はじめに
前回の中編では、Apache Beamを使ってバッチ処理でデータの重複排除を実装しました。今回の後編では、ストリーミング処理に挑戦します。
Pub/Sub → Dataflow → BigQueryの流れで、リアルタイムデータ処理とウィンドウ集計を実装していきます。
実装内容
フェイクデータを生成してPub/Subに送信し、Dataflowで受け取って以下の2つの処理を行います:
- 生データの保存:受信したデータをそのままBigQueryに保存
- ウィンドウ集計:60秒ごとに言語別の統計を集計して別テーブルに保存
ストリーミング処理の重要概念
ウィンドウ処理
ストリーミングデータは終わりのない無限のデータストリームです。そのため、「いつまでのデータを集計するか」を定義する必要があります。
余談ですが、Datastreamを常時稼働にさせていたせいで、3000円ほど知らないうちに課金されていたので要注意です。検証が終わったら止めたほうがいいですね。(この手の検証を続けているからには、いつか課金の罠に引っかかるだろうと思っていましたが、、)
ストリーミングはお金がかかるということがよくわかりました。
windowed = records | beam.WindowInto(FixedWindows(60)) # 60秒ごと
バッチ処理は「全データ」が前提ですが、ストリーミングは「時間軸で区切る」ことで集計タイミングを決定します。
GroupByKey
by_language = (
windowed
| beam.Map(lambda r: (r.get('language'), r)) # (key, value)のペアに
| beam.GroupByKey() # keyごとにまとめる
)
重要:GroupByKeyはウィンドウ内のデータのみをグループ化します(この場合60秒分)。
FILE_LOADS vs STREAMING_INSERTS
BigQueryへの書き込み方法には2つあります:
| 方式 | レイテンシ | コスト | レート制限 |
|---|---|---|---|
| STREAMING_INSERTS | 数秒 | 高い | かかりやすい |
| FILE_LOADS | 分単位 | 安い | かかりにくい |
今回はリソース問題も頻発したので、FILE_LOADSを採用しました。
ストリーミングデータの準備
ストリーミング処理を検証するために、フェイクデータを生成してPub/Subに送信するスクリプトを用意しました。
# scripts/publish_fake_data.py(抜粋)
from google.cloud import pubsub_v1
import json
import time
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(PROJECT_ID, TOPIC_NAME)
# フェイクデータを生成
fake_data = {
'article_id': f'fake_{uuid.uuid4()}',
'source': 'github_trending',
'title': 'Sample Repository',
'language': random.choice(['Python', 'JavaScript', 'Go', 'Rust']),
'stars': random.randint(100, 10000),
'today_stars': random.randint(10, 500),
'collected_at': datetime.now().isoformat(),
# ...
}
# Pub/Subに送信
message = json.dumps(fake_data).encode('utf-8')
publisher.publish(topic_path, message)
このスクリプトを定期的に実行することで、継続的なストリームデータを模擬できます。今回は100件のフェイクデータを送信して検証しました。
Dataflow のストリーミングでは、本来は以下の2種類を意識する必要があります。
- Event Time(データが発生した時刻)
- Processing Time(パイプラインが処理した時刻)
今回はフェイクデータのため両者はほぼ一致しますが、実サービスでは Event Time が遅延するケースが多く、Watermark や Allowed Lateness を設定する必要があります。
結果について:生データテーブルには91件のレコードが正常に保存されましたが、集計テーブルにはデータが入りませんでした。パイプラインは2日間動作していたため、タイミングの問題ではなく、集計処理のどこかでエラーが発生していた可能性があります。原因の特定には至りませんでしたが、本番運用ではエラーハンドリングとモニタリングの重要性を痛感しました。
パイプラインの骨格
ストリーミングパイプラインの基本構造は以下の通りです:
with beam.Pipeline(options=pipeline_options) as p:
# 1. Pub/Subから読み込み
messages = p | beam.io.ReadFromPubSub(subscription=subscription)
# 2. パース → 処理時刻付与
records = messages | beam.ParDo(ParsePubSubMessage())
records_with_time = records | beam.ParDo(AddProcessingTime())
# 3-A. 生データを保存
records_with_time | WriteToBigQuery(...)
# 3-B. ウィンドウ集計
windowed = records | beam.WindowInto(FixedWindows(60)) # 60秒ウィンドウ
by_language = windowed | beam.Map(...) | beam.GroupByKey()
aggregated = by_language | beam.ParDo(CountByLanguage())
aggregated | WriteToBigQuery(...)
コンソールで見るとこのようになります。複雑ですね。

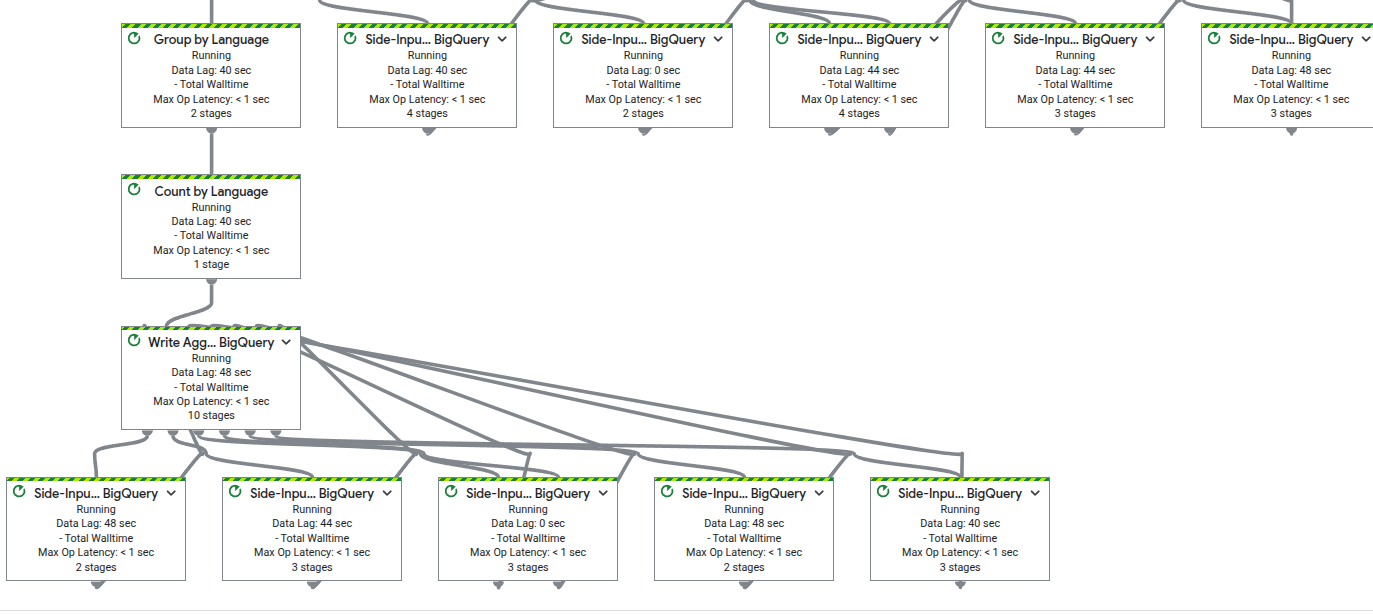
ポイントは1つの入力ストリームから2つの処理パスに分岐していることです。
同じデータ(records)を2つの異なる処理に使っています:
パスA: records_with_time → BigQueryにそのまま書き込み
パスB: records → ウィンドウ処理 → 集計 → BigQueryに書き込み
Pub/Subから1回読み込んだデータが、2つの出力先に流れていきます。
例えば「生データは全部保存したいけど、リアルタイムで集計も見たい」といった要件に対応できます。
パスAで書き込まれたデータはこちら。

パスBはスキーマが異なるテーブルを用意。ただし上述の通り今回はデータ登録は失敗しました。

ハマったポイント1:BigQueryのレート制限
エラー内容
HttpForbiddenError: Exceeded rate limits:
too many table update operations for this table.
複数のワーカーが同時にテーブル作成・更新を試み、BigQueryのレート制限に引っかかりました。
解決策
1. テーブルを事前作成
BigQueryコンソールで事前にテーブルを作成しておきます。
2. CREATE_NEVERを使用
create_disposition=BigQueryDisposition.CREATE_NEVER
3. FILE_LOADSを使用
method='FILE_LOADS',
triggering_frequency=60
4. ゾーンをus-centralに切り替えて使用
バッチ処理よりさらにリソースが厳しく、大阪はもとより、東京リージョンでも耐えられず。
最もリソースが豊富なUSゾーンに切り替えました。
--region us-central1
GCPの中心はUSに・・
ハマったポイント2:triggering_frequencyが必須
ストリーミングパイプラインでFILE_LOADSを使う場合、以下のエラーが発生します:
ValueError: triggering_frequency must be specified
to use fileloads in streaming
解決策
triggering_frequencyパラメータを追加:
WriteToBigQuery(
table,
method='FILE_LOADS',
triggering_frequency=120 # ← これが必須
)
この値は用途に応じて調整します:
- 小さい値(30秒):リアルタイム性重視、ロード頻度が多い
- 大きい値(300秒):コスト重視、遅延が大きい
Dataflowの実行グラフについて
実行時のグラフビューを見ると、「Side-Input... BigQuery」というステップが複数表示されます。
これはBeamがWriteToBigQuery内部で自動的に使用しているSide Inputです。BigQueryのメタデータ(テーブルスキーマ、設定など)をメインデータストリームとは別に参照するために使われています。
明示的にSide Inputのコードを書いていなくても、Beamが裏側で複雑な処理を行っていることが分かります。
まとめ
ストリーミング処理で学んだこと
- ウィンドウ処理の必要性:無限ストリームを時間軸で区切る
- GroupByKeyの挙動:ウィンドウ内でのグループ化
- FILE_LOADSの選択:レート制限とコストの観点
- triggering_frequencyの役割:リアルタイム性とコストのトレードオフ
中編・後編を通しての気づき
バッチ処理(中編)では:
- リソース制限との戦い
ストリーミング処理(後編)では:
- ウィンドウによる時間軸の区切り
- triggering_frequencyの必須性
- リソース制限とのさらなる戦い
認定試験では学べない「実際に動かすと出てくる問題」をたくさん経験できました。
全3回を振り返って
- 前編:Cloud Functionsでのスクレイピングとバッチ処理
- 中編:Apache Beamでのバッチ重複排除
- 後編:Dataflowでのストリーミング処理とウィンドウ集計
全3回を通じて、GCPのデータパイプラインの基礎から実践的な問題解決まで、一通り体験することができました。認定試験に合格しても、実際に手を動かさないと分からないことが本当に多いと実感しています。
この経験が、同じようにGCPでデータエンジニアリングを学習している方の参考になれば幸いです!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion