ご挨拶
こんにちは!Acompanyのイナミです。
この記事は Acompany5周年アドベントカレンダー 17日目 の記事です。
今回は私が担当した 3日目の記事 に引き続きCountについて、詳しくご紹介できなかったチャートの種類や可視化の機能をご紹介します。
3日目の記事 ではPython cellsやSQLを用いたパイプラインをご紹介してます!
まだお読みになっていない方はこちらも合わせて読んでくださると大変嬉しいです。
Countとは?何ができるの?
Countの基本的な説明は割愛させていただきたいので、前回の記事での #Countとは をご参照ください。
チャートやダッシュボードについて
CountはFigmaのUIによく似たデータ分析ツールですがホワイトボード上で簡単にデータを加工できるほかに、チャートやBIツールを用いた分析や可視化、ダッシュボード作成も行うことができます。
BIツールとしても使えるほど豊富なチャートが多く実装されているので、気軽に可視化し共有するために中々使えるツールだと思います。

チャート使ってダッシュボードを作る
なぜ作るのか
私は実務でCountをパイプラインやワークフローの設計として使っているので最近はチャート使ってダッシュボードを作る機会を作れていませんでした。
通常のBIツールだとデータが揃っていないと何もできなかったりするので腰が重いのですが、Countであれば簡単なデータを取得する実装から作れてしまうのでドッグフーディングにうってつけでした。
何を作るのか
いきなりダッシュボードを作ると言ってもデータもなく利用用途もない状態になってしまうのでなにかしらの題材が必要です。
成果物に対する期待を考えたいですがどのような題材でも下記のような選択肢が出てしまうかと思います。
- ゼロから納得の行くものを作ってみるのか
- 機能をゆるふわに体験したいだけなのか
あえてここでは既存のダッシュボードを模倣してみて使い心地だけ理解することとします。
デジタル庁が政策データダッシュボード出しているので模倣する
題材としてはデジタル庁が公開している 政策データダッシュボード というものを選んでみました。
データもダッシュボードも公開されていてそっくり模倣できるので、Count製模倣とPowerBI製本物のちょうどいい比較材料になりそうです。
政策データダッシュボードをCountで作る
CSVファイル準備編
まずはチャートに表示するために 政策データダッシュボード のページからデータを取得しましょう。
ページのセクション一個目にCSVファイルをダウンロードできる データデーブル ボタンがあるのでこれをぜひ使いたいです。

Webスクレイピングでデータ自動更新されるダッシュボード
すぐにCSVファイルが欲しい場合は データデーブル ボタンをクリックしてダウンロードでもよいのですが、ひと工夫加えて管理の手間を減らします。
今回は データデーブル ボタンのダウンロードURLをPython cellsで毎回Webスクレイピングすることでデータ更新も動的に行えるように実装します。
Webスクレイピングを軽量に行いたいので必要最小限のパッケージだけを利用して実現します。
こちらの記事 を参考にして、HTTPクライアント requests パッケージを count_requests に置き換えた上でWebスクレイピングパッケージ BeautifulSoup4 を利用します。
CSSセレクタ準備編
さっそく、記事に従い政策データダッシュボードページをChromeでページを開き、
その他のツール → デベロッパーツール → Elements
を選ぶことでHTMLを表示します。
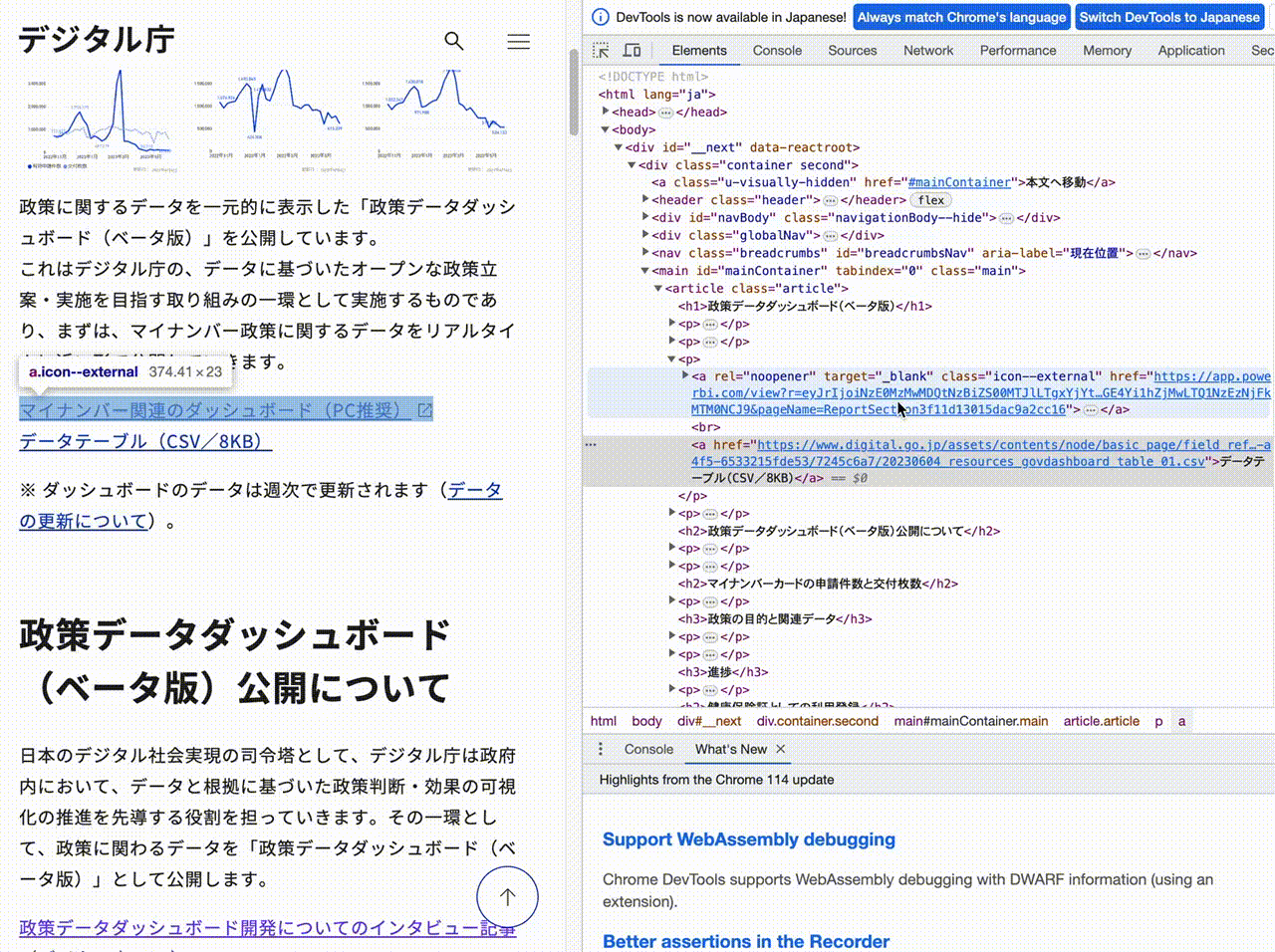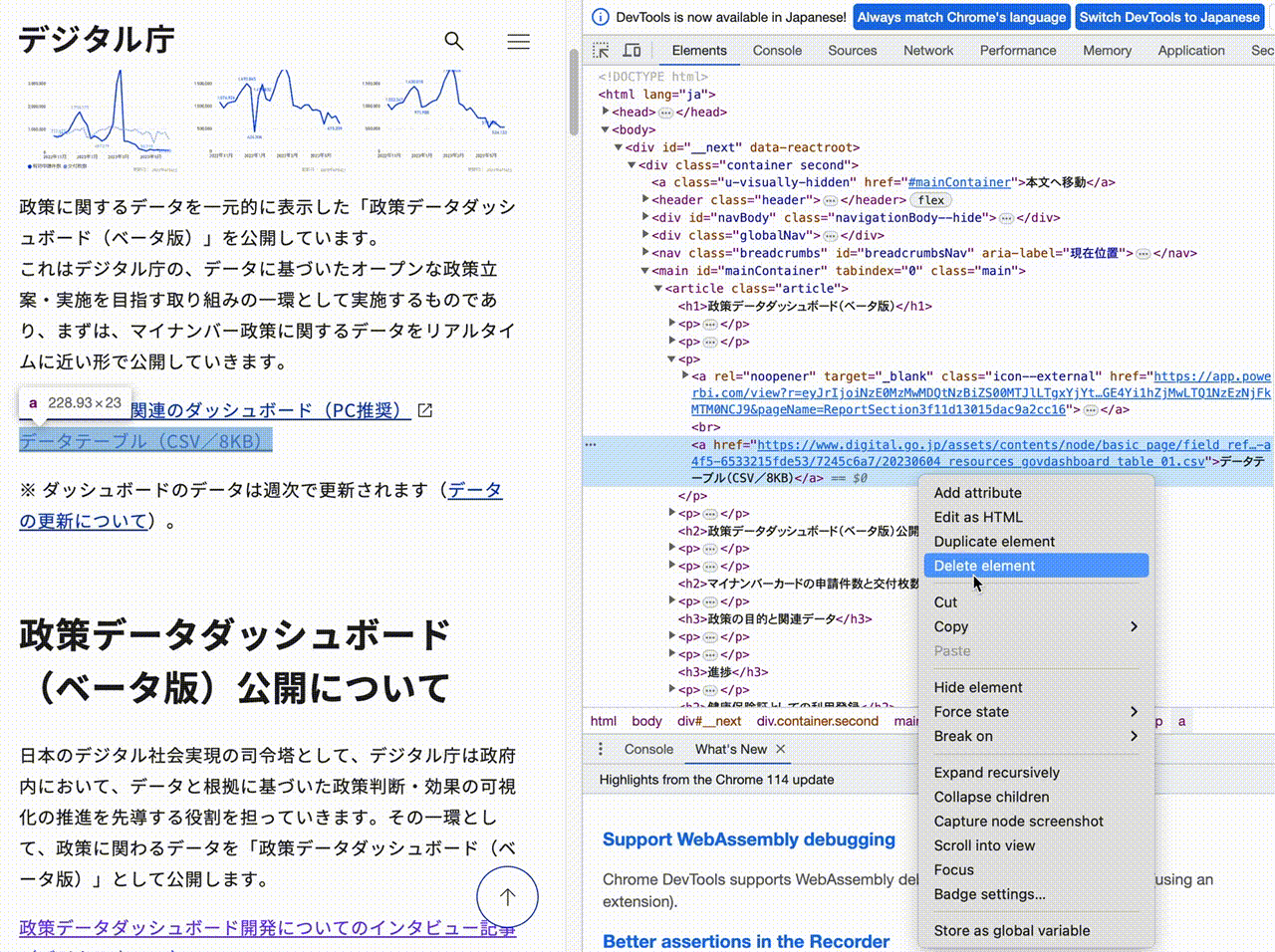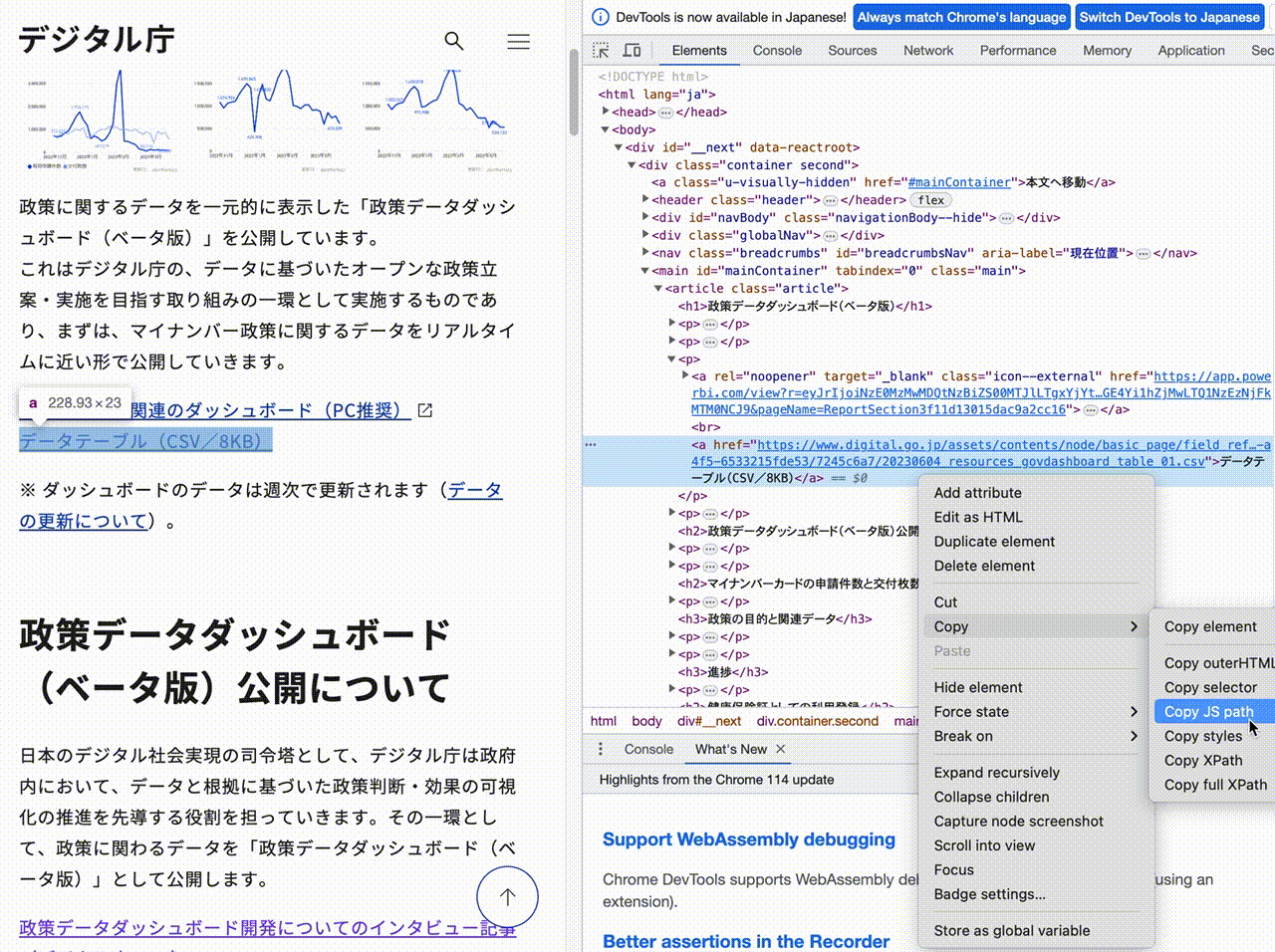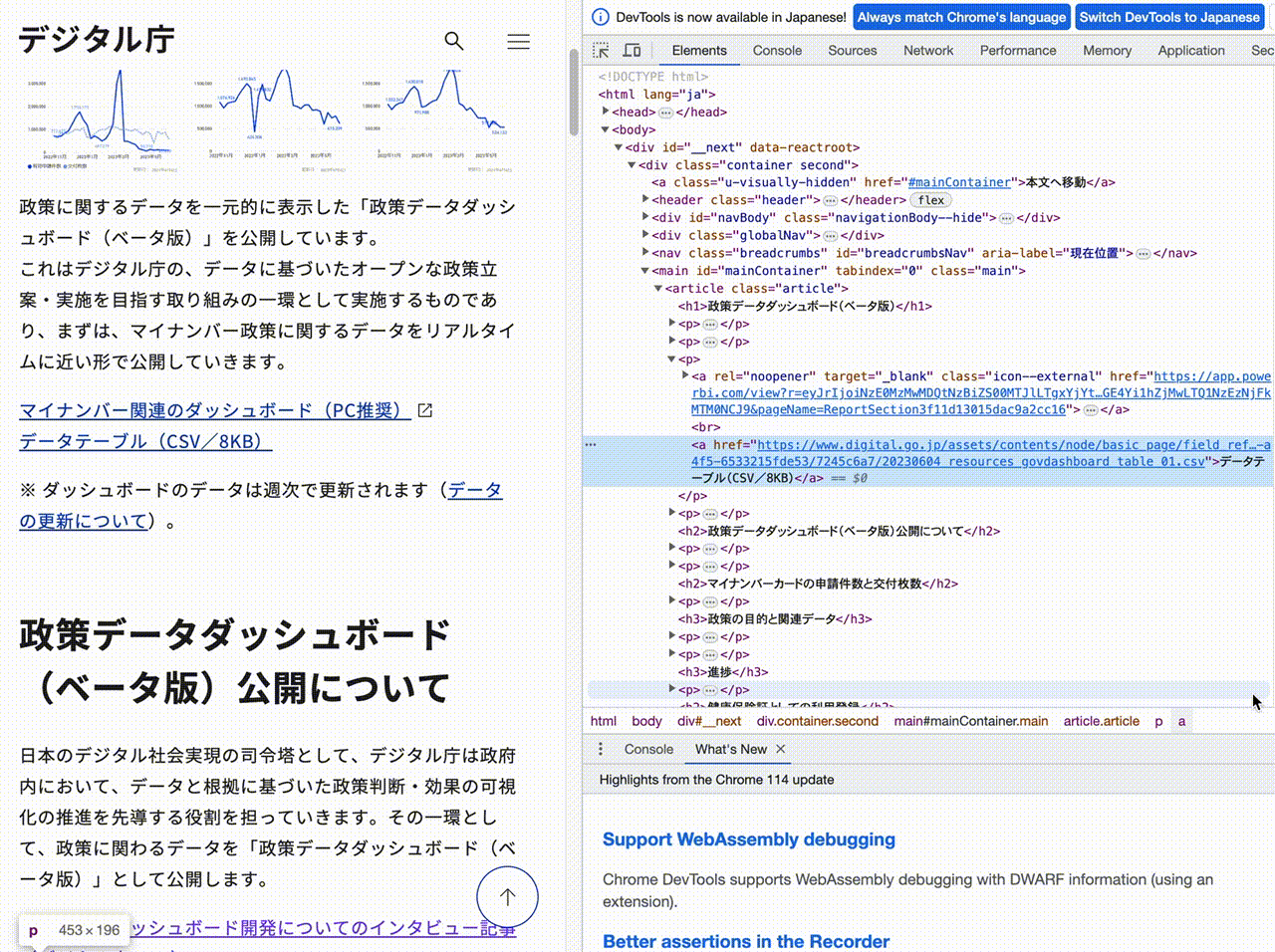
データテーブル に関する部分を右クリックし、
Copy → Copy selector
を選びます。
結果としてこのようなCSSセレクタが取得できます。
#mainContainer > article > p:nth-child(4) > a:nth-child(3)
Webスクレイピング実装編
CSSセレクタが準備できたら BeautifulSoup4 でダウンロードURLを取得してみましょう。
処理手順としては下記です。
- スクレイピングして 政策データダッシュボード のページ内にあるCSVの動的ダウンロードURLを取得する
- 取得したダウンロードURLから取得したCSVファイルをpandasデータフレームに変換する

コードも貼り付けておきます。
import micropip
await micropip.install(["beautifulsoup4"], keep_going=True)
from count_requests import get
from bs4 import BeautifulSoup
request_dashboard = get("https://www.digital.go.jp/resources/govdashboard")
response_dashboard = await request_dashboard.text()
soup = BeautifulSoup(response_dashboard, "html.parser")
item = soup.select(
"#mainContainer > article > p:nth-child(4) > a:nth-child(3)"
).pop()
source_csv_url = item.get("href")
from count_requests import get
from io import StringIO
import pandas as pd
request_csv = get(source_csv_url)
response_csv = await request_csv.text()
pd.read_csv(StringIO(response_csv)).sort_values("集計の週")
ダッシュボード作成編
常に新鮮なデータが手に入るようになったので残りはダッシュボードを作り込むのみです!
詳しい作り込み方は Getting Started Guide から可視化に関するページをご参照ください。
実際に作成してみて、必要な数字の算出はSQLもpandasも両方利用できるのでBIツールに苦手意識があるエンジニアの方でも手軽に使ってもらえるかなと感じました!


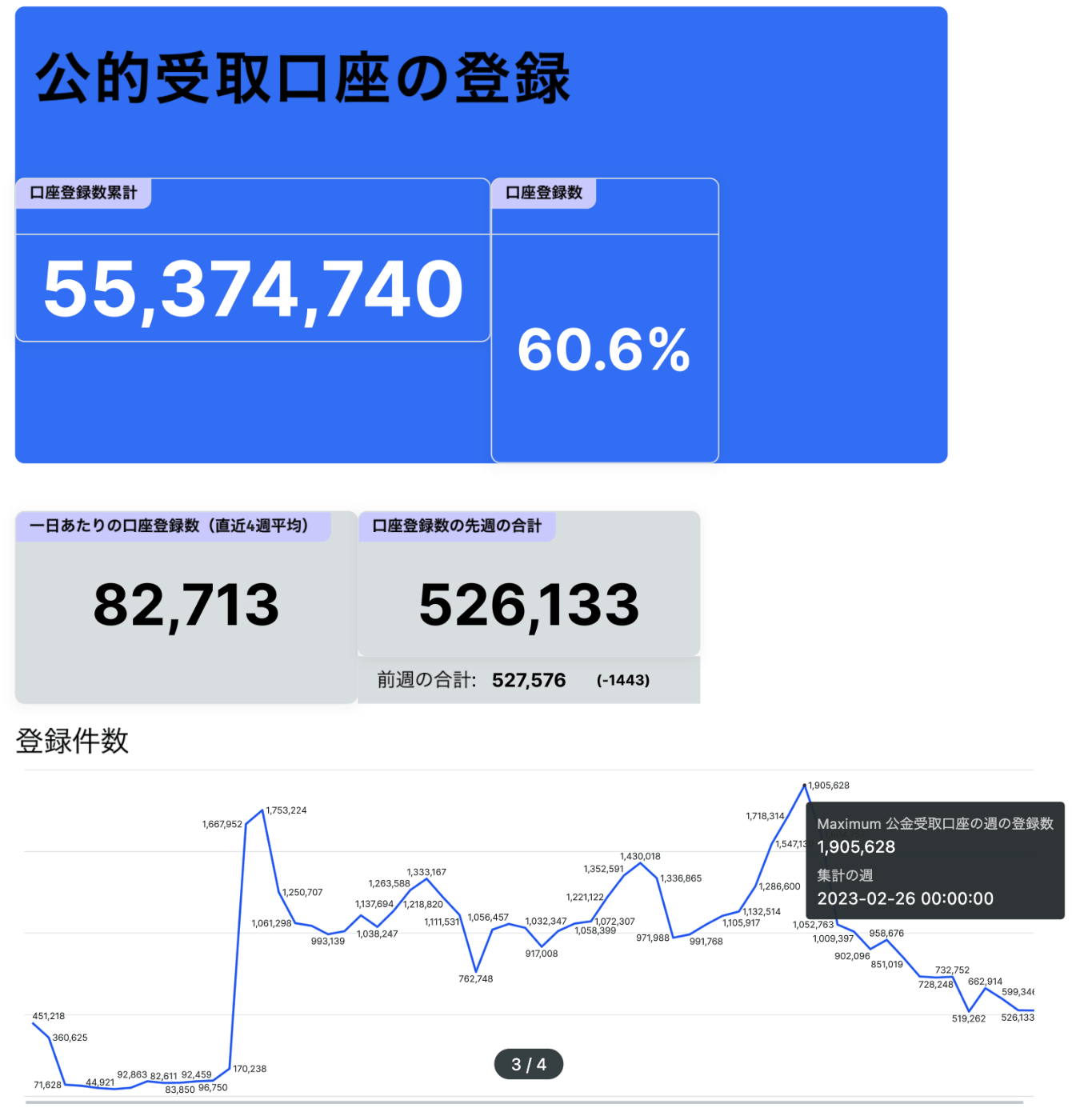
キャンバス公開中
すでに一般公開したデモがあるのでサクッと完成品を見てみたい方はこちらをご覧ください!
所感
感想
CountでWebスクレイピングも可能なことがわかったので、これは応用が色々できそうだなという感想です。
パッと思いついた例としては下記があり、どれも手元で算出することはできますがホスティングまで考えると頭が痛いものは多いかなと思います。
- Webメディアから情報を集計して新たなインサイトを得る
- 災害情報を可視化し気になる点をポストイットで書き込む- 競馬や金融商品、不動産などのデータを可視化し自分なりにサクッと分析する
- Web上の何かしらの在庫状況等をダッシュボード化して生活を快適にする
- ECサイトやレンタル系サービスの状況を見る
- 自分が勤める会社が利用するWebサービスにアクセスして自作の管理画面をデプロイする
また可視化周りで他の方が発見もしてくださってます!
私はまだ試していないですがmatplotlibも利用できるようなので夢が広がりますね!
pie chartがサポートされないので完全には模倣できなかった
得られた知見として、Countはpie chartを未来永劫サポートするつもりがないようです。
No pie charts
Yeah sorry, we don’t do pie charts and probably never will. But we can do all of these.
引用元:https://count.co/use-cases/reporting
そのため政策データダッシュボードを完全には模倣できませんでした。
matplotlibのような他の選択肢で実現する可能性はありますが、実はpie chartを推奨しない意見は以前から存在するため今回はあえて再現することはしませんでした。
調べたところ、pie chartを推奨しないことはメルボルン大学の統計コース関係も言及しています。
また個人的な意見として、学術論文でpie chartは基本的に見かけない印象が強いので資料としてはあまりよろしくないと言って差し支えないかと思いました。
ネットのメディアにもわかりやすく説明されているものが散見されます。

Discussion