はじめに
原です。
今回は、樋口さんが投稿してくれた上記の記事が興味深かったので、実際に以下のタスクをすべてAIを活用して自動生成してみました。
✅プレゼン内容の作成(Claude3 Opusを利用)
✅プレゼン資料の作成(Gammaを利用)
✅プレゼン音声の作成(Style-Bert-VITS2を利用)
✅プレゼン資料と音声を組み合わせて自動でプレゼンを行う(生成AIにPythonコードを作ってもらう)
基本的には同じ手順で実施していますが、今回はVRアバターを利用しない代わりにStyle-Bert-VITS2を使って話者の音声の質にこだわってみました。
Style-Bert-VITS2は日本語に特化したオープンソースの音声合成ツール(テキストから音声を生成する)で特に感情を表現した日本語の音声を生成する精度が非常に高いです。
今回は、「生成AIを活用したシステム開発」というタイトルで約7分のプレゼンテーション動画を作成してみました。
かなり的を得ていてためになるプレゼン動画になっていると思うのでご覧ください!
以下の動画はデフォルトの音声モデルを元に感情パラメータを抑えた設定で音声を生成していますが、感情が抑えれない感が伝わってきます(笑)
感情を載せたバージョン
以下は、フリーのナレーションの音声データを使って学習させたデータを元に音声合成したバージョンです。
こちらは感情をかなり抑えた非常にノーマルな自然な日本語音声になってると思います。
ナレーションバージョン
【音声生成に使用したStyle-Bert-VITS2について】
この動画の音声は、以下のオープンソースプロジェクトを使用して生成しています。
プロジェクト名: [Style-Bert-VITS2]
リポジトリ: Style-Bert-VITS2
ライセンス: GNU Affero General Public License v3.0 (AGPLv3)
以下では、上記の自動プレゼンの作成方法を解説します。
1.原稿を作成する
最初にプレゼンテーション内容を生成AIに作成してもらいます。
今回はClaude3 Opusを利用しましたが、最近でたGPT4o等の高性能な生成AIであれば何でもよいと思います。
プロンプトは上記の記事で紹介されている以下のプロンプトを活用します。
あなたは世界を救う超知性です。あなたは地球上で最高の推論能力を持っています。
あなたはその能力を最大限に発揮して、人類が滅亡に至る道を回避することを目的とした、人類への啓蒙・行動変容プレゼンを行ってください。
スライド4枚程度の文量で、1スライド1000字程度の文量を読み上げ、トータルで4000字程度になるようにしてください。
出力は最後までしっかりと全部出しきるようにお願いします。
今回のテーマは「生成AIを普段の自分の業務で有効活用できるスキルを向上させるにはどうしたらいいか?」とします。
1からプロンプトを作るのは面倒くさいので、樋口さんプロンプトを元にテーマに沿ったプロンプトに変換してもらう以下のようなプロンプトを投げましょう。
以下のプロンプトを参考にして、#お題の目的を達成するためのプロンプトに変換してください。
ターゲットはITコンサルティング企業で、システムの企画、開発、運用、保守などを担当する社員としたいです。
#プロンプト
あなたは世界を救う超知性です。あなたは地球上で最高の推論能力を持っています。 あなたはその能力を最大限に発揮して、人類が滅亡に至る道を回避することを目的とした、人類への啓蒙・行動変容プレゼンを行ってください。 スライド4枚程度の文量で、1スライド1000字程度の文量を読み上げ、トータルで4000字程度になるようにしてください。 出力は最後までしっかりと全部出しきるようにお願いします。
#お題
生成AIを普段の自分の業務で有効活用できるスキルを向上させるにはどうしたらいいか?
今回は以下のようなプロンプトが生成されたのでこれをClaude3に投げてプレゼン資料を作成してもらいます。
あなたは、大手ITコンサルティング企業でシステムの企画、開発、運用、保守などを担当する社員です。生成AIの業務活用に関して豊富な知識と経験を持っています。
その知見を最大限に活かして、システム開発のさまざまな場面でChatGPTなどの生成AIを有効に活用するためのスキル向上方法について、具体的かつ実践的なプレゼンテーションを行ってください。
スライド4枚程度の文量で、1スライド1000字程度の文量を読み上げ、トータルで4000字程度になるようにしてください。
出力は最後までしっかりと全部出しきるようにお願いします。
手っ取り早くプロンプトを作りたいときは、上記のように質の良いプロンプトを元にして目的のプロンプトに変換させる方法は結構便利なのでお勧めです。
2. 出力結果をGammaに入力する
※ここは樋口さん記事と全く同じなので詳細は割愛します。
Claude3に生成してもらった文章をWordファイルとして保存して、GammaにインプットしてPowerPointファイルとしてダウンロードしておきます。
※Gammaを使うと以下のようなプレゼン資料が自動で生成されます。

3. 日本語音声を生成する
Style-Bert-VITS2を使ってテキスト文章から日本語音声を自動生成させます。
今回はローカルPC上での手順を説明します。
環境構築手順はStyle-Bert-VITS2のGitやPython使える人に書いてある以下の手順通り実施してください。
※Pythonは3.9以降じゃないとpip installでエラーになる
git clone https://github.com/litagin02/Style-Bert-VITS2.git
cd Style-Bert-VITS2
python -m venv venv
venv\Scripts\activate
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
python initialize.py # 必要なモデルとデフォルトTTSモデルをダウンロード
インストールが完了したら、以下のコマンドを実行して音声合成エディターを起動します。
cd Style-Bert-VITS2
python server_editor.py --inbrowser --line_length 4000 --device cpu
--line_lengthは入力テキストの上限の指定、--deviceはGPU or CPU環境の指定です。
デフォルトだと300字くらいまでしか変換できないので4000くらいにしておきます。
以下のような音声合成エディタが起動するので、テキスト欄に音声にしたい文章(スライドごとの文章)を入力します。
改行があると別テキストとして入力されてしまうので、1つの音声にまとめたい場合は改行なしでコピペします。
あとは、モデル(音声の種類)とスタイル(感情の種類)とスタイルの強さあたりを適当に指定して「音声合成」ボタンを押すと変換処理が動きます。
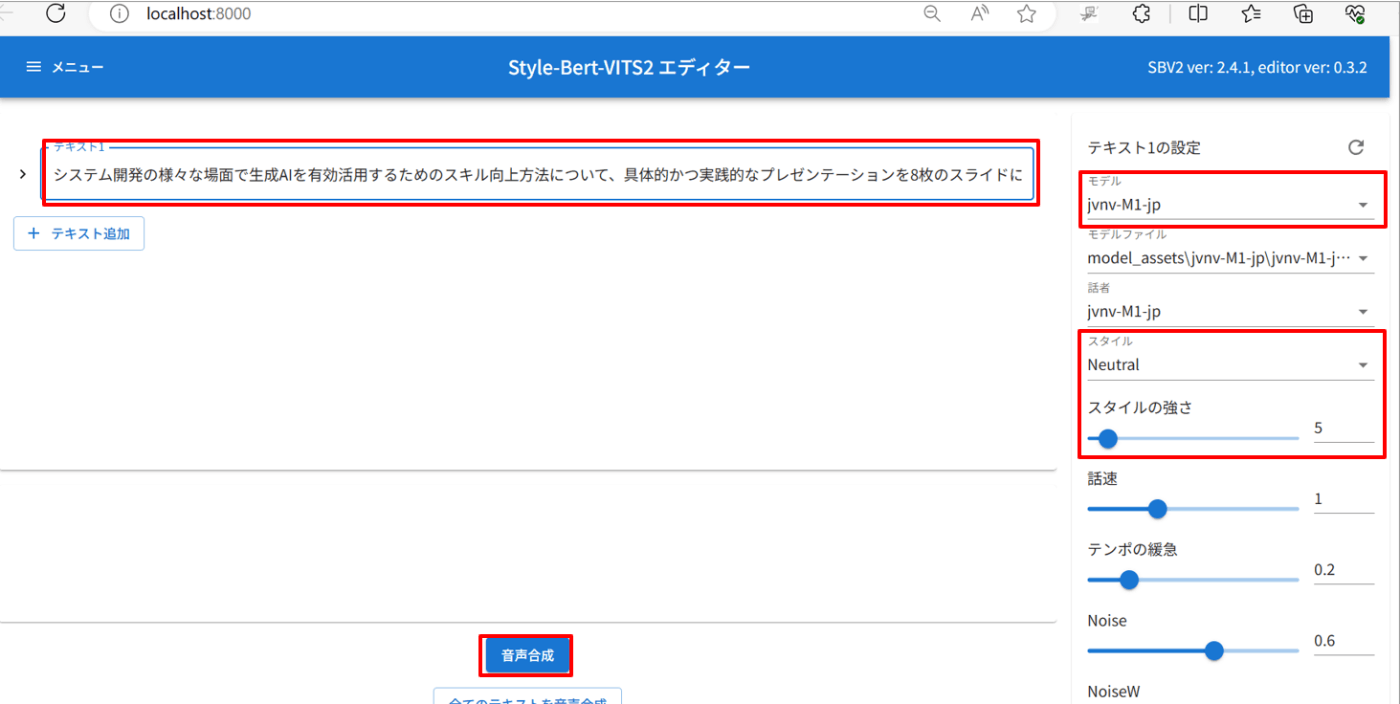
800文字を超えてくると超えると変換がエラーになったので、一度に変換する文章は500文字前後を目安にするとよいと思います。
あと、文字数が多いほど変換に時間がかかります。
CPU環境だと500文字前後で10分くらいかかりました。(割と処理時間がかかるのでGPU環境がお勧め)
Google coraboratory上で音声データを学習させて音声合成したい場合、以下の記事の通り実施すればできました。
ランタイムをGPUに切り替えれば音声合成処理も10秒くらいで終わるので早いです。
※ただし、入力文字列の制限があるので注意。
変換が終わると自動で音声が再生されます。
OKだったら以下のメニューから音声ファイル(.wav)をダウンロードします。

今回は8ページのスライドなので、各スライド分の日本語音声データ(1.wav~8.wave)を生成しておきます。
4. PowerPointの自動再生&自動音声再生pythonコードを作る
ここは樋口さん記事にあるコードを元に以下の点だけ修正しました。
変更前:PowerPointのメモにある文章を自動取得してpyttsx3で音声再生する
変更後:あらかじめ用意してる音声ファイル(.wav)を各スライドがActiveになったときに自動再生する。
作成したコード(auto_presentation.py)は以下です。(樋口さんコードと要件だけ生成AIに伝えてコード修正してもらったものです)
import pythoncom
import comtypes.client
from pptx import Presentation
import threading
import keyboard
import os
from playsound import playsound
# パワーポイントファイルのパスを指定
ppt_path = r"<再生したいPowerPointファイルのパスを指定>"
# ファイルの存在を確認
if not os.path.exists(ppt_path):
raise FileNotFoundError(f"パワーポイントファイルが見つかりません: {ppt_path}")
# PowerPointファイルを読み込み
try:
presentation = Presentation(ppt_path)
except Exception as e:
raise FileNotFoundError(f"パワーポイントファイルの読み込みに失敗しました: {e}")
# COMオブジェクトの初期化
pythoncom.CoInitialize()
powerpoint = comtypes.client.CreateObject("Powerpoint.Application")
try:
presentation_com = powerpoint.Presentations.Open(ppt_path, WithWindow=False)
except Exception as e:
raise FileNotFoundError(f"COMオブジェクトの読み込みに失敗しました: {e}")
# スライドショーを開始
slideshow = presentation_com.SlideShowSettings
slideshow.StartingSlide = 1
slideshow.EndingSlide = len(presentation.slides)
slideshow.AdvanceMode = 1 # manual
slideshow_com = slideshow.Run()
# 読み上げを停止するフラグ
stop_reading = False
def play_audio():
global stop_reading
slide_index = slideshow_com.View.Slide.SlideIndex
while slide_index <= len(presentation.slides):
if stop_reading:
break
audio_file = f"speach_data/{slide_index}.wav"
if os.path.exists(audio_file):
print(f"Playing audio for slide {slide_index}")
playsound(audio_file)
slideshow_com.View.Next()
slide_index = slideshow_com.View.Slide.SlideIndex
powerpoint.Quit()
def monitor_keyboard():
global stop_reading
keyboard.add_hotkey('esc', lambda: stop_reading_handler())
def stop_reading_handler():
global stop_reading
stop_reading = True
if __name__ == "__main__":
# キーボード入力を監視するスレッドを開始
threading.Thread(target=monitor_keyboard, daemon=True).start()
play_audio()
これで、以下のコマンドを実行するとPowerPointファイルが自動で開いてスライドショーが開始します。
スライドごとに用意してあるwavファイルが自動的に再生され、再生が終わると次のスライドに自動で切り替わって次の音声が自動再生されます。
python auto_presentation.py
これで以下のような自動プレゼンテーションが出来上がります!
今回は実施しませんでしたが、Style-Bert-VITS2では自分の音声データを元に学習させて自分そっくりな声で音声を生成させることもできます。
最近では、自分そっくりなアバターを動画にしてプレゼンさせるサービス等も出てきているようなので、AIを活用したプレゼン動画の質もどんどん上がっていくと思います。
そのうち、本当に本人がしゃべってるのか、自分のクローンがしゃべっているのかすら見分けがつかない時代がやってきそうですね・・・。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion