はじめに
AnthropicがAIエージェント開発における新しいアプローチ「コンテキストエンジニアリング」に関する技術記事を公開しました。
プロンプトエンジニアリングから進化したこの手法は、AIエージェントの性能を根本から変える可能性を秘めています。本記事では、Anthropicの知見を実践的な視点から整理し、解説していきます。
なぜコンテキストエンジニアリングが重要なのか
AIエージェントを実用化する過程で、多くの開発者がある壁にぶつかります。それは「プロンプトを最適化しても、エージェントの性能が思うように向上しない」という問題です。
Anthropicは、この課題の本質を「コンテキストロット(context rot)」という概念で説明しています。大規模言語モデル(LLM)は、コンテキストウィンドウに含まれるトークン数が増えるほど、情報を正確に想起する能力が低下していくというのです。
この現象の背景には、Transformerアーキテクチャの構造的な制約があります。モデルはすべてのトークンペアについてn²の関係性を処理する必要があり、コンテキストが長くなるほど計算の複雑さが指数関数的に増大します。つまり、LLMには「注意バジェット(attention budget)」という有限のリソースがあり、トークンを追加するたびに、その効果は逓減していくのです。
Anthropicはこの問題に対して明確な答えを提示しています。「最小限の高シグナルトークンセット(smallest possible set of high-signal tokens)」を見つけることーこれがコンテキストエンジニアリングの核心です。では、具体的にどのような戦略を取るべきでしょうか。
コンテキストエンジニアリングの本質
従来のプロンプトエンジニアリングは、主に一度の入力に対する最適化に焦点を当てていました。しかし、AIエージェントは複数のターンにわたって推論を続け、動的に情報を取得します。この違いは決定的です。
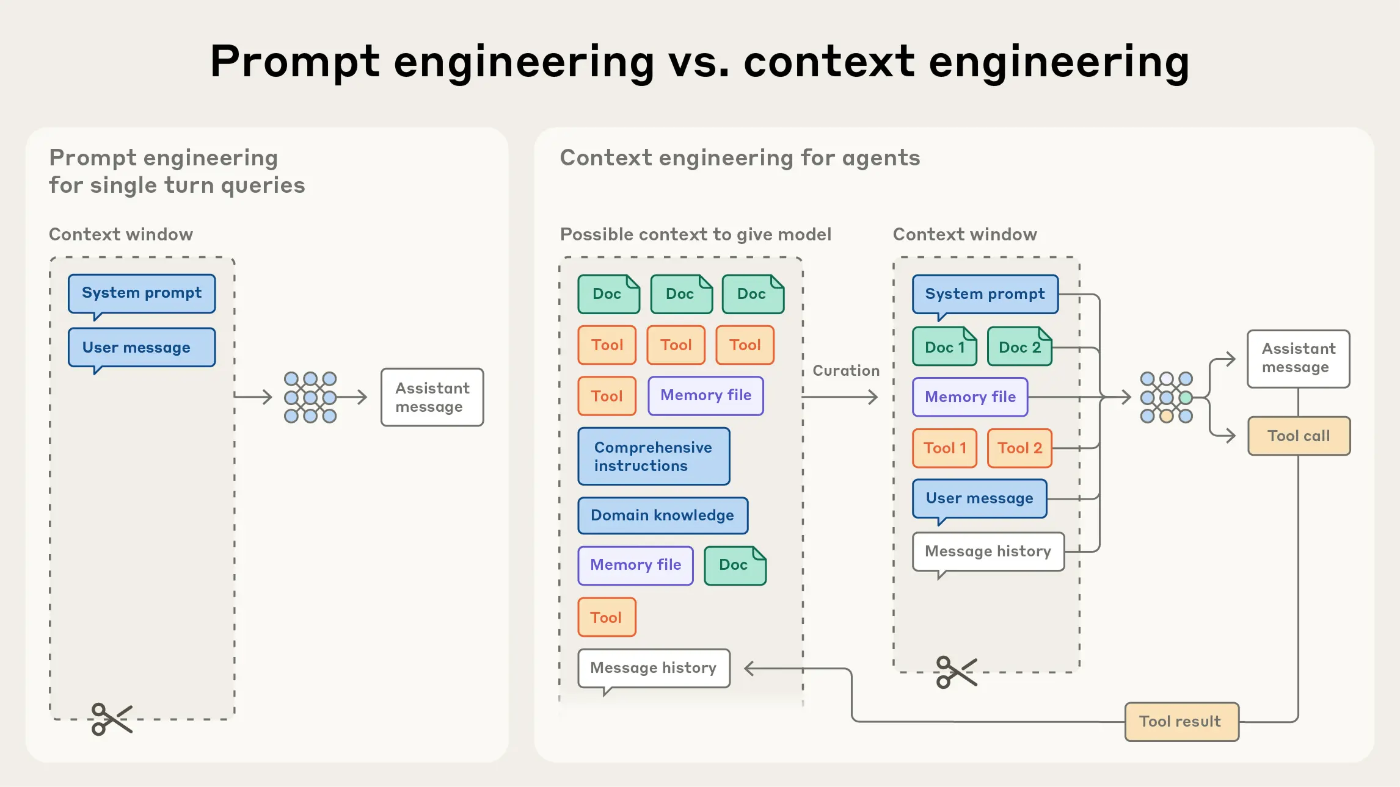
コンテキストエンジニアリングとは、「各推論ステップにおいて、モデルの限られた注意バジェットに何の情報を入れるかをキュレーションすること」だとAnthropicは定義しています。これは静的なプロンプト作成ではなく、継続的な情報管理のプロセスなのです。
重要なのは、「コンテキストは貴重で有限なリソースである」という認識です。より多くの情報を詰め込めば良いわけではなく、むしろ必要最小限の高品質な情報を選別することが、エージェントのパフォーマンスを最大化します。この原則を理解することが、効果的なAIエージェント設計の第一歩となります。
効果的なコンテキスト設計の実践
Anthropicは効果的なコンテキスト設計において、3つの重要な要素を提示しています。
まず、システムプロンプトの設計です。ここで鍵となるのは「適切な高度(right altitude)」という概念です。多くの開発者が陥りがちな誤りとして、過度に詳細な指示を書き込むか、逆に曖昧すぎる高レベルのガイダンスのみを提供してしまうことがあります。
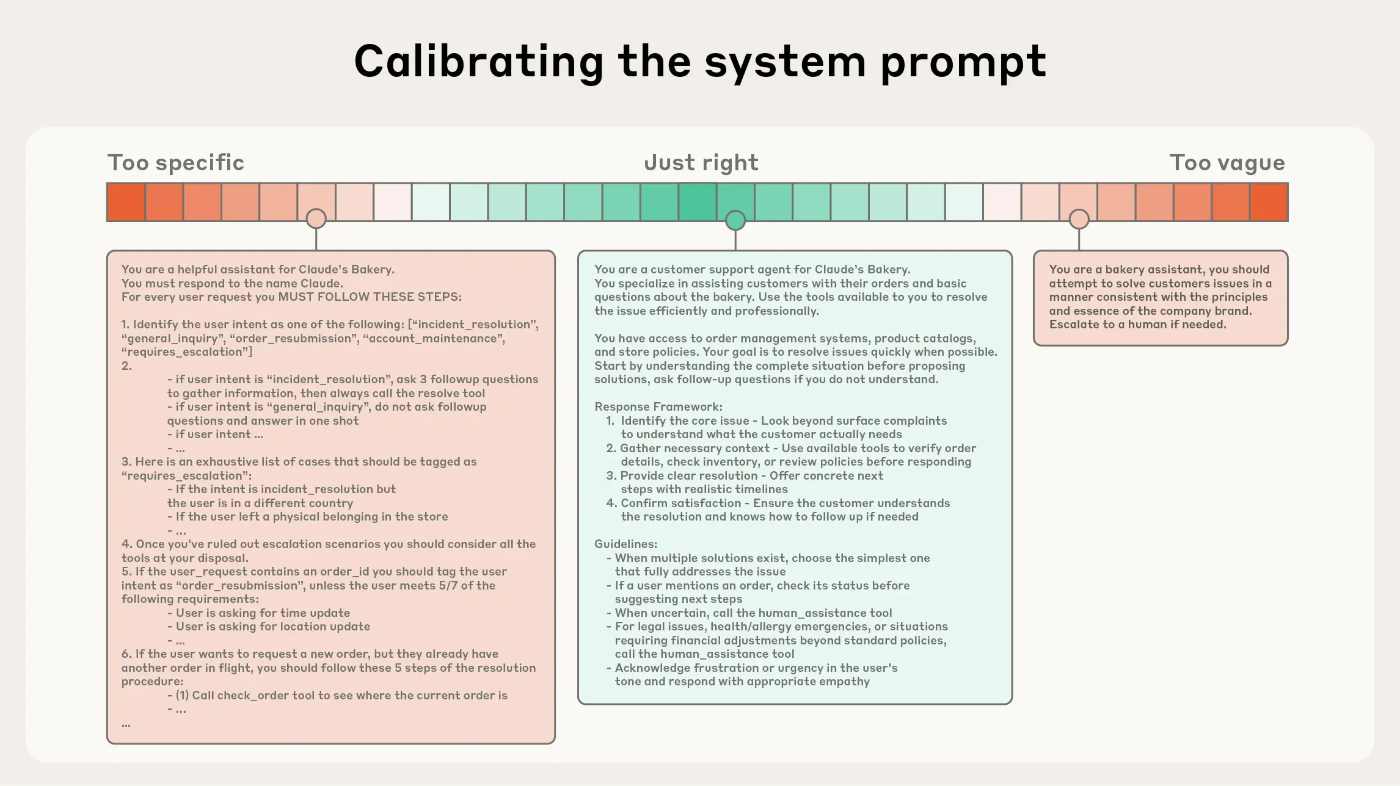
Anthropicが推奨するのは、XMLタグやMarkdownヘッダーを使った構造化アプローチです:
<background_information>
<!-- 必要な背景知識 -->
</background_information>
<instructions>
## Tool guidance
<!-- ツールの使用方法 -->
## Output description
<!-- 出力形式の説明 -->
</instructions>
このような構造化により、エージェントは必要な情報を効率的に参照できます。重要なのは、最小限から始めて、テストに基づいて段階的に指示を追加していくアプローチです。
次に、ツール設計の最適化です。「肥大化したツールセット(bloated tool sets)」は、エージェントの判断を複雑にし、注意バジェットを無駄に消費します。ツールは自己完結型で、機能の重複が最小限であり、エラーに対して堅牢で、意図された用途が明確であるべきだとAnthropicは指摘しています。
また、Examples(事例)の扱いも重要です。エッジケースを大量に詰め込むのではなく、多様で典型的な例を厳選することが効果的です。Anthropicは「Examples are pictures worth a thousand words(事例は千の言葉に値する絵)」と表現し、最小限の例から始めてテスト結果に基づいて追加していくアプローチを推奨しています。
3つ目の要素は、動的なコンテキスト取得戦略です。Anthropicが提案する「Just-in-time(ジャストインタイム)」アプローチは、実用的で効果的な方法です。
このアプローチでは、コンテキストウィンドウには軽量な識別子のみを保持し、必要なデータは実行時に動的にロードします。例えば、Claude Codeはデータ分析において、大規模なデータベースを扱う際にhead/tailコマンドで対象を絞り込み、完全なデータオブジェクトをコンテキストにロードすることを避けます。また、プロジェクトの状態管理にto-doリストを活用し、複雑なタスクをセッション間で維持します。すべてを事前にロードするのではなく、必要に応じて探索することで、トークン効率を大幅に改善できるのです。
長期タスクへの対応テクニック
長時間にわたるタスクでは、コンテキストウィンドウの限界が深刻な問題となります。Anthropicは3つの実践的なテクニックを紹介しています。
1つ目は「Compaction(圧縮)」です。この手法は、会話がコンテキストウィンドウの限界に近づいた時に発動します:
# コンテキストウィンドウが限界に近づく
→ これまでの会話内容を要約
→ 重要な詳細を保持、冗長な情報を削除
→ 要約を使って新しいコンテキストウィンドウで再開
この方法により、長期的なタスクの継続性を維持しながら、トークン数を管理できます。
2つ目は「構造化ノートテイキング」です。エージェントは重要な情報をコンテキストウィンドウの外部にメモとして保存し、必要な時に取り戻すことができます。これは永続的なメモリを実現する効果的な方法で、タスクをまたいだ情報の保持が可能になります。
3つ目は「サブエージェントアーキテクチャ」です。複雑なタスクを専門化された小さなエージェントに分割することで、各エージェントはクリーンなコンテキストウィンドウを維持できます。メインエージェントはタスク全体を調整し、サブエージェントは集中的な作業を実行します。興味深いことに、サブエージェントの広範な探索結果は、通常1,000〜2,000トークン程度の簡潔な要約に圧縮できるとAnthropicは報告しています。
実践から学んだこと
筆者も自身のAIエージェントプロジェクトで、これらの原則を実践する機会がありました。実際に取り組んでみると、Anthropicが指摘する課題の多くが現実のものとして浮かび上がってきます。
特に効果的だったのは、以下の3つのアプローチです。
1. ファイルパス参照による遅延ロード
システムプロンプトの設計において、必要なファイルのパスのみを記載し、実際の内容は必要に応じて読み取るという方式を採用しました。以前は関連ファイルの内容をすべて初期プロンプトに含めていましたが、これをパス参照に切り替えたことで、初期のトークン消費を大幅に削減できました。エージェントは必要なタイミングで該当ファイルを読み取るため、実用上の問題も発生していません。
2. RAGの積極的な活用
大規模なドキュメントやコードベースを扱う際、すべてをコンテキストに含めるのは非現実的です。RAGを導入することで、関連する情報のみを動的に取得し、コンテキストウィンドウを効率的に使えるようになりました。
3. 複雑なロジックのツール化
複雑な処理手順を長々とプロンプトで説明するのではなく、それらをツールやMCPサーバーとしてパッケージ化し、エージェントが必要に応じて呼び出せるようにしました。これにより、プロンプトは簡潔になり、エージェントの判断も明確になります。ツールの説明は必要ですが、詳細な実装ロジックをコンテキストから排除できる効果は大きいと感じています。
まとめ
コンテキストエンジニアリングは、AIエージェント開発における新しい思考法です。Anthropicが提示する「最小限の高シグナルトークン」という原則、システムプロンプト・ツール・動的取得の最適化、そして長期タスクへの3つのテクニックは、実践的で効果的なガイドラインとなります。
重要なのは、コンテキストを「貴重で有限なリソース」として扱うという認識です。より多くの情報を詰め込むのではなく、適切な情報を適切なタイミングで提供することが、エージェントの真の性能を引き出します。
所感として、この分野はまだ探索の初期段階にあり、今後も新しいパターンやベストプラクティスが発見されていくでしょう。開発者としては、これらの原則を基礎としながら、自身のユースケースに最適なアプローチを継続的に探求していくことが重要だと思います。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion