マルチモーダルAIエージェント開発を加速する「Agno」
1.Agnoとは?
AgnoはマルチモーダルAIエージェント構築を手軽に実現する軽量ライブラリです。テキスト・画像・音声・動画を自在に扱える高性能なAIエージェントを、シンプルなコードで作成できます。
Agnoの主な特徴
Agnoはシンプル・高速・モデル非依存を追求しています。主な特徴は以下の通りです:
| 特徴 | 説明 |
|---|---|
| ⚡ 圧倒的な高速性 | エージェントの作成速度はLangGraphより最大10,000倍高速(ベンチマーク参照) |
| 🔄 モデル非依存 | 特定モデルやプロバイダーに縛られず、自由に選択可能 |
| 🌈 マルチモーダル対応 | テキスト、画像、音声、動画を標準機能でサポート |
| 👥 マルチエージェント | 専門分野ごとのエージェントを組み合わせてチームを構築可能 |
| 💾 メモリ管理 | エージェントの状態や会話履歴をデータベースに簡単保存 |
| 📚 ナレッジストア | RAGや動的Few-shotに使えるベクトルDBを標準搭載 |
| 📊 構造化出力 | エージェントからのレスポンスを構造化データ形式で受け取り可能 |
| 📈 リアルタイムモニタリング | エージェントの動作状況や性能をリアルタイムで追跡・可視化 |
目的に合わせた4つのエージェントレベルがある
Agnoなら目的に応じて、簡単な推論エージェントから複雑なチームまで作成可能:
- レベル0:基本推論のみ
- レベル1:外部ツールでタスク実行
- レベル2:知識ベースとメモリを統合
- レベル3:複数エージェントのチーム運用
AIエンジニアリングは、ソフトウェアエンジニアリングである
AI製品の開発においては、80%が通常のPythonコードで解決可能であり、残りの20%にAIエージェントを活用することで効率化を図ります。Agnoはこのような用途に最適化されています。
Agnoは馴染み深いif、else、while、forなどの標準的なプログラミング構文を使い、シンプルかつ明確にAIロジックを記述できます。複雑な抽象化を避け、誰にでもわかりやすいコードを実現しています。
シンプルなコードでエージェントを定義
例えば、WEB検索を行うAIエージェントは以下の5行コードで実装できます:
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.tools.duckduckgo import DuckDuckGoTools
agent = Agent(model=OpenAIChat(id="gpt-4o"),tools=[DuckDuckGoTools()],markdown=True)
agent.print_response("ニューヨークで何が起きている?", stream=True)
2.Agnoでエージェントを作成してみましょう
仮想環境の作成と、必要なモジュールをインストールします。
python -m venv .venv
.venv\Scripts\activate
pip install -U openai agno
以下は最もシンプルなエージェントの例です:
※api_keyにOpenAIのAPIキーを設定しておく。
from agno.agent import Agent
from agno.models.openai import OpenAIChat
api_key = "sk-xxxx"
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini", api_key=api_key),
description="あなたは最先端の技術トレンドに精通したITコンサルタントです!",
markdown=True
)
agent.print_response("最新のクラウドコンピューティングの動向を分析してください。", stream=True)
回答例

WEB検索が可能なエージェント
標準ツールを組み込むとエージェントの能力を拡張することができます。
以下は、WEB検索ツール(DuckDuckGoTools)を組み込んだエージェント例です。
必要なモジュールをインストールします。
pip install duckduckgo-search
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.tools.duckduckgo import DuckDuckGoTools
api_key = "sk-xxxxxxxx"
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini", api_key=api_key),
description="あなたは最新の技術トレンドと市場分析に精通したITコンサルタントです。",
tools=[DuckDuckGoTools()], # ウェブ検索ツールを追加
show_tool_calls=True,
markdown=True
)
agent.print_response("企業向けの最新のAIエージェントのトレンドを教えてください。", stream=True)
回答例

ナレッジベースを活用したエージェント
PDFなどの文書を知識として与え、RAG機能を構築することもできます。
必要なモジュールをインストールします。
pip install pypdf lancedb numpy tantivy pylance pandas
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.embedder.openai import OpenAIEmbedder
from agno.tools.duckduckgo import DuckDuckGoTools
from agno.knowledge.pdf_url import PDFUrlKnowledgeBase
from agno.vectordb.lancedb import LanceDb, SearchType
api_key="sk-xxxxxx"
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini", api_key=api_key),
description="あなたは事業所台帳管理システムAPIの専門家です!",
instructions=[
"API仕様書の情報を知識ベースで検索してください。",
"質問がウェブに適している場合は、ウェブを検索して情報を補完してください。",
"ウェブ結果よりも知識ベースの情報を優先してください。"
],
knowledge=PDFUrlKnowledgeBase(
urls=["https://www.mhlw.go.jp/content/12300000/001234800.pdf"],
vector_db=LanceDb(
uri="tmp/lancedb",
table_name="api_specifications",
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small",api_key=api_key),
),
),
tools=[DuckDuckGoTools()],
show_tool_calls=True,
markdown=True
)
# 知識ベースがロードされた後にコメントアウト
if agent.knowledge is not None:
agent.knowledge.load()
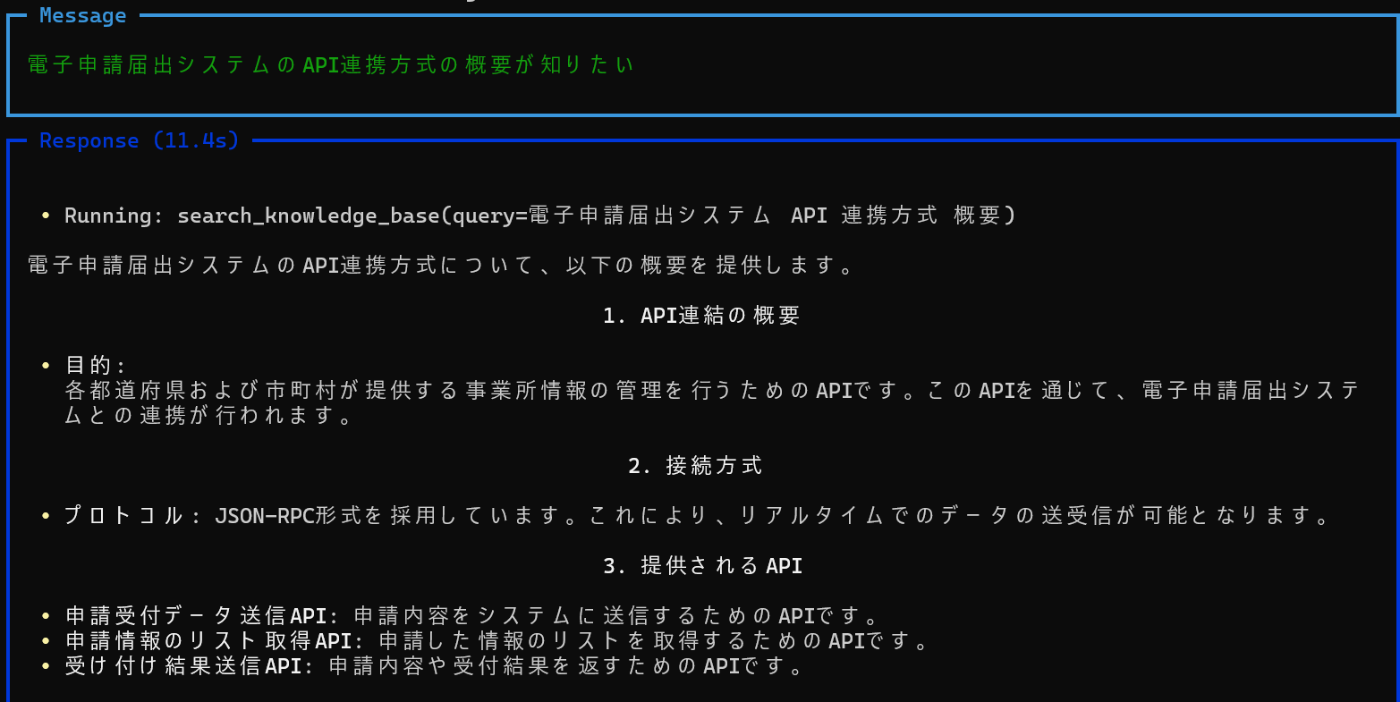
agent.print_response("電子申請届出システムのAPI連携方式の概要が知りたい", stream=True)
回答例
マルチエージェントチームの構築
複数のエージェントを組み合わせたチームを作ることも可能です:
web_agent = Agent(
name="Web Agent",
role="情報のためにウェブを検索する",
model=OpenAIChat(id="gpt-4o-mini", api_key=api_key),
tools=[DuckDuckGoTools()],
)
finance_agent = Agent(
name="Finance Agent",
role="金融データを取得する",
model=OpenAIChat(id="gpt-4o-mini", api_key=api_key),
tools=[YFinanceTools()],
)
agent_team = Agent(
team=[web_agent, finance_agent], # 複数のエージェントをチームとして組織
model=OpenAIChat(id="gpt-4o-mini", api_key=api_key),
markdown=True,
)
様々な出力フォーマット
Agnoでは出力形式を柔軟に制御できます:
- print_response: 装飾された結果を表示
- run()メソッド: 応答を直接プログラムで処理
- ファイル出力: 結果を自動的にファイルに保存
- 構造化出力: Pydanticモデルを使用した型付きレスポンス
- ストリーミング: リアルタイムでレスポンスを取得
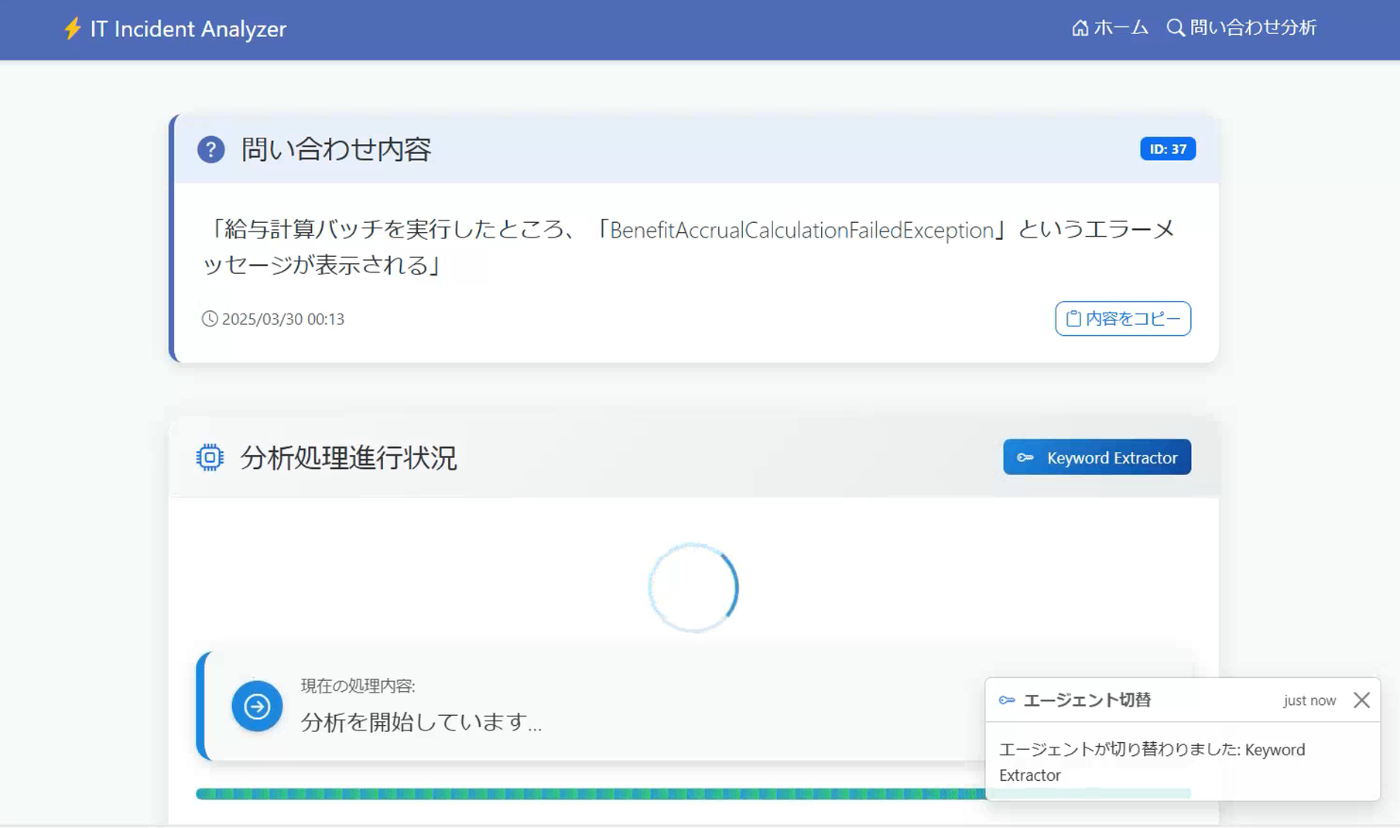
3.試作してみた:ITインシデント解決エージェント
ここからは、試作した「ITインシデント解決エージェント」を簡単に紹介します。
Agnoでどのような感じでマルチエージェントシステムを構築できるかイメージできるように説明はできるだけ簡略化しています。
このマルチエージェントシステムは、ユーザーが入力したシステムの問題やエラー内容を分析し、過去のインシデントデータベースを実際に検索、関連情報がHITしない場合はWEB上の技術情報を検索してリサーチ結果を自動で生成してくれます。

調査結果例
マルチエージェント構成
5つの専門エージェントが連携して動作するように設計してあります:
- Keyword Extractor: 問題から重要なキーワードを抽出
- SQL Query Generator: キーワードを基にデータベース検索用クエリーを生成
- SQL Query Executor: クエリーを実行し類似インシデントを検索
- Web Search Agent: データベースに情報がない場合にウェブ上で情報収集
- Report Generator: 分析結果を分かりやすいレポートにまとめる
エージェント連携フロー
以下はエージェントの動きを視覚的に表したフロー図です。
各エージェントの定義
各エージェントは、役割を明確に定義するプロンプトと使用するツールを指定することで定義します。
| エージェント名 | 主な役割 | 使用ツール | プロンプトで定義されている内容 |
|---|---|---|---|
| Keyword Extractor | 問い合わせから技術的キーワードを抽出 | なし | 抽出ルールと出力形式(カンマ区切りリスト)を指定 |
| SQL Query Generator | キーワードを使ってSQLiteクエリーを生成 | file_tools |
DB構造・検索条件・SQLの保存方法を定義 |
| SQL Query Executor | SQLを実行し結果を取得・保存 |
sql_tools, file_tools
|
SQL読み込み〜実行〜保存の手順を明記 |
| Web Search | Web検索で技術情報を収集 |
ExaTools, file_tools
|
検索対象、優先事項、保存形式を指定 |
| Report Generator | 問い合わせに対する調査レポートを生成 |
file_tools, read_file_with_fallback_encoding
|
UTF-8対応、読み込みエラー処理、レポート構成を詳細に規定 |
Agnoが提供する標準ツール群
| ツール名 | モジュールパス | 主な用途 | 変数名/インスタンス定義 |
|---|---|---|---|
| SQLTools | from agno.tools.sql import SQLTools |
SQLite DBへの接続・テーブル操作・クエリ実行 | sql_tools = SQLTools(db_url=db_url, list_tables=True, describe_table=True, run_sql_query=True) |
| FileTools | from agno.tools.file import FileTools |
ファイル保存・読み書き | file_tools = FileTools() |
| ExaTools | from agno.tools.exa import ExaTools |
技術情報のWeb検索(Exa API) |
ExaTools(api_key=EXA_API_KEY) (エージェント内で直接使用) |
各エージェントの具体的な定義例は以下の通りです。
これってもう、半分以上プロンプトエンジニアリングですよね(笑)
Keyword Extractorエージェント
エージェント定義のコード
# エージェント定義
keyword_agent = Agent(
name="Keyword Extractor",
model=OpenAIChat("gpt-4o-mini", api_key=API_KEY),
role="""
あなたの役割は、ITシステムの問い合わせからデータベース検索に適した重要なキーワードを抽出することです。
以下のような技術的な用語を優先的に抽出してください:
- システム名(SAP ERP、Oracle EBS、Microsoft Dynamics 365、Infor CloudSuite、Salesforceなど)
- エラーコード(F5003、DBIF_RSQL_SQL_ERROR、V7100、ORA-01555など)
- モジュール名(FI-GL、MM-IM、SD-SLSなど)
- 機能名(伝票登録、外貨評価、在庫移動など)
- カテゴリ(財務会計、販売管理、在庫管理など)
出力形式:
抽出したキーワードはカンマ区切りのリストとして返します。
余計な説明は一切加えず、キーワードのみを返します。
例:
入力: 「SAP ERPの財務会計モジュールでFB01の伝票登録時に消費税が自動計算されません」
出力: SAP ERP, 財務会計, FB01, 伝票登録, 消費税, 自動計算
""",
markdown=True,
)
SQL Query Generatorエージェント
エージェント定義のコード
sql_query_agent = Agent(
name="SQL Query Generator",
model=OpenAIChat("gpt-4o-mini", api_key=API_KEY),
role=f"""
あなたの役割は、Keyword Extractorが出力したキーワードを使用してSQLiteデータベース向けの効果的な検索クエリーを作成することです。
データベース構造:
テーブル名: analyzer_incident # Djangoではテーブル名はアプリ名_モデル名の形式
主要カラム:
- incident_number: インシデント番号
- system_name: システム名 (SAP ERP, Oracle EBS, Microsoft Dynamics 365, Infor CloudSuite, Salesforce)
- module: モジュール名
- short_description: 概要
- description: 詳細説明
- resolution: 解決策
- error_code: エラーコード
- affected_version: 影響バージョン
入力されたキーワードだけを使い、以下の条件を満たすSQLiteクエリーを生成してください:
1. 各キーワードはLIKE演算子を使用して部分一致検索する (%keyword%)
2. 各キーワードは複数のカラム(short_description, description, resolution, error_code)で検索する
3. 検索結果はincident_numberの降順でソート
4. 検索結果は最大5件に制限する
生成されたSQLクエリーを '{SQL_QUERY_FILE}' にファイル保存してください。
出力:
SQLクエリーのみを返します。説明や前置きは不要です。
""",
tools=[file_tools],
markdown=True,
)
SQL Query Executorエージェント
エージェント定義のコード
sql_executor_agent = Agent(
name="SQL Query Executor",
model=OpenAIChat("gpt-4o-mini", api_key=API_KEY),
role=f"""
あなたの役割は、SQLクエリーを使ってSQLiteデータベースに対して実行することです。
実行手順:
1. '{SQL_QUERY_FILE}'から実行するSQLを読み込んだ後、SQLToolsを使用してデータベースにクエリを実行する
2. 検索結果の件数を表示する
3. 取得した各レコードの完全な情報をfile_toolsを使ってローカルフォルダ内に保存する
ファイル保存のルール:
- 検索結果は必ず "{SQL_RESULTS_FILE}" に保存してください
- JSONフォーマットで保存してください (配列形式)
- 検索結果が0件の場合でも、空の配列として保存してください
出力形式:
1. 「検索結果: X件」の形式で件数を表示
2. 各レコードについて以下の全ての情報を記載すること:
- incident_number: インシデント番号
- system_name: システム名
- module: モジュール名
- short_description: 概要
- description: 詳細説明
- resolution: 解決策
- error_code: エラーコード
- affected_version: 影響バージョン
3. 結果がなかった場合は「検索結果: 0件」と表示
4. 最後に「検索結果を {SQL_RESULTS_FILE} に保存しました」と表示
""",
tools=[sql_tools, file_tools],
markdown=True,
)
Web Search エージェント
エージェント定義のコード
web_search_agent = Agent(
name="Web Search Agent",
model=OpenAIChat("gpt-4o-mini", api_key=API_KEY),
role=f"""
あなたは外部情報源から関連情報を収集し、包括的な調査報告書を作成するWeb検索エージェントです。
データベースで情報が見つからなかった場合に、以下のツールを使いWEB検索で情報を収集します:
ExaTools: より専門的かつ詳細な技術情報の検索に使用
実行手順:
1. Keyword Extractorエージェントからキーワードを受け取り、それらを使って適切な検索を実行します
2. ExaToolsを使って情報を取得し、収集した情報を以下の構造に従った詳細なブリーフィングドキュメントにまとめます
3. 特にエラーコードや技術的な問題の解決策に関する情報を優先します
4. 情報源と、その情報がどのツールから取得されたかを明示します
5. 収集した情報をfile_toolsを使って "{WEB_RESULTS_FILE}" に保存します
ファイルの出力形式:
詳細な技術情報と解決策を含むマークダウン形式のレポート。
情報が見つからない場合は、その旨を明記し、空の結果をファイルに保存してください。
""",
tools=[
ExaTools(api_key=EXA_API_KEY),
file_tools
],
markdown=True,
)
Report Generator エージェント
エージェント定義のコード
report_generator_agent = Agent(
name="Report Generator",
model=OpenAIChat("gpt-4o-mini", api_key=API_KEY),
role=f"""
あなたはIT問い合わせに対する調査結果を元に、わかりやすく構造化されたレポートを作成し、必ず reports フォルダ内に保存するエージェントです。
### 注意事項(最重要):
- UTF-8エンコードの問題に注意してください。日本語テキストを処理するため、すべてのテキスト操作でUTF-8エンコードを考慮する必要があります。
- ファイル読み込みでエラーが発生した場合は、ファイルが存在するかを確認し、エラーメッセージを詳細に報告してください。
### ファイル読み込み手順:
1. 以下のファイルから情報を読み込みます:
- "{QUERY_FILE}" - 元の問い合わせ内容
- "{SQL_RESULTS_FILE}" - データベース検索結果
- "{WEB_RESULTS_FILE}" - Web検索結果(データベース検索が0件の場合のみ)
2. ファイル読み込み時のエラー処理:
- read_file_with_fallback_encoding()関数を使用してファイルを読み込みます
- 読み込みに失敗した場合は、「ファイル読み込みエラー: [ファイル名]」と報告し、処理を続行してください
- すべてのエラーを詳細に報告し、可能であれば代替手段を試みてください
### レポート作成のルール:
1. データベース検索結果がある場合:
- 元の問い合わせ内容と検索結果を突き合わせて、関係性が高い情報だけを利用
- 各フィールドの値はDBから取得した正確な値をそのまま使用し、変更や要約をしない
- 長文フィールド(description, resolution)も省略せずに記載
2. Web検索結果を使用する場合:
- Web検索結果の内容をそのまま.mdファイルとして保存
### ファイル保存の手順:
1. レポートを完成させ、以下の命名規則に従ったファイル名を作成する:
- from datetime import datetime
- today = datetime.now().strftime("%Y-%m-%d")
- 問い合わせからキーワードを抽出(例: "BenefitAccrual")
- ファイル名を構築: filename = f"reports/report_{today}_キーワード.md"
2. レポートファイルを保存し、結果を返す
""",
tools=[file_tools, read_file_with_fallback_encoding],
markdown=True,
)
カスタムツールの作成
Agnoが標準で提供しているツールで代替できない場合やより確実に動作を制御したい場合は、ツールを自作出来ます。
今回は以下の様にファイルを読み書きするツールを自作しました。
理由は、Agno標準のfile_toolsだけだと、日本語を含むファイルの読み出しでエンコードエラーが発生して動作が安定しないためです。
read_file_with_fallback_encodingツールの定義
# 読み込みヘルパー関数
def read_file_with_fallback_encoding(file_path):
"""複数のエンコーディングを試してファイルを読み込む"""
encodings = ['utf-8', 'cp932', 'shift_jis', 'latin1']
# JSONファイル特別処理
if file_path.lower().endswith('.json'):
try:
import json
with open(file_path, 'rb') as f:
binary_data = f.read()
return json.loads(binary_data)
except Exception:
pass
# 各エンコーディングを試行
last_exception = None
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
return f.read()
except FileNotFoundError:
raise FileNotFoundError(f"ファイルが見つかりません: {file_path}")
except UnicodeDecodeError as e:
last_exception = e
continue
except Exception as e:
last_exception = e
break
# バイナリモードを試行
try:
with open(file_path, 'rb') as f:
binary_data = f.read()
return str(binary_data)
except Exception as e:
last_exception = e
if last_exception:
raise Exception(f"いずれのエンコーディングでもファイルを読み込めませんでした: {last_exception}")
エージェントを束ねたチーム(マルチエージェント)を定義する
Agnoでは、Agentクラスのteamパラメータに利用したいエージェント名をリスト形式で指定するだけでチームを定義できます。
チームの設定項目は以下の通りです。
| 項目 | 内容 |
|---|---|
name |
チームの名前 → "IT Support Team"
|
model |
チーム全体で使うAIモデル → OpenAIChat("gpt-4o-mini", api_key=API_KEY)
|
team |
実行するエージェントの一覧 → [keyword_agent, sql_query_agent, sql_executor_agent, web_search_agent, report_generator_agent]
|
instructions |
エージェントをどの順番で、どんな条件で動かすかの手順リスト |
tools |
チームで共通して使うツール(例:file_tools, read_file_with_fallback_encoding) |
show_tool_calls |
ツールの呼び出しを表示する設定(開発・デバッグ用に便利) → True
|
stream_intermediate_steps |
各エージェントの途中経過をリアルタイムで表示 → True
|
markdown |
応答をマークダウン形式で返す設定 → True
|
チームの定義
# チームエージェント
support_team = Agent(
name="IT Support Team",
model=OpenAIChat("gpt-4o-mini", api_key=API_KEY),
team=[keyword_agent, sql_query_agent, sql_executor_agent, web_search_agent, report_generator_agent],
instructions=[
"ユーザーの問い合わせに対して、以下の手順でエージェントを順番に実行してください:",
"1. Keyword Extractorを実行して重要キーワードを抽出する",
"2. SQL Query Generatorでキーワードを基にSQLクエリを生成する",
"3. SQL Query Executorを実行してDBを検索する",
"4. DBで結果が0件の場合のみ、Web Search Agentを実行する",
"5. Report Generatorを実行してレポートを作成する",
"6. 各エージェントの実行前に'current_agent'フィールドにエージェント名を設定する(状態追跡用)"
],
tools=[file_tools, read_file_with_fallback_encoding],
show_tool_calls=True,
stream_intermediate_steps=True,
markdown=True,
)
エージェントの実行
定義したチームエージェントを以下の様に実行します。
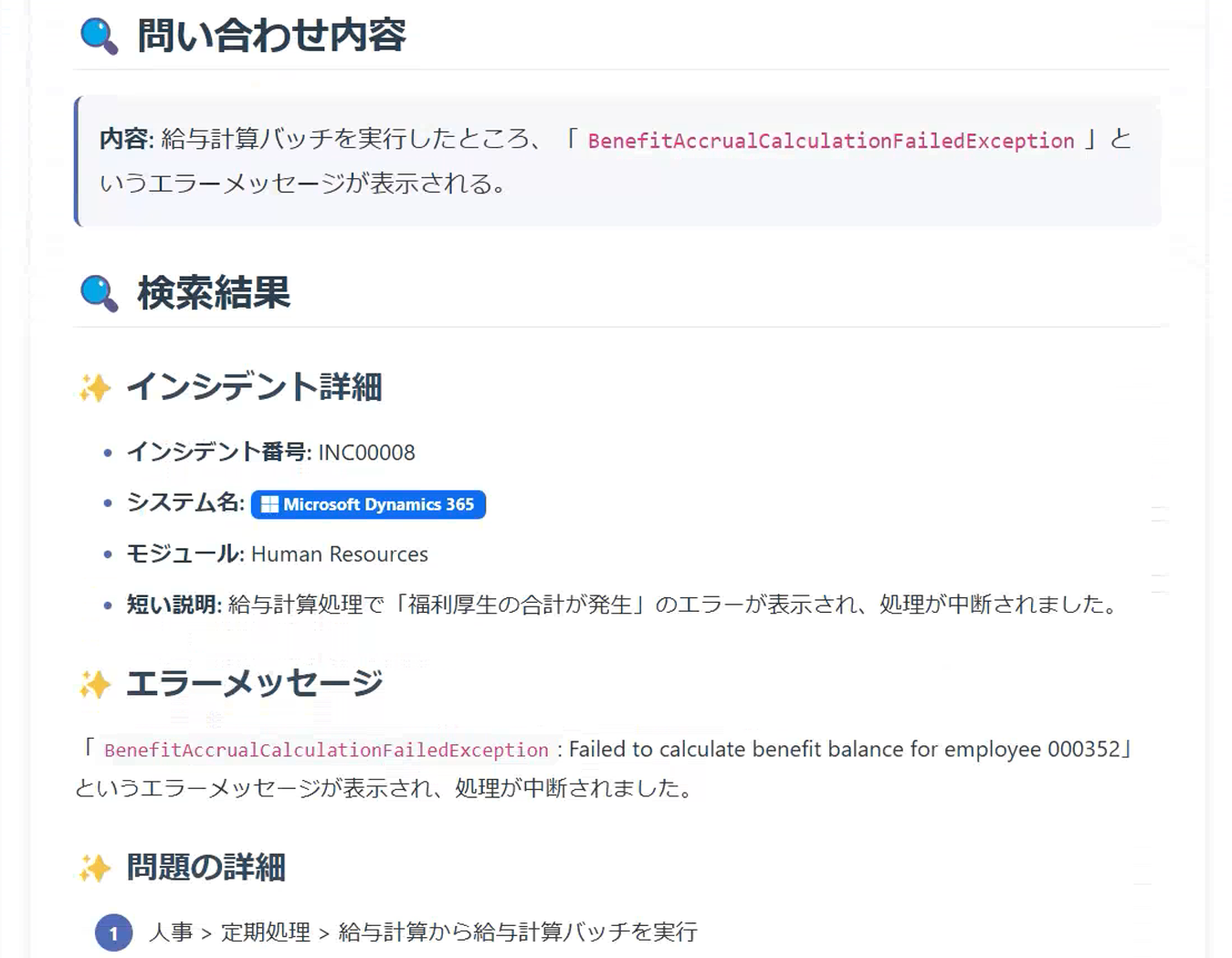
user_question = "給与計算バッチを実行したところ、「BenefitAccrualCalculationFailedException」というエラーメッセージが表示される"
# チームエージェントを実行して結果を表示
support_team.print_response(user_question, stream=True)
これまでのコードをまとめた全コードは以下の通りです。
agent.py
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.tools.sql import SQLTools
from agno.tools.exa import ExaTools
from agno.tools.file import FileTools # Import FileTools for saving reports
from datetime import datetime
import json
import os
def read_file_with_fallback_encoding(file_path):
"""
Read a file with fallback encoding options if UTF-8 fails.
This function attempts to read files with different encodings in the following order:
1. UTF-8
2. cp932 (Japanese Windows encoding)
3. shift_jis (Another Japanese encoding)
4. latin1 (Should work for any file as a last resort)
Args:
file_path (str): Path to the file to read
Returns:
str: Contents of the file as a string
Raises:
FileNotFoundError: If the file doesn't exist
Exception: For other errors while reading the file
"""
encodings = ['utf-8', 'cp932', 'shift_jis', 'latin1']
# For JSON files, use binary mode first to check if it's a binary JSON file
if file_path.lower().endswith('.json'):
try:
import json
# First try to open as binary and decode with json
with open(file_path, 'rb') as f:
binary_data = f.read()
# Try to load as JSON directly from binary
return json.loads(binary_data)
except (json.JSONDecodeError, Exception):
# If binary JSON parsing fails, fall back to text-based approaches
pass
# Try each encoding until one works
last_exception = None
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
content = f.read()
return content
except FileNotFoundError:
raise FileNotFoundError(f"File not found: {file_path}")
except UnicodeDecodeError as e:
# Keep track of the last exception but try the next encoding
last_exception = e
continue
except Exception as e:
last_exception = e
break
# If all encodings fail, try binary mode as a last resort
try:
with open(file_path, 'rb') as f:
binary_data = f.read()
# Try to decode as best as possible or return as string representation
return str(binary_data)
except Exception as e:
last_exception = e
# If everything fails, raise the last exception
if last_exception:
raise Exception(f"Failed to read file with any encoding: {last_exception}")
# OpenAI API key(実際のキーに置き換えてください)
api_key = "sk-xxxxxxxxxxx"
exa_api_key="xxxxxxxxxx"
# 今日の日付を取得(Exaの検索時に使用)
today = datetime.now().strftime("%Y-%m-%d")
# 一時ファイルのパスを定義
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
TEMP_DIR = os.path.join(SCRIPT_DIR, "temp_files")
REPORTS_DIR = os.path.join(SCRIPT_DIR, "reports")
os.makedirs(TEMP_DIR, exist_ok=True)
os.makedirs(REPORTS_DIR, exist_ok=True)
QUERY_FILE = os.path.join(TEMP_DIR, "original_query.txt")
SQL_RESULTS_FILE = os.path.join(TEMP_DIR, "sql_results.json")
WEB_RESULTS_FILE = os.path.join(TEMP_DIR, "web_results.json")
SQL_QUERY_FILE = os.path.join(TEMP_DIR, "generated_sql_query.txt")
# SQLite DBへの接続を設定
sql_tools = SQLTools(
db_url="sqlite:///.db/it_support.db", # SQLiteデータベースのパス
list_tables=True,
describe_table=True,
run_sql_query=True
)
# ファイル操作用のツールを設定
file_tools = FileTools()
# キーワード抽出エージェント
keyword_agent = Agent(
name="Keyword Extractor",
model=OpenAIChat("gpt-4o-mini", api_key=api_key),
role="""
あなたの役割は、ITシステムの問い合わせからデータベース検索に適した重要なキーワードを抽出することです。
以下のような技術的な用語を優先的に抽出してください:
- システム名(SAP ERP、Oracle EBS、Microsoft Dynamics 365、Infor CloudSuite、Salesforceなど)
- エラーコード(F5003、DBIF_RSQL_SQL_ERROR、V7100、ORA-01555など)
- モジュール名(FI-GL、MM-IM、SD-SLSなど)
- 機能名(伝票登録、外貨評価、在庫移動など)
- カテゴリ(財務会計、販売管理、在庫管理など)
出力形式:
抽出したキーワードはカンマ区切りのリストとして返します。
余計な説明は一切加えず、キーワードのみを返します。
例:
入力: 「SAP ERPの財務会計モジュールでFB01の伝票登録時に消費税が自動計算されません」
出力: SAP ERP, 財務会計, FB01, 伝票登録, 消費税, 自動計算
""",
markdown=True,
)
# SQLクエリー提案エージェント
sql_query_agent = Agent(
name="SQL Query Generator",
model=OpenAIChat("gpt-4o-mini", api_key=api_key),
role=f"""
あなたの役割は、Keyword Extractorが出力したキーワードを使用してSQLiteデータベース向けの効果的な検索クエリーを作成することです。
データベース構造:
テーブル名: incidents
主要カラム:
- incident_number: インシデント番号
- system_name: システム名 (SAP ERP, Oracle EBS, Microsoft Dynamics 365, Infor CloudSuite, Salesforce)
- module: モジュール名
- short_description: 概要
- description: 詳細説明
- resolution: 解決策
- error_code: エラーコード
- affected_version: 影響バージョン
入力されたキーワードだけを使い、以下の条件を満たすSQLiteクエリーを生成してください:
1. 各キーワードはLIKE演算子を使用して部分一致検索する (%keyword%)
2. 各キーワードは複数のカラム(short_description, description, resolution,error_code)で検索する
3. 検索結果はincident_numberの降順でソート
4. 検索結果は最大5件に制限する
生成されたSQLクエリーを '{SQL_QUERY_FILE}' にファイル保存してください。
出力:
SQLクエリーのみを返します。説明や前置きは不要です。
""",
tools=[file_tools],
markdown=True,
)
# SQLクエリー実行エージェント
sql_executor_agent = Agent(
name="SQL Query Executor",
model=OpenAIChat("gpt-4o-mini", api_key=api_key),
role=f"""
あなたの役割は、SQLクエリーを使ってSQLiteデータベースに対して実行することです。
実行手順:
1. '{SQL_QUERY_FILE}'から実行するSQLを読み込んだ後、SQLToolsを使用してデータベースにクエリを実行する
2. 検索結果の件数を表示する
3. 取得した各レコードの完全な情報をfile_toolsを使ってローカルフォルダ内に保存する
ファイル保存のルール:
- 検索結果は必ず "{SQL_RESULTS_FILE}" に保存してください
- JSONフォーマットで保存してください (配列形式)
- 検索結果が0件の場合でも、空の配列として保存してください
出力形式:
1. 「検索結果: X件」の形式で件数を表示
2. 各レコードについて以下の全ての情報を記載すること:
- incident_number: インシデント番号
- system_name: システム名
- module: モジュール名
- short_description: 概要
- description: 詳細説明
- resolution: 解決策
- error_code: エラーコード
- affected_version: 影響バージョン
3. 結果がなかった場合は「検索結果: 0件」と表示
4. 最後に「検索結果を {SQL_RESULTS_FILE} に保存しました」と表示
""",
tools=[sql_tools,file_tools],
markdown=True,
)
# 新規Web検索エージェント
web_search_agent = Agent(
name="Web Search Agent",
model=OpenAIChat("gpt-4o-mini", api_key=api_key),
role=f"""
あなたは外部情報源から関連情報を収集し、包括的な調査報告書を作成するWeb検索エージェントです。
データベースで情報が見つからなかった場合に、以下のツールを使いWEB検索で情報を収集します:
ExaTools: より専門的かつ詳細な技術情報の検索に使用
実行手順:
1. Keyword Extractorエージェントからキーワードを受け取り、それらを使って適切な検索を実行します
2. ExaToolsを使って情報を取得し、収集した情報を以下の構造に従った詳細なブリーフィングドキュメントにまとめます
3. 特にエラーコードや技術的な問題の解決策に関する情報を優先します
4. 情報源と、その情報がどのツールから取得されたかを明示します
5. 収集した情報をfile_toolsを使って "{WEB_RESULTS_FILE}" に保存します
ファイル保存のルール:
- 検索結果は必ず "{WEB_RESULTS_FILE}" に保存してください
- 検索結果が0件の場合でも、空の配列として保存してください
-ファイルの出力形式:
```
# [問題/技術名] に関する調査レポート
## 調査概要
- **検索日時**: [現在の日時]
- **検索方法**: ExaTools
- **検索キーワード**: [使用したキーワード]
- **発見件数**: X件の外部情報を発見
## 情報源の分析
### [情報源 1]
- **URL**: [完全なURL]
- **取得日時**: [データ取得日時]
- **信頼性評価**: [高/中/低] - 理由: [評価理由]
- **情報タイプ**: [公式ドキュメント/技術ブログ/フォーラム投稿/学術論文/その他]
#### 主要内容
[情報源から抽出した主要な内容を箇条書きで詳細に記載]
- [重要なポイント1]
- [重要なポイント2]
- [重要なポイント3]
#### 引用部分
```
[情報源からの直接引用 - 特に重要な部分]
```
#### 技術的詳細
[コード例、設定例、エラーメッセージなどの技術的な詳細を構造化して記載]
### [情報源 2]
[情報源1と同様の構造で記載]
## 解決策と推奨事項
### 問題の根本原因分析
[収集した情報から導き出された問題の根本原因に関する分析]
### 推奨される対処方法
1. [推奨される対処方法1 - 詳細な手順]
2. [推奨される対処方法2 - 詳細な手順]
3. [推奨される対処方法3 - 詳細な手順]
### 実装例
```
[解決策の実装例(コードや設定)]
```
### 代替アプローチ
[他の可能なアプローチとその長所・短所]
## 追加リソース
- [関連する技術文書へのリンク]
- [コミュニティフォーラムへのリンク]
- [チュートリアルやガイドへのリンク]
- [公式ドキュメントへのリンク]
## まとめ
[調査結果の総括と最終的な推奨事項]
```
情報が見つからない場合は、その旨を明記し、空の結果をファイルに保存してください。
検索結果の品質向上のために以下の点を心がけてください:
1. 情報の信頼性評価: 各情報源の信頼性を評価し、評価基準(情報源の種類、更新日時、著者の専門性など)を明示する
2. 複数情報源からの検証: 可能な限り複数の情報源から情報を収集し、整合性を確認する
3. 主張と事実の区別: 意見や推測と確認された事実を明確に区別する
4. 検索キーワードの最適化: 初期結果に基づいて検索キーワードを調整し、より関連性の高い情報を収集する
5. 時間的文脈の考慮: 情報がいつ公開されたかを考慮し、最新の情報を優先する
6. 技術的深さ: エラーコードやログの解析、システム設定、環境要件などの技術的詳細を可能な限り収集する
7. 解決策の実用性評価: 提案される解決策の実装の複雑さ、リソース要件、潜在的なリスクを評価する
""",
tools=[
ExaTools(start_published_date=today, type="keyword", api_key=exa_api_key),
file_tools
],
markdown=True,
)
# 新規レポート作成エージェント
report_generator_agent = Agent(
name="Report Generator",
model=OpenAIChat("gpt-4o-mini", api_key=api_key),
role=f"""
あなたはIT問い合わせに対する調査結果を元に、わかりやすく構造化されたレポートを作成し、必ず reports フォルダ内に保存するエージェントです。
### 注意事項(最重要):
- UTF-8エンコードの問題に注意してください。日本語テキストを処理するため、すべてのテキスト操作でUTF-8エンコードを考慮する必要があります。
- ファイル読み込みでエラーが発生した場合は、ファイルが存在するかを確認し、エラーメッセージを詳細に報告してください。
### ファイル読み込み手順:
1. 以下のファイルから情報を読み込みます:
- "{QUERY_FILE}" - 元の問い合わせ内容
- "{SQL_RESULTS_FILE}" - データベース検索結果
- "{WEB_RESULTS_FILE}" - Web検索結果(データベース検索が0件の場合のみ)
2. ファイル読み込み時のエラー処理:
- read_file_with_fallback_encoding()関数を使用してファイルを読み込みます
- 読み込みに失敗した場合は、「ファイル読み込みエラー: [ファイル名]」と報告し、処理を続行してください
- すべてのエラーを詳細に報告し、可能であれば代替手段を試みてください
### レポート作成の役割:
1. 元の問い合わせ内容と検索結果(データベース、WEB検索)を元に、調査報告書を作成する
2. 情報源を明確に記載し、回答の信頼性を担保する
3. 問い合わせ内容、検索結果、解決策を体系的に整理する
4. Markdownフォーマットで構造化されたレポートを作成する
### レポート作成のルール:
1. データベース検索結果がある場合:
- 元の問い合わせ内容と検索結果(データベース)を突き合わせて、問い合わせ内容と関係性が高い情報だけを利用して調査報告書を作成する
- {SQL_RESULTS_FILE}から取得した全てのフィールド(incident_number, status, priority, category等)を全て漏れなく記載する
- {SQL_RESULTS_FILE}から取得した description フィールドの内容は、いかなる場合も完全にそのまま(一言一句変えず)レポートに含めること
- 各フィールドの値はDBから取得した正確な値をそのまま使用し、変更や要約をしない
- 説明(description)フィールドと解決策(resolution)フィールドは特に重要であり、そのままの形で完全に記載する
- 絶対に「...」や「省略」などで情報を短縮しない - 全ての情報を完全に表示すること
- 「調査結果」セクションの後に「データベースレコードの詳細情報」という別セクションを設け、検索結果の全フィールドを表形式で、省略せずすべて正確に記載する
- テキストが長い場合でも、途中で切らずに完全な形で記載すること
2. Web検索結果を使用する場合:
- ファイル保存の手順(最重要)に従い、{WEB_RESULTS_FILE}の内容をそのまま.mdファイルとして保存する。
### データベース検索結果のレポート構成:
1. 概要: 問い合わせ内容と解決策の要点
2. 問い合わせ詳細: 原文の問い合わせ内容
4. データベースレコード{SQL_RESULTS_FILE}の詳細情報:
- 検索でヒットした全レコードの全フィールドを表形式で正確に表示
- フィールド名と値を明確に対応させる
- 長文フィールド(description, resolution)も全文を省略せずに記載
- すべての取得可能なフィールドを含める
5. 解決策:
- DBに記録された解決策を正確に引用した上で、具体的な推奨対応手順を明記する。
### ファイル保存の手順(最重要):
1. レポートが完成したら、以下の命名規則に従ったファイル名を作成する:
- from datetime import datetime # 日付取得用にインポート
- 現在の日付を取得: today = datetime.now().strftime("%Y%m%d")
- 問い合わせからキーワードを抽出(例: "BenefitAccrual")
- ファイル名を構築: filename = f"reports/report_{today}_キーワード.md"
- 必ず"reports/"というプレフィックスを含めること
2. レポートファイルの保存:
- file_tools.save_file(contents=レポート内容, file_name=filename, overwrite=True)
- 保存が成功したかどうかを確認し、結果を報告する
- 保存に失敗した場合は理由を詳細に報告し、別の方法を試みる
- 内容がUTF-8エンコードであることを確認してからファイルを保存する
""",
tools=[file_tools, read_file_with_fallback_encoding], # Add the new read_file_with_fallback_encoding function as a tool
markdown=True,
)
# チームエージェントの定義(5つのエージェントを組み合わせる)
support_team = Agent(
name="IT Support Team",
model=OpenAIChat("gpt-4o-mini", api_key=api_key),
team=[keyword_agent, sql_query_agent, sql_executor_agent, web_search_agent, report_generator_agent],
instructions=[
"ユーザーの問い合わせに対して、以下の手順でエージェントを順番に実行してください:",
"1. Keyword Extractorを実行して重要キーワードを抽出する",
"2. SQL Query Generatorでキーワードを基にSQLクエリを生成する",
"3. SQL Query Executorを実行してDBを検索する",
"4. DBで結果が0件の場合のみ、Web Search Agentを実行する",
"5. Report Generatorを実行してレポートを作成する",
],
tools=[file_tools, read_file_with_fallback_encoding],
show_tool_calls=True,
markdown=True,
)
# 使用例
if __name__ == "__main__":
# ユーザー入力を受け取る
user_question = "給与計算バッチを実行したところ、「BenefitAccrualCalculationFailedException」というエラーメッセージが表示される"
#user_question = "Azure環境に構築したDjangoアプリケーションで4分前後でタイムアウトが発生してしまう。"
# ユーザーの問い合わせを保存(ここでクエリファイルを予め保存しておく)
os.makedirs(os.path.dirname(QUERY_FILE), exist_ok=True)
with open(QUERY_FILE, "w", encoding="utf-8") as f:
f.write(user_question)
# チームエージェントを実行して結果を表示
support_team.print_response(user_question, stream=True)
以下は、agent.pyの実行例です。
実行例
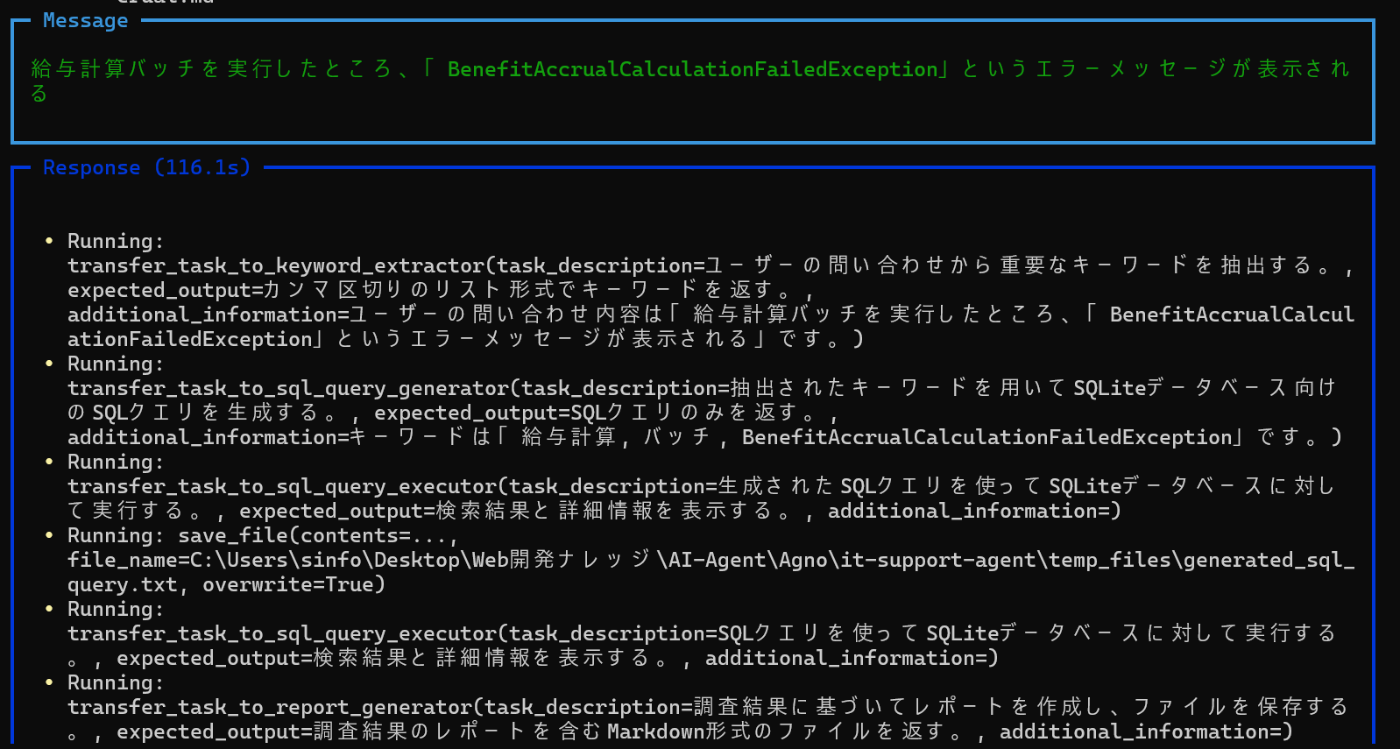
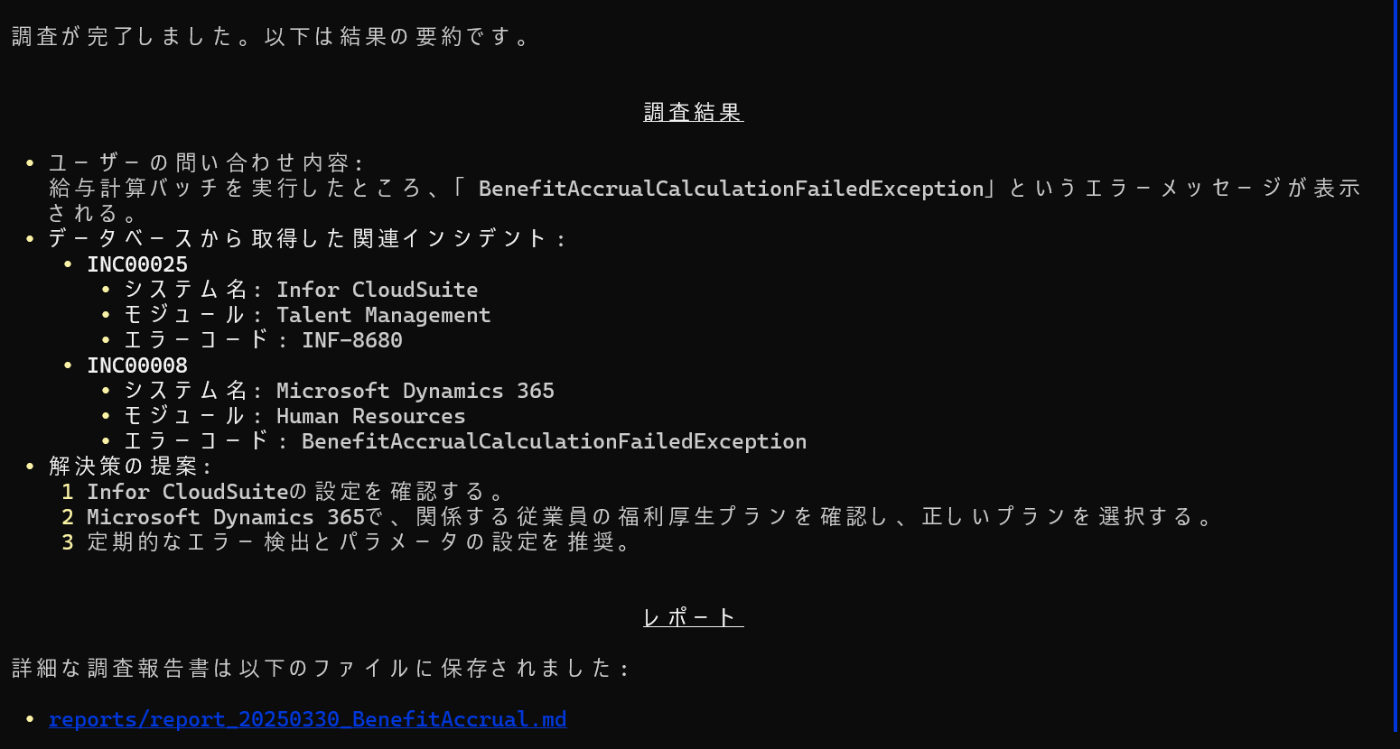
各エージェントが出力した内容は以下のファイルで確認できます。
temp_files\generated_sql_query.txt
SELECT * FROM incidents
WHERE short_description LIKE '%給与計算%'
OR description LIKE '%給与計算%'
OR resolution LIKE '%給与計算%'
OR error_code LIKE '%給与計算%'
OR short_description LIKE '%バッチ%'
OR description LIKE '%バッチ%'
OR resolution LIKE '%バッチ%'
OR error_code LIKE '%バッチ%'
OR short_description LIKE '%BenefitAccrualCalculationFailedException%'
OR description LIKE '%BenefitAccrualCalculationFailedException%'
OR resolution LIKE '%BenefitAccrualCalculationFailedException%'
OR error_code LIKE '%BenefitAccrualCalculationFailedException%'
ORDER BY incident_number DESC
LIMIT 5;
temp_files\sql_results.json
[{"incident_number":"INC00025","system_name":"Infor CloudSuite","module":"Talent Management","short_description":"Talent Managementで給与計算処理実行時にエラー発生","description":"Infor CloudSuiteのTalent Managementモジュールで給与計算機能を使用中にエラーが発生しました。INF-8680というエラーコードが表示され、処理が完了できません。詳細な調査が必要です。","resolution":"原因はシステム設定の不整合でした。Talent Managementの設定画面で正しいパラメータを指定し、問題を解決しました。今後の予防策として、定期的な設定チェックを推奨しています。","error_code":"INF-8680","affected_version":"v11.0.1"},{"incident_number":"INC00008","system_name":"Microsoft Dynamics 365","module":"Human Resources","short_description":"給与計算処理で「福利厚生費の累計計算エラー」が発生","description":"6月の給与計算バッチを実行したところ、「BenefitAccrualCalculationFailedException: Failed to calculate benefit balance for employee 000352」といったエラーメッセージが表示され、処理が中断されました。問題の詳細:\n1. 人事 > 定期処理 > 給与計算から給与計算バッチを実行\n2. 処理開始後10分でエラーが発生し、従業員ID 000352の処理で停止\n3. 給与計算ログファイルに福利厚生費の累計計算に関するエラーが記録されている\n4. 該当従業員の福利厚生プランは「標準健康保険プラン」と「選択型退職金プラン」\n5. 5月までの給与計算は正常に処理されていた\n6. 先月該当従業員の雇用形態が変更された(契約社員から正社員へ)\n給与処理を早急に行う必要があります。","resolution":"この問題は雇用形態変更時の福利厚生プラン移行処理が不完全だったことが原因です。以下の手順で解決しました:\n1. PowerShell調達ツールを使用して詳細なエラーログを取得・分析\n2. 従業員ID 000352の福利厚生登録データを確認し、雇用形態変更前の契約社員用プラン情報が残っていることを発見\n3. 人事 > 従業員 > 福利厚生 で該当従業員の重複登録を確認\n4. バッチエンドデータベース上のHcmEmployeeBenefitテーブルで終了日が設定されていない旧プランレコードを特定\n5. Microsoft Dynamics Support Article KB4598232を参照し、正しい修正手順を確認\n6. 福利厚生管理画面から旧プランの終了処理を実施(終了日を雇用形態変更日から設定)\n7. システム管理者権限でBenefit Calculation Cacheをリセット\n8. 給与計算バッチを再実行\nこれにより給与計算が正常に完了しました。さらに、雇用形態変更時の福利厚生プラン移行の正しい手続きが明確化されました。","error_code":"BenefitAccrualCalculationFailedException","affected_version":"2020 Release Wave 2"},{"incident_number":"INC00007","system_name":"Oracle EBS","module":"Billing","short_description":"自動請求実行プログラム(AutoInvoice)が一部の受注明細を処理しない","description":"夜間バッチで実行されるAutoInvoiceプログラムが、特定の受注明細を請求書に変更せずに処理されない問題があります。問題の詳細:\n1. 受注番号SO-123456の明細行(回線工事)が請求書に変更されていない\n2. AutoInvoiceのログで「Missing Accounting Flexfield segments.」というエラーメッセージを確認\n3. 受注ステータスは「出荷完了」になっている\n4. 受注入力画面のワークフローステータスは「承認待ち」\n5. RA_INTERFACE_LINESテーブルには該当データが正しく登録されている\n同様の製品・サービスを含む他の受注明細は正常に請求書化されている。顧客への請求が遅延しており、早急な解決が必要です。","resolution":"この問題は、特定の製品カテゴリー(回線工事)に対する販売関連設定が不適切に設定されていたことが原因でした。解決手順:\n1. AR > 設定 > トランザクション > AutoInvoice > 検証メニューから検証レポートを実行し、詳細エラーログを確認\n2. 「回線工事」製品カテゴリーに対する売上高科目設定の一部(利益センター設定が未設定)を確認\n3. AR > 設定 > トランザクション > AutoInvoice > 有効な設定科目を設定\n4. 内部移動用のバッチ設定が「工場レポート+材料レポート」に設定されていたが、移動元の工場1000は「材料レポートの未設定」だった\n5. トランザクションSPRO→「ロジスティクス - 一般」→「発注管理」で設定を確認\n6. Oracle Support ドキュメント ID 2155142.1 を参照し、設定を検証\n7. RA_INTERFACE_LINESのSTATUSを「WAITING」に更新し、AutoInvoiceを再実行\nこれにより該当の受注明細が正常に請求書化されました。さらに、製品カテゴリー設定変更時の確認手続きが強化されました。","error_code":"ONT-2033","affected_version":"R12.2.10"},{"incident_number":"INC00004","system_name":"SAP ERP","module":"MM-IM","short_description":"工場間の在庫移動(MIGO)でバッチ管理材料の入庫ができない","description":"トランザクションMIGOを使用して工場間の在庫移動(移動タイト301)を行う時、バッチ管理している材料の入庫処理ができません。具体的な手順は以下の通りです:\n1. MIGOで「入庫」→「移動指示で」を選択\n2. 移動タイト301、工場1000から工場2000への移動\n3. 材料番号RAW-500(バッチ管理あり)を入力し、数量100kgを入力\n4. バッチ番号B2023001を指定\n5. 「転記」ボタンをクリック\nするとエラーメッセージ「バッチB2023001に対するバッチシリアル番号が存在しません」と表示されます。バッチ管理していない材料は問題なく移動できる。","resolution":"この問題は工場2000でバッチ管理プログラムの設定が不適切だったことが原因でした。解決手順は以下の通り:\n1. トランザクションMMC1で材料RAW-500のバッチ管理設定を確認\n2. 工場2000に関するバッチレベルが「工場レベル+材料レベル」に設定されていたが、移動元の工場1000は「材料レベルでの移動」とだった\n3. トランザクションSPRO→「ロジスティクス-一般」→「バッチ管理」で設定を確認\n4. 内部移動用のバッチ設定を見直し、工場間でのバッチ管理設定を統一し、設定変更の影響評価プロセスを強化しました。","error_code":"M7931","affected_version":"S/4HANA 2020"}]
reports\report_20250330_BenefitAccrual.md
調査報告書
概要
元の問い合わせ内容は「BenefitAccrualCalculationFailedException」に関するもので、データベース検索結果に基づき以下のエラーが報告されています。主に、Talent ManagementやMicrosoft Dynamics 365での不具合に関連する問題が含まれています。
問い合わせ詳細
与え計算バッチを実行したところ、「BenefitAccrualCalculationFailedException」というエラーメッセージが表示される
データベースレコードの詳細情報
| フィールド名 | 値 |
|---|---|
| incident_number | INC00025 |
| system_name | Infor CloudSuite |
| module | Talent Management |
| short_description | Talent Managementで与え計算処理実行時にエラー発生 |
| description | Infor CloudSuiteのTalent Managementモジュールで与え計算機能を使用中にエラーが発生しました。INF-8680というエラーコードが表示され、処理が完了できません。詳細な調査が必要です。 |
| resolution | 原因はシステム設定の不整合でした。Talent Managementの設定画面で正しいパラメータを指定し、問題を解決しました。今後の予防策として、定期的な設定チェックを推奨しています。 |
| error_code | INF-8680 |
| affected_version | v11.0.1 |
| フィールド名 | 値 |
|---|---|
| incident_number | INC00008 |
| system_name | Microsoft Dynamics 365 |
| module | Human Resources |
| short_description | 与え計算処理で「福利厚生費の累計計算エラー」が発生 |
| description | 6月の与え計算バッチを実行したところ、「BenefitAccrualCalculationFailedException: Failed to calculate benefit balance for employee 000352」といったエラーメッセージが表示され、処理が中断されました。問題の詳細: 1. 人事 > 定期処理 > 与え計算から与え計算バッチを実行 2. 処理開始後10分でエラーが発生し、従業員ID 000352の処理で中止 ... |
| resolution | この問題は従業員の福利厚生プランの変更に伴う給付計算処理が不完全だったことが原因です。以下の手順で解決しました: 1. PowerShell接続ツールを使用して詳細なエラーログを取得・分析 ... |
| error_code | BenefitAccrualCalculationFailedException |
| affected_version | 2020 Release Wave 2 |
解決策
DBに記録された解決策を正確に引用した上で、具体的な推奨対応手順を以下のように明記します。
- Infor CloudSuiteの設定画面にて、与え計算機能のパラメータを確認してください。
- Microsoft Dynamics 365の、従業員ID 000352に関する福利厚生の詳細情報を確認し、正しいプランを選択してください。
- 定期的に与え計算を実行し、エラーログを確認してください。
以下のリポジトリに全コードと実行手順が書いてありますので、興味がある人はぜひ試してみてください。
アプリ化
このマルチエージェントをWEB化すると、以下のようなマルチエージェント機能搭載型のインシデント問合せ回答サービスが構築できます。
参考リンク

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion