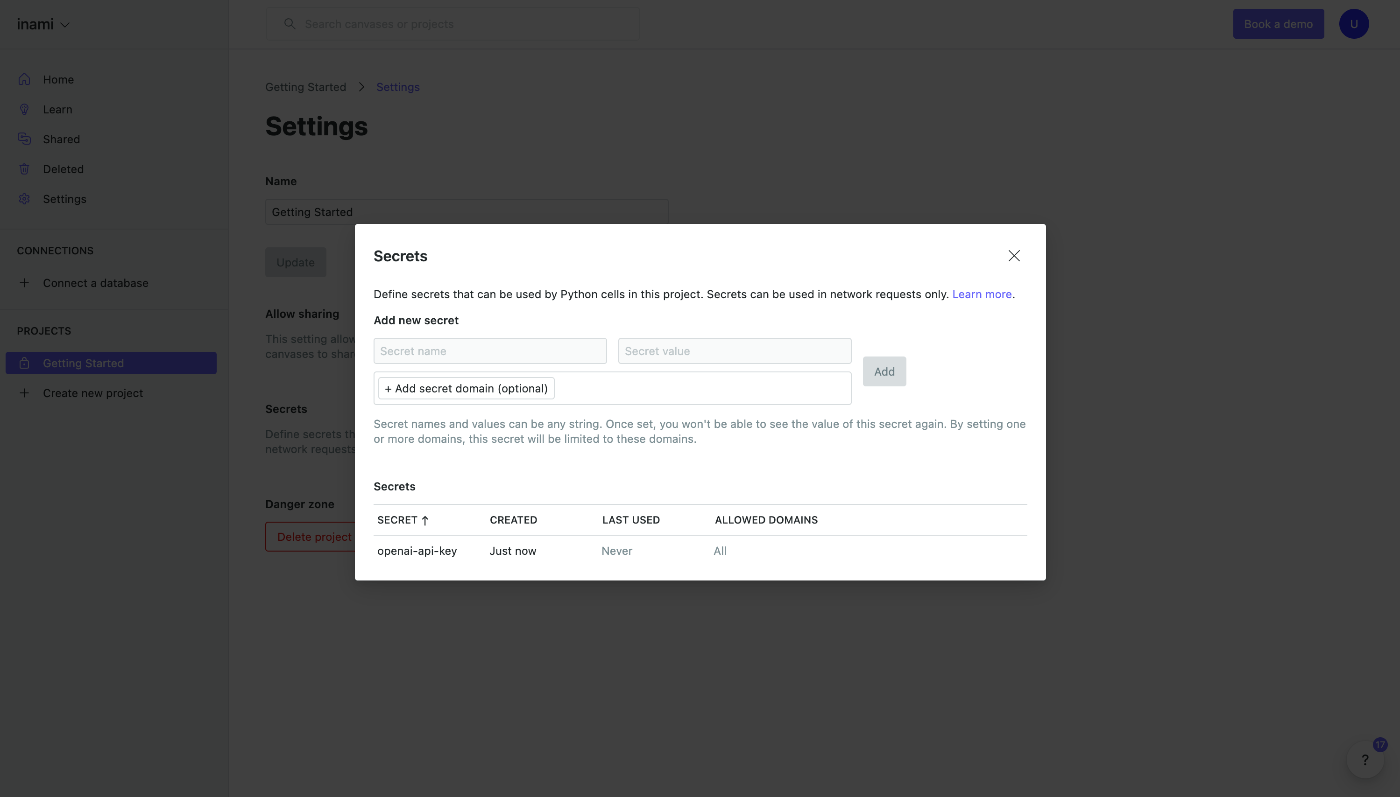
シークレットが登録されました。
このシークレット自体へ更に制約を追加することもできますが、今回はあまり関係ないのでこのまま先へ進みましょう。
キャンバス作成編
OpenAI APIへPOSTリクエストを送信するキャンバスを作っていきましょう。
New canvas ボタンをクリックします。
空のキャンバスが表示されます。
下のアイコンからPython Cellを選択しましょう。
Python Cellが表示されます。
手始めにHello, worldしてみます。
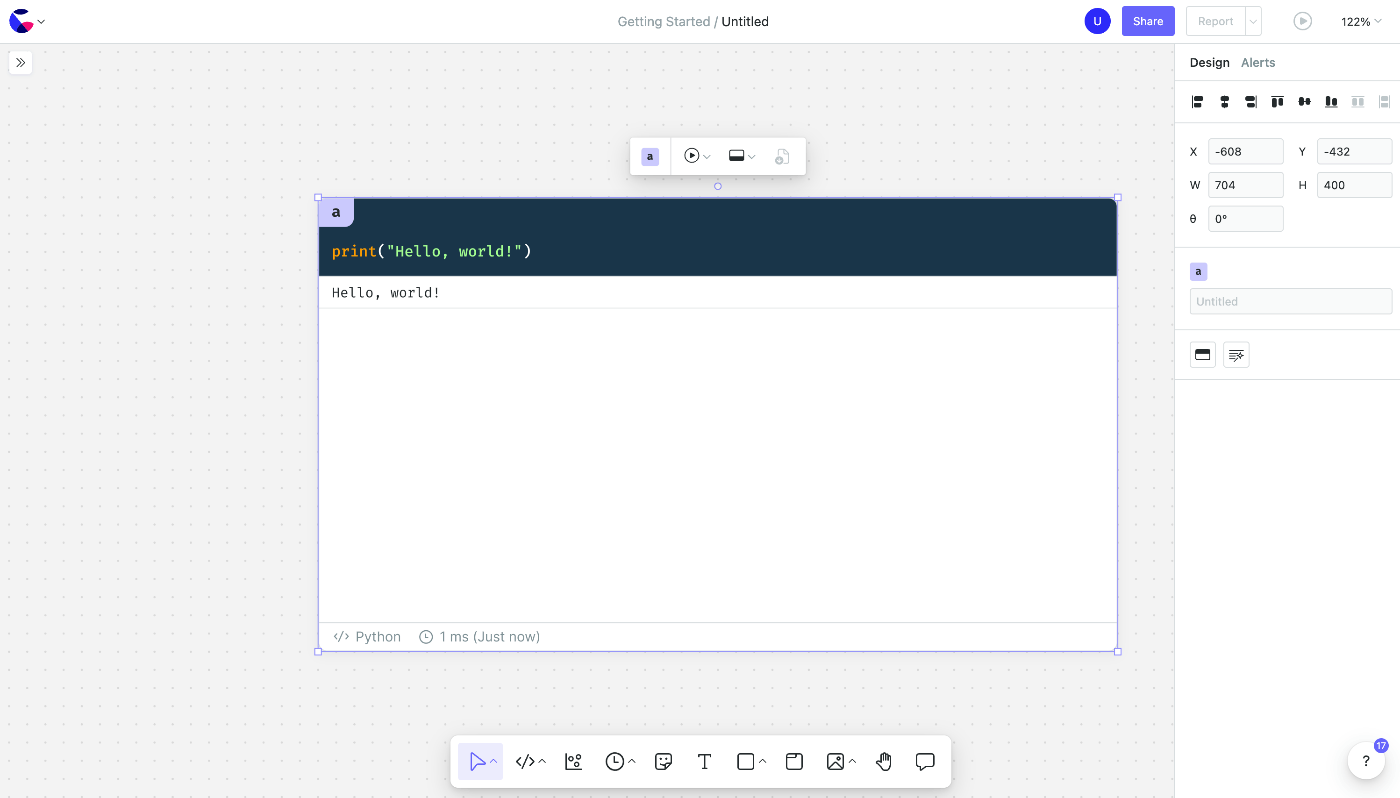
動作しました。
ここまで来れば残るはリクエストを送るだけです。
APIリファレンスの実行例を参考に作ってみましょう。
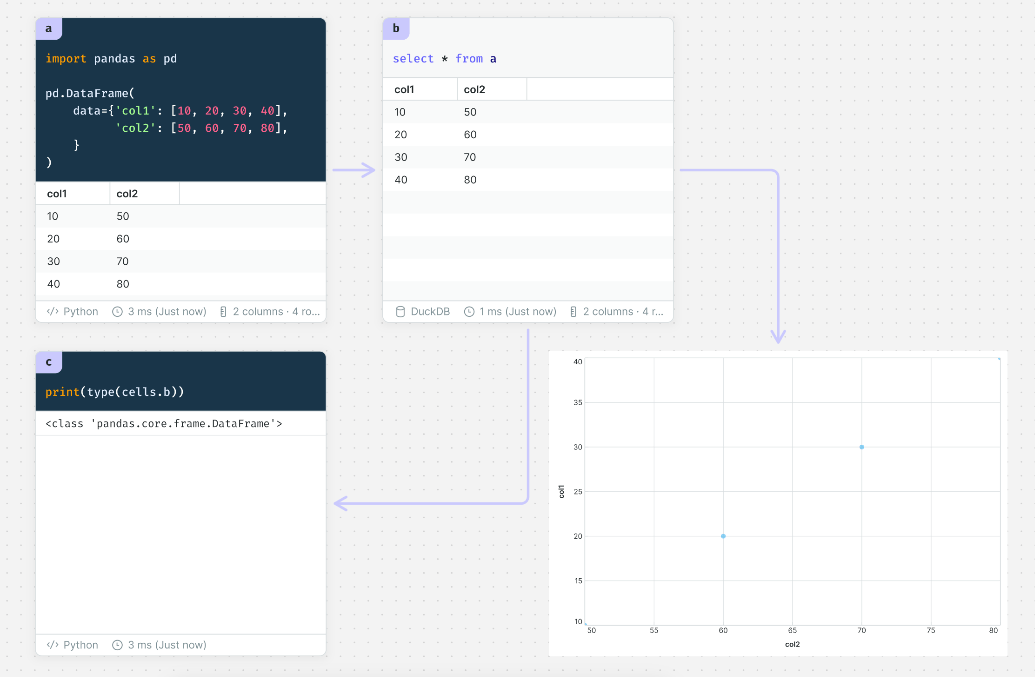
少し工夫すれば画像のようなセル群を作ることができます。
最初に左上のセルにシークレットを読み込ませています。
ただしシークレットは通常のprint等はできずCountのHTTPライブラリ上でのみ展開されるようです。
実際にprintしましたが無意味な文字列が表示されてしまいます。
base64にも見えますが、$マークを削除してデコードしても無意味なままでした。
次に左上のセルから右のセルにシークレットが入った変数を渡しています。
Countでは別のセルの値も簡単に読み込む事ができます。
シークレットが入った変数を使ってCountのHTTPライブラリからOpenAIへPOSTリクエストを送信します。
最後にレスポンスをawaitして結果を表示しています。
JSON形式でOpenAIから結果を受け取ることができます。
Python cellsの注意点
openaiのPythonパッケージは2023/6/1現在Countで使えない
公式のPythonパッケージは6/1現在利用できないようです。
今回の記事では代わりとしてAPIに直接postして対応しました。
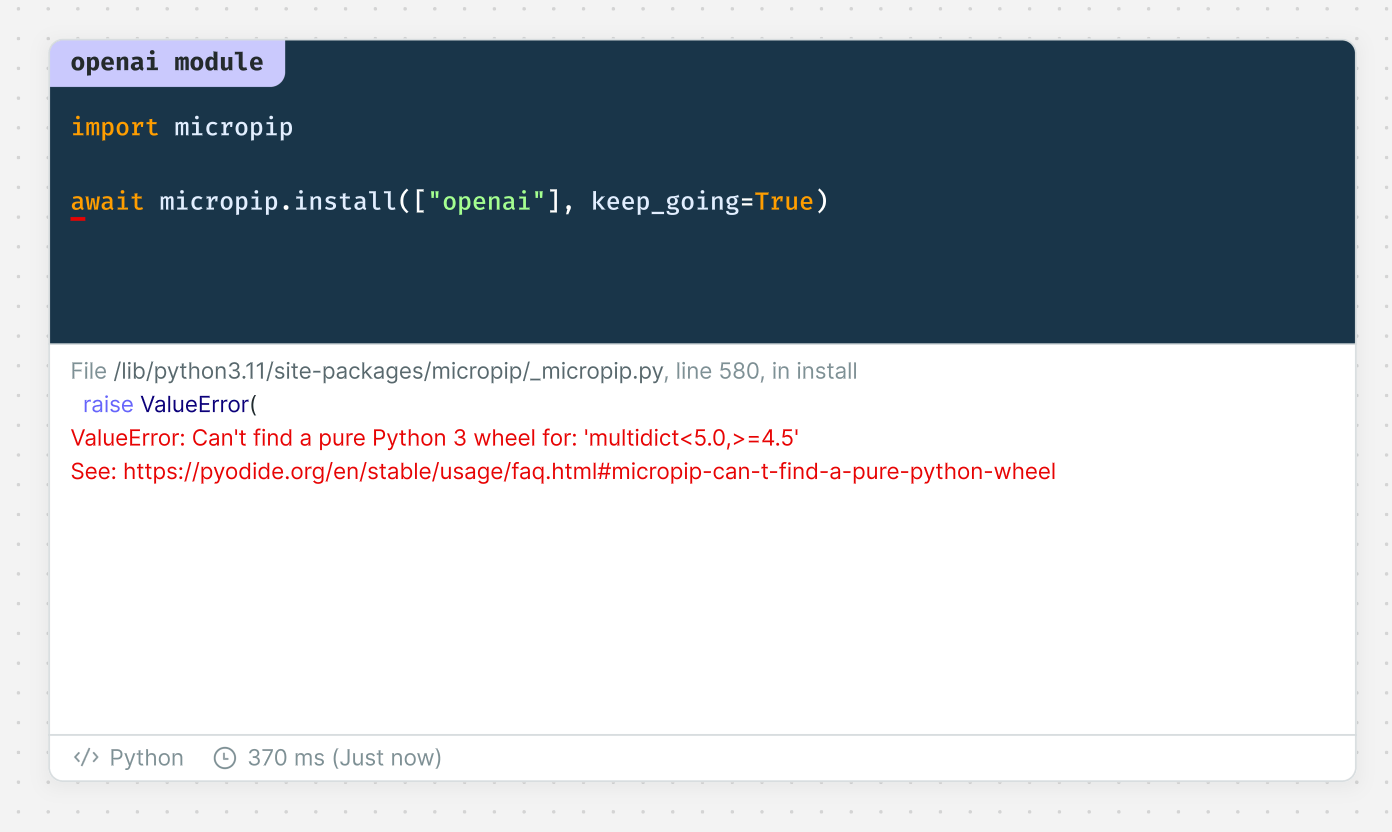
調べてみたところ、Pyodideとopenaiに両方ともissueが上がっていました。
依存関係が解消されたパッケージしか利用できない
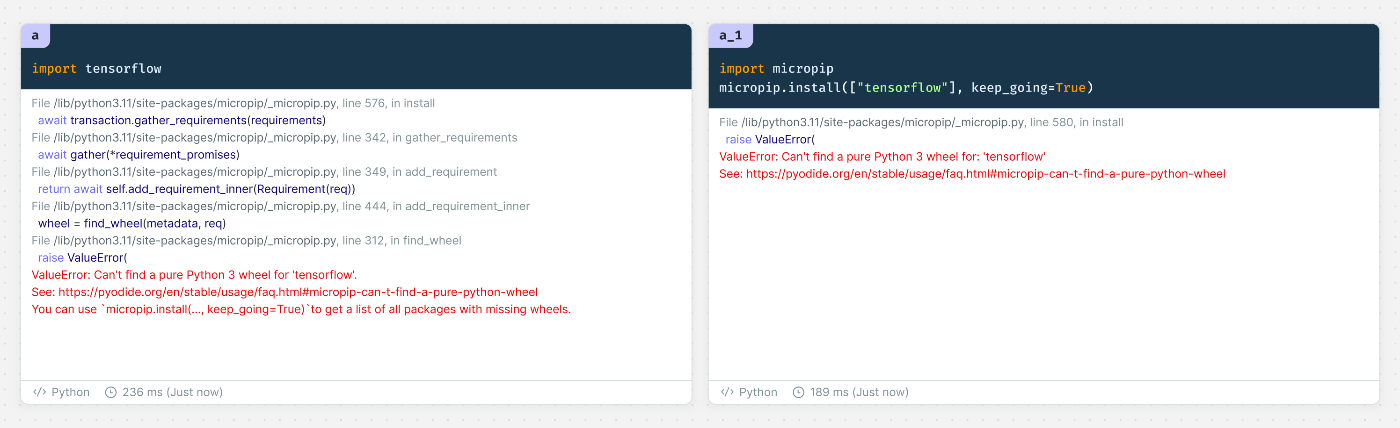
openaiのPythonパッケージは2023/6/1現在Countで使えない についての原因ですが、Pyodideで利用できないパッケージはCountでもできないようです。
パッケージ固有の様々な依存関係が解消されない場合はインストールもできないようです。
試しにtensorflowをインストールしようとしてみましたが失敗しました。
Pyodide公式によって依存関係が解消され利用できるようになっているパッケージ一覧は下記です。
LightGBMやXGBoostも利用可能となっているようです。
imoport <package>でpip installまでされている可能性
Python cellsにインストールされていないであろうパッケージをインポートしても読み込む事ができるようです。
例として janome という形態素解析ツールがありますが、基本的には日本国内で使われている印象があります。
そのためCountに最初からインストールされている可能性は低いと考えています。
しかしながら実際にimportしてみると問題なく利用できそうです。
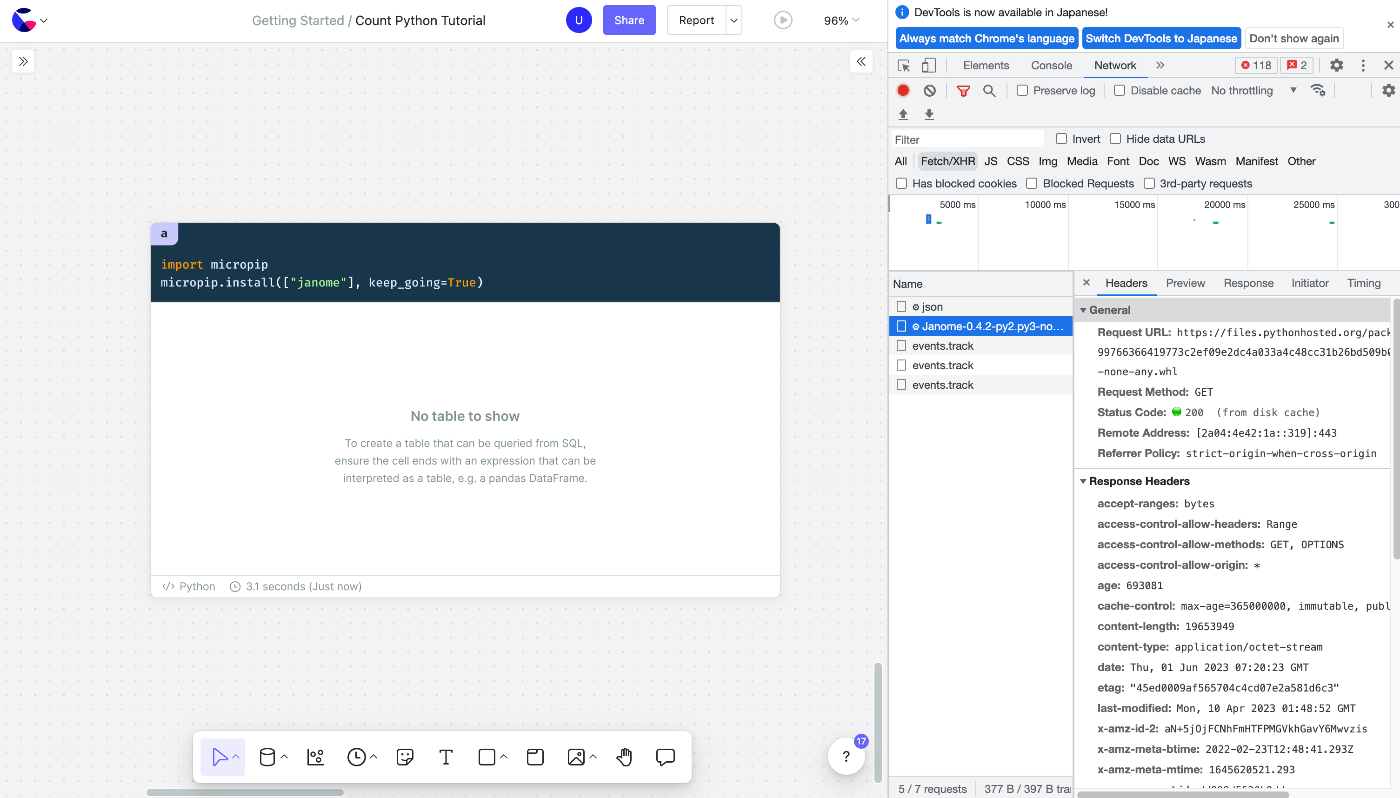
PyodideはwasmなのでChromeの開発者ツールでなにかfetchしていないかなと見ていると、どうやらimport時にPyPIからwhlファイルを引っ張ってきているようです。
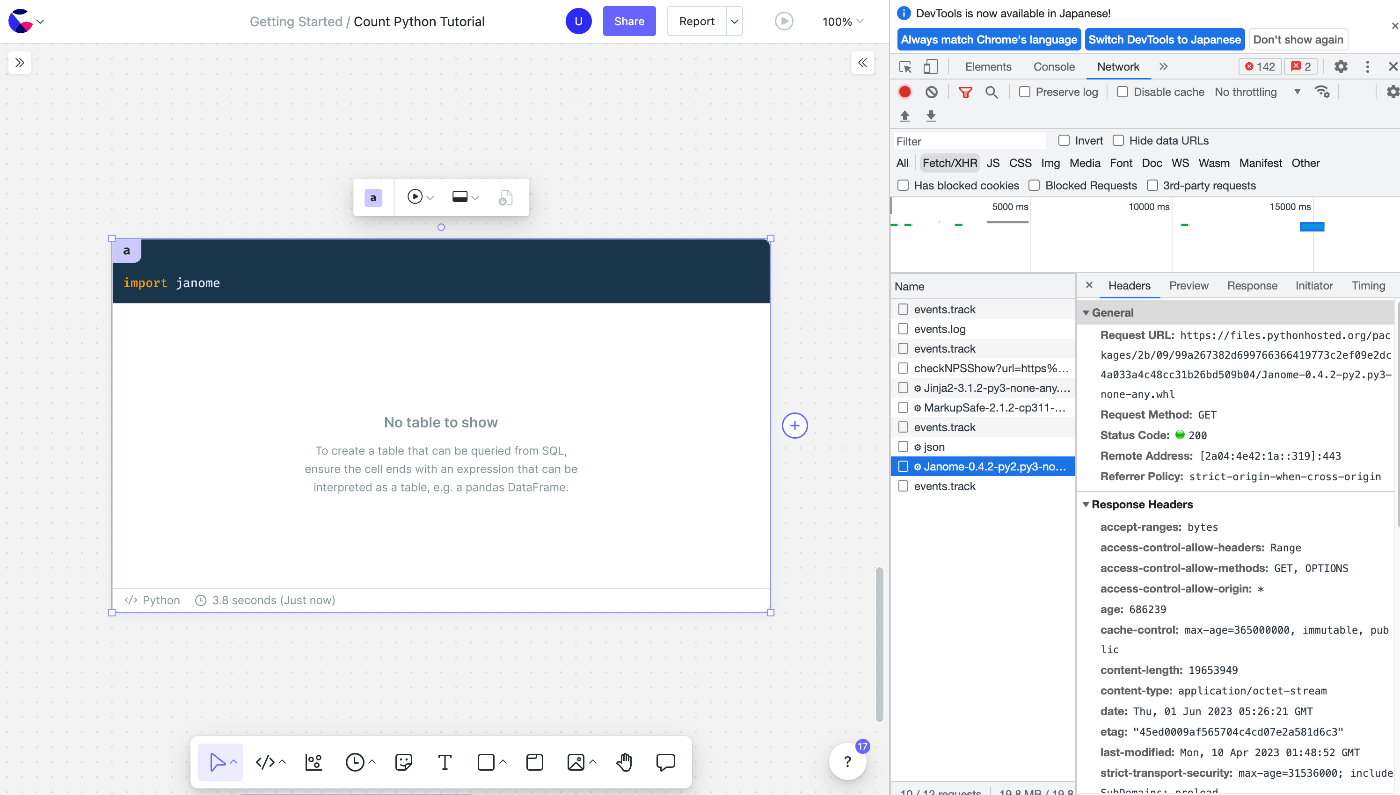
あくまで仮説ですが import が発生したら直接インストールしているのではないかと考えています。
ページを更新しインストールし直すべき状態において micropip.install() を行っても同様の処理であることが読み取れます。
今後の展望
PoCのサイクル高速化
Countを実務で使うユースケースとしてはデータ基盤やデータパイプラインのPoCを高速なサイクルで対応できると感じています。
データ基盤やデータパイプラインを作る際にいきなり実装してしまうと最終的なアウトプットがよくわからないといった事態に陥ってしまう可能性があると思います。
そうならないために手元で加工して一旦すり合わせすることがあると思いますが、Countであれば加工し認識を合わせた後もそのままレポートやダッシュボードとしても使えるかもしれません。
別のシーンではデータパイプラインをCountでざっくりとイメージを固めてから、AirflowやDagsterといったワークフローオーケストレーションツールで実装するという使い方もできます。
私は実際にこの手順でデータパイプラインに関するPoCを対応していますが、中々使い心地は良いと感じています。
実装レベルで共通認識が取りやすいので取引先との認識合わせにも役立つと感じています。
ChatGPT × SQL
CountでChatGPTが利用可能になりその結果を更に加工することができるので今後はChatGPTからSQL形式で実装を受け取れそうです。
そうなればCount上で半自動的にSQLベースのパイプラインを組むことも不可能ではなさそうですね!
データ加工の共有ツールとして
これまではデータエンジニア、AIエンジニア、データサイエンティストなどがそれぞれ使いたいツールを使ってレポーティングする場面があったように思います。
- データエンジニア
- SQL
- ワークフローオーケストレーション
- AIエンジニア(代表的なもの)
- データサイエンティスト
- R言語
- Python
- BIツール
これら人材はPythonという共通項が存在することはありますが共同で作業することはあまりないと思います。
各々が作った成果物のレポートを個別に集約せず、精緻化された一貫性のある数値を出そうとすると互いのロジックを共有する必要が出てきます。
まだまだ理想的でない部分はあると思いますがCountは現時点でも列挙したほとんどの要素に対応できているといえるので、互いのロジックを繋ぎ合わせることも可能になってくるかもしれません。
様々な職種のメンバーが共有ツールとしてCountを利用することでビジネス目標に最短で近づけそうに感じました!

Discussion