1.はじめに
2024/05/14にOpenAIからGPT-4 omni(以下gpt-4o)が発表されました。
マルチモーダルに対応した高性能大規模言語モデルということで夢が広がりますが、今回は動画から作業手順を自動生成させてどのくらい使えるのか検証してみました。
2.GPT-4oでできること
OpenAIのCookbookには、GPT-4oの設計コンセプトに関する情報が記載されています。
概要をまとめると以下の通りです。
| GPT-4o | 設計されている入出力 | 現在(2024/6/15) |
|---|---|---|
| 入力 | - テキスト - オーディオ - ビデオ |
- テキスト - 画像 |
| 出力 | - テキスト - オーディオ - 画像 |
- テキスト |
テキスト、画像だけでなく音声や動画も入出力にできるように設計されているようです。
現時点(2024/6/15)では音声や動画を直接モデルにインプット、出力させることはできませんが今後のアップデートに期待したいですね。
3.今回試したシナリオ
今回は、Excelのリストからシートを一気に作成する方法を解説した以下のYoutube動画(5分くらい)を元に作業手順書を自動生成させてみました。
最終的にExcelの手順書まで自動生成する形にしてみました。

動画から実際に自動生成されたExcel手順書の例

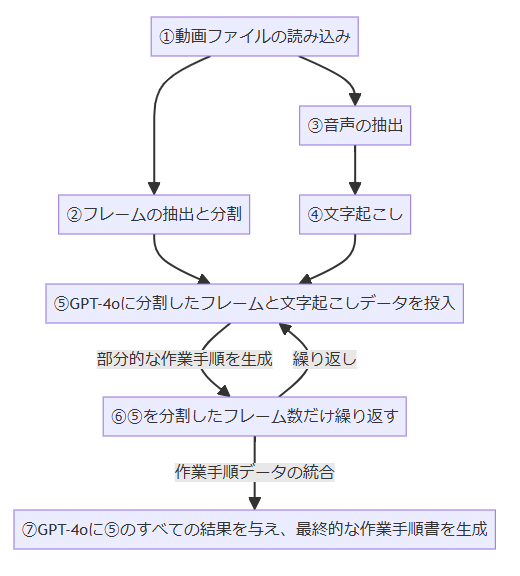
5分程度の動画のフレームデータ(動画を静止画に分割したデータ)でも、丸ごとGPT-4oに投げるとToken上限に引っ掛かりエラーになってしまうので、フレームを分割してトークン数を抑えるようなフローにしました。
具体的な実現フローは以下の通りです。
利用してる主なライブラリは以下の通りです。
| ライブラリ | 用途 |
|---|---|
| openai | OpenAIのAPIを使用するためのライブラリ |
| cv2 | OpenCVライブラリ。動画ファイルからフレーム(静止画)を抽出するために使用。 |
| moviepy | 動画編集のためのライブラリ。動画から音声を抽出するために使用。 |
後は、動画からフレームに切り出すためにffmpegを利用する必要があります。
Windows環境でffmpegを利用するにはFFmpeg-Buildsからffmpeg-master-latest-win64-gpl.zipをダウンロード&解凍してパスを通すだけで利用できるようになります。
4.実行コード
基本的にはOpenAIのCookbookに記載されているコードをベースに実装しましたが、先述した通り、動画のフレームデータを一括で投げるとGPT-4oのトークンリミットtokens per min (TPM): Limit 30000に引っ掛かりリクエストがエラーになるので、
リミットの引っかからない程度に動画フレームを分割するようにカスタマイズしています。
2024/06/06 14:56:37 Error creating chat completion stream: error, status code: 429, message: Request too large for gpt-4o in organization org-... on tokens per min (TPM): Limit 30000, Requested 30182. The input or output tokens must be reduced in order to run successfully. Visit https://platform.openai.com/account/rate-limits
完成系の全コード(詳細説明は割愛)
from openai import OpenAI
from moviepy.editor import VideoFileClip
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
from openpyxl.cell.text import InlineFont
from openpyxl.cell.rich_text import TextBlock, CellRichText
import time
import base64
import math
import openpyxl
import os
import cv2
VIDEO_PATH = r"<MP4ファイルのパスを指定>"
def process_video(video_path, seconds_per_frame=2):
base64Frames = []
base_video_path, _ = os.path.splitext(video_path)
video = cv2.VideoCapture(video_path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = video.get(cv2.CAP_PROP_FPS)
print("fps=", fps)
frames_to_skip = int(fps * seconds_per_frame)
curr_frame=0
# Loop through the video and extract frames at specified sampling rate
while curr_frame < total_frames - 1:
video.set(cv2.CAP_PROP_POS_FRAMES, curr_frame)
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
curr_frame += frames_to_skip
video.release()
# Extract audio from video
audio_path = f"{base_video_path}.mp3"
clip = VideoFileClip(video_path)
clip.audio.write_audiofile(audio_path, bitrate="32k")
clip.audio.close()
clip.close()
print(f"Extracted {len(base64Frames)} frames")
print(f"Extracted audio to {audio_path}")
return base64Frames, audio_path
# Extract 1 frame per second. You can adjust the `seconds_per_frame` parameter to change the sampling rate
base64Frames, audio_path = process_video(VIDEO_PATH, seconds_per_frame=1)
# Set the API key and model name
MODEL="gpt-4o"
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY", "sk-xxxxxxxxxx"))
def transcribe_audio(client, audio_path, model):
# Transcribe the audio
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=open(audio_path, "rb"),
)
return transcription.text
def generate_procedure(base64_frames, transcription_text, model, client, max_frames_per_request=30):
num_requests = math.ceil(len(base64_frames) / max_frames_per_request)
procedure_steps = []
for i in range(num_requests):
start_index = i * max_frames_per_request
end_index = min((i + 1) * max_frames_per_request, len(base64_frames))
frames_subset = base64_frames[start_index:end_index]
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": f"与えられた動画データのセグメント{i+1}/{num_requests}と文字起こしデータを元に、説明されている作業の手順をできるだけ詳細に日本語で箇条書きで作成してください。"},
{"role": "user", "content": [
f"こちらが動画セグメント{i+1}/{num_requests}のフレーム画像です。",
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, frames_subset),
{"type": "text", "text": f"音声の文字起こしデータは以下の通りです: {transcription_text}"}
],
}
],
temperature=0,
)
procedure = response.choices[0].message.content
procedure_steps.append(procedure)
print(f"セグメント {i+1}/{num_requests} の作業手順:")
print(procedure)
print("=" * 40) # 区切り線を表示
final_response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content":
"""
これまでに生成された各セグメントの作業手順をもとに、動画全体の詳細な作業手順書を章建てて構成し、#出力フォーマットで作成してください。
出力フォーマットの前後に余計な説明をつけないでください。
#出力フォーマット:
|No|作業名|詳細手順|
|xxx|xxxx|xxxx|
"""
},
{"role": "user", "content": "\n".join(procedure_steps)}
],
temperature=0,
)
return final_response.choices[0].message.content
def create_excel_from_markdown_table(answer, output_file):
# Excelファイルを新規作成
wb = openpyxl.Workbook()
sheet = wb.active
# 1行目の列名を設定
sheet["A1"] = "No"
sheet["B1"] = "作業名"
sheet["C1"] = "詳細手順"
# 1行目のセルのスタイルを設定
header_fill = PatternFill(start_color="7030A0", end_color="7030A0", fill_type="solid")
header_font = Font(color="FFFFFF", name="Meiryo Boot")
for cell in sheet[1]:
cell.fill = header_fill
cell.font = header_font
# answerからMarkdownの表形式の部分だけを取り出す
lines = answer.split("\n")
table_data = []
in_table = False
for line in lines:
if line.startswith("|") and "---" in line:
in_table = True
continue
if in_table:
if line.startswith("|"):
table_data.append(line)
else:
break
# 取り出したデータをシートに追加
for line in table_data:
data = line.strip("|").split("|")
if len(data) == 3:
data[2] = data[2].replace("<br>", "\n")
rich_text = CellRichText()
for i, part in enumerate(data[2].split("**")):
if i % 2 == 0:
rich_text.append(part)
else:
inline_font = InlineFont(b=True)
rich_text.append(TextBlock(inline_font, part))
data[2] = rich_text
sheet.append(data)
# セル幅の自動調整
for column in sheet.columns:
max_length = 0
column_letter = column[0].column_letter
for cell in column:
if isinstance(cell.value, CellRichText):
length = len(str(cell.value))
else:
length = len(str(cell.value))
if length > max_length:
max_length = length
adjusted_width = (max_length + 2) * 1.2
sheet.column_dimensions[column_letter].width = adjusted_width
# C列のセルの折り返し設定
for row in sheet.iter_rows(min_row=2):
cell = row[2]
cell.alignment = Alignment(wrap_text=True)
# フォントの設定
for row in sheet.iter_rows(min_row=2):
for cell in row:
cell.font = Font(name="Meiryo Boot")
# 枠線の設定
border = Border(left=Side(border_style="thin", color="000000"),
right=Side(border_style="thin", color="000000"),
top=Side(border_style="thin", color="000000"),
bottom=Side(border_style="thin", color="000000"))
for row in sheet.iter_rows():
for cell in row:
cell.border = border
# Excelファイルを保存
wb.save(output_file)
# 関数を実行して文字起こしを行う
transcription_text = transcribe_audio(client, audio_path, "whisper-1")
# 作業手順書を生成
procedure = generate_procedure(base64Frames, transcription_text, MODEL, client, max_frames_per_request=34)
#回答結果の表示
print(procedure)
5.検証結果
以下の3パターンで実験しました。
- 動画データのみから手順書を生成
- 音声データを文字起ししたテキストデータのみから手順書を生成
- 動画データ+文字起ししたテキストデータから手順書を生成
5.1 動画データの身から生成した手順書
以下のような手順書が生成されました。
Ctrl + Shift + 1は実際はCtrl + Shift + ↓だったり、動画に映っている情報だけを頼りに手順に起こしているので、情報が多くちょっとわかりにくい手順書になっている印象です。でも細かく手順には落としてくれてる。
| No | 作業名 | 詳細手順 |
|---|---|---|
| 1 | リストからシートを一気に作成する方法 | 1. Excelファイルを開く。 2. 「リストからシートを一気に作成する方法」というタイトルのシートを確認する。 3. 「リストからシート名」列のデータを選択する。 4. 「Ctrl + Shift + 1」を押して、選択したデータをシート名として使用する。 5. 「リストの名前をシートの名前に!」というメッセージが表示される。 6. 各リスト名に基づいて新しいシートが作成される。 |
| 2 | リストからシートを作成しデータを貼り付ける方法 | 1. Excelシートを開く。 2. 「リストから作成」シートを選択する。 3. 「リストから作成」シートのデータを確認する。 4. データの範囲を選択する(例:A2からA13)。 5. キーボードの「Ctrl」キーを押しながら「Shift」キーと「+」キーを押す。 6. データが選択された状態で、右クリックして「コピー」を選択する。 7. 新しいシートを作成する。 8. 新しいシートに移動し、セルA1を選択する。 9. 右クリックして「貼り付け」を選択する。 10. データが正しく貼り付けられたことを確認する。 |
| 3 | ピボットテーブルのオプション設定方法 | 1. 「ピボットテーブルのオプション」ボタンをクリック。 2. 「リストから作成」を選択。 3. 「リストから作成」ウィンドウが表示される。 4. リストの項目を選択。 5. 「OK」ボタンをクリック。 6. 上部の「オプション」タブをクリック。 7. 「レポートフィルター ページの表示」オプションを選択。 8. 画面下部の「シート1」を選択。 |
| 4 | シート間の移動方法 | 1. シートタブのクリック: - 画面下部のシートタブをクリックして、異なるシートに移動します。 2. Ctrl + Page Up: - キーボードの「Ctrl」キーを押しながら「Page Up」キーを押すと、左側のシートに移動します。 3. Ctrl + Page Down: - キーボードの「Ctrl」キーを押しながら「Page Down」キーを押すと、右側のシートに移動します。 4. Ctrl + Shift + Page Up: - キーボードの「Ctrl」キーと「Shift」キーを押しながら「Page Up」キーを押すと、複数のシートを選択しながら左側のシート に移動します。 5. Ctrl + Shift + Page Down: - キーボードの「Ctrl」キーと「Shift」キーを押しながら「Page Down」キーを押すと、複数のシートを選択しながら右側のシー トに移動します。 |
| 5 | すべてのシートに同じデータを入力する方法 | 1. Excelファイルを開く。 2. シートタブを確認し、複数のシートが存在することを確認する。 3. シートタブの1つを右クリックする。 4. 「すべてのシートを選択」をクリックする。 5. 任意のセルにデータを入力する。 6. Enterキーを押してデータを確定する。 7. 他のシートにも同じデータが入力されていることを確認する。 |
| 6 | 複数シートの選択と操作方法 | 1. シートタブを選択する。 2. Shiftキーを押しながら、他のシートタブをクリックして選択する。3. 選択したシートに対して操作を行う(例:セルの内容を削除する)。 4. CtrlキーとPage Upキー、またはCtrlキーとPage Downキーを使ってシート間を移動する。5. シートタブを右クリックし、表示されるメニューから「グループ解除」を選択する。 |
| 7 | ピボットテーブルの作成方法 | 1. Excelのシートタブをクリックして、シート「1」を選択する。 2. キーボードの「Ctrl」キーを押しながら「Page Down」キーを押して、次のシート「2」に移動する。 3. 再度「Ctrl」キーを押しながら「Page Down」キーを押して、シート「3」に移動する。 4. シート「3」でデータを選択するために、セル範囲をクリックしてドラッグする。 5. キーボードの「Ctrl」キーを押しながら「Shift」キーと「+」キーを押して、選択範囲を拡大する。 6. 「Enter」キーを押して、選択範囲を確定する。 7. ピボットテーブルを挿入するために、リボンの「挿入」タブをクリックする。 8. 「ピボットテーブル」ボタンをクリックして、ピボットテーブルの作成ウィンドウを開く。 9. ピボットテーブルのフィールドリストから、必要なフィールドをドラッグして配置する。 10. ピボットテーブルの設定が完了したら、「OK」ボタンをクリックしてピボットテーブルを作成する。 |
| 8 | 新しいウィンドウを開いてシートを操作する方法 | 1. 「表示」タブをクリックする。 2. 「ウィンドウ」グループの「新しいウィンドウを開く」をクリックする。 3. 新しいウィンドウが開かれる。 4. 「Ctrl + Page Down」キーを押してシートを切り替える。 5. 「Ctrl + Page Up」キーを押してシートを切り替える。 6. 「Ctrl + Shift + Page Up」キーを押してシートを切り替える。 7. 「Ctrl + Shift + Page Down」キーを押してシートを切り替える。 8. シートタブを右クリックし、「削除」を選択する。 9. 「Delete」キーを押してセルの内容を削除する。 10. シートタブを右クリックし、「名前の変更」を選択する。 11. シートの名前を変更する。 12. 「Ctrl + Page Down」キーを押してシートを切り替える。 |
| 9 | シートのデータ入力と保存方法 | 1. Excelシートを開く。 2. 「Ctrl + Page Down」キーを押して、次のシートに移動する。 3. 新しいシートにデータを入力する。 - A列に「リスト内の数字(大文字)」を入力。 - B列に「リスト内の英字」を入力。 - D列に「月のリスト」を入力。 4. データの入力が完了したら、シートを保存する。 5. 動画の最後に、視聴者に動画の高評価とチャンネル登録を促す。 |
5.2 音声データを文字起ししたテキストデータのみから手順書を生成
以下のような手順書が生成されました。
動画だけから生成した手順に比べるとポイントを押さえた見やすい手順書が出来上がりました。
動画の解説者が丁寧に説明していることも重要な要素だとは思います。
また、画面の情報は欠落しているため、動画で解説してないけど画面上から判断できる重要な情報がある場合はそこは手順書には載ってこないことになります。
| No | 作業名 | 詳細手順 |
|---|---|---|
| 1 | 準備 | - 対象リスト: 1から12のリスト、またはA社からL社のリストなど |
| 2 | ピボットテーブルの作成 | 1. 対象範囲を選択: - リストの範囲を選択します。 2. ピボットテーブルの作成: - Alt + N + V + Enter を押してピボットテーブルを作成します。 |
| 3 | ピボットテーブルの設定 | 1. フィルターの設定: - 右側のリストから項目名をフィルターにドラッグします。 2. レポートフィルターページの表示: - オプションの右側にある三角印をクリックし、「レポートフィルターページの表示」を選択します。 - OK を押します。 |
| 4 | シートの整理 | 1. 不要なデータの削除: - 全てのシートを選択します。 - Ctrl + Shift を押しながら Ctrl + Page Down でシートを選択。- Delete キーを押して不要なデータを削除します。 |
| 5 | 作業グループの解除 | 1. 作業グループの解除: - 他のシートをクリックするか、右クリックから「作業グループの解除」を選択します。 |
| 6 | 確認 | - 各シートにリストの名前が付けられていることを確認します。 - 不要なデータが削除されていることを確認します。 |
| 7 | まとめ | - 手順を再度確認し、必要に応じて再実行します。 |
| 8 | 動画の視聴とフィードバック | - この手順を動画で確認しながら実行してください。 - 動画が役立った場合は、Goodボタンとチャンネル登録をお願いします。 |
| 注意点 | - | 作業グループを解除しないと、全てのシートに同じ操作が適用されるので注意してください。 |
| 参考 | - | 動画の再生と手順の確認を行いながら作業を進めてください。 |
5.3 動画データ+文字起ししたテキストデータから手順書を生成
以下のような手順書が生成されました。
| No | 作業名 | 詳細手順 |
|---|---|---|
| 1 | はじめに | この手順書では、Excelのリストからシートを一気に作成する方法を紹介します。手動でシートを作成するのは大変ですが、ピボット テーブルを使用することで効率的に作業を進めることができます。 |
| 2 | 必要な準備 | - Excelファイルを開き、リストを用意します(例:1から12までのリストやA社からL社までの会社リスト)。 |
| 3 | ピボットテーブルの作成 | 1. リストの範囲を選択: - 対象範囲(例: 1から12のリスト)を選択します。 2. ピボットテーブルの作成: - Alt + N + V + Enterを押してピボットテーブルを作成します。 |
| 4 | フィルターの設定 | 1. フィルターに項目名をドラッグ: - ピボットテーブルのフィールドリストから項目名をフィルターにドラッグします。 2. レポートフィルターページの表示: - ピボットテーブルツールの「オプション」タブをクリックし、オプションの右側にある三角印をクリックします。 - 「レポートフィルターページの表示」を選択し、OKを押します。 |
| 5 | シートの作成 | - 指定したリストの名前に従ってシートが自動的に作成されます。 |
| 6 | 不要なデータの削除 | 1. 全シートを選択: - Ctrl + Shift + Page Downを押して全てのシートを選択します。2. 不要なデータを削除: - Deleteキーを押して不要なデータを削除します。 |
| 7 | 作業グループの解除 | - 作業グループを解除するために、他のシートをクリックするか、右クリックして「作業グループの解除」を選択します。 |
| 8 | 再確認 | - 必要に応じて、再度手順を繰り返してリストからシートを作成する方法を確認します。 |
| 9 | 動画の見返しと実践 | - 動画を見返しながら、手元でも同じ操作を実践することを推奨します。 |
| 10 | チャンネル登録と評価 | - 動画が役立った場合は、Goodボタンとチャンネル登録をお願いします。 |
音声情報のみから生成した手順書と比べると以下の点がより詳しく手順として記載されていました。
| 項目 | より詳細に記載されている内容 |
|---|---|
| はじめに | 手動でシートを作成するのが大変である点と、ピボットテーブルを使用することで効率的に作業を進められる点について言及されています。 |
| 必要な準備 | 具体的なリストの例(1から12までのリストやA社からL社までの会社リスト)が示されています。 |
| ピボットテーブルの作成 | 対象範囲の選択方法(例: 1から12のリスト)が具体的に記載されています。 |
| フィルターの設定 | ピボットテーブルツールの「オプション」タブをクリックし、オプションの右側にある三角印をクリックする手順が詳しく説明されています。 |
| 不要なデータの削除 | 全シートを選択するショートカットキー(Ctrl + Shift + Page Down)が記載されています。 |
| 作業グループの解除 | 作業グループを解除する方法として、他のシートをクリックする方法と右クリックして「作業グループの解除」を選択する方法の両方が示されています。 |
6.おまけ(Excel手順書まで自動生成する)
以下のコードを追加すればGPT-4oの回答内容を元にExcelの手順書を自動生成できます。
#Excelファイルを生成
create_excel_from_markdown_table(procedure, "作業手順書.xlsx")
できあがるExcel手順書のサンプル
7.他の活用案
今回は操作説明動画からExcelの操作手順書を自動生成させてみましたが、以下のように様々な業務活用案が考えられます。
| 活用例 | 概要 |
|---|---|
| 手順書・ガイドの自動生成 | - 会議録、運用手順書、トラブルシューティングガイドなどを動画から自動生成 |
| トレーニング教材・ナレッジ共有 | - 技術者のデモンストレーションや問題解決の動画からトレーニング教材やナレッジベースを作成 |
| 進捗報告・インタビュー分析 | - ミーティングやユーザーインタビューの動画から、進捗状況や要望・課題を自動抽出 |
| ユーザーサポート強化 | - ユーザーからの問い合わせ対応の動画、画像から原因分析、FAQ、対応マニュアルを自動生成 |
| 社内イベントのダイジェスト作成 | - 社内イベントや研修の動画から、ハイライトシーンを自動抽出し、ダイジェスト動画、要約を作成 |
| 会議のアクションアイテム抽出 | - 会議の動画から、次のアクションアイテムや宿題を自動的に抽出し、リマインダーを設定 |
8.まとめ
※生成AIにまとめてもらった内容をそのまま記載しています。
✅ GPT-4 omni(GPT-4o)を使ってYoutubeの動画から作業手順書を自動生成する方法を検証
- 使用動画:「Excelのリストからシートを一気に作成する方法」(約5分)
- 実験パターン:
- 動画データのみ
- 音声データの文字起こしのみ
- 動画データと文字起こしデータの組み合わせ
✅ 検証結果(ただし動画と音声の情報量の質にもよるのであくまで参考値)
- 動画データのみ:情報が多くてややわかりづらい手順書ができあがる。
- 音声データの文字起こしのみ:要点を押さえたわかりやすい手順書ができあがる。
- 動画データと文字起こしデータの組み合わせ:画面の情報も考慮したより具体的な手順書ができあがる。
- 5分程度の動画から手順書を生成するのに1回50円弱かかった(コスト高め)
✅ 現状と将来性
- 2024年6月時点でGPT-4oはテキストと画像の入力のみに対応
- 音声や動画の直接入力にはフレーム抽出や文字起こしなどの前処理が必要
- 今後のアップデートで性能と利便性の向上に期待

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion