はじめに
Claude 3.5 Sonnetで領収書読めちゃう記事がいくつかあったので、見て行こうと思います。
ただ見ていくのも面白くないので、今回はGoogle Clolabを使ってAPI経由でClaude 3.5 Sonnetへ画像連携して解析してもらいます。
アーキテクチャ
こんなかんじでいきます。
Colab便利ですよねぇ。
気軽にPythonを実行できちゃう。

プロンプト
きちんと領収書としてClaude 3.5 Sonnetに認識してもらって画像解析してほしいので、こんなプロンプトを作ってみました。
あなたは優秀な経理担当者です。受け取った領収書を画像解析して文字や金額を起こしてください。
## 重要事項
- わからない項目がある場合は、正直に「N/A」と記入してください。
- 1枚の画像に複数の領収書が含まれている場合は、それぞれの領収書ごとに別々のCSVを作成してください。
- 各値はダブルクォーテーションで囲ってください
- 回答はCSVのみで出力してください。
- 標準的でない形式や追加情報がある場合は、各行の注記として記載してください。
## 項目の説明
主に以下の情報が含まれます。
- 支払先会社名
- 発行日
- 支払金額税込
- 通貨
- 登録番号
## 出力形式
以下の項目を含む表形式で出力してください。各項目は「項目名: 値」の形式で記入してください。
## 出力項目(優先順位順)
1. ファイル名
2. 支払先会社名
3. 発行日
4. 支払金額税込
5. 通貨
6. 登録番号
7. 注記
## 通常項目の出力項目の説明
1. ファイル名: 解析した画像のファイル名。(例:test.png)
2. 支払先会社名: 支払先の会社名。宛名や請求先ではないので注意してください。
3. 発行日: 領収書を発行した日付(YYYY/MM/DD形式で出力)
4. 支払金額税込: 税込みの合計金額(カンマ区切りで記入、小数点以下2桁まで)
- 税抜き金額のみ記載の場合は、課税対象額を加算して計算してください
5. 通貨: 支払金額の通貨(例:JPY、USD、EUR)
6. 登録番号:税務署に認められた適格請求書発行事業者に発行される番号です。 すでに法人番号がある事業者の場合は「T+法人番号」が登録番号となります。 法人番号を持っていない事業者に関しては、「T+13桁の固有番号」が登録番号です。 (T0000000000000形式で出力)
7. 注記
## 項目の出力例
"ファイル名","支払先会社名","発行日","支払金額税込","通貨","登録番号","注記"
"invoice_001.pdf","株式会社テスト","2024-07-15","150000","JPY","T1234567890123","初回取引"
Pythonのコード
見ていきましょう。
anthropicライブラリをインストール
デフォルトのColabだとimportできないのでインストールしましょう。20秒弱でできます。
!pip install anthropic
使用するライブラリをimportする
詳しくない方はお作法的ということでimportしましょう。
import anthropic
import base64
from google.colab import drive
from google.colab import auth
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseDownload, MediaFileUpload
from googleapiclient.http import MediaIoBaseUpload
import io
import os
APIキーの設定
こちらは、Anthropic社のClaudeのAPIサイトでAPIキーを発行して「xxx」に入力しましょう。
client = anthropic.Anthropic(
api_key="xxx",
)
Google Driveをマウント
Google Drive上に領収書画像を格納したり、画像解析結果を格納するのでマウントしましょう。
これをしないと、ColabからGoogle Driveにアクセスができません。
# Google Driveをマウント
drive.mount('/content/drive')
# Google Driveの認証
auth.authenticate_user()
# Drive APIを初期化
drive_service = build('drive', 'v3')
functionを定義①
function定義します。主にファイル操作系。
def get_folder_id(folder_path):
"""指定されたパスのフォルダIDを取得する"""
folder_name = os.path.basename(folder_path)
results = drive_service.files().list(
q=f"mimeType='application/vnd.google-apps.folder' and name='{folder_name}'",
fields="files(id)"
).execute()
items = results.get('files', [])
if not items:
raise FileNotFoundError(f"Folder '{folder_name}' not found in Google Drive")
return items[0]['id']
def list_files_in_folder(folder_id):
"""フォルダ内のファイル一覧を取得する"""
results = drive_service.files().list(
q=f"'{folder_id}' in parents and mimeType contains 'image/'",
fields="files(id, name)"
).execute()
return results.get('files', [])
def download_file(file_id):
"""
指定されたファイルIDのファイルをダウンロードする
"""
request = drive_service.files().get_media(fileId=file_id)
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
return fh.getvalue()
def upload_file(file_name, file_content, mime_type, parent_folder_id):
"""ファイルを指定されたフォルダにアップロードする"""
file_metadata = {
'name': file_name,
'parents': [parent_folder_id]
}
if isinstance(file_content, str):
file_content = io.BytesIO(file_content.encode())
elif not isinstance(file_content, io.BytesIO):
raise ValueError("file_content must be either str or BytesIO object")
media = MediaIoBaseUpload(file_content, mimetype=mime_type, resumable=True)
file = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return file.get('id')
functionを定義②
function定義します。主にClaudeとのAPI通信。
def analyze_image_with_claude(image_data, file_name):
image_base64 = base64.b64encode(image_data).decode('utf-8')
prompt = f"""あなたは優秀な経理担当者です。受け取った領収書を画像解析して文字や金額を起こしてください。
## 重要事項
- わからない項目がある場合は、正直に「N/A」と記入してください。
- 1枚の画像に複数の領収書が含まれている場合は、それぞれの領収書ごとに別々のCSVを作成してください。
- 各値はダブルクォーテーションで囲ってください
- 回答はCSVのみで出力してください。
- 標準的でない形式や追加情報がある場合は、各行の注記として記載してください。
## 項目の説明
主に以下の情報が含まれます。
- 支払先会社名
- 発行日
- 支払金額税込
- 通貨
- 登録番号
## 出力形式
以下の項目を含む表形式で出力してください。各項目は「項目名: 値」の形式で記入してください。
## 出力項目(優先順位順)
1. ファイル名
2. 支払先会社名
3. 発行日
4. 支払金額税込
5. 通貨
6. 登録番号
7. 注記
## 通常項目の出力項目の説明
1. ファイル名: 解析した画像のファイル名。(例:test.png)
2. 支払先会社名: 支払先の会社名。宛名や請求先ではないので注意してください。
3. 発行日: 領収書を発行した日付(YYYY/MM/DD形式で出力)
4. 支払金額税込: 税込みの合計金額(カンマ区切りで記入、小数点以下2桁まで)
- 税抜き金額のみ記載の場合は、課税対象額を加算して計算してください
5. 通貨: 支払金額の通貨(例:円、USD、EUR)
6. 登録番号:税務署に認められた適格請求書発行事業者に発行される番号です。 すでに法人番号がある事業者の場合は「T+法人番号」が登録番号となります。 法人番号を持っていない事業者に関しては、「T+13桁の固有番号」が登録番号です。 (T0000000000000形式で出力)
7. 注記
## 項目の出力例
"ファイル名","支払先会社名","発行日","支払金額税込","通貨","登録番号","注記"
"invoice_001.pdf","株式会社テスト","2024-07-15","150000","JPY","T1234567890123","初回取引"
解析する画像のファイル名: {file_name}
"""
message = client.messages.create(
model="claude-3-5-sonnet-20240620",
max_tokens=4096,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_base64,
},
},
{
"type": "text",
"text": prompt
}
],
}
],
)
return message.content[0].text
メイン処理
今回は複数の領収書画像ファイルをInputする想定なので、for文入れています。
# メイン処理
input_folder_path = '/content/drive/MyDrive/claude_ocr_demo/input'
output_folder_path = '/content/drive/MyDrive/claude_ocr_demo/output'
# 入力フォルダと出力フォルダのIDを取得
input_folder_id = get_folder_id(input_folder_path)
output_folder_id = get_folder_id(output_folder_path)
# フォルダ内のファイル一覧を取得
files = list_files_in_folder(input_folder_id)
for file in files:
print(f"Processing file: {file['name']}")
# ファイルをダウンロード
image_data = download_file(file['id'])
# Claudeで画像を解析
analysis_result = analyze_image_with_claude(image_data, file['name'])
# 結果をGoogle Driveに保存
output_file_name = f"analysis_{file['name']}.txt"
# upload_file(output_file_name, analysis_result, 'text/plain')
uploaded_file_id = upload_file(output_file_name, analysis_result, 'text/plain', output_folder_id)
print(f"Analysis result for {file['name']} has been saved as '{output_file_name}' in your Google Drive.")
print("All files have been processed.")
画像解析結果
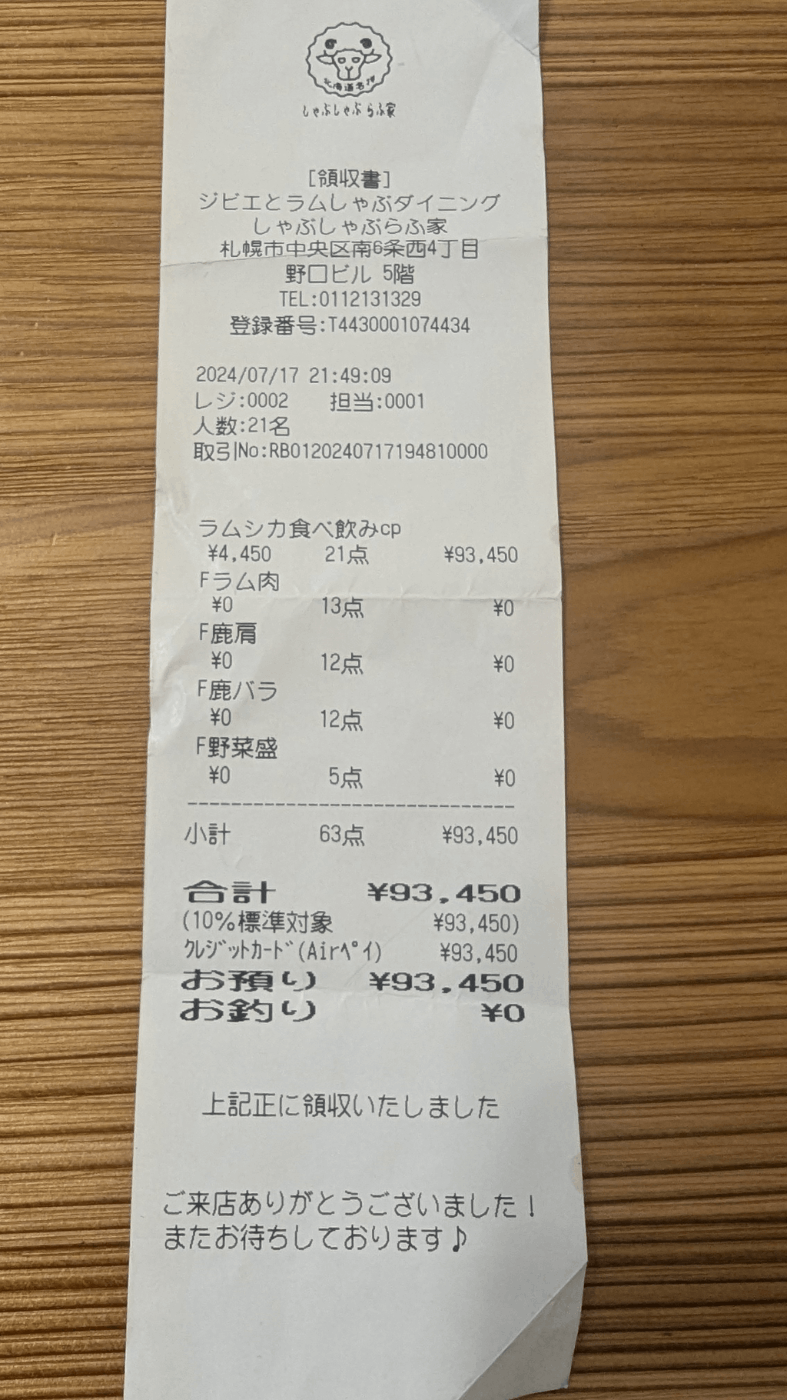
ファイル1
概ね合っていますが、支払先会社名が若干間違っているのと、登録番号がT+14桁になってしまっていますね。。。
Input領収書画像
Output解析結果
| ファイル名 | 支払先会社名 | 発行日 | 支払金額税込 | 通貨 | 登録番号 | 注記 |
|---|---|---|---|---|---|---|
| sample1.png | ジビエとラムしゃぶダイニング しゃぶしゃぶらぶ家 | 2024/07/17 | 93,450 | JPY | T44300010744434 | 人数: 21名, クレジットカード(AirPay)での支払い |
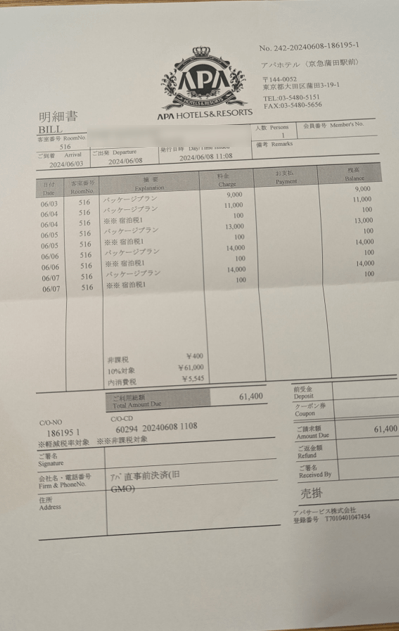
ファイル2
妙に斜めの画像になってしまいました。登録番号が間違っていますね。。。
Input領収書画像
Output解析結果
| ファイル名 | 支払先会社名 | 発行日 | 支払金額税込 | 通貨 | 登録番号 | 注記 |
|---|---|---|---|---|---|---|
| sample2.png | APA HOTELS & RESORTS | 2024/06/08 | 61,400 | JPY | T1440032 | パッケージプランの宿泊料金が含まれています。詳細な内訳は画像に記載されています。 |
ファイル3
これはいい感じに解析できましたね!
Input領収書画像

Output解析結果
| ファイル名 | 支払先会社名 | 発行日 | 支払金額税込 | 通貨 | 登録番号 | 注記 |
|---|---|---|---|---|---|---|
| sample3.png | 東京空港交通株式会社 | 2024/06/23 | 3,600 | JPY | T8010001061264 | 羽田空港から成田空港への片道乗車券、大人1人分 |
さいごに
いかがでしたか。
今回はClaude 3.5 SonnetとGoogle Colabを使って領収書画像の画像解析を試しました。
100%の精度ではないもののまずまずだったのかなと思います。
画像が斜めになったりするとさすがに精度落ちるなといった印象です。まぁ、これはどのOCR製品も同じかなとは思います。(自動的に画像を回転させるOCR製品もあるようです。)
また、「注記」を見ると内容把握力はかなり高そうですね。
みなさんの、なんらかの参考になれば幸いです!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion